语音识别中的End2End模型: CTC, RNN-T与LAS
作者:互联网
语音识别中的End2End模型: CTC, RNN-T与LAS
自动语音识别(Automatic Speech Recognition,简称ASR)是一项将机器学习与实际需要紧密结合的领域,应用场景如语音助手,聊天机器人,客服等等。今天就来比较一下比较流行的几种End-to-End的ASR模型。
经典语音识别系统
在了解End-to-End模型之前,我们先来看看经典的语音识别系统是怎样工作的以及为什么需要End-to-End模型。
经典语音识别系统通常有如下几个组成部分:特征提取,如利用输入的waveform提取MFCC特征,然后再经过三个独立的模型再求得它们概率的乘积得到总的概率:
1. acoustic model 即根据之前提取的特征预测每个对应的音素(phoneme),传统上用GMM Gaussian Mixture Model。
2. pronunciation model即根据音素组合成词语的发音, 传统上用一些pronunciation table。
3. language model即根据发音预测对应的文本, 传统上用一些n-gram model。
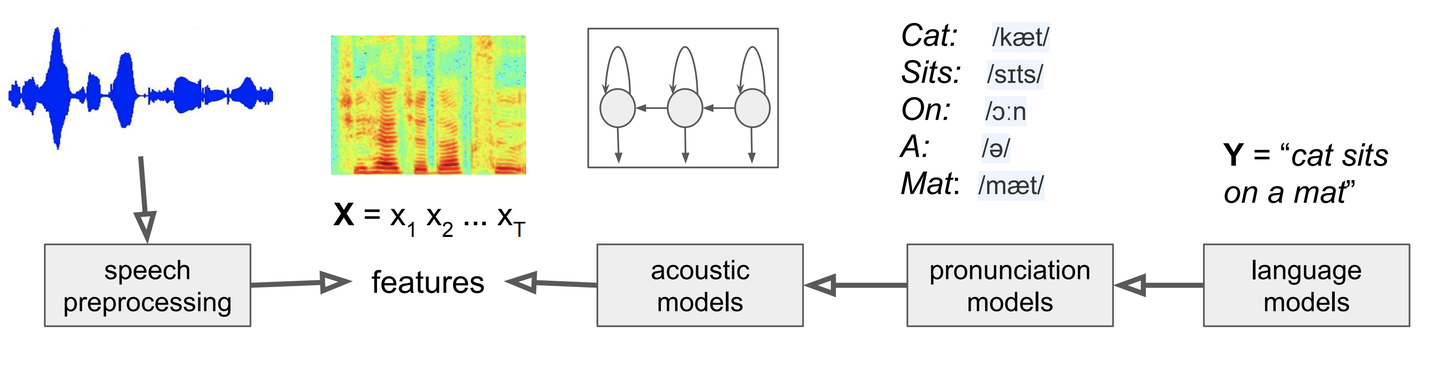
神经网络技术发展后,特征提取又可用CNN来做,其他部分也可用DNN或一些RNN结构如LSTM来做。
但是这三部分模型还是相互独立训练的,这使得训练过程异常复杂,我们希望能用一个end-to-end的模型来包含所有的步骤:可输入语音或其频谱而直接产出文本从而简化训练过程。以下我们来比较一下三种常见的end-to-end模型的原理及优缺点。
CTC
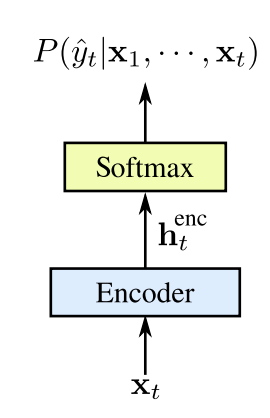
CTC全称是Connectionist Temporal Classification,主要是为了解决利用RNN训练时需要目标label与输入的每一帧需要alignment的问题,即我们需要知道哪几帧输入对应输出的哪个字符并且知道如何分割不同输出字符对应的输入帧的边界,而且有的时候这种边界较为模糊,这种需要逐帧对应的标记的数据相较于只是需要简单的文字输出的人力要求要高很多。
假设输入的语音为 ,而对应的label为
,其输出空间为
,对于ASR,通常
,为解决alignment问题,CTC规定了额外的空格标记blank symbol,假设用标记<b>来表示。我们利用
来代表所有的长度为T的输出序列,且每一个元素均属于
的集合,并且经过把所有相连的重复字母合并且除去所有blank symbol的操作后与原label
相同。举个例子,假设我们输入的语音有八帧,并且其对应的文字是cat仅有三个字符,如何使输出与输入对应呢,我们可以是cc<b>aa<b>t<b>,也可以是c<b><b>aa<b>t<b>,或者是c<b>aaa<b>t<b>等等,这些分割都可以经过上述操作对应到最终的文字输出cat上,这就省去了我们需要带有alignment的标记的需要,而
就可以表示成以上各种分割的概率的求和形式
。对于输入向量,我们可用RNN作为encoder,得到一系列的隐藏向量
,并通过softmax layer来得到每个时刻的输出的类别的概率,其总类别个数为
,并且我们可以利用gradient ascent来求得使
最大化的参数。
该模型可用下图表示:
RNN-T
RNN-T全称是Recurrent Neural Network Transducer,是在CTC的基础上改进的。CTC的缺点是它没有考虑输出之间的dependency,即 与之前帧的
没有任何关联,而RNN-T则在CTC模型的Encoder基础上,又加入了将之前的输出作为输入的一个RNN,称为Prediction Network,再将其输出的隐藏向量
与encoder得到的
放到一个joint network中,得到输出logit再将其传到softmax layer得到对应的class的概率。
整体模型结构如下
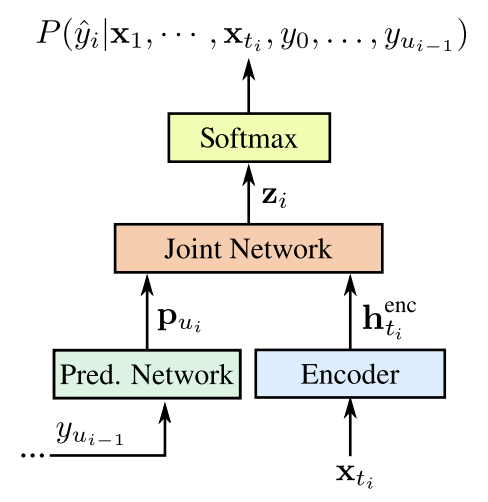
相较于传统模型,RNN-T模型训练较快,模型也较小,并且能够有可比拟的准确率,最近谷歌也是将该模型压缩后deploy到了语音输入Gboard上,详情可参见Google AI Blog https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html。
LAS
LAS,全称Listen Attend and Spell,与CTC/RNN-T思路不同,它利用了attention机制来进行有效的alignment。关于attention机制可参考之前的文章
川陀学者:Attention机制详解(一)——Seq2Seq中的Attentionzhuanlan.zhihu.comLAS模型主要由两大部分组成:1. Listener即Encoder,利用多层RNN从输入序列提取隐藏特征,2. Attend and Spell,即Attention用来得到context vector,decoder利用context vector以及之前的输出来产生相应的最终的输出,其模型结构如下:
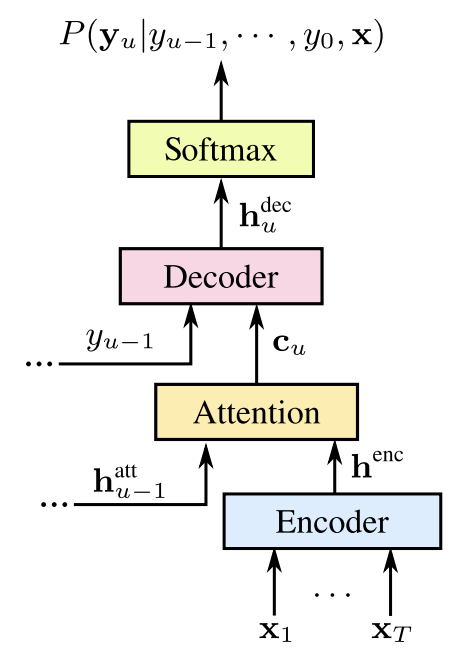
LAS模型由于考虑了上下文的所有信息,所以它的精确度可能较其他模型略高,但是同时由于它需要上下文的信息所以没法进行streaming的ASR,另外输入的语音长度对于模型的准确度也有较大的影响。
总结
这里仅仅简单的介绍与比较了几种常见的end-to-end的ASR模型,实际应用中还有很多的trick,比如是选择grapheme还是wordpiece model,要不要和external language模型做fusion,如何考虑user context等等,希望end-to-end模型能够不断改进,达到更好的效果。
参考资料
斯坦福CS224N 2017 Speech Recognition视频https://youtu.be/3MjIkWxXigM,讲义https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1174/lectures/cs224n-2017-lecture12.pdf
CTC 论文:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks https://www.cs.toronto.edu/~graves/icml_2006.pdf
RNN-T论文:Sequence Transduction with Recurrent Neural Networks https://arxiv.org/pdf/1211.3711.pdf
LAS论文:Listen, Attend and Spell https://arxiv.org/pdf/1508.01211.pdf
A Comparison of Sequence-to-Sequence Models for Speech Recognition https://ai.google/research/pubs/pub46169
@川陀学者
版权声明
本文版权归《川陀学者》,转载请自行联系。
点击下方链接地址,了解CCAI 2019更多信息
CCAI 2019 中国人工智能大会ccai.cn 发布于 2019-08-09 人工智能 语音识别推荐阅读
Attention based model for 语音识别
知乎 Attention based model 是什么,它解决了什么问题?大家从不同的角度解释了Attention based model的机制和在NLP,图像等领域的应用,但是对Attention based model在语音识别的领域解释…
Qoboty基于CTC的语音识别基础与实现
范汝超Speech Recognition(2)--LAS
steph...发表于AI-琅嬛...端到端语音识别时代
希尔贝壳还没有评论
写下你的评论...标签:RNN,模型,语音,https,CTC,End2End,model 来源: https://www.cnblogs.com/cx2016/p/13845817.html