SOTA集结,2020登顶关系抽取的3篇佳作
作者:互联网

在开始学习之前推荐大家可以多在 FlyAI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
摘要: 2020实体关系联合抽取一片红海,各种SOTA方法你方唱罢我方登场,在一些数据集上也是不断刷出新高度,为信息抽取领域带来了新思路,推动了信息抽取领域的发展。本文梳理了实体关系联合抽取取得SOTA的三种方法,以做总 ...
2020实体关系联合抽取一片红海,各种SOTA方法你方唱罢我方登场,在一些数据集上也是不断刷出新高度,为信息抽取领域带来了新思路,推动了信息抽取领域的发展。本文梳理了实体关系联合抽取取得SOTA的三种方法,以做总结。

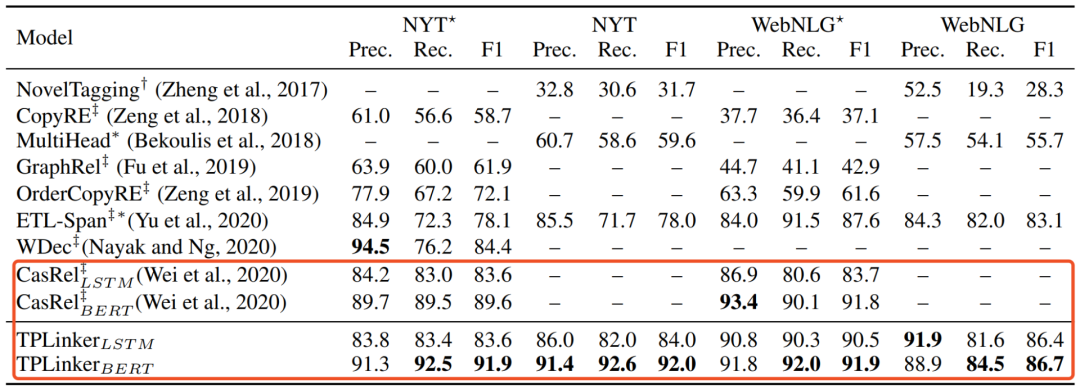
先总体对三种方法做个比较:*表示Exact Matching

以下将对上面提到的三篇文章依次进行详细解读。
CasRel
论文:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
地址:https://arxiv.org/abs/1909.03227
2019年的时候看到苏剑林在paperweekly上的一篇文章,阐述了其在参加百度SPO竞赛中所使用的方法,这篇论文可以认为是之前所提方法的延伸。
论文提出级联二分标记框架CasRel方法(a novel cascade binary tagging framework),与以往把关系看着离散标签不同,这里把关系看着是一个函数fr(sub)->obj,头实体sub是自变量,尾实体obj是因变量,先抽取出头实体,然后结合各关系类型,进一步抽取出对应的尾实体。该方法可以解决实体关系中的EPO/SEO实体重叠问题。结合模型框架图更好理解:

CasRel模型可以分两部分理解:
编码部分:采用Bert进行编码,输入subword embedding + position embedding
Cascade解码(级联解码):先对subject实体进行抽取(subject tagger),然后对每一种关系,进一步去抽取该关系下subject所对应的object实体(relation-specific object tagger)。
subject实体抽取:直接在Bert编码后进行span解码,得到实体的start和end位置,如图示,对每个token位置做二分类,判断是否为start位,或者是否为end位。注意:在解码的时候,start和end配对可以采用就近原则得到实体

特定关系下的object实体抽取:结合上图示,obj实体解码类似于sub的解码,需要注意两点:一是对每种关系都要做obj解码,二是obj的解码中引入了上一步中所得到的sub实体的信息Vsub,Vsub是对sub实体中各token向量求平均。当start_o和end_o经过二分判断都为0时,表示该关系下没有对应的obj实体,也即该sub为头实体时不存在这个关系的三元组。
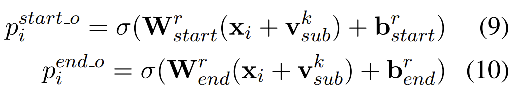
优化目标及模型损失函数:目标是较大化三元组抽取概率,sub和obj的抽取都是采用span方式,可采用二分交叉熵计算loss。优化目标公式如下:
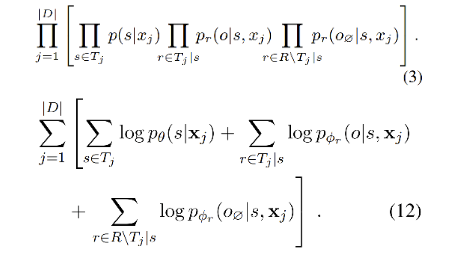
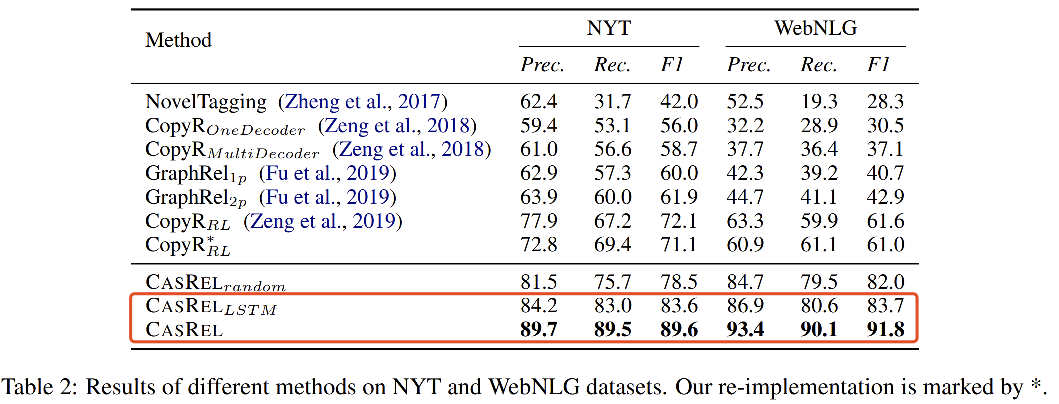
实验结果
在NYT和WebNLG两个数据集上达到了SOTA,如下图所示,即使不使用Bert进行编码(使用LSTM)效果依然是十分显著的。实验同时对比了句子中不同三元组数目下的结果,以及Normal、EPO和SEO三种情况下的结果,实验显示CasRel方法在多三元组、EPO和SEO情况下效果提升更明显。
总结:
级联两个任务,两个任务独立解码,共享编码,这种模型架构也可以算到多任务学习的范畴,模型先抽取出sub实体,再在各个relation下去抽sub实体对应的obj实体,把relation看成函数,模型整体架构很清晰,特别是在relation纬度上做堆叠,打开了关系抽取的新思路。
TPLinker
论文:TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
地址:https://arxiv.org/abs/2010.13415
这篇文章提出TPLinker方法(Token Pair Linking)能够end2end对实体及实体关系三元组进行联合抽取,可解决实体关系抽取中的SEO、EPO、实体嵌套等问题。其设计了一种很巧妙的数据标注方式,被称为Handshaking tagging scheme,这种标注统一了实体及实体关系的信息,同时避免了以往其他方法中普遍存在的标签曝光偏差问题(exposure bias)(训练阶段标签使用ground true,推断阶段标签使用predict tag)。
Handshaking tagging scheme: 个人感觉文中所给图示(下图)其实不太好理解,从具体例子出发会更方便理解的。

为长度为n的句子,构造nxn的矩阵M,行、列分别对应着句子中的token,针对句子中的实体及实体关系设计三种标注方式:
entity head to entity tail (EH-to-ET): 对每个实体,将它的头token(行)对应的尾token(列)位置标记为1,反应在M的上三角上,如所给例子实体:New York City ==> M(New, City) = 1, De Blasio ==> M(De, Blasio) =1,上图中紫色背景。
subject head to object head (SH-to-OH): 对每个关系下的实体对,将首实体(sub)的头token(行)对应到尾实体(obj)的头token(列),如所给例子关系mayor实体对:(New York City, De Blasio) ==> M(New, De),上图中红色背景。
subject tail to object tail (ST-to-OT): 对每个关系下的实体对,将首实体(sub)的尾token(行)对应到尾实体(obj)的尾token(列),如所给例子关系mayor实体对:(New York City, De Blasio) ==> M(City, Blasio),上图中蓝色背景。
注意:EH-to-ET只会存在M的上三角,而SH-to-OH和ST-to-OT是上下三角都会存在的,为了节省存储资源,同时减少目标tag的稀疏性(还是很稀疏),将M的下三角映射到上三角上,值设置为2。(考虑上三角映射的位置上会不会不为0呢,是会存在这种可能的,但现实中概率很低,如triple (ABC, R, CDE)和(CDE, R, BC))
上面将三元组中的实体信息映射到矩阵上三角,然后将其展平为标记序列,可以得到序列的长度为n*(n+1)/2。如果有N中关系,则经过Handshaking tagging后,得到2N+1个标记序列。
解码方式:
先不用去看下面所给的解码图示,考虑上面讲到的Handshaking tagging作为模型的预测目标,实际上是2N+1个n*n的矩阵,矩阵的元素为句子各token对的关系,其值为0、1、2。其中一个矩阵标记了实体EH-to-ET,N个矩阵标记了SH-to-OH,N个矩阵标记了ST-to-OT。文章给出了一个解码的算法流程,不再贴出,简述过程如下:

解码EH-to-ET可以得到句子中所有的实体,用实体头token idx作为key,实体作为value,存入字典D中
对每种关系r,解码ST-to-OT得到token对存入集合E中,解码SH-to-OH得到token对并在D中关联其token idx的实体value
对上一步中得到的SH-to-OH token对的所有实体value对,在集合E中依次查询是否其尾token对在E中,进而可以得到三元组信息。
相关公式:
模型编码可以是LSTM也可以是Bert,Token Pair表示为公式(1),Handshaking Tagger可以看着是多分类,公式为(2),损失函数定义为公式(4):
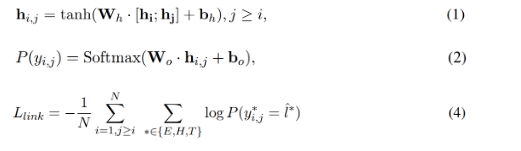
实验结果:
同样在NYT和WebNLG两个数据集上进行实验,延续CasRel的实验结果,TPLinker方法达到了新的SOTA,同时通过进一步细化实验分析得到以下结论:
句子中triple数目大于5的时候,TPLinker方法优势更加明显
在实体关系标注中只标注实体尾token,和标注实体span相比,并没有简化问题
得益于解码的高效性,TPLinker推断性能相对于CasRel有极大提升
总结:
创新性地提出了Handshaking tagging方式,统一了实体与实体关系信息,使得模型能够一次解码得到三元组信息
能够解决实体关系中的实体重叠EPO、SEO问题,受益于EH-to-ET标记,模型同时能够解决嵌套实体问题
end2end得到实体及实体关系,避免了标签暴露偏差的问题
SPN4RE
论文:Joint Entity and Relation Extraction with Set Prediction Networks
地址:https://arxiv.org/abs/2011.01675
这篇文章出至中科院刘康老师团队,是目前NYT和WebNLG数据集上的SOTA。论文将实体关系联合抽取归纳为三种范式,分别为:
end2end抽取实体及关系(as table filling problem),编码层共享参数,解码层独立解码
转化为序列标注问题,需要设计复杂的tagging scheme,即每个tag需要同时表示实体及关系的信息(之前的方案无法应对嵌套、重叠实体)
转化为seq2seq问题,解码时生成三元组(多次生成可解决嵌套、重叠实体(autoregressive decoder and cross-entropy loss))
实际上,第一种也可以看着是多任务学习,第二种在TPLinker方法中已经比较好地解决了实体重叠和嵌套问题,论文认为所提出的SPN4RE属于seq2seq范畴,通读下来笔者窃以为也可将SPN4RE归为实体关系联合抽取中的多任务学习。
论文的初衷是在以往使用seq2seq解决实体关系三元组时,面临三元组生成顺序对结果产生影响,所以从生成顺序无关三元组、并行生成三元组集合出发提出新的模型SPN。
SPN(set prediction networks)包含了三个部分:
句子编码:采用预训练语言模型Bert,BPE编码输入
三元组集合生成:基于transformer的非自回归解码NAT(transformer-based non-autoregressive decoder)
并行产生三元组,产生三元组顺序无关,加速解码,NAT结构使用到了双向信息
NAT条件概率公式:j!=i说明第j个triple和其他triple也是有关系的,n为三元组个数,本文设置为常数m

基于集合的Loss设计:二部图匹配损失函数(bipartite matching loss function)
NAT结构解码:
输入m表示要解码的triple个数,N个transformer层,每层先是各triple间做self-attention,然后是和sentence的编码做inter-attention,输出解码向量为Hd,其为m*d纬度
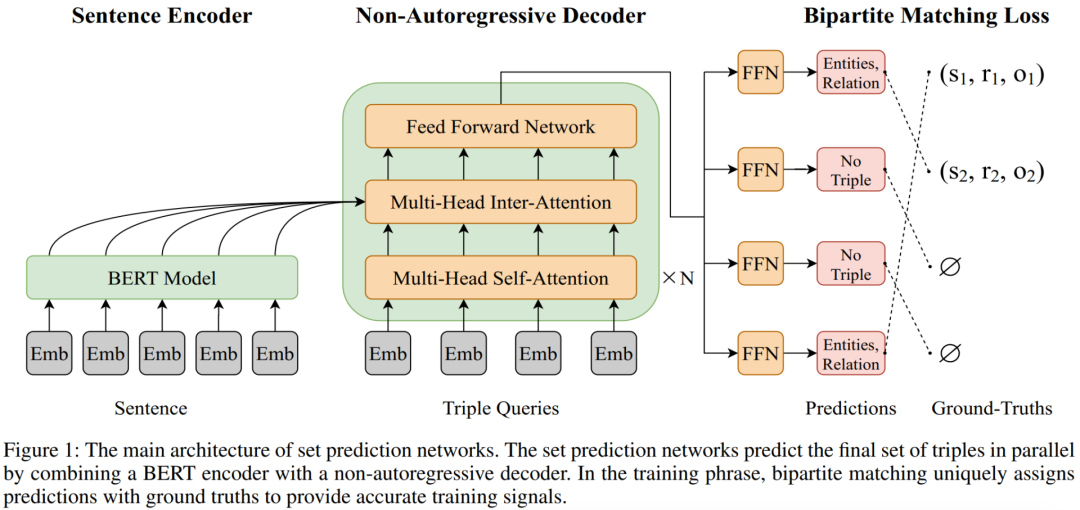
关系预测:对每个hd过FFN经过softmax,预测「关系」,关系数量为总关系量+1(包含了null),公示如下:

关系首尾实体预测:类似与对sentence做span,融合了sentence编码和对应关系的编码,公式如下:

二部图匹配损失函数(Bipartite Matching Loss):在预测的三元组集合和ground true三元组集合间计算loss
两个集合的元素进行最优匹配:预测的集合大小为m,如果ground true集合小于m则补充null至大小为m。寻找最优匹配的过程,实际上相当于对m个人分配m个任务,第i个人做第j个任务的代价为Cij,寻找最优方式将这m个任务分配给m个人,使得总代价最小,这就是二部图匹配问题,可以利用匈牙利算法求解,时间复杂度为O(m^3)。本文定义代价函数如下:

损失函数定义:对最优匹配得到的m个三元组对计算loss,注意,如果「关系」为null,则关系中的头尾实体不参与loss计算,Loss函数定义如下:
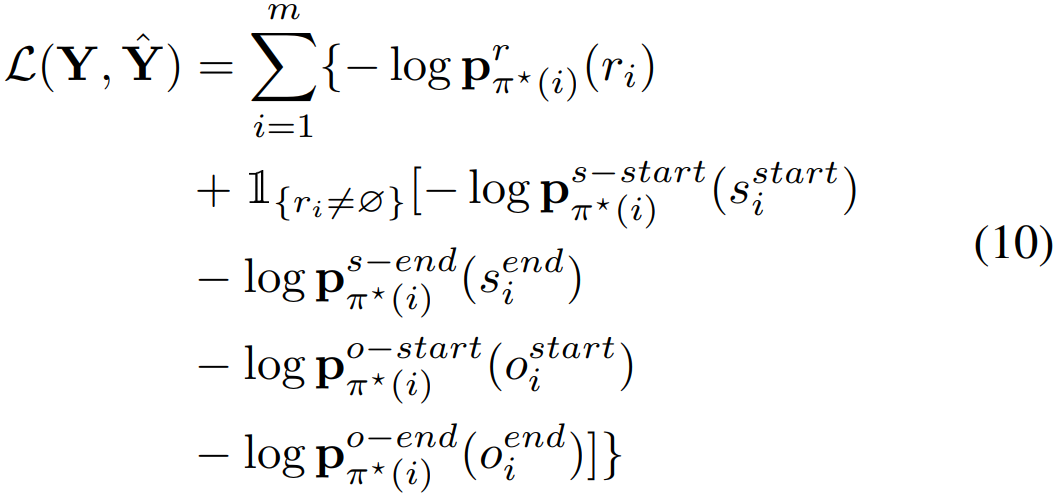
实验结果:
在NYT和WebNLG数据集上进行实验,结果如下图,提出并回答了以下四个问题:

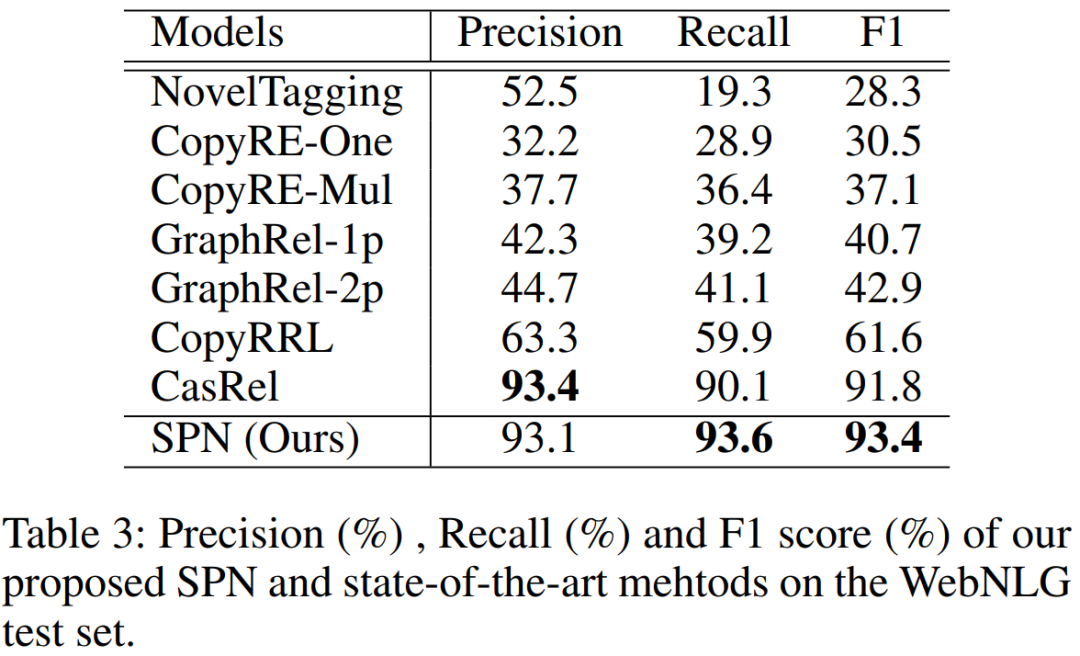
联合抽取模型SPN的整体性能如何:对比CasRel F1在NYT上提升2.9%,在 WebNLG上提升1.6%(图略)
模型中每个设计对结果的影响:通过消融实验,对比了交叉熵loss和二部图匹配loss,以及非自回归解码层数对结果的影响,得到了NAT层数为3时最优,二部图匹配Loss优于交叉熵Loss(图略)
数据中存在不同数量的三元组对性能的影响:数据中三元组数量越多(信息越复杂),对比其他方法SPN的效果越显著(图略)
该方法在解决重叠模式问题上性能如何(EPO, SEO):和其他方法对比了Normal、SEO、EPO三种triple类型下效果,结论同上一条一致,在复杂问题上(SEO, EPO),相比与其他方法SPN效果显著(图略)
总结:
对NAT解码的结果做关系预测,可看着是分类问题,然后将解码结果进一步融合编码信息对句子做实体抽取,可看着实体span解码过程,所以笔者认为该方法也属于联合抽取中的多任务学习
采用二部图匹配,寻找最优三元组匹配的过程复杂度O(m^3),先匹配再计算Loss为集合纬度的Loss计算提供了参考。
以上对实体关系联合抽取三篇SOTA文章进行了分析解读,在实际的工作当中,我们也已经将CasRel方法进行落地实践,并取得了一定的效果。在实体抽取任务中,也可以借鉴TPLinker的标记方法,解决嵌套实体问题。SPN作为的SOTA,其所涉及的NAT解码和在集合纬度上的Loss计算也值得借鉴参考。


标签:关系,抽取,登顶,SOTA,解码,实体,三元组,token,2020 来源: https://blog.csdn.net/iFlyAI/article/details/113175283