技术基础 | 舍弃”读修复概率”特性
作者:互联网
读修复这个特性给系统施加了额外的负载,却没有任何实质好处——这就是为什么我们一直以来都会建议大家先关闭这个特性;这也是在下一个Cassandra主要的版本,即Cassandra 4.0版本中,将这个特性完全拿掉的根本原因。
Apache Cassandra有一个叫做读修复概率(Read Repair Chance)的特性,通常我们都会建议我们的用户关闭这个功能,因为它经常会给你的集群内部增加大约20%的读负载成本,但这样的成本付出却目的不明且效果难保。
01 什么是读修复概率? Read Repair Chance可以通过两个数据表级别的模式(schema)选项来进行设置:read_repair_chance和dclocal_read_repair_chance。这两个选项都代表着在要求的一致性级别(consistency level)之上,协调节点(coordinator node)为了进行读修复而向额外的副本节点(replica node)发送请求的概率。 read_repair_chance的原始设定决定了在所有数据中心范围内,向所有副本发送额外请求的概率。而后来出现的dclocal_read_repair_chance设定则决定了在本地的数据中心范围内,向所有副本发送额外请求的概率。 默认值是read_repair_chance = 0.0以及dclocal_read_repair_chance = 0.1。这意味着跨数据中心的异步读修复默认是被关闭的,而在本地数据中心范围内的异步读修复发生的概率是收到的读取请求数量的10%。
02 读修复的成本几何? 考虑一下下面的集群部署方案: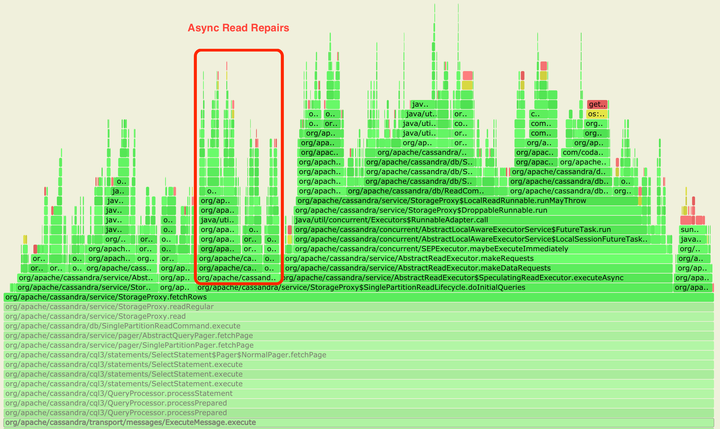 第二张火焰图展示的是当配置被改成dclocal_read_repair_chance = 0.0之后的情况。可以看到AlwaysSpeculatingReadExecutor的那支火焰降下去了,这显示出系统运行时的复杂程度降低了。
具体来说,复杂度的降低是因为从客户端发来的读请求在这种情况下会被转发给每一个副本节点,而非仅仅转发给一致性级别定义的那些副本。
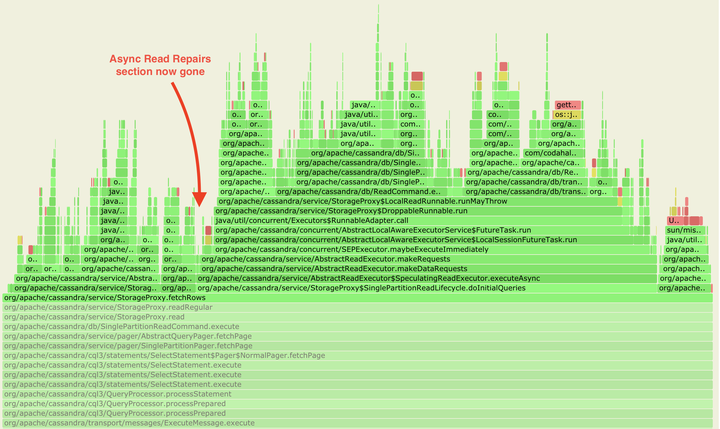
第二张火焰图展示的是当配置被改成dclocal_read_repair_chance = 0.0之后的情况。可以看到AlwaysSpeculatingReadExecutor的那支火焰降下去了,这显示出系统运行时的复杂程度降低了。
具体来说,复杂度的降低是因为从客户端发来的读请求在这种情况下会被转发给每一个副本节点,而非仅仅转发给一致性级别定义的那些副本。
 这两张火焰图均是在使用Apache Cassandra 3.11.9、Kubernetes和cass-operator、nosqlbench以及async-profiler的情况下生成的。
以前,我们需要依赖于已有的tlp-cluster、ccm、tlp-stress和cassandra-stress工具进行测试。而新工具带来的新测试方式格外地简单。通过使用k8s,同样的测试方式可以在本地或针对k8s的基础架构下使用。也就是说,我们无需在用于本地测试的ccm集群和用于云端测试的tlp-cluster中间来回切换。这条适用于所有的地方。我也并不是非要使用AWS做云端测试。
另外还值得一提的是这些新工具得到了来自DataStax的很多关注和支持,所以向开源社区介绍这些是值得的。
这两张火焰图均是在使用Apache Cassandra 3.11.9、Kubernetes和cass-operator、nosqlbench以及async-profiler的情况下生成的。
以前,我们需要依赖于已有的tlp-cluster、ccm、tlp-stress和cassandra-stress工具进行测试。而新工具带来的新测试方式格外地简单。通过使用k8s,同样的测试方式可以在本地或针对k8s的基础架构下使用。也就是说,我们无需在用于本地测试的ccm集群和用于云端测试的tlp-cluster中间来回切换。这条适用于所有的地方。我也并不是非要使用AWS做云端测试。
另外还值得一提的是这些新工具得到了来自DataStax的很多关注和支持,所以向开源社区介绍这些是值得的。
03 用额外的负载换得的好处是什么? 根据用户要求的一致性级别,当协调节点从多个副本节点中的任意一个获得回复后,它就会将这个结果返回给客户端。这也是为什么我们将这个特性称为“异步”读修复——虽然额外的后台负载会间接地影响读取操作的时延,但是这种影响并不是直接的。 异步的读修复同时意味着返回给客户端的结果不一定是修复后的数据。总的来说,你读取的数据中的10%是一定会在你读取之后被修复的。 而这个修复概率并不是对客户端来说被保证的概率,各种Cassandra operator也没法根据它赖以保证磁盘存储的数据的一致性的。事实上,这种修复概率对Cassandra operator没有什么保证,因为大多数不一致的数据都由hints处理,而节点宕机时间长于hint窗口的情况则需要手动修复。 除此之外,使用强一致性的系统(如读写操作都使用QUORUM作为一致性级别的系统)并不会出现这种数据未修复的情况。 这种系统需要做repair操作和磁盘上的数据一致性只是为了降低读取操作的时延(通过避免协调节点和副本节点之间因digest不匹配而引起的反复通信),同时确保已经被删除的数据不会被错误地读到(即墓碑都被合理且及时地发送到各个副本)。 所以说,读修复这个特性给系统施加了额外的负载,却没有任何实质好处。这就是为什么我们一直以来都会建议大家先关闭这个特性。这也是在下一个Cassandra主要的版本,即Cassandra 4.0版本中,将这个特性完全拿掉的根本原因。 从3.0.17 和3.11.3版本开始,如果你仍在你的数据库表中设置了与这些属性相关的值,你可能会在系统启动时看到如下警告:
04 现在就舍弃读修复吧 如果你使用的是4.0版本以前的Cassandra集群,下方代码可关闭异步读修复功能:
Apache Cassandra有一个叫做读修复概率(Read Repair Chance)的特性,通常我们都会建议我们的用户关闭这个功能,因为它经常会给你的集群内部增加大约20%的读负载成本,但这样的成本付出却目的不明且效果难保。
01 什么是读修复概率? Read Repair Chance可以通过两个数据表级别的模式(schema)选项来进行设置:read_repair_chance和dclocal_read_repair_chance。这两个选项都代表着在要求的一致性级别(consistency level)之上,协调节点(coordinator node)为了进行读修复而向额外的副本节点(replica node)发送请求的概率。 read_repair_chance的原始设定决定了在所有数据中心范围内,向所有副本发送额外请求的概率。而后来出现的dclocal_read_repair_chance设定则决定了在本地的数据中心范围内,向所有副本发送额外请求的概率。 默认值是read_repair_chance = 0.0以及dclocal_read_repair_chance = 0.1。这意味着跨数据中心的异步读修复默认是被关闭的,而在本地数据中心范围内的异步读修复发生的概率是收到的读取请求数量的10%。
02 读修复的成本几何? 考虑一下下面的集群部署方案:
- 在一个单独的数据中心里有一个键空间,其复制因子(replication factor)为3,即RF=3
- 默认值是dclocal_read_repair_chance = 0.1
- 客户端读取的一致性级别为LOCAL_QUORUM
- 客户端使用大多数驱动程序默认的token aware policy
第二张火焰图展示的是当配置被改成dclocal_read_repair_chance = 0.0之后的情况。可以看到AlwaysSpeculatingReadExecutor的那支火焰降下去了,这显示出系统运行时的复杂程度降低了。
具体来说,复杂度的降低是因为从客户端发来的读请求在这种情况下会被转发给每一个副本节点,而非仅仅转发给一致性级别定义的那些副本。
这两张火焰图均是在使用Apache Cassandra 3.11.9、Kubernetes和cass-operator、nosqlbench以及async-profiler的情况下生成的。
以前,我们需要依赖于已有的tlp-cluster、ccm、tlp-stress和cassandra-stress工具进行测试。而新工具带来的新测试方式格外地简单。通过使用k8s,同样的测试方式可以在本地或针对k8s的基础架构下使用。也就是说,我们无需在用于本地测试的ccm集群和用于云端测试的tlp-cluster中间来回切换。这条适用于所有的地方。我也并不是非要使用AWS做云端测试。
另外还值得一提的是这些新工具得到了来自DataStax的很多关注和支持,所以向开源社区介绍这些是值得的。
03 用额外的负载换得的好处是什么? 根据用户要求的一致性级别,当协调节点从多个副本节点中的任意一个获得回复后,它就会将这个结果返回给客户端。这也是为什么我们将这个特性称为“异步”读修复——虽然额外的后台负载会间接地影响读取操作的时延,但是这种影响并不是直接的。 异步的读修复同时意味着返回给客户端的结果不一定是修复后的数据。总的来说,你读取的数据中的10%是一定会在你读取之后被修复的。 而这个修复概率并不是对客户端来说被保证的概率,各种Cassandra operator也没法根据它赖以保证磁盘存储的数据的一致性的。事实上,这种修复概率对Cassandra operator没有什么保证,因为大多数不一致的数据都由hints处理,而节点宕机时间长于hint窗口的情况则需要手动修复。 除此之外,使用强一致性的系统(如读写操作都使用QUORUM作为一致性级别的系统)并不会出现这种数据未修复的情况。 这种系统需要做repair操作和磁盘上的数据一致性只是为了降低读取操作的时延(通过避免协调节点和副本节点之间因digest不匹配而引起的反复通信),同时确保已经被删除的数据不会被错误地读到(即墓碑都被合理且及时地发送到各个副本)。 所以说,读修复这个特性给系统施加了额外的负载,却没有任何实质好处。这就是为什么我们一直以来都会建议大家先关闭这个特性。这也是在下一个Cassandra主要的版本,即Cassandra 4.0版本中,将这个特性完全拿掉的根本原因。 从3.0.17 和3.11.3版本开始,如果你仍在你的数据库表中设置了与这些属性相关的值,你可能会在系统启动时看到如下警告:
dclocal_read_repair_chance table option has been deprecated and will be removed in version 4.0
04 现在就舍弃读修复吧 如果你使用的是4.0版本以前的Cassandra集群,下方代码可关闭异步读修复功能:
cqlsh -e 'ALTER TABLE <keyspace_name>.<table_name> WITH read_repair_chance = 0.0 AND dclocal_read_repair_chance = 0.0;'
如果你已经升级到了Cassandra 4.0,那么你无需任何额外操作,因为读修复相关的设置已经被忽略和删除了。
标签:repair,副本,修复,舍弃,read,特性,chance,节点 来源: https://www.cnblogs.com/datastax/p/14383779.html