TridentNet:处理目标检测中尺度变化新思路
作者:互联网
TridentNet:处理目标检测中尺度变化新思路
Naiyan Wang 机器学习、人工智能、深度学习(Deep Learning)等 3 个话题下的优秀回答者今天破天荒地为大家介绍一篇我们自己的工作(Scale-Aware Trident Networks for Object Detection),因为我是真的对这个工作很满意,哈哈。这篇文章主要要解决的问题便是目标检测中最为棘手的scale variation问题。我们使用了非常简单干净的办法在标准的COCO benchmark上,使用ResNet101单模型可以得到MAP 48.4的结果,远远超越了目前公开的单模型最优结果。(代码已经开源在SimpleDet中:TuSimple/simpledet)
在正式介绍我们的方法之前,我先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。
 几种处理scale variation方法的比较
几种处理scale variation方法的比较
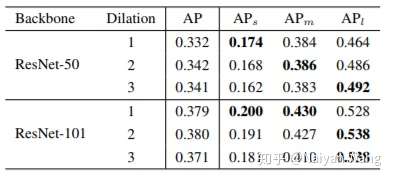
我们方法的motivation其实早在16年刷KITTI榜单的时候就有初步形成,但是一直因为各种原因搁置,直到今年暑假有两位很优秀的同学一起将这个初步的想法改进,做扎实,结果其实也很出乎我最开始的意料。我们考虑对于一个detector本身而言,backbone有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate和receptive field。对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。但是没有工作,单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。所以,我们做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,我们便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。我们很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。于是下面的问题就变成了,我们有没有办法把不同receptive field的优点结合在一起呢?
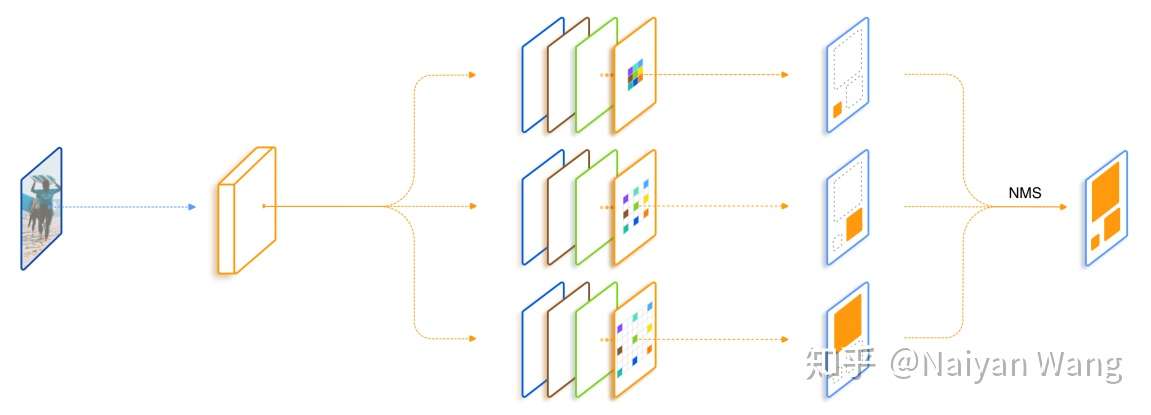
所以我们最开始的一个想法便是直接加入几支并行,但是dilation rate不同的分支,在文中我们把每一个这样的结构叫做trident block。这样一个简单的想法已经可以带来相当可观的性能提升。我们进一步考虑我们希望这三支的区别应该仅仅在于receptive field,它们要检测的物体类别,要对特征做的变换应该都是一致的。所有自然而然地想到我们对于并行的这几支可以share weight。 一方面是减少了参数量以及潜在的overfitting风险,另一方面充分利用了每个样本,同样一套参数在不同dilation rate下训练了不同scale的样本。最后一个设计则是借鉴SNIP,为了避免receptive field和scale不匹配的情况,我们对于每一个branch只训练一定范围内样本,避免极端scale的物体对于性能的影响。
总结一下,我们的TridentNet在原始的backbone上做了三点变化:第一点是构造了不同receptive field的parallel multi-branch,第二点是对于trident block中每一个branch的weight是share的。第三点是对于每个branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。这三点在任何一个深度学习框架中都是非常容易实现的。
在测试阶段,我们可以只保留一个branch来近似完整TridentNet的结果,后面我们做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
 TridentNet网络结构
TridentNet网络结构
我们在论文中做了非常详尽的ablation analyses,包括有几个branch性能最好;trident block应该加在网络的哪个stage;trident block加多少个性能会饱和。这些就不展开在这里介绍了,有兴趣的读者可以参照原文。这里主要介绍两个比较重要的ablation。
第一个当然是我们提出的这三点,分别对性能有怎样的影响。我们分别使用了两个很强的结构ResNet101和ResNet101-Deformable作为我们的backbone。这里特地使用了Deformable的原因是,我们想要证明我们的方法和Deformable Conv这种 去学习adaptive receptive field的方法仍然相兼容。具体结果见下。
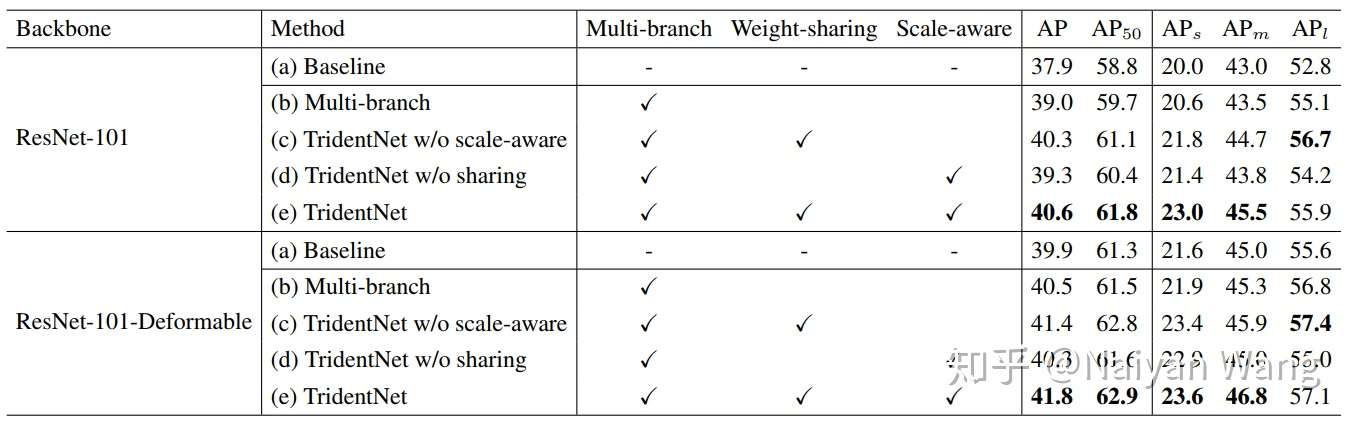
可以看到,在接近map 40的baseline上,我们提出的每一部分都是有效的,在这两个baseline上分别有2.7和1.9 map的提升。
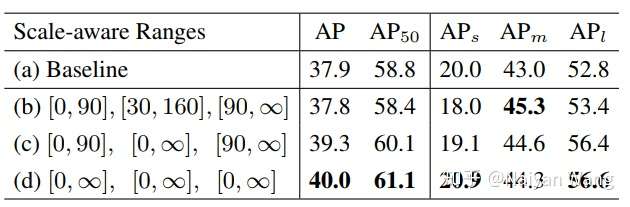
另外一个值得一提的ablation是,对于我们上面提出的single branch approximation,我们如何选择合适的scale-aware training参数使得近似的效果最好。其实我们发现很有趣的一点是,如果采用single branch近似的话,那么所有样本在所有branch都训练结果最好。这一点其实也符合预期,因为最后只保留一支的话那么参数最好在所有样本上所有scale上充分训练。如果和上文40.6的baseline比较,可以发现我们single branch的结果比full TridentNet只有0.6 map的下降。这也意味着我们在不增加任何计算量和参数的情况,仍然获得2.1 map的提升。这对于实际产品中使用的detector而言无疑是个福音。
我们还和经典的feature pyramid方法FPN做了比较。为了保证比较公平,我们严格遵循Detectron中的实现方式,并使用两层fc作为detector的head。可以看到在这样的setting下,FPN其实对于baseline而言小物体有一定提升,然而大物体性能下降,综合下来并没有比baseline有提高,但是我们的方法仍然可以持续地提升2.2个点map,就算使用single branch approximation,仍然也有1.2个点的提升。这充分证明了我们的方法的普适性。
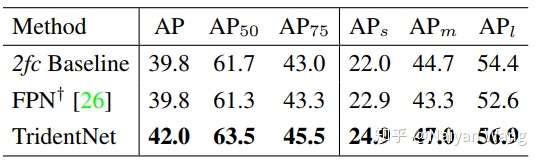
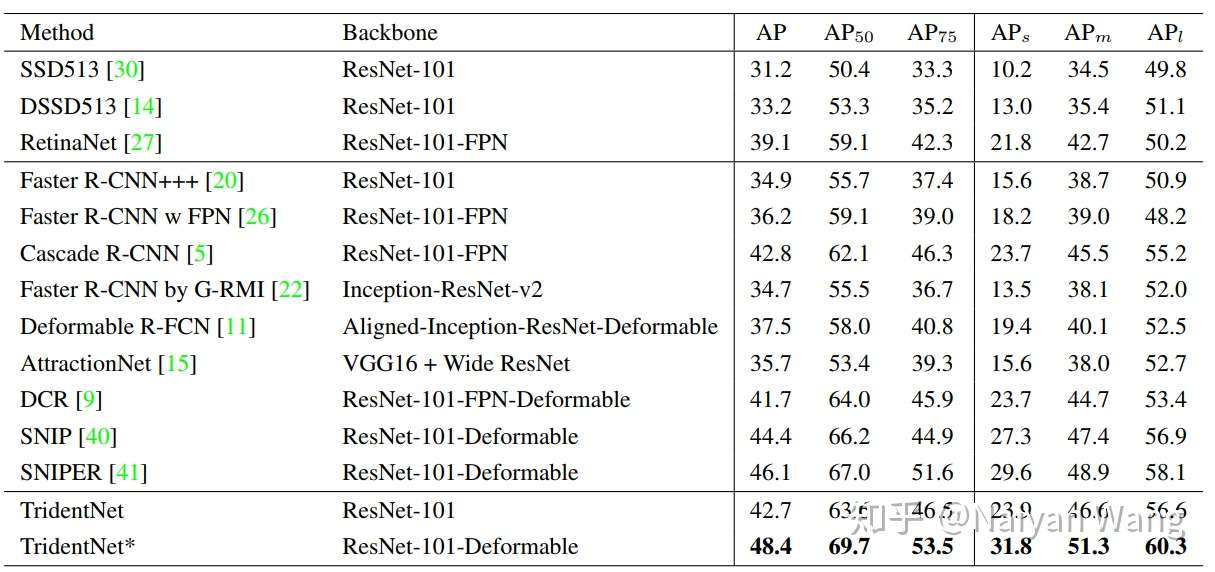
最后我们将我们的方法和各paper中报告的最好结果相比较。但是其实很难保证绝对公平,因为每篇paper使用的trick都不尽相同。所以我们在这里报告了两个结果,一个是ResNet101不加入任何trick直接使用TridentNet的结果,一个是和大家一样加入了全部trick(包括sync BN,multi-scale training/testing,deformable conv,soft-nms)的结果。在这样的两个setting下,分别取得了在COCO test-dev集上42.7和48.4的结果。这应该分别是这样两个setting下目前最佳的结果。single branch approximation也分别取得了42.2和47.6的map,不过这可是比baseline不增加任何计算量和参数量的情况下得到的。
最后的最后,我们会在本月内开源整套训练代码,可以很方便复现TridentNet结果以及各种常见trick。这个框架下也包含了其他Detection和Instance Segmentation方面的经典工作,敬请期待!
文章被以下专栏收录
推荐阅读
我这两年的目标检测
打个酱油发表于小白的视觉...目标检测:Anchor-Free时代
陀飞轮目标检测:FCOS(2019)
TeddyZhang【Roadmap】目标检测
本文汇总部分经典和最新的目标检测方法和Tricks,但不介绍基础知识及深入讨论。 深度学习时代,目标检测领域涌现了大量的算法,发展历程如下,因为算法太多而篇幅有限,只能选择部分代表作…
yanwa...发表于AI约读社384 条评论
写下你的评论... 精选评论(3)-
![[已重置]](https://pic4.zhimg.com/da8e974dc_s.jpg) [已重置]2019-01-08
[已重置]2019-01-08
几个问题: (1)把一个提取特定特征模式的匹配滤波器变化尺度去提取多尺度特征,和使用一个定尺度滤波器提取FPN中变尺度特征有什么区别么? (2)变化滤波器尺度的时候填充0是不是会遗漏很多信息,为什么不是局部拷贝? (3)共享参数理论上性能不及不同尺度独立寻找参数, 当然可以收敛性更好一些,提取的特征在不同尺度上都有效所以更通用,除此之外还有哪些好处?(4)如果是多层使用这个策略,在后续阶段会不会出现不同尺度的特征混合到一起了?还是不同尺度的特征放在不同的通道不会随便混合?这个和densenet直接混合多尺度特征的方法有什么区别? 谢谢。
-
 藏云阁主2019-01-08
藏云阁主2019-01-08
我终于看到一篇真正让机器去学习“什么是scale”这个问题的文章了。。。看了这么多关于scale的文章,都没有很好地做到让机器明白,不同scale的猫本质是一只猫,只是距离远近导致的scale变化,基本上都是变相地增加参数让网络去记住大猫中猫小猫这三种猫。这篇文章的motivation完全击中了我心里的想法,并且确实提升了效果。要做到not only make sense but also work真的不容易!
-
 beyond回复Naiyan Wang (作者)2019-01-08
beyond回复Naiyan Wang (作者)2019-01-08
看了这个人的回复,我就知道我的论文审稿人都是哪来的了,他们这种说法往极端了就是已经有人用CNN来做物体检测了,你这有什么novelty
-
 长安太保2019-01-08
长安太保2019-01-08
请问有paper link吗?Google搜不到。
-
Naiyan Wang (作者) 回复长安太保2019-01-08
sorry,已经更新在第一段里了
-
 李韶华2019-01-08
李韶华2019-01-08
我在一些classification问题上用了类似的trick。。还以为这trick早有了
-
Naiyan Wang (作者) 回复李韶华2019-01-08
分类和检测本质不同,没什么可比性。
-
李韶华回复Naiyan Wang (作者)2019-01-08
是medical image,某种abnormal pattern可以在image中以多尺度多次出现,其实和detection差不多,只是label不精细
-
 尼箍纳斯凯奇2019-01-08
性能刷的很高,简单实用,很多检测任务都可以直接上啊[机智] 准备这几天就试试了。
尼箍纳斯凯奇2019-01-08
性能刷的很高,简单实用,很多检测任务都可以直接上啊[机智] 准备这几天就试试了。
-
 eric2019-01-08
该评论已删除
eric2019-01-08
该评论已删除
-
Naiyan Wang (作者) 回复eric2019-01-08
哥?还有什么区别?还同一波人?醒醒再来喷?
-
 鲭兜回复eric2019-01-08
鲭兜回复eric2019-01-08
还是有明显区别的,这个工作可以看成是rfb-net的延伸
-
 deepDrowner2019-01-08
1. 即使只用一个branch,但由于backbone的输出分辨率比较大,是不是还是比较慢。。
deepDrowner2019-01-08
1. 即使只用一个branch,但由于backbone的输出分辨率比较大,是不是还是比较慢。。
2.小目标利用的特征依旧是大目标特征的局部,这个在fpn里面存在的问题,本篇文章是不是还是存在。。 -
Naiyan Wang (作者) 回复deepDrowner2019-01-08
- 现在的downsample rate是16,和baseline保持一致。
- 并不是,小目标检测的还是完整的小物体,因为weight和检测大物体的weight是完全一致的,只是RF有差。这也就是我们说的FPN 对不同scale物体的representation power不同的原因。这是一个很好的问题。
-
冬日的海回复deepDrowner2019-01-08
大佬,能否解释一下为什么小目标利用的特征是大目标特征的局部这句话啊
-
 Gundam2019-01-08
nice work,期待源码
Gundam2019-01-08
nice work,期待源码
-
Zhaozhe Song2019-01-08
single branch approximation论文里提了,但是这里是不是漏了
-
Naiyan Wang (作者) 回复Zhaozhe Song2019-01-08
嗯,我怕写太长大家不爱读了,所以在这里只贴了一个对single branch的ablation实验。。。
-
Naiyan Wang (作者) 回复Zhaozhe Song2019-01-08
哦,我知道你意思了。。。那我还是补充下吧。。
-
 Bin GAO2019-01-08
每次读大佬的文章,都觉得思路很清晰,解决问题有理有据,特别insights,但是到自己就是想不到 。
Bin GAO2019-01-08
每次读大佬的文章,都觉得思路很清晰,解决问题有理有据,特别insights,但是到自己就是想不到 。
-
 Wayne2019-01-08
Wayne2019-01-08
single branch approximation为啥还能提升呢? 和baseline的区别有: 1带了dilation,2训练时是三个branch一起训练。不清楚这两点哪个贡献大?
-
Naiyan Wang (作者) 回复Wayne2019-01-08
同样重要,我们开始讲motivation的时候有一个只train dilation=2的branch的结果,可以看到还没有我们三个一起训练然后保留一个的效果好。
-
Wayne回复Naiyan Wang (作者)2019-01-08
厉害!看到了,在Table 1 --
-
 Qjtbs2019-01-08
Qjtbs2019-01-08
简单实用的方法,赞;但是各个trident不共享weight效果却变差了,感觉这里还可以深入的找下原因
-
Naiyan Wang (作者) 回复Qjtbs2019-01-08
啊?没变差啊,table2里面res101和res101-deformable都涨了的啊。
-
 longbye0回复Naiyan Wang (作者)2019-01-08
longbye0回复Naiyan Wang (作者)2019-01-08
Table 2(c)在multi branch上用了weight sharing涨了,是因为文章里讲的不共享的多分支版本overfitting吗?
-
 Andy2019-01-08
Andy2019-01-08
很棒的工作!论文中大佬是基于Faster-RCNN的工作做的实验吧,不知道有没有在one-stage框架上做过实验啊~
-
Naiyan Wang (作者) 回复Andy2019-01-08
这个还没有,因为我们内部不用one stage的方法。等我们放了代码你可以迁移下试试哈~
-
zxhr2793回复Andy2019-01-09
ECCV18有篇使用SPP构建了多分支并行的特征金字塔可以看一下,
-
 whjxnyzh2019-01-08
gluoncv来一波?
whjxnyzh2019-01-08
gluoncv来一波?
-
Naiyan Wang (作者) 回复whjxnyzh2019-01-08
会放在我们另外一套mxnet的detection框架里。。。
-
whjxnyzh回复Naiyan Wang (作者)2019-01-08
为啥重复造轮子
-
 孙杨威2019-01-08
孙杨威2019-01-08
Table 6有点没看懂。。。另外table2里(d)相对于(b) Multi-branch加了Scale-aware,res101和res101-deformable一个涨点一个掉点是为啥?
-
Naiyan Wang (作者) 回复孙杨威2019-01-08
table 6就是说如果最后只保留一个branch,每个branch的valid range怎样影响性能。
没有weight sharing其实很容易导致训练不充分和overfitting,加了deformable自由度更高,我猜这个问题吧。。不过就差0.2,也可能就是没啥用差不多啦。
-
 Angzz回复Naiyan Wang (作者)2019-01-21
Angzz回复Naiyan Wang (作者)2019-01-21
按照我的理解,Table 6的(b)结果应该比(d)高才对啊,因为野weight share了,也有valid range了,求解~
-
 Tyrone2019-01-08
什么时候开源呀[飙泪笑]
Tyrone2019-01-08
什么时候开源呀[飙泪笑]
-
Naiyan Wang (作者) 回复Tyrone2019-01-08
快了快了,本月内一定。
-
 ning ji回复Naiyan Wang (作者)2019-02-12
ning ji回复Naiyan Wang (作者)2019-02-12
还没出??说话不算话!!!!
-
 merlin2019-01-08
大佬大佬~简单明了~
merlin2019-01-08
大佬大佬~简单明了~
-
孙杨威2019-01-08
Table6的实验是说三个分支都用所有scale来训练,最后inference的时候只在branch-2上做这个意思吗?这个结果会比三个分支不同scale分别训练最后三个分支同时预测这个标准做法稍微差一点是吗?
-
Naiyan Wang (作者) 回复孙杨威2019-01-08
对的,就是我文章里提到的single branch approximation
-
 王贺璋回复Naiyan Wang (作者)2019-01-10
王贺璋回复Naiyan Wang (作者)2019-01-10
这个地方看论文的时候确实有些疑惑,然后我就回来翻评论了,哈哈
-
zzzz2019-01-08
其实我们可不可以理解为深度学习并不能以同一套kernel去拟合所有情况
所以我们一方面尽可能的共享数据,学到common knowledge
另一方面需要在一些层做一些显式的alignment,这样让他们在不同数据上的feature map是可比的。
比如snip trident都是在做scale的alignment,我理解deformable是在做shape的alignment。
如果是这样的话,最后深度学习会不会“倒退”回需要(至少在训练阶段)显式对不同情况(如光照)建模的状态。。 -
Naiyan Wang (作者) 回复zzzz2019-01-08
你理解基本是对的,不过deformable某种意义上也有scale的alignment。本质问题还是我之前在SNIP那个文章里说的,CNN现在没有能对scale invariant的meta operator。alignment我觉得是需要的,但是像光照这种,其实conv本身是应该有能力invariant的。
-
王康康回复zzzz2019-01-08
我理解这个网络就跟你说的一样,前半部分就是在学common knowledge 即不分尺度提特征,后半部分的trident就是在显式的处理不同尺度。
标签:01,Wang,08,新思路,TridentNet,中尺度,回复,branch,举报 来源: https://www.cnblogs.com/cx2016/p/13744261.html