论文记载: Deep Reinforcement Learning for Traffic LightControl in Vehicular Networks
作者:互联网
强化学习论文记载
论文名: Deep Reinforcement Learning for Traffic LightControl in Vehicular Networks ( 车辆网络交通信号灯控制的深度强化学习 )---年份:2018.3
主要内容:
文献综述载于第二节。模型和问题陈述将在第三节介绍。第四节介绍了强化学习的背景,第五节介绍了在车辆网络交通灯控制系统中建立强化学习模型的细节。第六节将强化学习模型扩展为深度学习模型,以处理我们系统中的复杂状态。该模型的评估载于第七节。最后,论文的结论在第八节。
Introduction:
- 提出了一种深度强化学习模型来控制交通信号灯的模型。在模型中,通过收集数据并将整个交叉路口划分为小网格,将
复杂的交通场景看作为状态,交通信号灯的时间变化看作是动作,这些动作被建模为高维度马尔可夫决策过程。奖励是两个周期之间的累积等待时间差。为解决模型,采用卷积神经网络将状态映射为奖励。所提出的模型由提高性能的几个组件组成,例如dueling network, target network, double Q-learning network,和prioritized experience replay。我们通过在车辆网络中的城市机动性仿真(SUMO)中通过仿真对模型进行了评估,仿真结果表明了该模型在控制交通信号灯方面的有效性。
Literature review:
-
为了实现这样一个系统,我们需要“眼睛”来观察实时的道路状况,“大脑”来处理它。对于前者,传感器和网络技术的最新进展,使实时交通信息作为输入,如车辆数量、车辆位置、车辆等待时间。对于“大脑”部分,作为一种机器学习技术,强化学习是解决这一问题的一种有前途的方法。强化学习系统的目标是使行动主体在与环境的交互中学习最优策略,以获得最大的奖励。
-
现有的研究主要存在两个局限性:(1)交通信号通常被划分为固定的时间间隔,绿灯/红灯的持续时间只能是这个固定时间间隔的倍数,在很多情况下效率不高;(2)交通信号是随机变化的,这对司机来说既不安全也不舒适。
-
文献综述载于第二节。模型和问题陈述将在第三节介绍。第四节介绍了强化学习的背景,第五节介绍了在车辆网络交通灯控制系统中建立强化学习模型的细节。第六节将强化学习模型扩展为深度学习模型,以处理我们系统中的复杂状态。该模型的评估载于第七节。
Model and problem statement:
- 在这篇论文中,我们考虑了一个用交通灯来控制交通流的十字路口场景。模型如图1所示。左边是交通灯的结构。交通灯首先通过车辆网络采集道路交通信息,如图中紫色虚线所示。交通灯对数据进行处理,获得道路交通的状态和奖励,这是很多前人研究所假设的。红绿灯根据当前状态和奖励选择一个行动,使用深度神经网络显示在右侧。
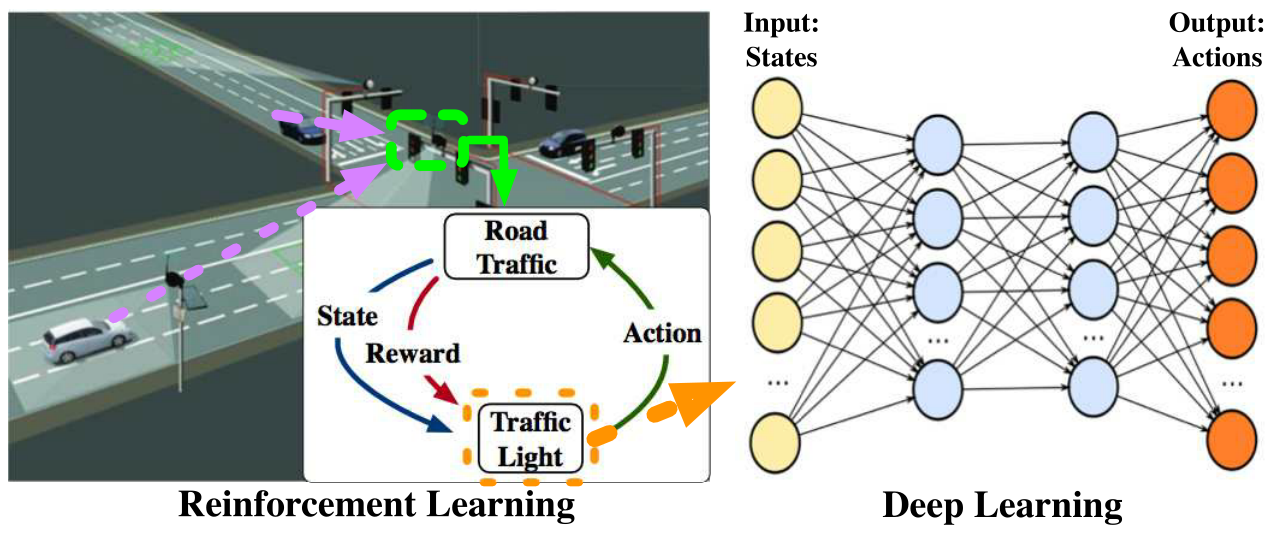
- 本系统中的交通灯控制模型。左侧为交叉口场景,交通灯通过车载网络采集车辆信息,并由强化学习模型控制;右边显示的是一个深度神经网络,帮助红绿灯选择一个动作。
- 在我们的模型中,交通灯被用来管理交叉路口的交通流量。十字路口的交通灯有三种信号,绿、黄、红。当一个十字路口有来自多个方向的车辆时,一个红绿灯可能不足以管理所有的车辆。因此,在一个多方向交叉路口,多个交通灯需要相互配合。在这种交叉路口,交通信号通过改变交通灯的状态,引导车辆一次从非冲突方向行驶。一种状态是只用交通信号灯的红绿信号,忽略黄信号,的合法组合。停留在一种状态的持续时间称为
一个阶段。信号灯的相位就是针对不同方向的交通流,给予相应的放行的时间,就是相位。相位的数量是由十字路口的法定状态的数量决定的。所有相位以固定的顺序循环变化,引导车辆通过交叉口。当各阶段重复一次时,称为一个周期。一个周期的相位序列是固定的,但每个相位的持续时间是自适应的。如果一个阶段需要被跳过,它的持续时间可以设置为0秒。在这个问题中,我们动态地调整每个阶段的持续时间,以应对不同的交通情况。 - 我们的问题是如何通过学习历史经验动态地改变交通信号灯的每一阶段的持续时间来优化交叉口的使用效率。一般的想法是延长在那个方向有更多车辆的阶段的持续时间。
Background on reinforcement learning:
- 强化学习的背景就不说了
Reinforcement learning model:
- 为了建立一个使用强化学习的交通信号灯控制系统,我们需要定义状态、行动和奖励。在本节的提醒中,我们将介绍如何在我们的模型中定义这三个元素。
状态States:
- 我们定义的状态是基于两条信息,车辆在十字路口的位置和速度。通过车辆网络,可以得到车辆的位置和速度。然后交通灯提取出当前交叉口的虚拟快照图像。整个交点被分割成大小相同的小正方形网格。网格的长度
c应保证同一网格中不能容纳两辆车,并且可以将一整辆车放入一个网格中以减少计算量。在我们的系统中c的值将在评估中给出。在每个网格中,状态值为车的二值向量<位置,速度>。位置维度是一个二进制值,表示网格中是否有车辆。如果网格中有车辆,网格中的值为1;否则,它是0。速度维数为整数值,表示车辆当前的速度,单位为m/s。 - 以图2为例,说明如何量化来获得状态值。图2(a)是用车辆网络中的信息构建的简单单线四向交叉口交通状态快照。交叉点被分割成正方形的网格。位置矩阵具有相同网格尺寸,如图2(b)所示。在矩阵中,一个十字路口对应图2(a)中的一个网格。空白单元格表示对应网格中没有车辆,为0。其他内部有车辆的单元被设置为1.0。速度维度中的值是以类似的方式构建的。如果网格中有车辆,对应的值为车辆的速度;否则,它是0。


动作Action:
-
交通灯需要根据当前的交通状态选择合适的动作来很好地引导交叉口的车辆。在这个系统中,通过选择
下一个周期中的每个阶段的持续时间来定义动作空间。但如果两个周期的持续时间变化很大,系统可能会变得不稳定。因此,当前状态下的法律阶段期限应平稳变化。我们将两个相邻周期之间合法阶段的持续时间变化建模为一个高维的MDP模型。在该模型中,交通灯在一小步内只改变一个阶段的持续时间。 -
十字路口分为南北绿、东南和西北绿、东西绿、东北和西南绿,四个阶段。其他未提及的方向默认为红色。让我们在这里忽略黄色信号,稍后将介绍它。设< t1, t2, t3, t4>的四元组表示当前周期四个阶段的持续时间。
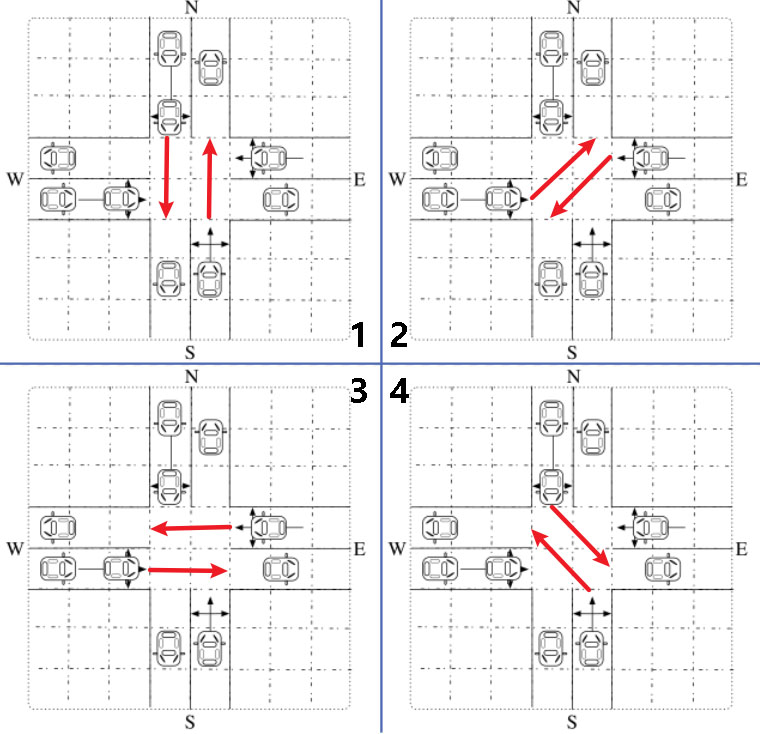
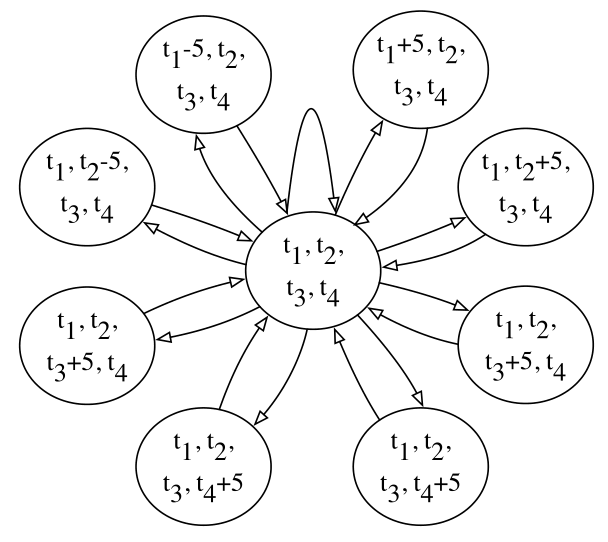
-
下一个周期的法律行为如图3所示。在图中,一个圆表示一个周期内四个阶段的持续时间。我们将从当前周期到下一个周期的时间变化离散为5秒。下一个周期中一个且只有一个阶段的持续时间是当前持续时间加或减5秒。在下一个循环中选择阶段的持续时间后,当前的持续时间成为被选择的时间。红绿灯可以以类似于前面步骤的方式选择一个动作。此外,我们将一个阶段的最大合法持续时间设置为60秒,最小的为0秒。
-
MDP是一种灵活的模式。它可以应用于有更多交通灯的更复杂的十字路口,这需要更多的阶段,如五、六路的不规则十字路口。当相交处有更多阶段时,它们可以作为高维值添加到MDP模型中。MDP中圆的尺寸等于交点处的阶段数。
-
红绿灯的相位按顺序周期性地变化。为了保证安全,相邻两个相位之间需要有黄色信号,这可以让行驶中的车辆在信号变成红色之前停下来。黄色信号的持续时间是由道路的最大速度$$v_{max}$$除以最常见的减速的加速度$$a_{dec}$$定义的。这意味着行驶中的车辆需要这么长的时间才能在十字路口前稳稳停车。
奖励Rewards
- 奖励是区分强化学习和其他学习算法的一个因素。奖励的作用是为强化学习模型提供关于之前行为表现的反馈。因此,定义奖励对正确指导学习过程是很重要的,这有助于采取最佳的行动政策。
- 在我们的系统中,主要的目标是提高交叉的效率。衡量效率的一个主要指标是车辆的等待时间。因此,我们将奖励定义为两个相邻周期的累积等待时间的变化。
- 设\(i_t\)为从开始时刻到\(t^{th}\)周期开始的时刻第\(i^{th}\)辆观测到的车,\(N_t\)表示到\(t^{th}\)周期为止对应的车辆总数。车辆\(i\)到第\(t^{th}\)周期的等待时间用\(w_{i_t,t}\)表示,(1≤\(i_t\)≤\(N_t\))。\(t^{th}\)阶段中的奖励由以下方程式定义:
- 这意味着奖励等于行动之前和行动之后累积等待时间的增量。如果奖励变大,等待时间的增量就变少。考虑到
delay(等待时长)不随时间而减少,总体奖励总是非正的。
Double dueling deep q network:
- 直接求解图(2)有很多实际问题,如要求状态是有限的。在车辆网络中的交通灯控制系统中,状态数过大。因此,在本文中,我们提出了卷积神经网络来近似\(Q\)值。结合最新的技术,提出的整个网络称为Double Dueling Deep Q Network (3DQN).
Convolutional Neural Network:
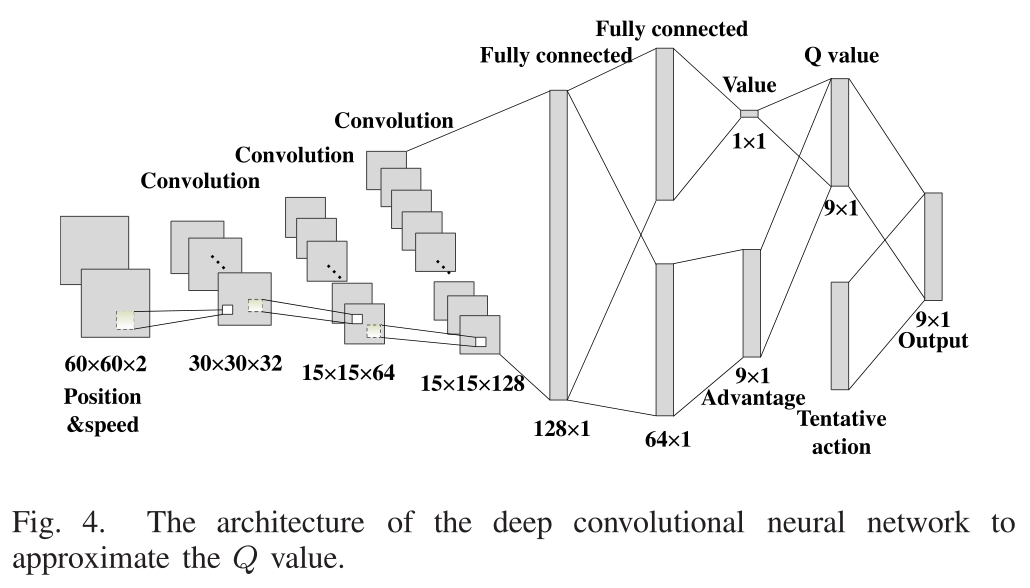
- 本文提出的CNN的架构如图4所示。它由三个卷积层和几个完全连接的层组成。在我们的系统中,输入的是包含车辆位置和速度信息的小网格。十字路口的网格数为60×60。输入数据变为60×60×2,同时包含位置和速度信息。数据首先经过三个卷积层。每个卷积层包括卷积、池化和激活三个部分。卷积层包括多个滤波器。每个过滤器都包含一组权值,它聚合上一层的局部块,并且每次移动由步幅定义的固定步长。不同的过滤器有不同的权值来在下一层生成不同的特征。卷积运算使模式的存在比模式的位置更重要。池化层从局部单位补丁中选择特征值,以替换整个补丁。池化过程去掉了不太重要的信息,并降低了维数。激活函数是决定一个单位如何被激活。最常见的方法是在输出上应用非线性函数。在本文中,我们使用漏的ReLU作为激活函数,其形式如下(让x表示一个单位的输出):
-
\(β\)是一个小常数,以避免零梯度在负侧。漏泄的ReLU比其他激活函数(如tanh和sigmoid)收敛得更快,并防止常规ReLU产生“死亡”神经元,也就是防止出现梯度弥散和梯度爆炸。
-
在该架构中,三个卷积层和全连接层的构造如下。第一个卷积层包含32个滤波器。每个过滤器的大小是4×4,并且每次通过输入数据的全深度移动2×2步。第二层卷积层有64个滤波器。每个滤镜的尺寸是2×2,每次移动2×2步长。经过两个卷积层后的输出大小为15×15×64。第三个卷积层有128个滤波器,尺寸为2×2,步长的大小为1×1。第三个卷积层的输出是一个15×15×128张量。一个完全连通的层将张量转换成一个128×1的矩阵。在全连通层之后,数据被分割成相同大小64×1的两部分。第一部分用于计算价值,第二部分用于获取优势。行动的优势是指采取某项行动比采取其他行动所取得的效果。因为如图3所示,我们的系统中可能的操作数是9,所以优势的大小是9×1。它们再次组合得到\(Q\)值,这就是Double Dueling Deep Q Network 的架构。
-
每个动作对应的\(Q\)值,我们需要高度惩罚可能导致事故或达到最大/最小信号持续时间的违法行为。输出将\(Q\)值和尝试的动作结合起来,迫使红绿灯采取法律行动。最后,我们得到输出中带有惩罚值的每个操作的\(Q\)值。\(CNN\)中的参数用\(θ\)表示。\(Q(s, a)\)现在变成了\(Q(s, a;θ)\),在\(CNN θ\)下进行估计。架构中的细节将在下一小节中介绍。
Dueling DQN
- 如前所述,我们的网络包含一个dueling DQN。在网络中,Q值是根据当前状态的值和每个动作相对于其他动作的优势来估计的。状态\(V (s;θ)\)的值表示在未来步骤中采取概率行动的总体预期回报。优势对应于每一个动作,定义为\(A(s, a;θ)\)。\(Q\)值是状态\(V\)值和动作优势\(A\)值的和,通过下面的方程进行计算:
- \(A(s, a;θ)\)表示一个动作对所有动作中的价值函数有多重要。如果行动的A值是正的,那就意味着与所有可能行动的平均表现相比,该行动在数值奖励方面表现得更好;否则,如果行动的价值是负的,那就意味着行动的潜在奖励低于平均值。结果表明,与直接使用优势值相比,从所有优势值的均值中减去优势值可以提高优化的稳定性。实验结果表明,该算法能够有效地提高强化学习的性能。
Target Network
- 为了更新神经网络中的参数,定义了一个目标值来帮助指导更新过程。设\(Q_{target}(s, a)\)表示采取动作\(a\)时状态\(s\)处的目标\(Q\)值,通过下式中的均方差损失函数(MSE)更新神经网络:
-
式中\(P(s)\)表示训练小批量(mini-batch)中出现状态\(s\)的概率。MSE可以看作是一个损耗函数来指导主网络的更新过程。为了在每次迭代中提供稳定的更新,通常使用独立的目标网络\(θ^−\)生成目标值,该网络与原始神经网络结构相同,但参数不同。在双DQN部分给出了目标Q值的计算。
-
通过公式(8)的反向传播对神经网络中的参数\(θ\)进行更新,\(θ^−\)根据下式中的\(θ\)进行更新:
- α是更新率,表示最新参数对目标网络中各成分的影响程度。目标网络可以有效地解决过乐观值估计问题
Double DQN
- 目标\(Q\)值由double Q-learning算法生成。在double DQN中,目标网络产生目标\(Q\)值,动作由主网络产生。目标\(Q\)值可以表示为:
- 结果表明,双DQN有效地缓解了过高价值估计,并且提高了的性能。
- 此外,我们也使用\(\epsilon-greedy\)算法来平衡在选择行动上的探索和利用
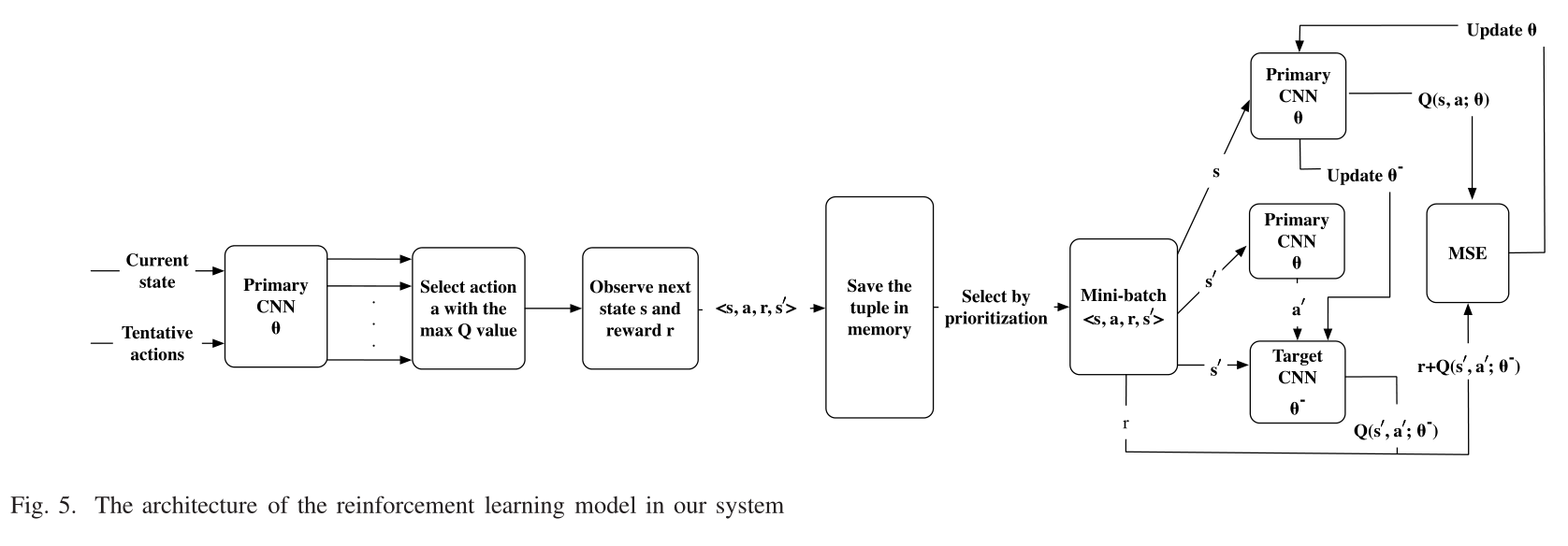
Fig.5 个人的一些理解:
Primary CNN主要用来更新\(Q(s,a;\theta)\)值
Target CNN主要用来更新神经网络中的参数
1》输入当前状态和试探性的动作,经过Primary CNN,更新每个试探性动作的\(Q(s,a;\theta)\)值
2》来选择一个\(Q(s,a;\theta)\)值最大的\(action\)
3》观察下一个状态\(state\)和奖励回报\(reward\)
4》将四元组\(<s,a,r,s'>\)保存到经验池里
5》通过优先级进行选择一个mini-batch的数据
6》一个Primary CNN通过输入均方差损失函数MSE更新后的\(\theta\),来更新\(\theta^-\),并且通过当前状态的s,a,\(\theta\),来获得当前状态的\(Q(s,a;\theta)\)值
7》另一个Primary CNN通过输入下一个状态s',来更新下一个动作a'
7》Target CNN通过输入上述的s',a',\(\theta^-\),来获取\(Q(s',a';\theta^-)\)值
8》 将mini-batch里的r与上述的\(Q(s',a';\theta^-)\)结合获得\(Q_{target}(s,a)\)
9》使用均方差损失函数MSE(\(Q(s,a;\theta)\),\(Q_{target}(s,a)\))来更新神经网络的参数\(\theta\)
- 随着训练步数的增加,\(\epsilon\) 值逐渐降低。我们设置好 \(\epsilon\) 的起始值和结束值,以及从开始达到结束值的步数。\(\epsilon\)从开始到结束值线性减少。当\(\epsilon\)到达结束值的时候,就在下面程序中保持值不变。
Prioritized Experience Replay
- 在更新过程中,梯度通过经验回放策略进行更新。优先经验回放策略根据优先级从经验池中选择样本,这可以导致更快的学习和更好的最终策略。其核心思想是提高时间差分误差大的样本的回放概率。有两种可能的方法来评估经验回放的概率,比例和排名。基于排名的优先经验回放可以提供更稳定的性能,因为它不受一些极端大错误的影响。在该系统中,我们采用基于排序的方法来计算经验样本的优先级。经验样本i的时差误差\(δ\)定义为:
- 经验按错误数排序,经验\(i\)的优先级\(p_i\)是其优先级的倒数。最后,对经验i进行抽样的概率按下式计算,
- τ表示使用了多少优先级。当τ为0时,为随机抽样。个人理解:τ等于0时,分子为1条经验,分母为所有的经验数量,所以相当于是随机抽样,当τ大于1时,优先级会被放大,例如原先是三条经验,每条经验优先级\(p_1=\frac{1}{2}\),\(p_2=\frac{1}{4}\),τ等于0时,\(P_1=\frac{p_1^0}{p_1^0+p_2^0}=\frac{1}{2}\),\(P_2=\frac{p_2^0}{p_1^0+p_2^0}=\frac{1}{2}\),τ等于2时,\(P_1=\frac{p_1^2}{p_1^2+p_2^2}=\frac{4}{5}\),\(P_2=\frac{p_2^2}{p_1^2+p_2^2}=\frac{1}{5}\),经验\(i=1\)就会更高的几率被抽取。
Optimization
- 本文采用ADAptive Moment estimation (Adam)对神经网络进行优化。将Adam算法与参考文献[27]中的其他反向传播优化算法进行了评价和比较,结果表明Adam算法具有较快的收敛速度和自适应学习速度,整体性能令人满意。采用随机梯度下降法自适应更新学习速率,同时考虑一阶和二阶。具体来说,让θ表示为CNN中的参数,J(θ)表示损失函数。Adam先计算参数的梯度,
- 然后它分别用指数移动平均更新一阶和二阶有偏差的s和r,
- 其中,\(ρ_s\)和\(ρ_r\)分别为一阶和二阶的指数衰减率。利用时间步长t对一阶和二阶偏差部分进行校正,通过以下方程:
- 最后将参数更新如下:
- \(\epsilon_r\)是初始化的学习速率,\(\delta\)是一个很小的正的常数,目的是为了数值稳定性。
Overall Architecture
- 综上所述,我们模型的整个过程如图5所示。当前的状态和尝试的动作被输入到初级卷积神经网络,以选择最有回报的动作。当前状态和行动以及下一个状态和收到的奖励以四元组\(<s, a, r, s'>\)的形式存储在经验池中。经验池中的数据由优先经验回放选择生成小批量数据,用于更新主神经网络的参数。目标网络\(θ^−\)是一个独立的神经网络,以增加学习过程中的稳定性。我们使用double DQN和dueling DQN 来减少可能的高估和提高性能。通过这种方法,可以训练出逼近函数和可以计算出每个动作在每个状态下的Q值。通过选择Q值最大的动作,可以得到最优策略。
Algorithm 1 Dueling Double Deep Q Network with Priori-tized Experience Replay Algorithm on a Traffic Light:
Input: replay memory size \(M\), minibatch size \(B\), greedy \(\epsilon\), pre-train steps \(tp\), target network update rate \(α\), discount factor \(γ\).
Notations:
\(θ\): the parameters in the primary neural network.
\(θ^−\): the parameters in the target neural network.
\(m\): the replay memory.
\(i\): step number.Initialize parameters \(θ\),$ θ^−$with random values.
Initialize \(m\) to be empty and \(i\) to be zero.
Initialize \(s\) with the starting scenario at the intersection.
while there exists \(a\) state \(s\) do
Choose an action \(a\) according to the \(\epsilon\) greedy.
Take action \(a\) and observe reward \(r\) and new state \(s′\).
if the size of memory m > M then
Remove the oldest experiences in the memory.
end if
Add the four-tuple \(<s, a, r, s′>\) into \(M\).
Assign \(s′\) to \(s\): \(s ← s′\).
\(i ← i + 1\).
if \(|M| > B\) and \(i > tp\) then
Select \(B\) samples from \(m\) based on the sampling priorities.
Calculate the loss \(J\):
\(J =\sum_s \frac{1}{B}[r + γQ(s′,argmax_{a′}(Q(s′, a′;θ)), θ^−)−Q(s, a;θ)]^2.\)
Update \(θ\) with \(∇J\) using Adam back propagation.
Update \(θ^−\)with \(θ\):
\(θ^−= αθ^−+ (1 − α)θ\).
Update every experience’s sampling priority based on \(δ\).
Update the value of \(\epsilon\).
end if
end while
- 我们的3DQN具有优先体验重放的伪代码显示在算法1中。它的目标是训练一个成熟的自适应交通灯,它可以根据不同的交通场景改变其相位的持续时间。智能体首先随机选择动作,直到步骤的数量超过了预训练步骤,并且内存中至少有足够的样本来处理一个小批量。在训练之前,每个样本的优先级都是相同的。因此,他们被随机挑选成一个小批进行训练。经过一次训练后,样本的优先级发生变化,根据不同的概率进行选择。采用Adam反向传播对神经网络中的参数进行更新。智能体选择行动基于 \(\epsilon\) 和行动的最大Q值。智能体最终学会了通过对不同的交通场景做出反应来获得高奖励。
Evalution:
- 在本节中,我们将介绍模拟环境。仿真结果表明了该模型的有效性
Evaluation Methodology and Parameters
我们进行仿真的主要目的是:
-
最大化所定义的奖励,减少所有车辆的累积延误。
-
减少交通道路场景下车辆的平均等待时间。
-
具体来说,第一个目标是强化学习模型的目标。我们会在1小时内测量每一集的累积奖励。第二个目标是衡量交通管理系统性能的重要指标,它直接影响司机的感受。为了这两个目标,我们比较了所提出的模型与预先安排的交通信号的性能。在有传统交通灯的十字路口,信号灯是由运营商预先安排的,它们不再改变。
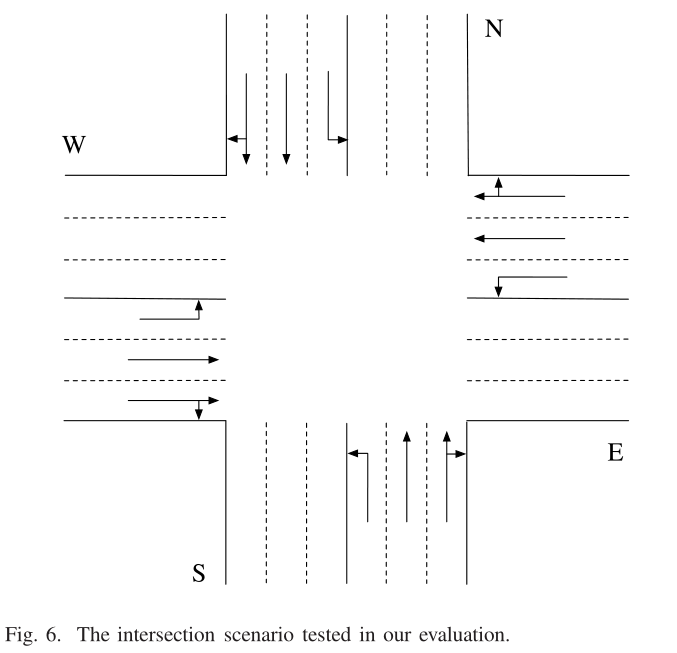
- 评估在SUMO中进行,提供了微观的实时交通模拟。我们使用SUMO提供的Python api来提取交通灯控制的十字路口的信息,并发送命令来更改交通灯的时间。十字路口由四条垂直的道路组成,如图6所示。每条路都有三条车道。最右边的车道允许右转通行,中间的车道是唯一通行的车道,左边的内车道只允许左转车辆通行。整个交叉口场景为\(300m×300m\)区域。车道长度为\(150m\)。车辆长度为\(5m\),两车最小间距为\(2m\)。我们设网格长度为\(c 5m\),因此网格总数为\(60×60\)。车辆的到达是一个随机过程。各车道的平均车辆到达率相同,为每秒1/10。有两条贯通车道,所有贯通车流(东西、东西、南北、南北)流速为每秒2/10,和转弯流量(从东到南,从西到北,从南到西,从北到东)为每秒1/10。 SUMO提供 Krauss Following Model ,可确保在道路上安全行驶。对于车辆,最大速度为\(13.9 m / s\),等于\(50公里/小时\) 最大加速加速度为\(1.0 m / s^2\),减速加速度为\(4.5 m / s^2\)。 黄色持续时间信号\(T_{yellow}\)设置为4秒。
Experimental Results
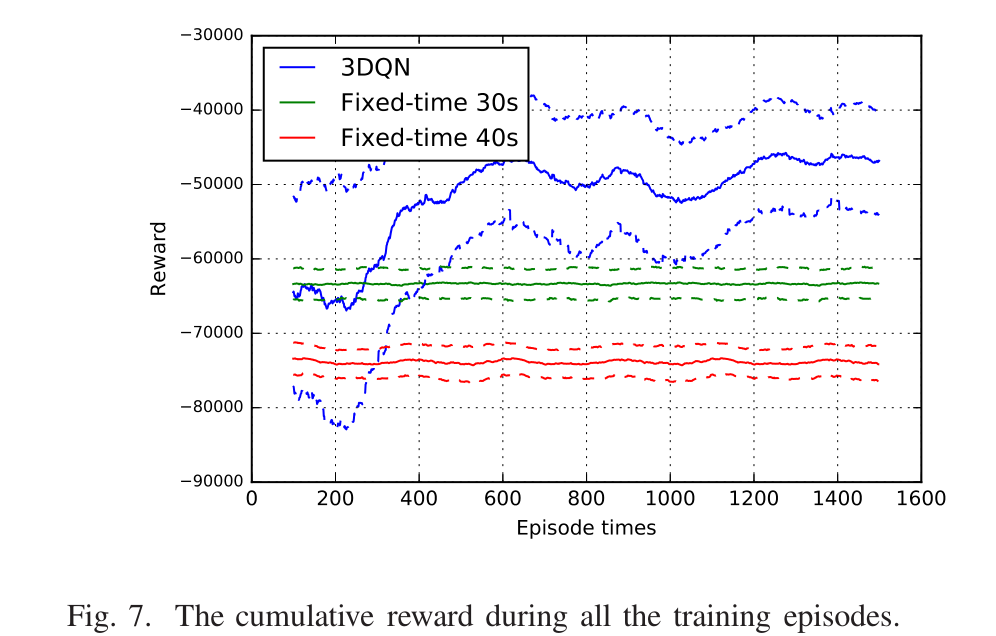
- Cumulative reward:每集累积的奖励首先以所有车道相同的车流率进行评估。仿真结果如图7所示。蓝色实线为我们模型的结果,绿色和红色实线为固定时间交通灯的结果。虚线是对应颜色的实线的置信区间。从图中可以看出,我们的3DQN策略在交通信号灯时间固定的情况下优于其他两种策略。具体来说,一次迭代的累积奖励大于-50000(注意,奖励是负的,因为车辆的延迟是正的),而其他两种策略的累积奖励都小于-6000。固定时间的交通信号总是获得较低的奖励,即使产生更多的迭代,而我们的模型可以学习通过更多的迭代获得更高的奖励。这是因为在不同的交通场景下,固定时间的交通信号不会改变信号的时间。在3DQN中,信号的时间变化以实现最佳预期回报,这平衡了当前的交通场景和潜在的未来交通。当训练过程在我们的协议中迭代超过1000次时,累积的奖励会比之前的迭代更加稳定。这意味着该协议已经学会如何处理不同的交通场景,以在1000次迭代后获得最多的奖励。
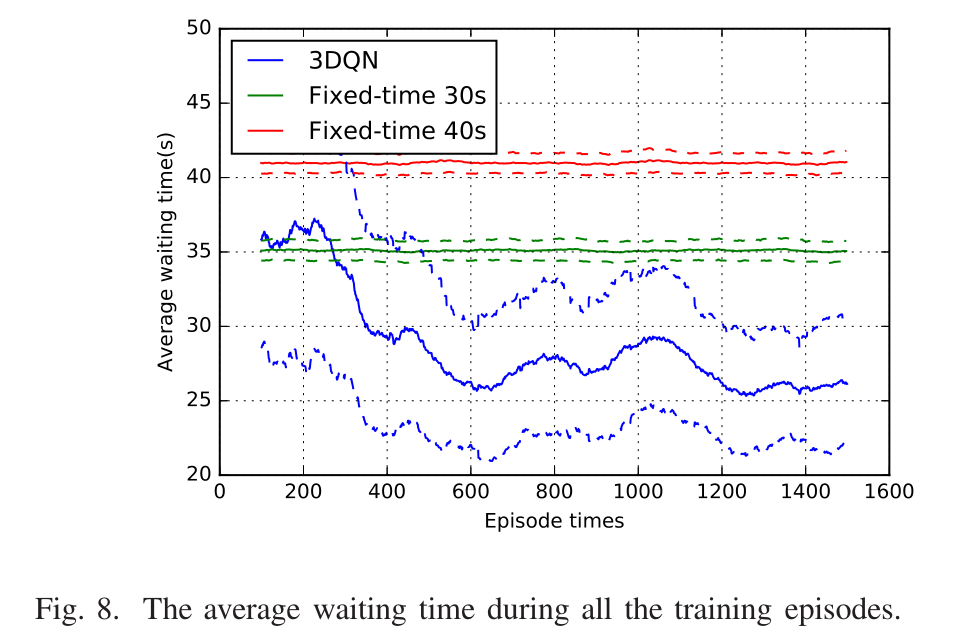
- Average waiting time:我们测试了每集车辆的平均等待时间,如图8所示。在这个场景中,来自所有车道的交通费率也是相同的。图中蓝色实线为我们模型的结果,绿色和红色实线为固定时间交通灯的结果。虚线也是相同颜色的点线的对应方差。从图中可以看出,我们的3DQN策略优于其他两种固定时间红绿灯策略。具体来说,固定时间信号中的平均等待时间总是超过35秒。我们的模型可以学习将等待时间从35秒以上迭代1200次,减少到26秒左右,比其他两种策略至少减少25.7%。结果表明,该模型能显著提高交叉口车辆平均等待时间的性能。
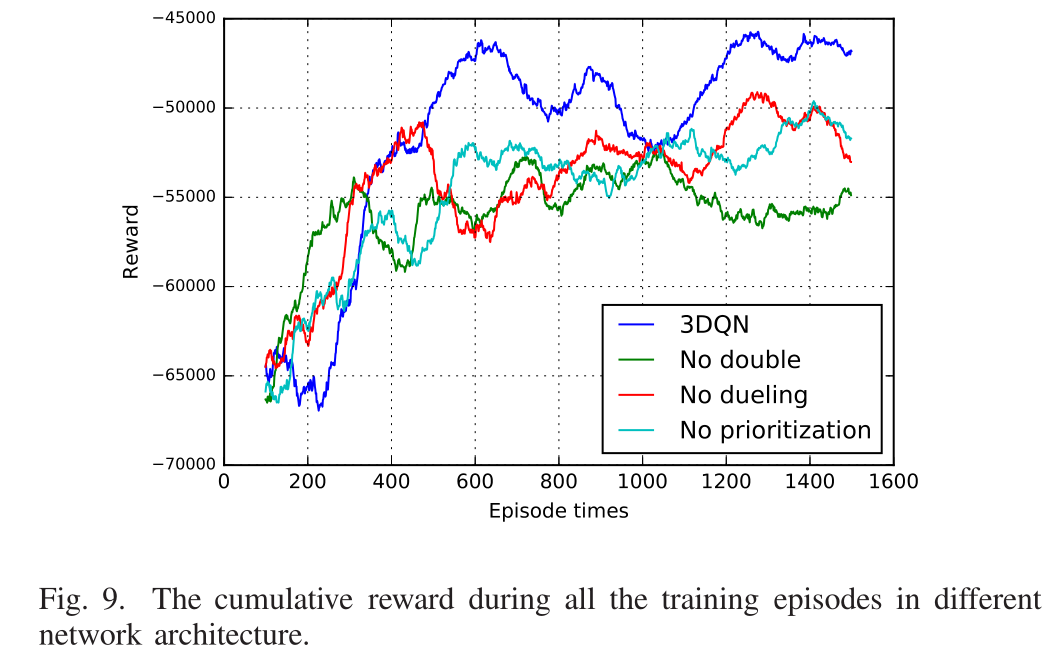
- Comparison with different parameters and algorithms:我们的模型,绿线是没有双网的模型。红线是没有决斗网络的模型,青色线是没有优先体验重放的模型。我们可以看到,我们的模型在四个模型中学习速度最快。这意味着我们的模式比其他模式更快地达到最佳政策。具体来说,即使在前400次迭代中有一些波动,我们的模型在500次迭代后仍然优于其他三个模型。我们的模型可以获得大于-47000的奖励,而其他模型的奖励少于-50000。
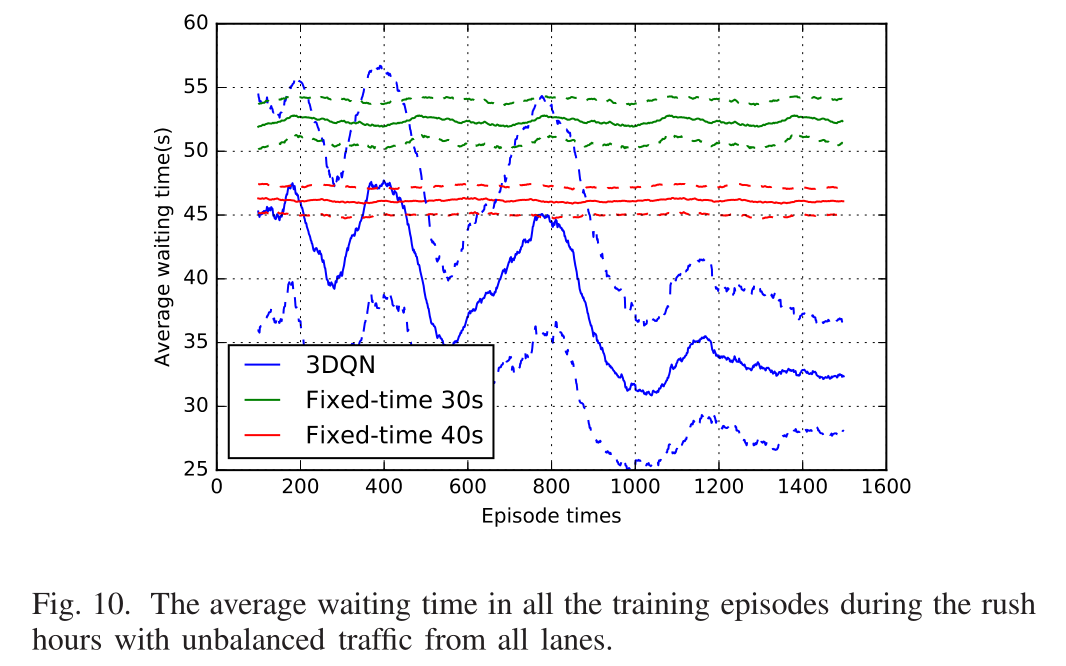
- Average waiting time under rush hours:在这一部分中,我们通过比较交通高峰期下的性能来评价我们的模型。高峰时间意味着所有车道的车流都不一样,这在现实生活中很常见。在高峰时间,一个方向的交通流率加倍,而其他车道的交通流率保持正常时间相同。具体来说,在我们的实验中,从西向东的车道上的车辆到达率为每秒2/10,其他车道上的车辆到达率仍为每秒1/10。实验结果如图10所示。图中蓝色实线为我们模型的结果,绿色和红色实线为固定时间交通灯的结果。虚线是对应颜色的实线的方差。从图中我们可以看出,最好的政策比之前的情景更难学习。这是因为交通场景变得更加复杂,导致更多不确定因素。但是经过反复试验,我们的模型仍然可以学习到一个很好的策略来减少平均等待时间。其中3DQN在1000个episodes后的平均等待时间约为33秒,而另外两种方法的平均等待时间分别在45秒和50秒以上。我们的模型减少了26.7%的平均等待时间。
CONCLUSION:
- 在本文中,我们提出了利用深度强化学习模型来解决交通信号灯控制问题。交通信息是从车辆网络收集的。状态是包含车辆位置和速度信息的二维值。这些行为被建模为马尔可夫决策过程,而回报则是两个周期的累积等待时间差,为了解决我们问题中的复杂交通场景,我们提出了一个具有优先经验重放的双决斗深度Q网络(3DQN)。该模型既能学习到高峰时段的交通策略,又能学习到正常交通流量下的交通策略。从开始训练开始,可以减少平均等待时间的20%以上。该模型在学习速度上也优于其他模型,这在SUMO和TensorFlow的大量仿真中得到了体现。
标签:模型,交通灯,学习,奖励,Vehicular,Traffic,Reinforcement,车辆,theta 来源: https://www.cnblogs.com/52dxer/p/14211671.html