不知道如何回答高并发+性能调优,那就看一下我得答案模板,提前准备应该有用
作者:互联网
不知道大家在面试的时候有没有被维导类似这样得问题:
你有高并发项目经验吗?性能优化怎么操作的?如何设计一个高并发系统?
差不多就是类似得,那你该如何应对这样得问题呢?
首先,如果面试官问你这个问题,那你就必须使出全身吃奶的劲了。从目前招聘要求来看,有高并发经验是非常吃香的。
假设你在某知名电商公司干过高并发系统,用户上亿,一天流量几十亿,高峰期并发量上万,甚至是十万。 那么人家一定会仔细盘问你的系统架构,你们系统啥架构?怎么部署的?部署了多少台机器?缓存咋用的? MQ 咋用的?数据库咋用的?就是深挖你到底是如何扛住高并发的。
因为真正干过高并发的人一定知道,脱离了业务的系统架构都是在纸上谈兵,真正在复杂业务场景而且还高 并发的时候,那系统架构一定不是那么简单的,用个 redis,用 mq 就能搞定?当然不是,真实的系统架 构搭配上业务之后,会比这种简单的所谓“高并发架构”要复杂很多倍。
如果有面试官问你个问题说,如何设计一个高并发系统?那么不好意思,一定是因为你实际上没干过高并发系统。面试官看你简历就没啥出彩的,感觉就不咋地,所以就会问问你,如何设计一个高并发系统?其实说 白了本质就是看看你有没有自己研究过,有没有一定的知识积累 。
其实所谓的高并发,如果你要理解这个问题呢,其实就得从高并发的根源出发,为啥会有高并发?为啥高并发就很牛逼?
我说的浅显一点,很简单,就是因为刚开始系统都是连接数据库的,但是要知道数据库支撑到每秒并发两三千的时候,基本就快完了。所以才有说,很多公司,刚开始干的时候,技术比较 low,结果业务发展太快,有的时候系统扛不住压力就挂了。
当然会挂了,凭什么不挂?你数据库如果瞬间承载每秒 5000/8000,甚至上万的并发,一定会宕机,因为mysql就压根儿扛不住这么高的并发量。所以为啥高并发牛逼?就是因为现在用互联网的人越来越多,很多 app、网站、系统承载的都是高并发请求, 可能高峰期每秒并发量几千,很正常的。如果是什么双十一之类的,每秒并发几万几十万都有可能。
那么如此之高的并发量,加上原本就如此之复杂的业务,咋玩儿?真正厉害的,一定是在复杂业务系统里玩儿过高并发架构的人,但是你没有,那么我给你说一下你该怎么回答这个问题:
可以分为以下 6 点:
- 系统拆分
- 缓存
- MQ
- 分库分表
- 读写分离
- ElasticSearch
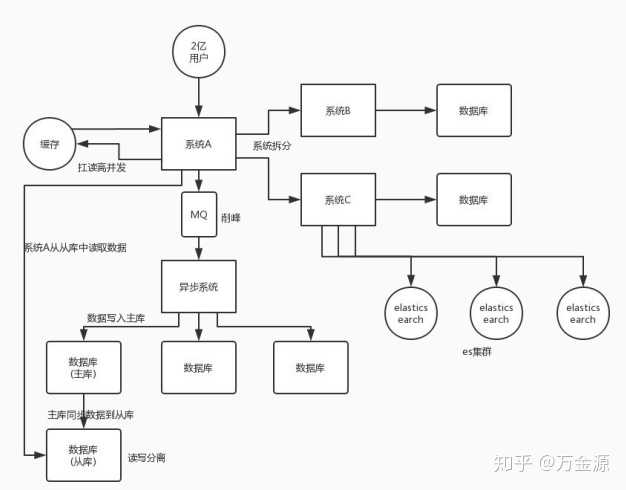
系统拆分
将一个系统拆分为多个子系统,用 dubbo 来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,不也可以扛高并发么。
缓存
缓存,必须得用缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家 redis 轻轻松松单机几万的并发。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
MQ
MQ,必须得用 MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,你要是用 redis 来承载写那肯定不行,人家是缓存,数据随时就被 LRU 了,数据格式还无比简单,没有事务支持。所以该用 mysql 还得用 mysql 啊。那你咋办?
用 MQ 吧,大量的写请求灌入 MQ 里,排队慢慢玩儿,后边系统消费后慢慢写,控制在 mysql 承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用 MQ 来异步写,提升并发性MQ 单机抗几万并发也是 ok 的,这个之前还特意说过。
分库分表
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 sql 跑的性能。
读写分离
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
ElasticSearch
Elasticsearch,简称 es。es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 es 来承载,还有一些全文搜索类的操作,也可以考虑用 es 来承载。
上面的 6 点,基本就是高并发系统肯定要干的一些事儿,大家可以仔细结合之前讲过的知识考虑一下,到时候你可以系统的把这块阐述一下,然后每个部分要注意哪些问题,之前都讲过了,你都可以阐述阐述,表明你对这块是有点积累的。
说句实话,毕竟你真正厉害的一点,不是在于弄明白一些技术,或者大概知道一个高并发系统应该长什么样?
其实实际上在真正的复杂的业务系统里,做高并发要远远比上面提到的点要复杂几十倍到上百倍。你需要考虑:哪些需要分库分表,哪些不需要分库分表,单库单表跟分库分表如何 join,哪些数据要放到缓存里去,放哪些数据才可以扛住高并发的请求,你需要完成对一个复杂业务系统的分析之后,然后逐步逐步的加入高并发的系统架构的改造,这个过程是无比复杂的,一旦做过一次,并且做好了,你在这个市场上就会非常的吃香。
其实大部分公司,真正看重的,不是说你掌握高并发相关的一些基本的架构知识,架构中的一些技术,RocketMQ、Kafka、Redis、Elasticsearch,高并发这一块,你了解了,也只能是次一等的人才。对一个有几十万行代码的复杂的分布式系统,一步一步架构、设计以及实践过高并发架构的人,这个经验是难能可贵的。
下面是有关阿里巴巴出的高并发系统设计学习笔记,希望对你有用,需要的话请戳下面卡片即可免费获取了!

高并发系统设计学习(基础篇)
01. 高并发系统:它的通用设计方法是什么

02. 架构分层:我们为什么一定要这么做?
03. 系统设计目标(一):如何提升系统性能?

04. 系统设计目标(二):系统怎样做到高可用?

05. 系统设计目标(三):如何让系统易于扩展?
高并发系统设计学习(数据库篇)
07. 池化技术:如何减少频繁创建数据库连接的性能损耗?

08. 数据库优化方案(一):查询请求增加时,如何做主从分离?

09. 数据库优化方案(二):写入数据量增加时,如何实现分库分表?

10. 发号器:如何保证分库分表后ID的全局唯一性?

11. NoSQL:在高并发场景下,数据库和NoSQL如何做到互补?
高并发系统设计学习(缓存篇)
12. 缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
13. 缓存的使用姿势(一):如何选择缓存的读写策略?
14. 缓存的使用姿势(二):缓存如何做到高可用?
15. 缓存的使用姿势(三):缓存穿透了怎么办?
16. CDN:静态资源如何加速?
高并发系统设计学习(消息队列篇)
17. 消息队列:秒杀时如何处理每秒上万次的下单请求?
18. 消息投递:如何保证消息仅仅被消费一次?
19. 消息队列:如何降低消息队列系统中消息的延迟?

高并发系统设计学习(分布式服务篇)
21. 系统架构:每秒1万次请求的系统要做服务化拆分吗?
22. 微服务架构:微服务化后,系统架构要如何改造?
23. RPC框架:10万QPS下如何实现毫秒级的服务调用?
24. 注册中心:分布式系统如何寻址?
25. 分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
26. 负载均衡:怎样提升系统的横向扩展能力?
27. API网关:系统的门面要如何做呢?
28. 多机房部署:跨地域的分布式系统如何做?
29. Service Mesh:如何屏蔽服务化系统的服务治理细节?
高并发系统设计学习(维护篇)
30. 给系统加上眼睛:服务端监控要怎么做?
31. 应用性能管理:用户的使用体验应该如何监控?
32. 压力测试:怎样设计全链路压力测试平台?
33. 配置管理:成千上万的配置项要如何管理?
34. 降级熔断:如何屏蔽非核心系统故障的影响?
35. 流量控制:高并发系统中我们如何操纵流量?

高并发系统设计学习(实战篇)
37. 计数系统设计(一):面对海量数据的计数器要如何做?
38. 计数系统设计(二):50万QPS下如何设计未读数系统?
39. 信息流设计(一):通用信息流系统的推模式要如何做?
40. 信息流设计(二):通用信息流系统的拉模式要如何做?

需要的话请戳下面卡片即可免费获取了!
标签:缓存,架构,如何,数据库,系统,提前准备,并发,调优,模板 来源: https://blog.csdn.net/weixin_42864905/article/details/111280044