(2)如何使用AutoEncoder预测客流量
作者:互联网
(2)如何使用AutoEncoder预测客流量
文章名称:《Traffic Flow Prediction With Big Data: A Deep Learning Approach》

中科院吕宜生老师2015年发在IEEE Transactions on Intelligent Transportation Systems上的一篇文章(运输科技2区,IF:4.051),被引807多次(可望不可及啊)。
01Introduction 和Literature Review
本文的简介部分组成:
首先,介绍了道路交通短时客流预测的意义。其次,由于大数据时代下的数据驱动,基于机器学习的预测方法得到了很大的关注(引出下文)。紧接着,介绍了的深度学习的优势:深度学习算法利用多层或深度神经网络体系结构,从最低层次到最高层次逐渐提取数据的固有特征,能够发现数据中大量的内在结构特征。由于交通流过程的复杂性,深度学习算法可以在不需要先验知识的情况下表征交通特征,对于交通流预测具有良好的性能。然后,介绍了文章的主要工作和创新点。最后简单写下文章结构。
本文的文献综述部分就是将既有的研究方法进行了分类,然后列了几个主流的方法,每个方法后面罗列了一点文献。然后进行了如下两点总结:
(1)很难说一种方法在任何情况下都明显优于其他方法。其中一个原因是,所提出的模型是用少量单独的特定交通数据建立的,而交通流预测方法的准确性依赖于所收集的时空交通数据中嵌入的交通流特征。
(2)虽然神经网络的深层结构可以学习到比浅层网络更强大的模型,但是现有的基于神经网络的交通流预测方法通常只有一个隐含层。基于梯度的训练算法很难训练出层次较深的神经网络。深度学习的最新进展使得训练深度架构成为可能,这表明深度学习模型在某些领域具有优于或可与最先进的方法相媲美的性能。
02 创新点
第一次使用深度学习架构,嵌入Stacked AutoEncoder(SAE)堆叠自编码器作为主体网络结构块来预测交通流。
03 主体内容
何为AutoEncoder ? 自编码也是一种网络结构,即将数据输入到输入层,通过编码和解码(其实也就是几层神经网络结构),得到output,与其他网络不同的是,其损失函数是使输入和输出之间的error尽可能小,即使输出尽可能地还原输入,如下所示,输入是X,输出是Z(X),损失函数是θ。
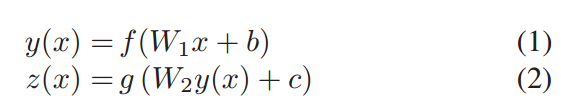
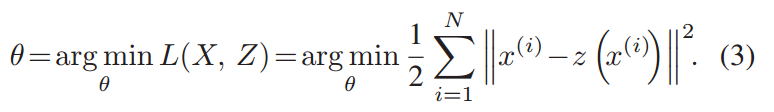
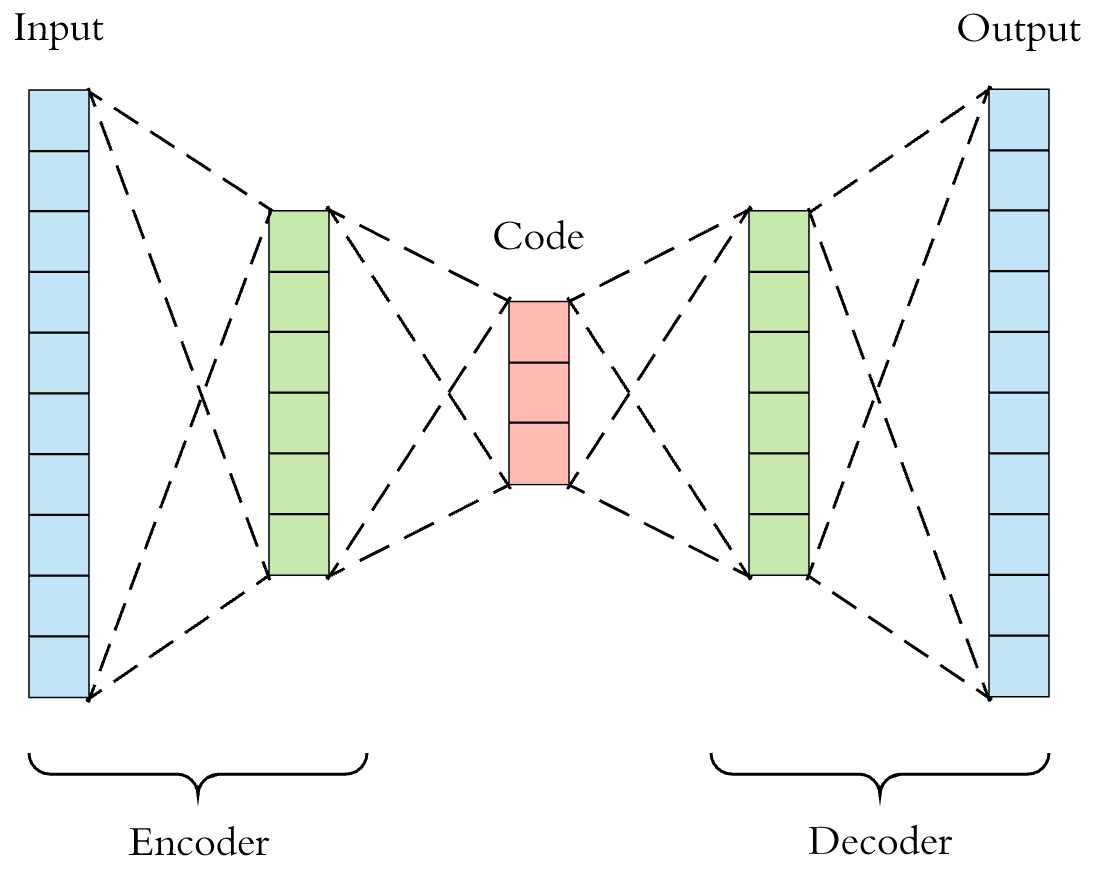
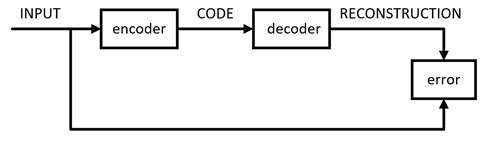
AE示意图
SAE模型是通过叠加自编码器,将底层自编码器的输出作为当前层的输入,形成一个深度网络。假设有l层的SAEs,第一层被训练为一个自动编码器,训练集作为输入。在获得第一个隐层后,将第k个隐层的输出作为第(k + 1)个隐层的输入。这样,多个自编码器就可以分层堆放。
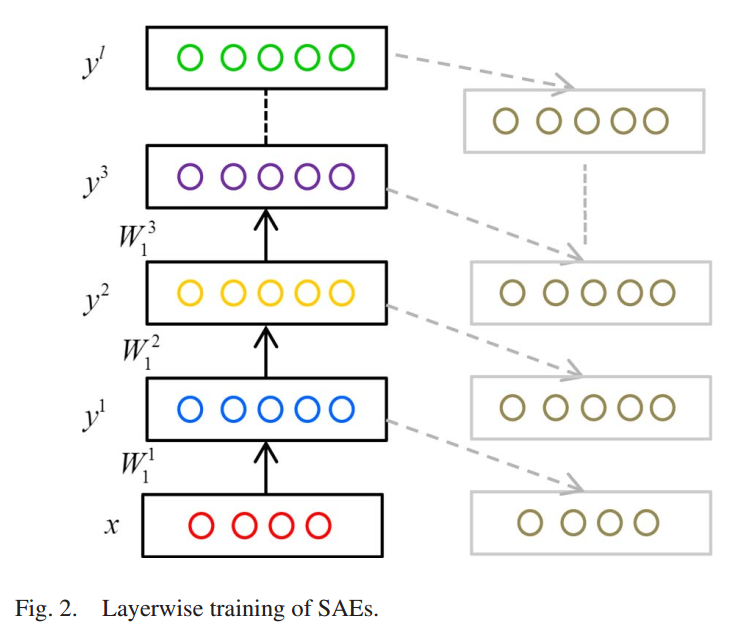
SAE示意图
为了使用SAE网络进行流量预测,我们需要在顶层添加一个标准的预测器。在此基础上,提出了一种基于logistic回归的交通流预测方法。SAEs加预测器构成了整个交通流预测的深层体系结构模型。
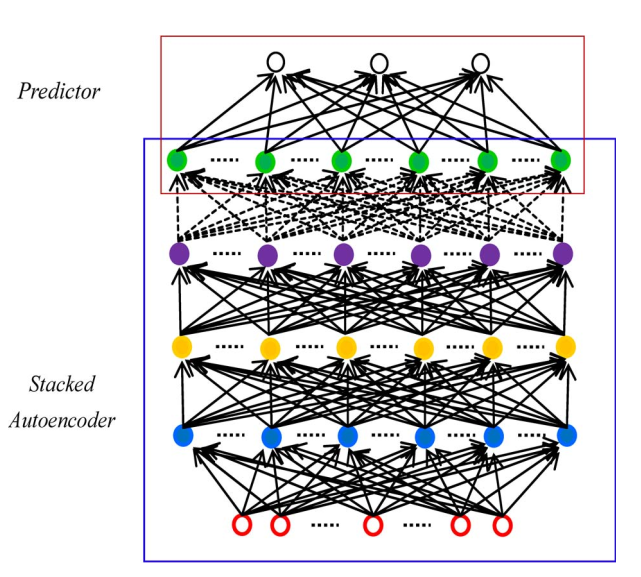
Model Structure
训练算法:
将BP方法与梯度下降算法相结合,可以直接训练深度网络。不幸的是,以这种方式训练的深层网络性能很差。最近,Hinton等人开发了一种贪婪分层无监督学习算法,可以成功地训练深度网络。使用贪心分层无监督学习算法的关键是采用自底向上的方式逐层对深层网络进行预训练。在预训练阶段后,利用BP再自顶向下对模型参数进行调整。(看着高大上,原理懂,技术层面暂时还不会……)
我们应该如何训练深度网络呢?贪婪训练方法是取得一定成功的一种方法。简单来说,逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,我们把已经训练好的前k-1层固定,然后增加第k层(也就是将我们已经训练好的前k-1的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差)。(原文:https://blog.csdn.net/dcxhun3/article/details/48131745)
模型配置:
PeMS系统采集的30秒时间间隔的交通流量数据,并以5分钟时间粒度进行积聚,3个月工作日的数据,前两个月用来训练,第三个月用来测试。另外,需要确定输入层的大小、隐藏层的数量以及每个隐藏层中隐藏单元的数量。对于输入层,我们使用所有高速公路收集的数据M作为输入,即考虑到了交通流的空间相关性。考虑到交通流的时间关系,为了预测t时段的交通流,我们应该使用之前时段的交通流数据,即X t - 1 ,X t – 2…… X t – r。因此,该模型内在地考虑了交通流的时空相关性。输入空间的维数为mr,而输出的维数为m,其中m为高速公路的数量。
PEMS是英文Portable Emission Measurement System的简写,中文译为“便携式排放测试系统”或者“车载尾气检测设备”。PEMS由车载气态污染物测量仪OBS-2200 ...本文利用该模型分别对15分钟、30分钟、45分钟和60分钟的交通流进行了预测。我们选择r从1到12,隐藏层的大小从1到6,隐藏层单元的数量从{100, 200, 300, 400, 500, 600, 700, 800, 900, 1000}。
实验结果:
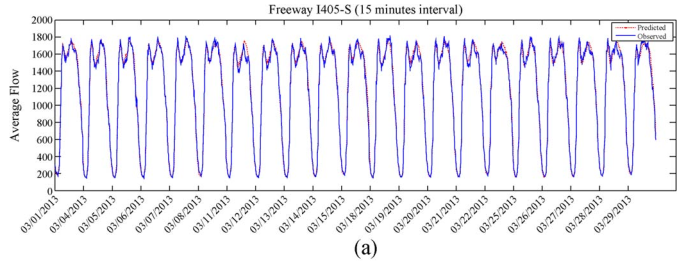
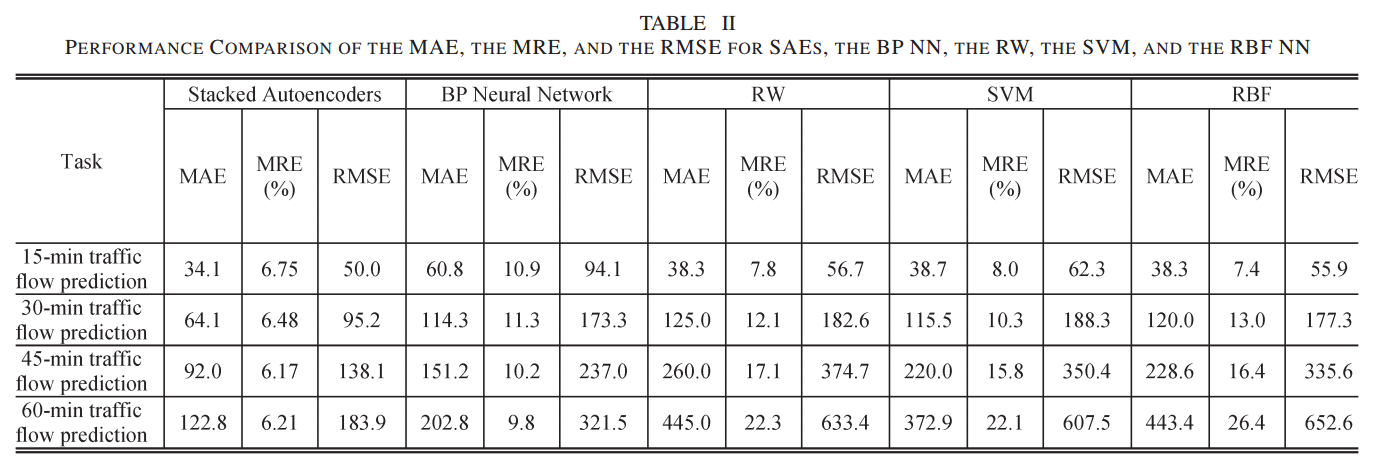
04 特别之处
文章给出的结论中,不同时间粒度下的预测模型使用的网络结构是不同的,很值得借鉴!(15分钟3层,每层400个神经元,30分钟3层,每层200个神经元,45分钟2层,每层500个神经元,60分钟4层,每层300个神经元。)从结果中可以看出,隐藏层的最佳数量至少为2层,最多不超过5层。从经验中得到的教训表明,神经网络的隐层数既不应过小也不应过大。我们的结果证实了这些教训
05 展望
本文的预测层只是一个逻辑回归。将其扩展到更强大的预测器可能会进一步提高性能。
06 Writing Tips from This Paper
(1)Herein (在本文中), a stacked autoencoder (SAE) model is used to learn generic traffic flow features, and it is trained in a layerwise greedy fashion.(in a … fashion, 以一种什么样的方式)
(2)To the best of the authors’ knowledge, it is the first time that the SAE approach is used to represent traffic flow features for prediction.(引出自己的创新点用,深深的套路)
(3)The remainder/rest of this study/paper is organized as follows.
关注微信公众号《当交通遇上机器学习》,后台回复“数据”即可获取高达175G的四个月的滴滴GPS数据和滴滴订单数据的获取方式。
标签:交通流,AutoEncoder,预测,训练,网络,深度,客流量,输入 来源: https://www.cnblogs.com/cx2016/p/13794832.html