第九届软件杯(第二批)基于深度学习的企业实体识别
作者:互联网
本赛题分为三个模块:文字检测、文字识别、命名实体识别。
赛题要求将图片中的所有文字检测并识别出来,并从识别出的文字中提取出企业名称。
文字检测模块
数据准备
ICDAR2019-LSVT数据集,下载并解压后的数据集如下:
~/train_data/LSVT/text_localization
└─ LSVT_train_imgs/ LSVT训练集
└─ LSVT_test_images/ LSVT测试集
└─ train_LSVT_label.txt LSVT训练标注
└─ test_LSVT_label.txt LSVT测试标注

模型选择
文字检测使用的方法是DB-ResNet-50。
通过下载预训练模型,在LSVT数据集上进行finetune。
# 执行以下命令,生成的检测结果在detect_results文件夹中
python3 predict_det.py --image_dir="./testImages" --det_model_dir="./inference/det/"
检测效果

文字识别模块:
数据准备
文字识别选择的数据是ICDAR2019-LSVT行识别任务数据集,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如图所示:

(a) 标注:魅派集成吊顶

(b) 标注:母婴用品连锁
模型选择
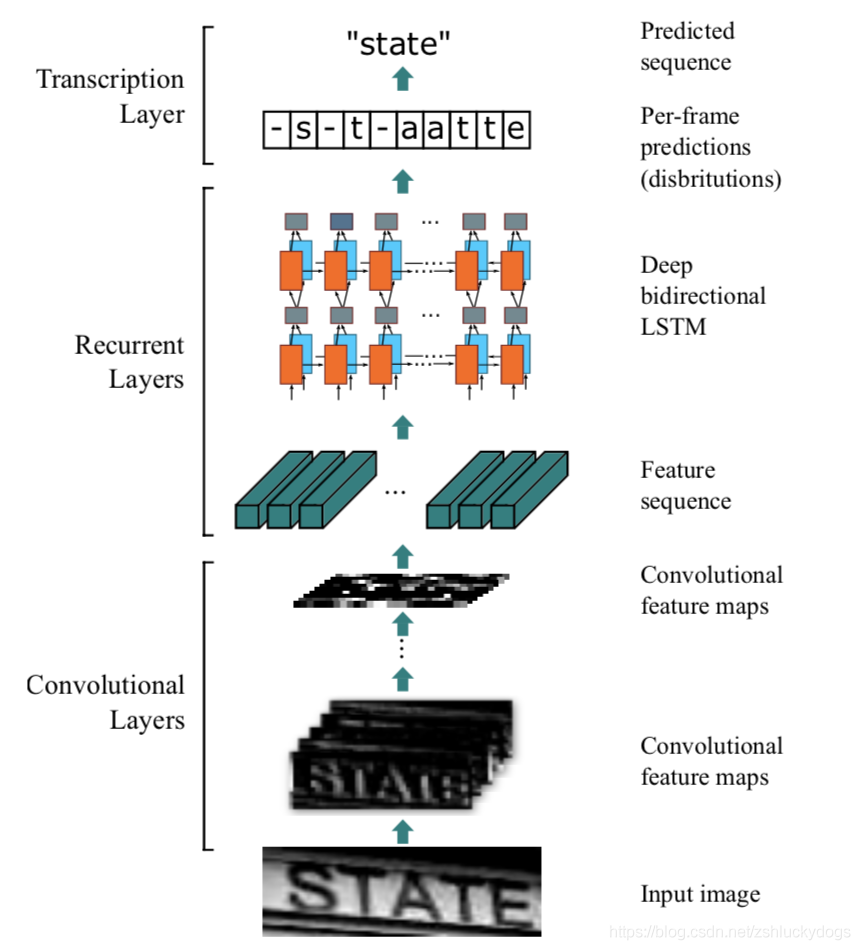
模型选择的是端到端的CRNN模型,CRNN的思想就是通过CNN网络提取文本图像的特征,然后转化这些特征用于RNN(LSTM)识别具体的文本内容。一般处理文本数据时最先想到的就是LSTM模型,这是因为文本的理解和处理必须在特定的语境(上下文)中进行,LSTM模型的输入通常都是学习到或者人工设定的词向量,CRNN的一个最大的优点就是通过预训练的CNN网络直接从图像中学习文本的表达向量,在最大程度上保证输入到LSTM的序列是最好的表达。如下图是CRNN的网络结构。
# 执行以下命令可以生成一个result.txt文件,内容是图片中识别到的所有文字,打印的内容可以看到每张图片的检测+识别时间
python3 predict_det_rec.py --image_dir="./testImages" --det_model_dir="./inference/det/" --rec_model_dir="./inference/rec/"
识别效果

命名实体识别模块:
数据准备
-
该模块的难点在于数据的准备,从初赛到决赛我们试了很多种方法去搭建数据集,但都没有得到一个非常令人满意的数据集。
-
我们采取的方法是首先从LSVT数据集的train_weak_labels.json标签文件中提取图片中的企业店铺名称,初赛通过爬虫建立语料库,但数据量极大,数据清理工作难以进行,故决赛时我们尝试利用MSRA数据集,将企业店铺名称替换掉MSRA数据集中的NT实体类别。虽然在逻辑上语义略显滑稽,但该模块的任务并不是在一个具有上下文语义的环境下完成,故做此尝试。
-
如何处理一张图片识别出的所有文字,用以进行命名实体识别也是一个问题,我们尝试将所有文字以逗号句号等字符连接,作为一条语料进行识别,效果因字符的不同而变化,且非常不稳定,最终我们选择将一张图片中识别到的每一个文本框中的文字作为一条语料进行识别,效果较之前有所提高。
-
同时我们使用了面积作为辅助识别,如果一张图片中没有提取出企业名,那么就选择文本检测+识别时目标框最大的文本作为企业名。
模型选择
- 模型选择的是albert模型,这个模型相比于bert,体积更小,效果更好。
# 运行一下命令可以提取企业实体名称
python predict_ner.py

做的并不好,只是单纯记录下软件杯经历。
标签:文字,第九届,LSVT,模型,det,第二批,识别,数据 来源: https://www.cnblogs.com/LiJinrun/p/13974475.html