[深度模型] 阿里MIND网络:天猫首页是怎么给用户做多兴趣embedding的
作者:互联网
[深度模型] 阿里MIND网络:天猫首页是怎么给用户做多兴趣embedding的
本人微信公众号为“推荐算法学习笔记”,定期推出经典推荐算法文章,欢迎关注。
一. 概述
我们知道推荐系统一般有两个重要阶段,召回和精排阶段。召回阶段负责从海量的商品中选出用户感兴趣的候选集,精排阶段再对这些候选集进行排序取出topN。
因此,在这两个阶段一个很重要的因素是如何表征用户的兴趣。一般的做法是为每个用户生成1个embedding来表征用户。而在这篇paper《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》中,paper作者提出了一种为每个用户生成多个embedding的网络,以表征同一个用户多个不同的兴趣。
目前为止,MIND网络已经部署在天猫首页的主流量位置上。

二. 需要了解的基础知识
(1)胶囊网络:paper名称为《Dynamic Routing Between Capsules》
(2)Attention机制:paper名称为《Attention Is All You Need》
如果对胶囊网络或Attention机制不熟悉,建议先阅读相关paper。
三.MIND模型整体架构
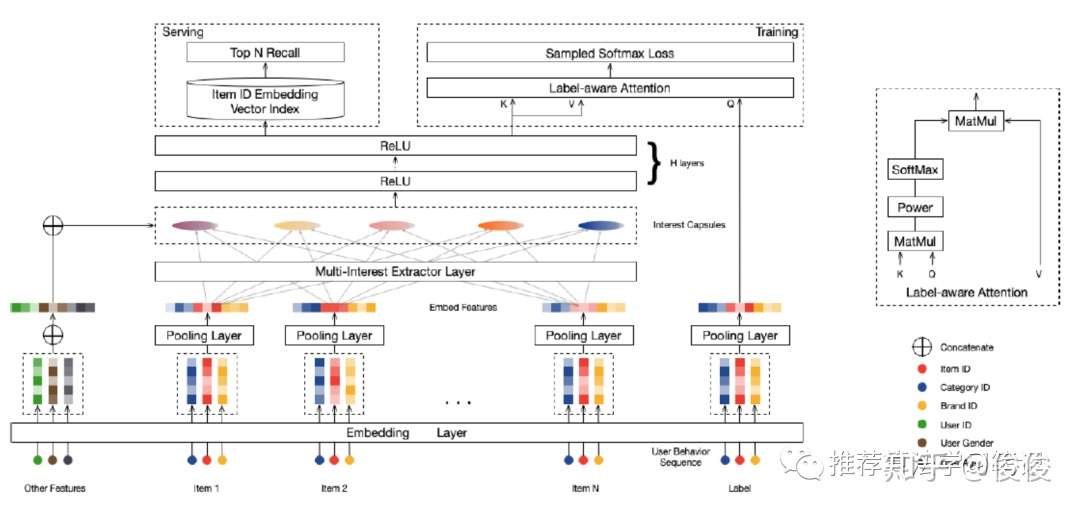
MIND的模型结构如上图所示。它主要包含以下3个layer
(1)Embedding & Pooling Layer:主要是将用户特征,用户行为特征和最终的label对应的target item的输入转换成embedding和pooling
(2)Multi-Interest Extractor Layer:使用类似胶囊网络的方法将用户行为聚类,最终得出用户的多个兴趣embedding
(3)Label-aware Attention Layer:将用户多兴趣embedding和label对应target item做attention,得出最终的用户embedding
下面对这3个layer做更详细的叙述。
四. Embedding & Pooling Layer
MIND模型的输入包含三组特征:user profile,user behavior和label对应的target item。
对于user profile,将所有的id特征 (性别,年龄)转换成embedding后concat起来。
user behavior就是用户交互过的items。target item就是user behavior之后下一个交互的item。对于这些items, 首先将item id和其他分类特征(类型ID,品牌ID)转换成embedding,然后经过一层average pooling后,再和其他一些特征,如颜色,纹理,风格concat起来,组成每个item最终的embedding。
其中,user behavior对应的item embedding将会送到Multi-Interest Extractor Layer里面进行聚类。
五. Multi-Interest Extractor Layer
我们知道在电商网站用户交互过的items可能成百上千,因此如何有效地将交互过的item进行聚类,并生成用户多个兴趣embedding很重要。
因此在我看来,Multi-Interest Extractor Layer主要的思路是这样的:
(1)利用胶囊网络的Dynamic Routing的特性对交互过的items进行聚类,有点类似深度版本的k-means。
(2)将聚类后得出的k个embedding分别和user profile对应的embedding concat起来,再分别经过两层全连接神经网络,得到最终的用户多兴趣embedding。
对应的伪代码如下所示

值得注意的是,为了使胶囊网络适合做聚类,paper作者对胶囊网络进行了以下修改
(1)bij初始化的时候用了正态分布,而不是初始化为0。这个有点类似于我们k-means的时候采用不同的点进行聚类,否则所有的点最终全部聚集到同一个类上了
(2)bilinear mapping matrix是共享的。主要原因在于(a)用户的行为序列是不同长度的;(b)希望不同的输入embedding处在相同的embedding映射空间
(3)每个用户最终的兴趣embedding个数是不一样的,计算公式如下
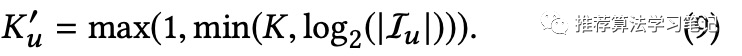
其中Iu是用户交互序列的个数,K是自己定的超参数
六. Label-aware Attention Layer
得到用户的多个兴趣embedding后,对于target item,我们就可以通过attention机制来生成最终用户的embedding,公式如下所示
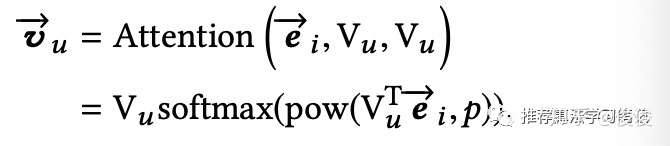
ei是目标item对应的embedding,Vu是用户多兴趣embeddings
七. training阶段和serving阶段
训练的目标是在vu的情况下,用户是否会和ei交互,公式如下所示
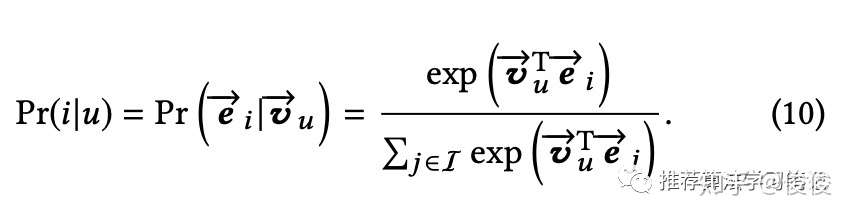
损失函数为
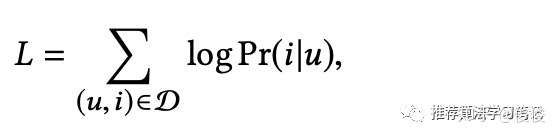
在serving阶段,我们可以提前计算好每个用户对应的多个embedding并保存起来。同时,可以取出与这些embedding最相似的embeding索引起来,作为用户兴趣的候选集。
八. 总结
以上便是MIND模型全部内容。如有问题,欢迎随时联系。本人微信公众号为“推荐算法学习笔记”,定期推出经典推荐算法文章,欢迎关注~
编辑于 07-06 「真诚赞赏,手留余香」 还没有人赞赏,快来当第一个赞赏的人吧! 个性化推荐 推荐系统 推荐算法
文章被以下专栏收录
推荐阅读
天猫召回推荐算法MIND模型——基于动态路由的用户多兴趣网络详解
被包养的程...发表于独立团丶RALM: 实时 Look-alike 算法在微信看一看中的应用
导读:本次分享是微信看一看团队在 KDD2019 上发表的一篇论文。长尾问题是推荐系统中的经典问题,但现今流行的点击率预估方法无法从根本上解决这个问题。文章在 look-alike 方法基础上,针…
末班车发表于智能推荐系...个性化推荐挑战与趋势
本文三部分:Foundations ,Challenges ,Trends 一、Foundation 推荐系统要做的就是预测 user 对 item 的 preference ,这里的 item 是 user 可能需要的 task 有哪些?1、Rating Prediction …
羊村你喜哥[FM学习] 推荐系统召回四模型之:FM模型
作者:张俊林老师 链接: 张俊林:推荐系统召回四模型之:全能的FM模型说明:仅用于学习、记录、进步 如果您真是推荐工程师,那么首先我想问个问题:一说起推荐模型或者推荐场景下的排序模…
梦醒潇湘发表于备忘录2 条评论
写下你的评论...-
 Tenzin06-02
Tenzin06-02
兄弟复现了没。。
-
 俊俊 (作者) 回复Tenzin06-02
俊俊 (作者) 回复Tenzin06-02
github上有人复现了 可参考https://github.com/shenweichen/DeepMatch
标签:推荐,MIND,用户,item,天猫,user,embedding,兴趣 来源: https://www.cnblogs.com/cx2016/p/13906744.html