论文阅读 Rethinking Pre-training and Self-training
作者:互联网
--> 自训练只是分类,回归能进行自训练吗?

论文阅读 Rethinking Pre-training and Self-training
Paper : https://arxiv.org/abs/2006.06882
概述
Google Brain 的文章,一作都是大牛。这篇文章延续之前何恺明的 Rethinking ImageNet Pre-Training[1],在之前的基础上通过大量的实验验证了在检测和分割任务中 Pre-training 和 Self-training 的效果,主要得出了以下几个结论:
- 对于 Pre-training
- 当使用更强大的数据增强方案时,预训练反而会损害模型的性能
- 可用标注数据越多,预训练的作用越小,价值越低
- 对于 Self-training
- Self-training 在使用高强度数据增强策略时仍能够提升性能,即使当预训练已经会损害性能时
- Self-training 在各种标注数据规模下都具能提升性能,并可以与预训练共同起作用
- 对于 Self-supervised pre-training 同样在高强度数据增强策略时会损害性能
最后使用 self-training,在检测和分割使用的 SOTA Baseline 上都有明显涨点,COCO 54.3 AP(+1.5),PASCAL segmentation 90.5 mIOU(+1.5%)。但是相应的,实验中训练需要 1.3x - 8x 的时间
Methodology
主要部分在实验,这里介绍一些实验设置,实验中设置的变量主要有两种,数据增强策略和预训练模型

- 数据增强:使用四种不同的数据增强策略,依次增强,第一种是和 [1] 中一致,后三种来自 AutoAugment 和 RandAugment
- 预训练:模型使用的是 Efficient-B7,ImageNet++ 表示使用 Noisy Student 方法利用了额外 300M 未标注图片训练的模型
实验中使用的 Self-training 使用基于 Noisy Student 训练的方法
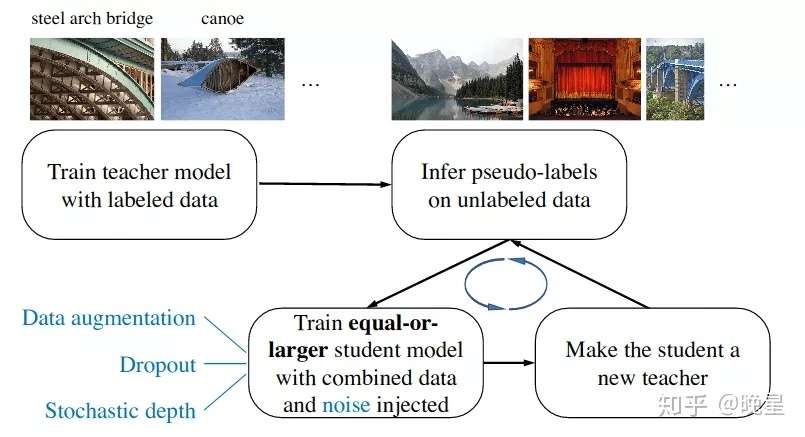
所有实验训练到收敛为止,例如当随机初始化时, Augment-S1 用了 45k iterations,Augment-S4 用了 120k iterations
Experiments
Pre-training
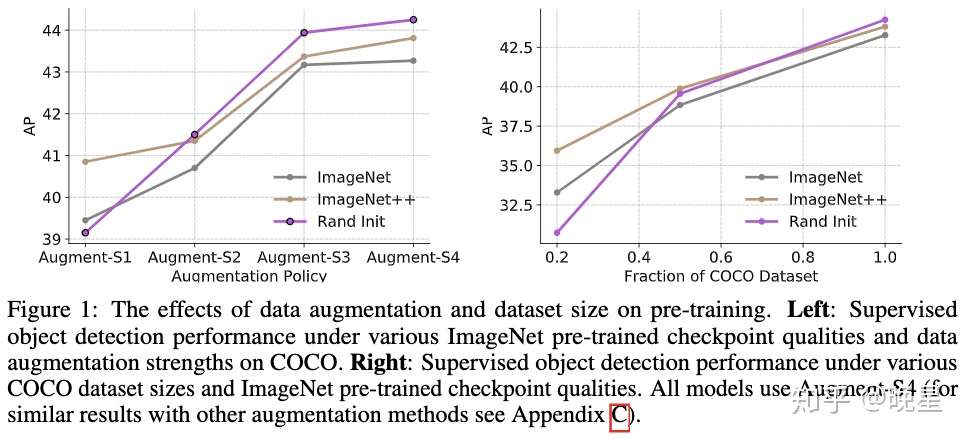
对 [1] 中的发现进行扩展,得出两个结论
- 当使用更强大的数据增强方案时,预训练反而会损害模型的性能
- 可用标注数据越多,预训练的作用越小,价值越低
Self-training
分析 self-training 的效果,得出两个结论
- Self-training 在使用高强度数据增强策略时仍能够提升性能,即使当预训练已经会损害性能时
- Self-training 在各种标注数据规模下都具能提升性能,并可以与预训练共同起作用


Self-supervised pre-training
对于 Self-supervised pre-training,同样在高强度数据增强策略时会损害性能。这里使用 Resnet50 作为 backbone,使用 100% COCO 数据和 Augment-S4

Exploring the limits of self-training and pre-training
结合之前的结论对 SOTA baseline 做优化

分割任务中由于 PASCAL 数据集规模比较小,因此使用预训练模型效果更好


Discussion
- 作者猜测预训练效果不佳是由于 pre-training 无法感知检测或分割任务感兴趣的地方并且无法适应,例如 ImageNet 上训练好的特征可能忽视了检测任务所需的位置信息
- Joint-training 的优势, joint-training 表示同时训练 ImageNet 分类和 COCO 的对象检测,实验结果 表明使用 350 epochs 的预训练模型进行初始化能够取得 +2.6AP(33.3-30.7) 的提升,但使用联合训练只需要在 ImageNet 上训练 19 epochs 就能获得 +2.9AP 的提升。此外预训练,自训练,联合训练加一起能够得到更大的提升。

- Task alignment 的重要性,self-training 能够对齐任务。由于标注的类别不一致,之前的实验中 Open Images 不能提升 COCO 数据集的性能,但在文章附录的实验中使用 self-training 能够用 Open Images 提升 COCO 指标。
- 局限性,self-training 相比在预训练模型上做微调需要多 1.3x - 8x 的时间,且数据规模较少时预训练依旧有效
- 扩展性、通用性、灵活性,实验结果显示 self-training 对检测分割中的各种设置和网络结构都能发挥作用
[1] He K, Girshick R, Dollár P. Rethinking imagenet pre-training
发布于 06-28 深度学习(Deep Learning) 计算机视觉 目标检测文章被以下专栏收录
推荐阅读
Learning Data Augmentation Strategies论文阅读
chaser
Jigsaw pre-training:摆脱ImageNet,拼图式预训练方法 | ECCV20
Vince...发表于晓飞的算法...Rethinking Pre-training and Self-training
Paper: Rethinking Pre-training and Self-training Arxiv: https://arxiv.org/abs/2006.06882v1IntroductionPre-training是深度学习领域常见的一种方法,在计算机视觉、自然语言处理和语…
yanwa...发表于AI约读社
论文阅读(小目标检测)
kyno发表于CV学习之...还没有评论
写下你的评论...
标签:Pre,Rethinking,training,pre,训练,Self,self 来源: https://www.cnblogs.com/cx2016/p/14069647.html