KubeEdge在国家工业互联网大数据中心的架构设计与应用
作者:互联网
摘要:在18年的时候,工信部开展了一个叫国家创新发展工程,这个工程中提出了要建立一个国家工业大数据中心,中国移动在其中承担了边缘协同与数据采集相关功能的研发。本文将从该项目背景下面临的问题与挑战、技术选型等方面进行阐述。
一、问题与挑战
需求
- 从工厂采集生产、运行数据,汇总云端
- 云端进行统一控制:采什么数据、数据怎么处理
挑战
- 只能边主动连云,云不可以主动连边(边缘没有公网IP)
- 足够通用,灵活适应各类工业设备与协议
- 具备边缘自治能力,在网络不稳定时,边缘能够自治
- 具备边缘计算能力,能够在边缘节点运行各类应用
- 占用资源少,功耗低
二、技术选型
技术选型其实也是从我们的实际需求出发的,首先是EdgeX,其实在做这个项目之前,我们一直是用EdgeX做数据采集和管理的,EdgeX在数据采集和管理上做的还是比较完善的,功能也比较强,但是它也缺少一些能力,比如云边协同能力,我认为它是一个纯的边缘自治架构,不具备和云的一个同步能力,当然我们也有一些方案,比如从EdgeX的节点上拨一个VPN拨到我们的中心云上,但是VPN这种方案的扩展性还是比较差一点的;
备注:图片来自互联网
第二就是K3S/K8S,K3S/K8S第一个问题也是不具备云边协同能力,第二点是尤其是K8s占用的资源太大了,不太适合放在我们的工厂,K3s占用的资源已经少了不少,但一方面缺少云边协同的能力,另一方面也缺少设备管理能力;
第三个是OpenNESS,它是非常通用的框架,但对我们来说太通用了,不论做什么,都需要写适配器,去底层对接Kubernetes都可以,有点太灵活,开发工作量相对比较大,缺乏设备管理的能力;
第四个是OpenYurt,这个从功能描述上和KubeEdge比较像,但出现的比较晚,而当时我们的项目已经进行了一半了,目前看起来它整体的成熟度还是比KubeEdge差一些;
最后是KubeEdge。它具有云边协同能力、资源开销比较小,它还具有设备管理能力,我认为它还是比较有特色的,尤其是云边协同能力和设备管理能力,可能市面上很少找到同时具备这两种能力的。
架构设计
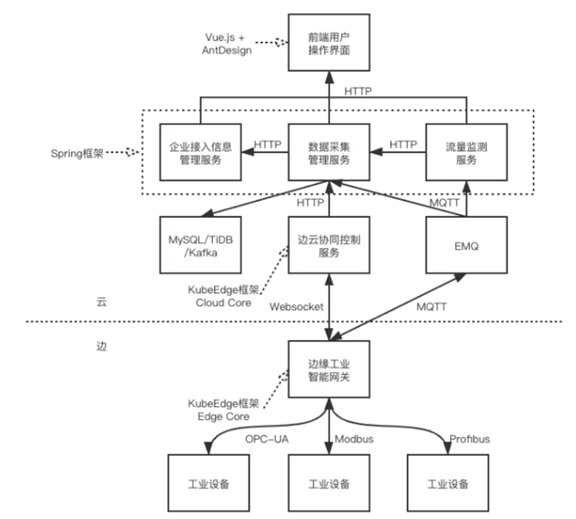
整体框架
这个是我们实际在国家工业互联网大数据中心中用到的架构,其实最核心的就是我们的KubeEdge,它其实就起到了一个设备管理、应用管理的作用;我的云端肯定首先会有一个K8s集群,我们会部署KubeEdge所谓的Cloud Core,所有的数据包括管理数据都是保存在云端的K8s中,边缘侧是运行在我们所谓的工控机或工业网关上,它运行的Kube Edge的Edge Core进程,它是负责在边缘侧运行我们的容器化应用,包括做设备管理、数据采集的一些应用;
Edge Core再往下就是Mapper,它是社区定义的一个标准,专门用来做设备管理和数据采集的,Mapper社区目前是提供了Modbus和蓝牙,比如我想管理一个摄像头,一个自己的设备,那我需要按照社区的规范去写Mapper,再往上看是我们封装那一层,通过Java和Spring Cloud封装了一层管理服务,为什么要做这一层封装呢?如果我们直接把KubeEdge或K8s的API暴露给用户,会有一些安全上的隐患,因为这个接口还是比较开放的,可能涉及到一些数据隔离性和K8s集群本身的一些功能,如果我们一旦把这个API暴露,用户可能会做一些破坏性的操作,所以我们对外还封装了一层业务逻辑。
最后我们还做了一个工业APP集市,做这个的原因主要是我们社区其实是定了一个标准,我个人开发者或者厂商其实我可以按照这个标准去做Mapper应用,做完之后它可以发布到我们的应用市场,我们可以收费或者免费分享给其他用户,其实这样我们也是希望建立这样一个生态来鼓励大家基于KubeEdge去做Mapper,希望做Mapper的开发者也能得到收益,这是我们的一个考虑。
数据采集
我们在项目过程中对KubeEdge的一些改进:
(1)支持更广泛的工业设备与协议
其实我们在刚做项目的时候发现KubeEdge支持的协议是有限的,只支持蓝牙、Modbus,而且它的CRD中把这个东西已经固定了,我们没有办法进行修改,所以我们要增加自己的协议就很不灵活,我们需要对代码层做一些改动,考虑到工业上协议非常多,而且有些是私有的东西,所以我们为了更好的支持这些协议,就允许做一些自定义扩展,一个是扩展现有的协议,比如说大家同样都是用Modbus协议,不同的设备可能有一些额外的配置,这个时候就可以用到我们新加的CustomizedValue字段,可以自定义的去配一些字段;第二种是完全就不用社区的协议,这个时候可以完全用我们的CustomizedProtocol,完全自定义自己的协议。
(2)支持更便捷的设备采集配置
其实工业上和我们有些IT思路还是不太一样,我们做IT的一般是先定义模板,再定义实例,但是工业上有所不同,一般是先定义实例,将实例复制修改里面的内容,但其实他们这么做也是考虑到现实情况的,举个例子,我有10个温度传感器,它是一模一样的,接到了同一个工业总线上,但是它所谓的属性都是一样的,唯一的区别是它在Modbus上的偏移量不一样,所以说我只要把Instance中的偏移量改了就可以了,所以基于这种考虑我们把原来Device model中的PropertyVisitor移动到DeviceInstance中,然后也加入了一些更灵活的配置项,比如整个采集周期是不可以配置的,工业中不同测点它是可以配置不同的采集周期,比如温度中周期可能是一小时一次,那像能耗数据可能就不需要这么高的频率了,所以这就需要一个更灵活的采集周期的一个配置,我们还做了增加CollectCycle等配置项到PropertyVisitor中以及抽取串口、TCP配置到公共部分。
(3)优化孪生属性的下发
(4)支持旁路数据配置
旁路数据处理
支持Mapper推送时序数据至边缘MQTT broker(EdgeCore不处理),具体推送到哪个Topic中也是可以定义的
与EMQX Kuiper进行集成,Kuiper支持从DeviceProfile中读取元数据
清洗规则由KubeEdge下发给Kuiper
第三方应用直接从边缘MQTT中获取数据
状态监控
其实要做一个商用的产品,状态监控是非常重要的,其实我觉得KubeEdge目前在监控这块还是有些缺失,社区提供了一个叫Cloud Stream的通道,这个通道可以配合MetricServer,也可以配合Prometheus,但是需要配置iptables来将流量拦截下来;还有一个是我如果一配就将整个流量拦截下来了,所以这块是有些问题的。
所以我们也做了另外一个方案:在边缘节点起了一个定时任务容器,这个定时任务做的事情也很简单,比如每5秒从我边缘的NodeExporter拉一次数据,把本地的数据拉完之后推到PushGateway上,PushGateway是普罗米修斯官方的一个组件,这个PushGateway是放在云上的,那通过这种方式我们可以实现整个监控。
三、其他项目中遇到的一些问题
多租户共享
其实K8s本身是有多租户的设计的,但KubeEdge在做的时候我们的Device没有考虑Namespace的问题,所以我们如果现在在Device中用Namespace是有bug的,所以现在KUbeEdge原身是没有办法把不同的设备放在不同的Namespace下,这个我们只能从业务层的业务逻辑做封装,比如给Device打一些标签,通过标签去做筛选;边缘node工作节点也是没有办法归属Namespace的,但是在我们的场景下,某个节点是属于某个租户的,是由这个租户独享的,这个时候我们可以通过和上层业务逻辑进行封装。
IP地址限制
其实按照我们现在的设计,我们每个租户会给他们一个K8s集群,会去连它的一个边缘设备,这种的方式其实云端的集群要求有一个公网IP,IP资源其实还是比较紧张的,怎么在地址有限的情况下比如说我们做一个项目给你200个公网IP,但我可能有1000个用户,那怎么去解决?
1)IPv6是最彻底的解决方案:目前社区给的答案是支持,但我们现在还没试过
2)端口复用:其实kubeEdge需要使用的端口比较少,默认是10003,最多也就4-5个端口,其实一个公网IP是可以给多个kubeEdge实例去复用的
高可用方案:这个其实社区是有的,其实是复用了kubernetes自有的功能,Service+Deployment与状态检查 应用案例
案例一:OPC-UA数据采集与处通过我们的放到了我们的应用超市,用户订购了以后OPC-UA mapper下发到边缘的网关上,再通过我们的一个页面配置就可以实现从
从边缘的工业设备上去采集数据,比如说:
- OPC-UA mapper采集温度数据
- 边缘节点告警应用直接从边缘获取数据
- 超过阈值触发告警,暂停设备
- KubeEdge对阈值进行调整
案例二:工业视频安防
这个是一个偏边缘自治的一个应用,其实和云目前的交互比较少,它下发到边缘侧可以独立运行,主要在边缘侧做AI推理,那如果要它和云结合起来,我们会把模型的训练放到云上,把训练完成的模型再通过KubeEdge推送到边缘,主要有:
- KubeEdge管理边缘节点上的视频安防应用配置
- 边缘视频安防应用在边缘节点自治运行
- 摄像头中取流,AI推理
- 安全帽、工作服佩戴检测
- 危险区域禁入检测
四、总结
(1)基于KubeEdge工业数据采集
- 当前通过CustomizedProtocol与CustomizedValue,已能支持各类工业协议
- 通过ConfigMap可以实现云端对边缘数据应用(Mapper)的控制
- 旁路数据(Spec/Data)为时序数据的处理提供了更便捷的支持
(2)KubeEdge的产品化
- 多租户方案
- 多种监控方案
- 高可用方案
- 公网IP复用方案
标签:架构设计,数据中心,KubeEdge,采集,边缘,数据,我们,其实 来源: https://www.cnblogs.com/huaweiyun/p/14384227.html