影响 Kubernetes 调度的决策因素
作者:互联网
本文永久链接: https://www.xtplayer.cn/kubernetes/scheduler/influencing-kubernetes-scheduler-decisions/
为了提高节点资源的最大利用率,调度程序使用复杂的算法来确保最有效的 Pod 调度。在本文中,我们讨论调度程序如何选择最佳节点来运行 Pod,以及如何影响其决策。
哪个节点具有可用资源?
选择适当的节点时,调度程序会检查每个节点是否有足够的资源满足 Pod 调度。如果您已经声明 Pod 所需的 CPU 和内存量(通过请求和限制),调度程序将使用以下公式来计算给定节点上的可用内存:
调度可用内存 = 节点总内存 - 已预留内存
保留内存是指:
- Kubernetes 守护进程使用的内存,例如:kubelet、containerd(一种容器运行时)。
- 节点操作系统使用的内存,例如:内核守护程序。
通过使用此方程式,调度程序可确保由于过多 Pod 竞争消耗节点所有可用资源,从而导致节点资源耗尽引起其他系统异常,比如系统触发 oom。
影响调度过程
在不受用户影响的情况下,调度程序在将 Pod 调度到节点时执行以下步骤:
- 调度程序检测到已创建新的 Pod,但尚未将其分配给节点;
- 它检查 Pod 需求,并相应地筛选出所有不合适的节点;
- 根据权重将剩下的节点进行排序,权重最高的排在第一位;
- 调度程序选择排序列表中的第一个节点,然后将 Pod 分配给它。
通常,我们会让调度程序自动选择合适的节点(前提是 Pod 配置了资源请求和限制)。但是,有时可能需要通过强制调度程序选择特定节点或手动向多个节点添加权重来影响此决策,以使其比其他节点更适合 Pod 调度。
让我们看看我们如何做到这一点:
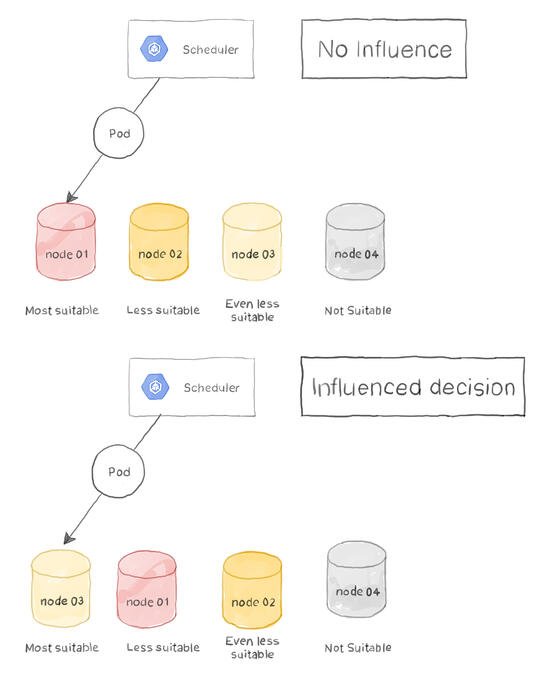
节点名称
在最简单的节点选择配置中,您只需在 .spec.nodeName 中指定其名称,就可以强制 Pod 在指定节点上运行。例如,以下 YAML 定义 Pod 强制在 app-prod01 上进行调度:
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx nodeName: app-prod01 |
请注意,由于以下原因,此方法是最简单但最不推荐的节点选择方法:
- 如果由于某种原因无法找到指定名称的节点(例如,更改了主机名),则 Pod 将不会运行。
- 如果该节点没有 Pod 运行所需的资源,则 Pod 会运行失败,并且也不会将该 Pod 调度到其他节点。
- 这会导致 Pods 与它们的节点紧密耦合,这是一种糟糕的设计实践。
节点选择器
覆盖调度程序决策的第一个最简单的方法是使用 Pod 定义或 Pod 模板(如果使用的是 Deployments 之类的控制器)中的 .spec.nodeSelector 参数。nodeSelector 接受 一个或多个 键-值对标签,这些 键-值对 标签必须在节点设置才能正常的调度 Pod。假设您最近购买了两台配备 SSD 磁盘的计算机,您希望数据库相关所有的 Pod 在 SSD 支持的节点上进行调度,以获得最佳的数据库性能。DB Pod 的 Pod YAML 可能如下所示:
apiVersion: v1 kind: Pod metadata: name: db spec: containers: - name: mongodb image: mongo nodeSelector: disktype: ssd |
根据该定义,当调度程序选择合适的 Pod 分配节点时,将仅考虑具有 disktype=ssd 标签的节点。
此外,您可以使用自动分配给节点的任何内置标签来操纵选择决策。例如,节点的主机名(kubernetes.io/hostname),体系结构(kubernetes.io/arch),操作系统(kubernetes.io/os)等均可用于节点选择。
节点亲和性
当您需要选择特定的节点来运行我们的 Pod 时,节点选择非常有用。但是选择节点的方式是有限的,只有与所有定义的标签匹配的节点才被考虑用于 Pod 放置。Node Affinity 通过允许您定义硬节点和软节点需求,为您提供了更大的灵活性。硬性要求必须在要选择的节点上匹配。另一方面,软条件允许您为具有特定标签的节点增加更多权重,以使它们在列表中的位置比对等节点更高。没有软需求标签的节点将不被忽略,但它们权重更小。
让我们举个例子:我们的数据库是 I/O 密集型的。我们需要数据库 Pods 始终在 SSD 支持的节点上运行。此外,如果 Pod 部署在区域 zone1 或 zone2 中的节点上,因为它们在物理上更靠近应用程序节点,那么它们的延迟会更短。满足我们需求的 Pod 定义可能如下所示:
apiVersion: v1
kind: Pod
metadata:
name: db
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk-type
operator: In
values:
- ssd
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: zone
operator: In
values:
- zone1
- zone2
containers:
- name: db
image: mongo
|
nodeAffinity 节使用以下参数来定义硬性要求和软性要求:
- requiredDuringSchedulingIgnoredDuringExecution:部署 DB Pod 时,节点必须具有 disk-type=ssd。
- preferredDuringSchedulingIgnoredDuringExecution: 当对节点进行排序时,调度器会给予标签为zone=zone1或zone=zone2的节点更高的权重。如果有disk-type=ssd和zone=zone1的节点,则优先选择 disk-type=ssd 且无 zone 标签的节点或指向其他 zone 的节点。权重可以是 1 到 100 之间的任意值,权重号赋予匹配节点相对于其他节点更高的权重。数字越大,权值越高。
注意,在进行选择时,节点亲和性允许您在选择目标节点上应该存在(或不存在)哪些标签时拥有更多的自由。在本例中,我们使用 In 操作符定义了多个标签,目标节点上存在任何一个标签即可。其他运算符是 NotIn、Exists、doesnoexistists、Lt(小于)和 Gt(大于)。值得注意的是,NotIn 和 doesnot existist 实现了所谓的节点反亲和性。
节点亲和性和节点选择器不是互斥的,它们可以共存于同一个定义文件中。但是,在这种情况下,节点选择器和节点亲和性硬要求必须匹配。
Pod 亲和性
节点选择器和节点亲和性(以及反亲和性)帮助我们影响调度器关于在何处放置 Pods 的决策。但是,它只允许您基于节点上的标签进行选择。它不关心 Pod 本身的标签。您可能需要在以下情况下根据 Pod 标签进行选择:
- 需要将所有中间件 Pod 放在同一个物理节点上,与那些具有 role=front 标签的 Pod 一起,以减少它们之间的网络延迟。
- 作为一种安全最佳实践,我们不希望中间件 Pod 与处理用户身份验证的 Pod 共存(role=auth)。这不是一个严格的要求。
如您所见,这些要求不能用节点选择器或亲和性来满足,因为在选择过程中不考虑 Pod 标签——只考虑节点标签。
为了满足这些需求,我们使用 Pod 亲和性和反亲和性。本质上,它们的工作方式与节点亲和性和反亲和性相同。必须满足硬性要求来选择目标节点,而软条件增加了拥有所选节点的机会(权重),但不是严格要求。让我们举个例子:
apiVersion: v1
kind: Pod
metadata:
name: middleware
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: role
operator: In
values:
- frontend
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- auth
topologyKey: kubernetes.io/hostname
containers:
- name: middleware
image: redis
|
在上面的 Pod 定义文件中,我们对硬性要求和软性要求进行了如下设置:
requiredDuringSchedulingIgnoredDuringExecution:我们的 Pod 必须在具有标签为 app-front 的 Pod 节点上调度。
preferredDuringSchedulingIgnoredDuringExecution:我们的 Pod 不应该(但它可以)被调度到运行带有标签为 role=auth 的 Pod 的节点上。与节点亲和性一样,soft requirement 将权重从 1 设置为 100,以增加节点相对于其他节点的概率。在我们的示例中,软需求被放置在 poantiaffinity 中,导致运行具有标签为 role=auth 的 Pod 的节点在调度程序做出决定时被选中的可能性更小。
topologyKey 用于对规则将应用于哪个领域做出更细粒度的决策。topologyKey 接受一个标签键,该标签键必须出现在选择过程中考虑的节点上。在我们的示例中,我们使用了自动填充的标签,该标签在默认情况下自动添加到所有节点,并引用节点的主机名。但是您可以使用其他自动填充的标签,甚至是自定义的标签。例如,您可能需要只在具有 rack 或 zone 标签的节点上应用 Pod 亲和规则。
关于 IgnoredDuringExecution 的注释
您可能已经注意到,硬需求和软需求都有 IgnoredDuringExecution 后缀。这意味着在做出调度决策之后,调度程序将不会尝试更改已经放置的 Pods,即使条件发生了变化。例如,根据节点亲和性规则,将一个 Pod 调度到一个具有标签为 app=prod 的节点上。如果该标签被更改为 app=dev, 旧 Pod 不会被终止,并在另一个有 app=prod 标签的节点上启动新的 Pod。这个行为在将来可能会改变,以允许调度程序在部署后继续检查节点和 Pod 的关联性(和反关联性)规则。
污点与容忍
在某些场景中,您可能希望阻止将 Pod 调度到特定节点。可能您正在运行测试或扫描此节点以查找威胁,而您不希望应用程序受到影响。节点反亲和性可以实现这一目标。但是,这是一个重大的管理负担,因为您需要向部署到集群的每个新 Pod 添加反关联规则。对于这种场景,您应该使用污点。
当一个节点配置了污点时,除非 Pod 能够容忍这种污点,否则不能对它调度 Pod。容忍只是一个与污点匹配的键-值对。让我们举个例子来说明:
需要对主机 web01 进行污染,以使其不接受更多 Pod。taint 命令如下:
kubectl taint nodes web01 locked=true:NoSchedule |
上面的命令在名为 web01 的节点上放置了一个污点,该节点具有以下属性:
-
标签 locked=true,该标签必须配置在想要运行在该节点的 Pod 上。
-
NoSchedule 的污点类型。污点类型定义了应用污点的行为,它有以下几种可能:
- NoSchedule:此节点一定不要调度。
- PreferNoSchedule:尽量不要调度,类似软亲和性。
- NoExecute:不仅不会调度,还会驱逐 Node 上已有的 Pod。
在带有污点的节点上,Pod 的定义文件可能如下所示:
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - name: mycontainer image: nginx tolerations: - key: "locked" operator: "Equal" value: "true" effect: "NoSchedule" |
让我们仔细看看这个定义的容忍部分:
-
为了具有正确的容忍,我们需要指定键(locked),值(true)和运算符。
-
运算符可以是两个值之一:
- Equal:当使用 equal 操作符时,键、值和污染效果必须与节点的污染匹配。
- Exists:在使用 exists 操作符时,不需要将污点与容忍匹配,只需匹配建即可。
-
如果使用 Exists 运算符,则可以忽略容忍键、值和效果。具有这种容忍的 Pod 可以被调度到具有任何受污点的节点。
注意,在 Pod 上放置容忍并不能保证它被部署到受污染的节点上。它只允许行为发生。如果要强制 Pod 加入受污染的节点,还必须像前面讨论的那样向其定义添加节点亲和性。
TL; DR
在节点上自动放置 Pod 是 Kubernetes 诞生的原因之一。作为管理员,只要您对 Pod 需求做出了良好的声明,您就不用担心节点是否有足够的空闲资源来运行这些 Pod。但是,有时您必须手动干预和覆盖系统关于在何处放置 Pods 的决定。在本文中,我们讨论了几种方法,在决定部署 Pods 时,您可以通过这些方法对特定节点的调度器产生更大的影响。让我们快速回顾一下这些方法:
- 节点名称:通过将节点的主机名添加到 Pod 定义的 .spec.nodeName 参数中,可以强制此 Pod 在该特定节点上运行。调度程序使用的任何选择算法都将被忽略。不建议使用此方法。
- 节点选择器:通过在节点上放置指定的标签,Pod 可以使用 nodeelector 参数指定一个或多个键-值标签,这些标签必须存在于目标节点上才能被选中以运行 Pod。推荐使用这种方法,因为它增加了很多灵活性,并建立了松耦合的 node-Pod 关系。
- 节点亲和性:在选择应该考虑哪个节点来调度特定的 Pod 时,这种方法增加了更多的灵活性。使用节点亲和性,Pod 可能严格要求在具有特定标签的节点上调度。它还可以通过影响调度程序为特定节点赋予更大的权重来表示对特定节点的某种程度的偏好。
- Pod 亲和性和反亲和性:当 Pod 与同一节点上的其他 Pod 共存(或不共存)时,可以使用此方法。Pod 亲和性允许将 Pod 部署在具有特定标签的 Pod 运行的节点上。相反,Pod 可能会强制调度程序不将其调度到具有特定标签的 Pod 运行的节点上。
- 污点和容忍:在这种方法中,您不需要决定将 Pod 调度到哪些节点,而是决定哪些节点是否接受 所有 Pod 调度,或者只接受选定的 Pod 调度。通过污染一个节点,调度程序将不考虑将这个节点作为任何 Pod 的调度节点,除非 Pod 配置了容忍。容忍由键、值和受染的效果组成。
标签:Kubernetes,标签,亲和性,调度,决策,污点,Pod,节点 来源: https://www.cnblogs.com/0591jb/p/14408317.html