论文导读-从Faster-RCNN/Mask RCNN/Cascade-RCNN到HTC
作者:互联网
论文导读-从Faster-RCNN/Mask RCNN/Cascade-RCNN到HTC
最近在看image segmentation的论文,有篇题为《Hybrid Task Cascade For Instance Segmentation》的paper写得非常地不错,为了很好地理解该篇论文,我顺便把其引用的几篇重要论文以及对应的源码(mmdetection),给看了。
这几篇重要论文包括:
(1)Faster-RCNN:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
(2)Mask-RCNN:《Mask R-CNN for Object Detection and Segmentation》
(3)Cascade-RCNN:《Cascade R-CNN: Delving into High Quality Object Detection》
(4)HTC:《Hybrid Task Cascade For Instance Segmentation》
首先介绍:Faster-RCNN
Faster-RCNN模型是目标检测领域一篇很牛逼的论文,它提出了一种名为RPN(Region Proposal Network)的网络结构,来提出候选框(bounding box),并以此替代传统方法(比如RCNN/Fast RCNN)中的Selective Search方法。解决了Fast RCNN算法没有实时性的问题。
这是Faster-RCNN的总体结构图。具体来说,
输入:被resize为w*h的图
操作:(1)经过多层卷积操作,得到feature maps,(2)这个feature maps一方面输出给RPN网络用于提取多个候选框,每个候选框的格式为(x,y,w,h);另一方面,feature maps与单个候选框结合,从feature map中唯一定位出局部图像(image patch),多个候选框能得到多个局部图像(image patch)。(3)由于每个局部图像(image patch)的大小不一,将其输入给ROI Pooling层,处理成相同大小的feature map。至此,每个得到长度相同的feature map;(4)将每个feature map分别输入给classifier和bbox regression,得到这个局部图像的分类,以及候选框的位置回归。
输出:目标物的候选框。具体:每个候选框都会有类别分数(来自classifier),以及候选框位置的精确调整值(来自bbox regression)。这里根据类别分数,确定候选框属于哪个目标类别;根据位置调整值,调整RPN输出的位置: 。
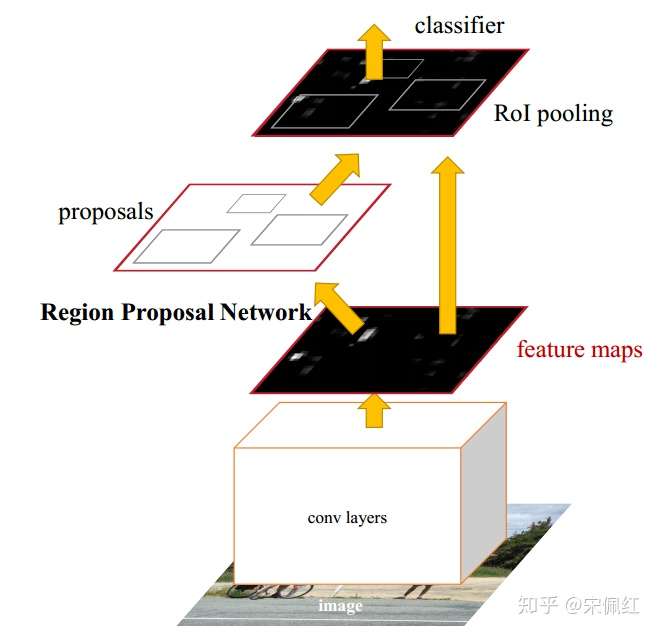 Faster RCNN模型的结构总览图
Faster RCNN模型的结构总览图
具体介绍:
具体细节图如下图所示:
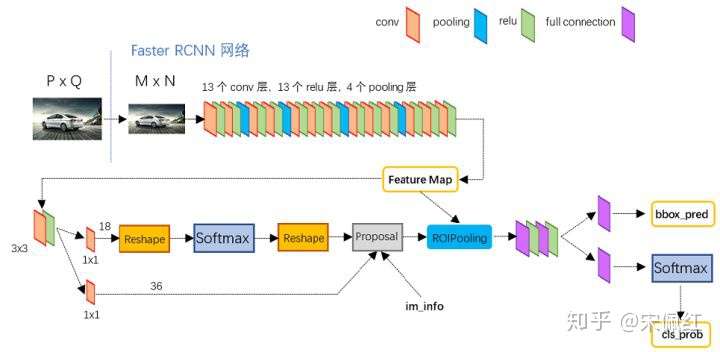 Faster RCNN的细节图
Faster RCNN的细节图
操作(0):首先将不同大小的输入图像,resize为固定大小M*N的图像
操作(1)是多个conv+relu+pooling的组合,这里选择有很多,比如VGG-Net,ResNet50,比如:ResNet50取stage2输出的feature maps。这部分比较简单,不再过多描述。
操作(2):RPN网络主要用于候选框的获取。
def forward_single(self, x):
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred其中,x为操作(1)输出的feature maps,rpn_conv为一层3*3 的卷积操作,rpn_cls为1*1的卷积操作,out_channel = num_anchor * num_classes,比如 anchor_scales=[2, 4, 8], anchor_ratios=[0.5, 1.0, 2.0],那么num_anchor=3*3=9,比如RPN阶段只区分前景和后景,那么num_classes=2,这里out_channel=9*2=18。rpn_reg为1*1的卷积操作,out_channel=num_anchor * 4,4表示每个anchor都拥有(x,y,w,h)四个值,这里out_channel=9*4=36。
rpn_cls_score = rpn_cls_score.reshape(-1, 2)
scores = rpn_cls_score.softmax(dim=1)[:, 1]这里对rpn_cls做reshape,是为了方便计算softmax值,每个bbox都会有两个概率值:前景概率/后景概率,用于判定bbox中的图像(image patch)是否属于前景/后景。
# 取top_nms_pre
_, topk_inds = scores.topk(nms_pre)
rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
anchors = anchors[topk_inds, :]
scores = scores[topk_inds]
....
proposals, _ = nms(proposals, nms_thr)
proposals = proposals[nms_post, :]然后根据前景值对scores进行排序,取前nms_pre个的scores值,以及其对应的rpn_bbox_pred和anchors。根据rpn_bbpx_pred对anchors的location进行微调,获得调整后的bbox, 。接着,做bbox的二次过滤,使用非极值抑制法(nms)过滤部分bbox,并取前nms_post个bbox(此时proposals是有序的)。最终输出bbox。
需要说明的是,这里的anchors的来源,每个像素点都会有num_anchor个anchor,那么对于大小为w*h的feature map,就会有w*h*num_anchor个bbox。anchors是这bbox的集合,这里可以根据像素点位置,以及anchor_scales和anchor_ratios唯一确定出bbox的位置(x,y,w,h)。后续的rpn_bbox_pred和rpn_cls都是对这w*h*num_anchor个bbox的位置回归,以及给出类别分数。
这里anchor_ratios是指anchor的宽长比,代码中会设置anchor_base_size的值,例如=4,那么若anchor_scales=[8],那么anchor的base_width=32, base_height=32。这样,知道中心点的位置,知道anchor_ratio,就可以知道anchor的具体位置了。
比如,anchor_ratios=[0.5,1,2],anchor_pt = [100, 100],那么anchor_width_ratio=[0.7,1,1.4], anchor_height_ratio=[1.4,1,0.7],且知道base_width=32, base_height=32,可得anchor_width=[22, 32, 49], anchor_height=[49,32,22],根据anchor_pt就可得anchor的具体位置了, anchor_top_left = [(100-22, 100-49),(100-32, 100-32),(100-49, 100-22)], anchor_bottom_right=[(100+22, 100+49),(100+32, 100+32),(100+49, 100+22)]
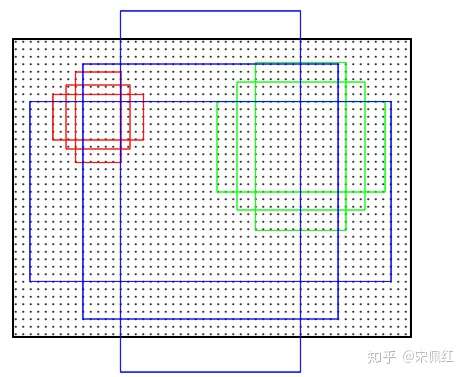 anchor展示,这里每个点都有3个anchor
anchor展示,这里每个点都有3个anchor
操作(3)每个bbox都可以在feature map上唯一定位出一个局部图像(image patch),它们大小不一,这里使用ROI Pooing层对其进行统一, 得到统一大小的feature map。
操作(4):将feature map输入给多层卷积,做特征提取。然后一方面输出给fc层,得到bbox_pred,另一方面输出给fc层+softmax层,得到cls_prob。
图像后处理阶段:根据bbox_pred对rpn输出的bbox的location进行微调,利用cls_prob来判定该bbox所在区域为哪个目标物。然后利用非极值抑制算法过滤无效bbox,得到最终的输出。
接着介绍Mask-RCNN
Mask-RCNN部分,介绍地特别地好,可以参考:https://zhuanlan.zhihu.com/p/37998710
接着介绍Cascade RCNN
faster-rcnn存在的问题:
(1)IOU阈值设的低,会引起noisy detection;IOU阈值设的高,会过拟合。
Cascafe R-CNN致力于解决该问题。
实验表明:(1)没有一直很好的阈值。
(2)通过regressor,output IOU会高于 input IOU。即,递增使用threshold,detector的输出能很好地被作为下一个阶段的输入。
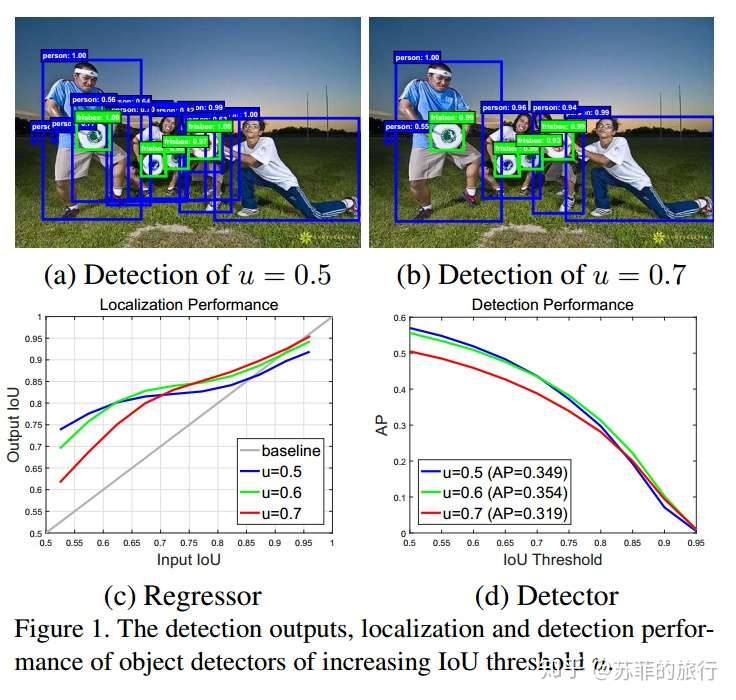
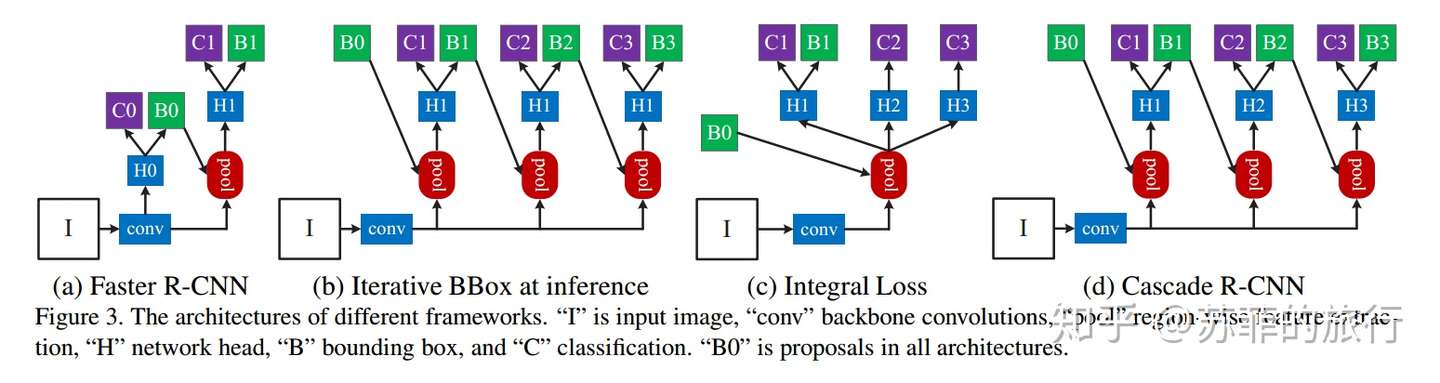
因为(a)只能使用一个IOU阈值
改进方案(b):多个bbox级联,可以递增地设置多个IOU阈值。
(b)的缺点:输入的bbox change分布不同,但H1没变,可能不能很好地拟合数据,得到有效的bbox regression。
实验观察:设置不同IOU阈值时,bbox regression学习到的bbox change的分布改变了,
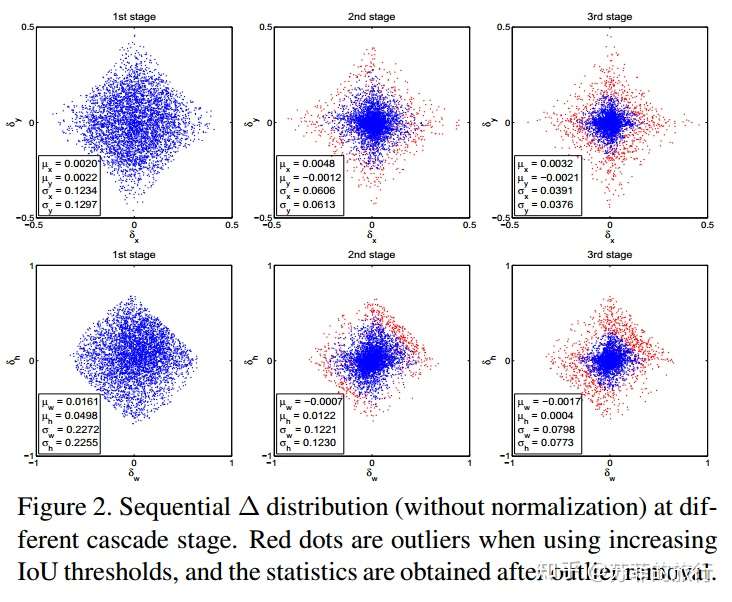
其中:参数表示bbox的回归,
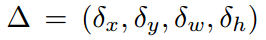
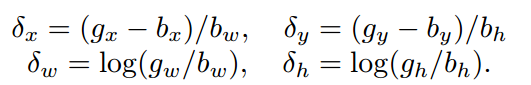
改进方案(c):pool输出给多个不同H,且只使用B1,可以递增地设置多个IOU阈值,然后多个C
(c)的缺点:高质量的C2,C3用于处理B1(low quality)数据,可能不能很好地拟合数据。
改进方案(d):在(b)地基础上,使用不同地H。
loss函数:
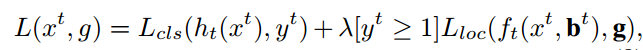
只考虑IOU值大于阈值的bbox
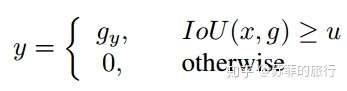
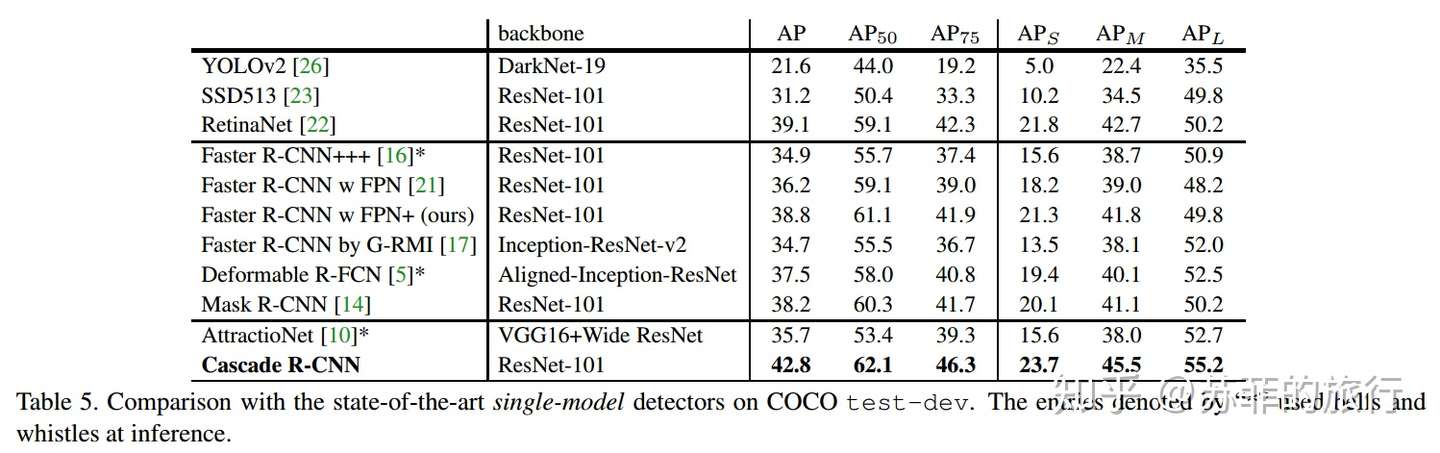
实现效果:
HTC
优点:
(1)Cascade-Mask-RCNN方法:没有很好地利用前一时刻的mask结果。
(2)能够区分难被区分的背景
四种改进方案:
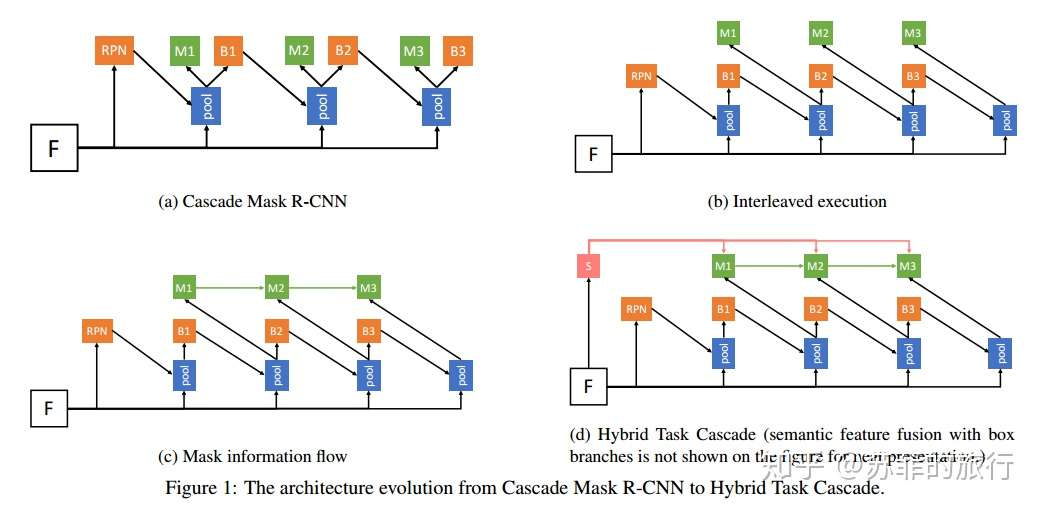
改进方案(a):直接组合cascade-rcnn和mask-rcnn
具体公式:P = ROI Align / ROI_pooing, Bt表示取box head(得到cls和reg的结果), mt表示mask head(得到mask feature 和mask prediction)
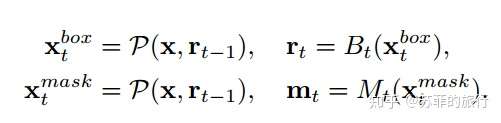
缺点: mask的改进只在bbox的改进上做,没有直接利用上一阶段mask。
改进方案(b)交叉bbox和mask,这样mask可以利用改进后的bbox,使得mask prediciton更加精准。
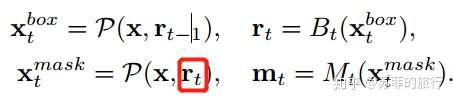
缺点: mask之间没有交互
改进方案(c):mask利用前一时刻的mask feature
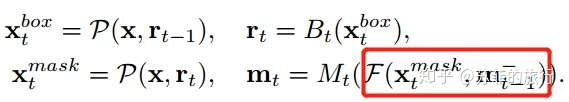
其中: gt表示1*1的conv
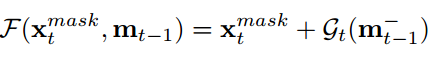
m-(t-1)表示 deconvolutional 前的roi feature
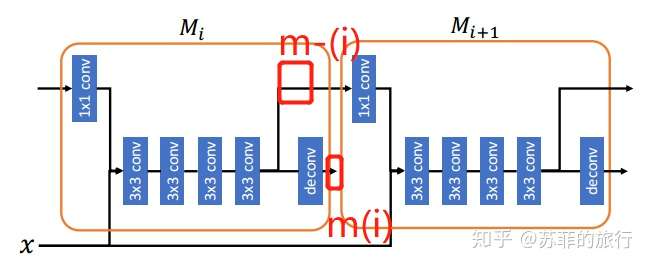
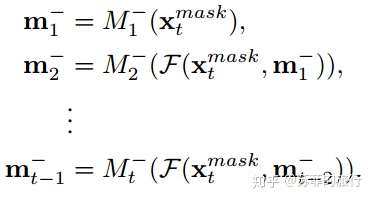
缺点: 没有直接使用背景信息。
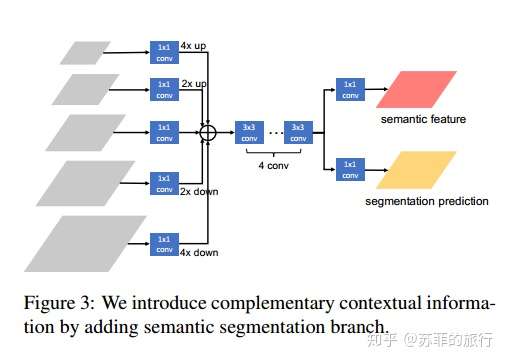
改进方案(d):增加多尺度semantic Segmentation分支,增加背景信息
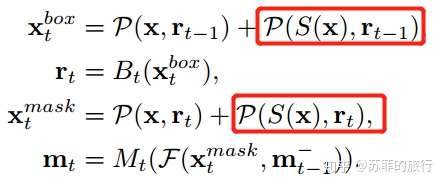
s模块:
loss设置:
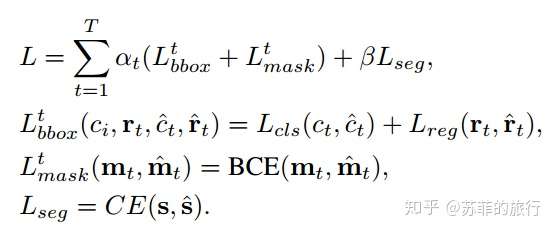
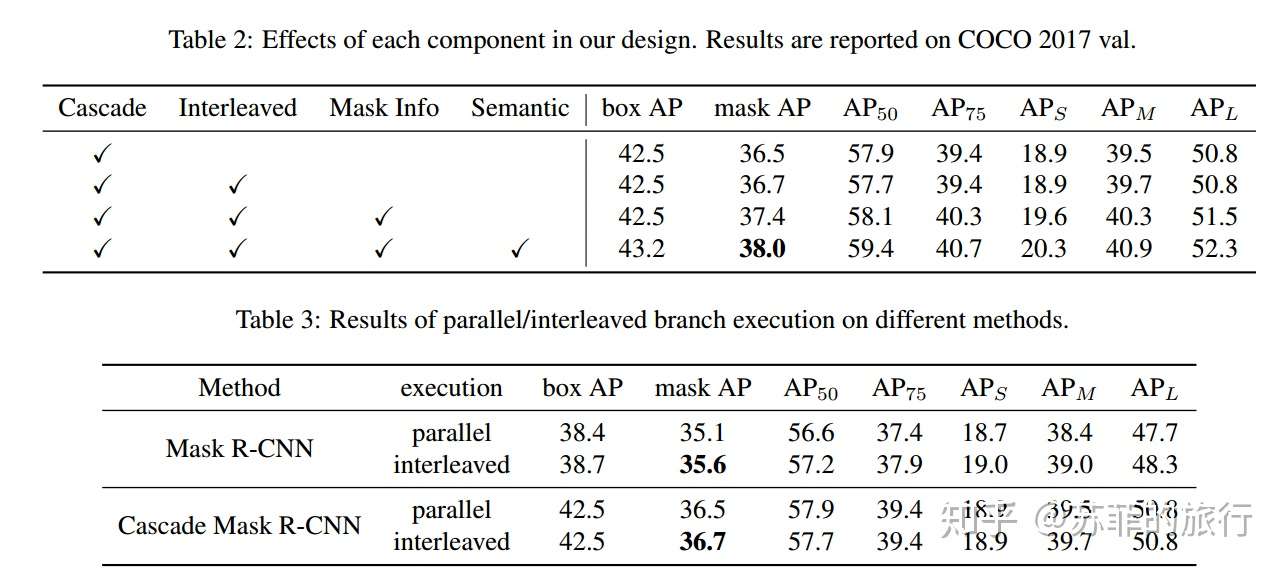
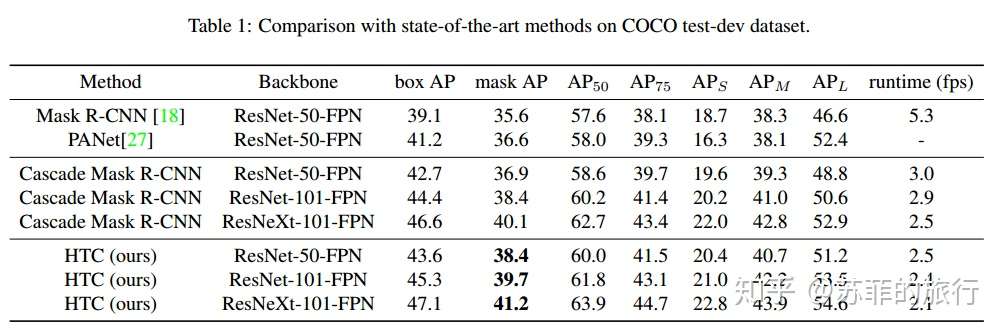
实验效果:
编辑于 2019-08-05 计算机视觉 图像分割 目标检测
推荐阅读
源码解读:Faster RCNN的细节(一)
TeddyZhangFaster-rcnn 代码详解
rootxuan目标检测算法 - Faster RCNN深度解析(前向计算篇)
风生水起实例分割算法之Mask R-CNN论文解读
BBuf发表于Giant...还没有评论
写下你的评论...标签:HTC,Faster,feature,bbox,RCNN,100,anchor,rpn 来源: https://www.cnblogs.com/cx2016/p/13760879.html