什么是耦合和解耦
作者:互联网
什么是耦合、解耦
一、耦合
1、耦合是指两个或两个以上的体系或两种运动形式间通过相互作用而彼此影响以至联合起来的现象。 2、在软件工程中,对象之间的耦合度就是对象之间的依赖性。对象之间的耦合越高,维护成本越高,因此对象的设计应使类和构件之间的耦合最小。 3、分类:有软硬件之间的耦合,还有软件各模块之间的耦合。耦合性是程序结构中各个模块之间相互关联的度量。它取决于各个模块之间的接口的复杂程度、调用模块的方式以及哪些信息通过接口。二、解耦
1、解耦,字面意思就是解除耦合关系。 2、在软件工程中,降低耦合度即可以理解为解耦,模块间有依赖关系必然存在耦合,理论上的绝对零耦合是做不到的,但可以通过一些现有的方法将耦合度降至最低。 3、设计的核心思想:尽可能减少代码耦合,如果发现代码耦合,就要采取解耦技术。让数据模型,业务逻辑和视图显示三层之间彼此降低耦合,把关联依赖降到最低,而不至于牵一发而动全身。原则就是A功能的代码不要写在B的功能代码中,如果两者之间需要交互,可以通过接口,通过消息,甚至可以引入框架,但总之就是不要直接交叉写。 4、观察者模式:观察者模式存在的意义就是「解耦」,它使观察者和被观察者的逻辑不再搅在一起,而是彼此独立、互不依赖。比如网易新闻的夜间模式,当用户切换成夜间模式之后,被观察者会通知所有的观察者「设置改变了,大家快蒙上遮罩吧」。QQ消息推送来了之后,既要在通知栏上弹个推送,又要在桌面上标个小红点,也是观察者与被观察者的巧妙配合。图解7种耦合关系
原文网址:http://yanhaijing.com/program/2016/09/01/about-coupling/
之前组内同学问我耦合的关系,我没给对方讲清楚,今天借这个机会来深入讲讲模块之间的耦合关系这个事情。
本文将用图文详细讲解七种耦合的不同之处。
高内聚与低耦合
高内聚与低耦合是每个软件开发者追求的目标,那么内聚和耦合分别是什么意思呢?
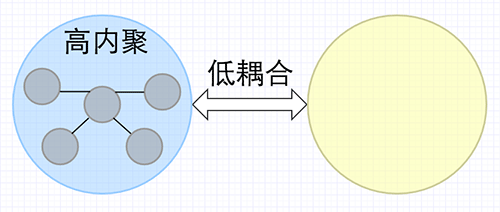
内聚是从功能角度来度量模块内的联系,一个好的内聚模块应当恰好做一件事。它描述的是模块内的功能联系。
耦合是软件结构中各模块之间相互连接的一种度量,耦合强弱取决于模块间接口的复杂程度、进入或访问一个模块的点以及通过接口的数据。
耦合
不同模块之间的关系就是耦合,根据耦合程度可以分为7种,耦合度依次变低。
- 内容耦合
- 公共耦合
- 外部耦合
- 控制耦合
- 标记耦合
- 数据耦合
- 非直接耦合
下面我们来说说每种耦合是什么,开始之前先来说下要实现的功能。m1和m2是两个独立的模块,其中m2种会显示m1的输入,m1会显示m2的输入。
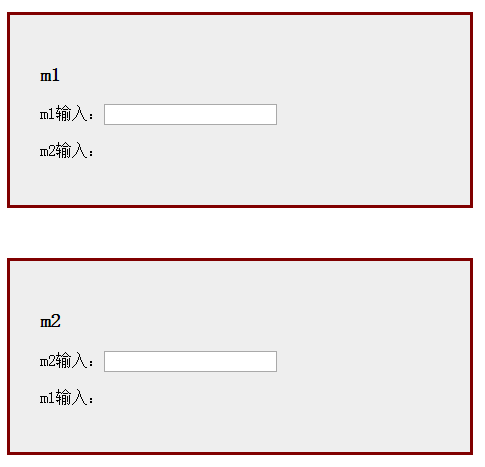
很显然,m1和m2两个模块之间会有一些联系(耦合),你也可以想想如何实现这个功能,下面用7种不同的方式来实现这个功能。
注:项目的代码我放到了github,项目的demo,可以在这里查看。
内容耦合
如果发生下列情形,两个模块之间就发生了内容耦合。 一个模块直接访问另一个模块的内部数据; 一个模块不通过正常入口转到另一模块内部; 两个模块有一部分程序代码重叠(只可能出现在汇编语言中); 一个模块有多个入口。 在内容耦合的情形,所访问模块的任何变更,或者用不同的编译器对它再编译, 都会造成程序出错。好在大多数高级程序设计语言已经设计成不允许出现内容 耦合。它一般出现在汇编语言程序中。这种耦合是模块独立性最弱的耦合。内容耦合是最紧的耦合程度,一个模块直接访问另一模块的内容,则称这两个模块为内容耦合。
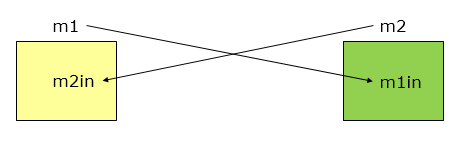
为了实现功能,我们将m1的输入放到m2.m1input上,将m2的输入放到m1.m2input上。
// m1.js
root.m2.m1input = this.value;
m2.update();
// m2.js
root.m1.m2input = this.value;
m1.update();
PS:不知道谁会这么写代码,除了我为了做演示之外。。。
公共耦合
若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。 这种耦合会引起下列问题: 所有公共耦合模块都与某一个公共数据环境内部各项的物理安排有关,若修改某个数据的大小,将会影响到所有的模块。 无法控制各个模块对公共数据的存取,严重影响软件模块的可靠性和适应性。 公共数据名的使用,明显降低了程序的可读性。 公共耦合的复杂程度随耦合模块的个数增加而显著增加。若只是两个模块之间有公共数据环境,则公共耦合有两种情况。 若一个模块只是往公共数据环境里传送数据,而另一个模块只是从公共数据环境中取数据,则这种公共耦合叫做松散公共耦合。若两个模块都从公共数据环境中取数据,又都向公共数据环境里送数据,则这种公共耦合叫做紧密公共耦合。只有在模块之间共享的数据很多,且通过参数表传递不方便时,才使用公共耦合。否则,还是使用模块独立性比较高的数据耦合好些。一组模块都访问同一个全局数据结构,则称之为公共耦合。
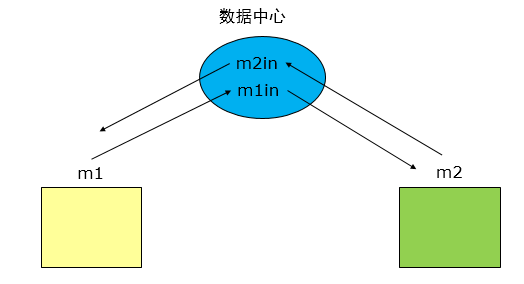
在这种case中,m1和m2将自己的输入放到全局的data上。
// m1.js
root.data.m1input = this.value;
m2.update();
// m2.js
root.data.m2input = this.value;
m1.update();
外部耦合
一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息,则称之为外部耦合。例如C语言程序中各个模块都访问被说明为extern类型的外部变量。外部耦合引起的问题类似于公共耦合,区别在于在外部耦合中不存在依赖于一个数据结构内部各项的物理安排。
一组模块都访问同一全局简单变量,而且不通过参数表传递该全局变量的信息,则称之为外部耦合。外部耦合和公共耦合很像,区别就是一个是简单变量,一个是复杂数据结构。
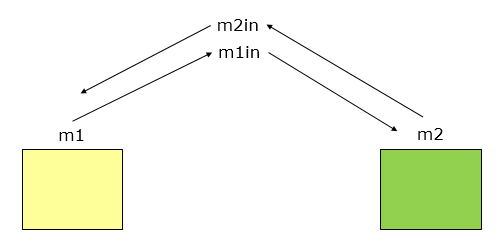
在这种case中,m1和m2都将自己的输入放到全局上。
// m1.js
root.m1input = this.value;
m2.update();
// m2.js
root.m2input = this.value;
m1.update();
控制耦合
如果一个模块通过传送开关、标志、名字等控制信息,明显地控制选择另一模块的功能,就是控制耦合。这种耦合的实质是在单一接口上选择多功能模块中的某项功能。因此,对所控制模块的任何修改,都会影响控制模块。另外,控制耦合也意味着控制模块必须知道所控制模块内部的一些逻辑关系,这些都会降低模块的独立性。
模块之间传递的不是数据信息,而是控制信息例如标志、开关量等,一个模块控制了另一个模块的功能。
从控制耦合开始,模块的数据就放在自己内部了,不同模块之间通过接口互相调用。
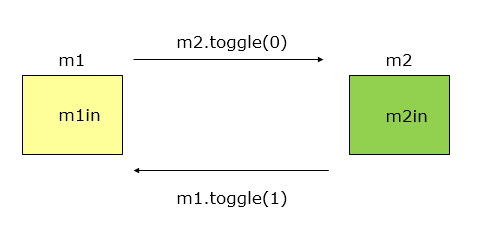
在这个case中,得增加一个需求,就是当m1的输入为空时,隐藏m2的显示信息。
// m1.js
root.m1input = this.value;
m2.update();
m2.toggle(!!this.value); // 传递flag
上面的代码中m1直接控制了m2的显示和隐藏。
标(印)记耦合
如果一组模块通过参数表传递记录信息,就是标记耦合。事实上,这组模块共享了这个记录,它是某一数据结构的子结构,而不是简单变量。这要求这些模块都必须清楚该记录的结构,并按结构要求对此记录进行操作。在设计中应尽量避免这种耦合,它使在数据结构上的操作复杂化了。如果采取“信息隐蔽”的方法,把在数据结构上的操作全部集中。
调用模块和被调用模块之间传递数据结构而不是简单数据,同时也称作特征耦合。
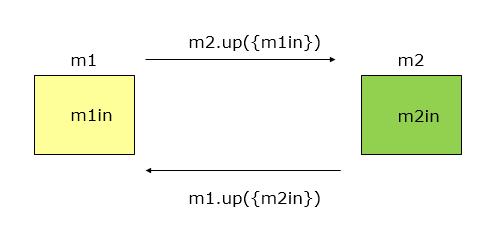
在这个case中,m1传给m2的是一个对象。
// m1.js
me.m1input = this.value;
m2.update(me); // 传递引用
// m2.js
me.m2input = this.value;
m1.update(me);
数据耦合
如果一个模块访问另一个模块时,彼此之间是通过数据参数(不是控制参数、公共数据结构或外部变量)来交换输入、输出信息的,则称这种耦合为数据耦合。由于限制了只通过参数表传递数据,按数据耦合开发的程序界面简单、安全可靠。因此,数据耦合是松散的耦合,模块之间的独立性比较强。在软件程序结构中至少必须有这类耦合。
调用模块和被调用模块之间只传递简单的数据项参数。相当于高级语言中的值传递。
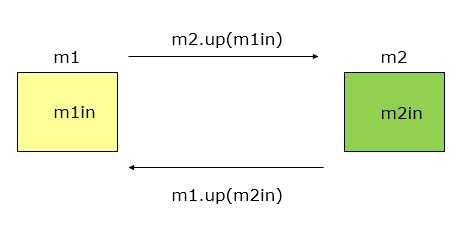
在这个case中,m1传给m2的是一个简单数据结构。
// m1.js
me.m1input = this.value;
m2.update(me.m1input); // 传递值
// m2.js
me.m2input = this.value;
m1.update(me.m2input);
非直接耦合
两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的。耦合度最弱,模块独立性最强。
子模块无需知道对方的存在,子模块之间的联系,全部变成子模块和主模块之间的联系。
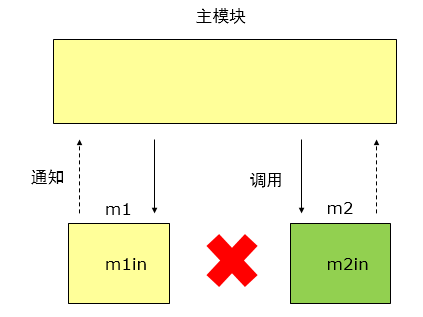
在这个case种,增加一个index.js作为主模块。
// index.js
var m1 = root.m1;
var m2 = root.m2;
m1.init(function (str) {
m2.update(str);
});
m2.init(function (str) {
m1.update(str);
});
// m1.js
me.m1input = this.value;
inputcb(me.m1input); // inputcb是回调函数
// m2.js
me.m2input = this.value;
inputcb(me.m2input);
内聚
其实关于内聚也分为很多种,如下所示,如果你感兴趣可以自己研究研究,我们下次再来分享内聚的问题。
- 偶然内聚
- 逻辑内聚
- 时间内聚
- 通信内聚
- 顺序内聚
- 功能内聚
原文网址:http://yanhaijing.com/program/2016/09/01/about-coupling/
什么是解耦
解耦:假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
因为太抽象,看过网上的说明之后,通过我的理解,我举了个例子:吃包子。
假如你非常喜欢吃包子(吃起来根本停不下来),今天,你妈妈(生产者)在蒸包子,厨房有张桌子(缓冲区),你妈妈将蒸熟的包子盛在盘子(消息)里,然后放到桌子上,你正在看巴西奥运会,看到蒸熟的包子放在厨房桌子上的盘子里,你就把盘子取走,一边吃包子一边看奥运。在这个过程中,你和你妈妈使用同一个桌子放置盘子和取走盘子,这里桌子就是一个共享对象。生产者添加食物,消费者取走食物。桌子的好处是,你妈妈不用直接把盘子给你,只是负责把包子装在盘子里放到桌子上,如果桌子满了,就不再放了,等待。而且生产者还有其他事情要做,消费者吃包子比较慢,生产者不能一直等消费者吃完包子把盘子放回去再去生产,因为吃包子的人有很多,如果这期间你好朋友来了,和你一起吃包子,生产者不用关注是哪个消费者去桌子上拿盘子,而消费者只去关注桌子上有没有放盘子,如果有,就端过来吃盘子中的包子,没有的话就等待。
原文:https://www.jianshu.com/p/5543b2eee223标签:和解,什么,内聚,js,m1,模块,m2,耦合 来源: https://www.cnblogs.com/zhj868/p/14221560.html