【论文阅读笔记】《DCGAN》
作者:互联网
论文:《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL
GENERATIVE ADVERSARIAL NETWORKS》发表日期:ICLR 2016
前言
这几年CNNs在计算机视觉应用的监督学习方面的应用广泛,而在非监督学习方向的应用就相对没有受到关注。因此,提出的这一深度卷积生成对抗网络(DCGANs)中使用了CNNs的内容,证明它也是可以进行非监督学习的。
通过各类的图像数据训练表明,DCGAN的生成器和鉴别器能够学习从物体部分到场景的表示层次。并且能把学到的特征用于新的任务中,以证明他们可以作为一般图像表征的适用性。
其次,GANs在训练时是不稳定的,经常导致生成器输出没有意义的图片。
架构设计规则
为了GAN能够很好得适应于卷积神经网络架构,DCGAN提出了四点架构设计规则:
- 使用卷积层替换池化层
- 去除全连接层
- 使用批归一化
- 使用恰当的激活函数
卷积层替换池化层
传统的CNN结构不仅包含卷积层,还包括了池化层。而在DCGAN结构中,采取把传统卷积网络中的池化层全部去除的操作,并使用卷积层来替换。
在判别器中,我们使用步长卷积(strided convolution)来代替池化层;在生成器中,我们使用分数步长卷积(fractional-strided convolutions)来代替池化层。
其中步长卷积的图形化解释如下:

实际上,卷积层在判别器中进行了空间下采样(spatial downsampling),输入数据为5x5的矩阵,使用了3x3的过滤器,步长为2x2,最终的输出矩阵为3x3。
假设输入的特征大小为i,卷积核尺寸k,步长s,padding为p,经过卷积后得到的结果为:
\[o = \frac{i + 2p - k }{s} + 1 \]
而分数步长卷积的图形化解释如下:
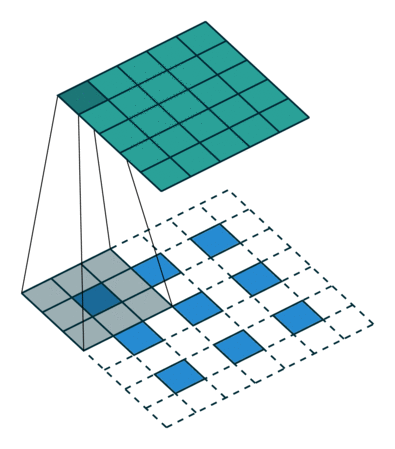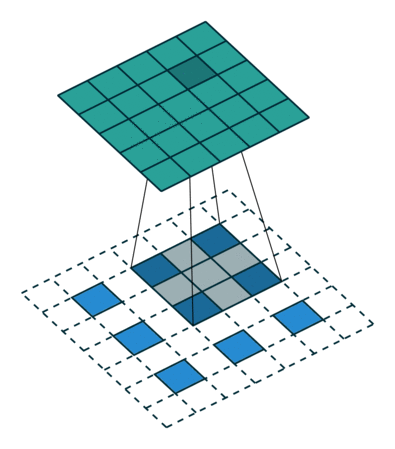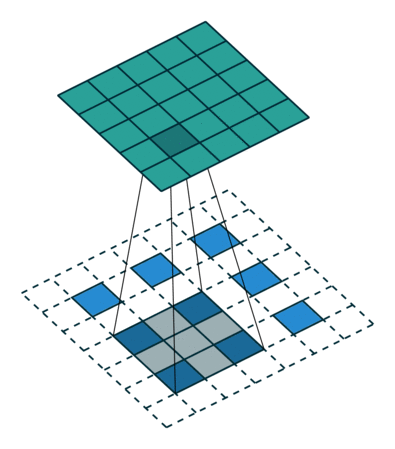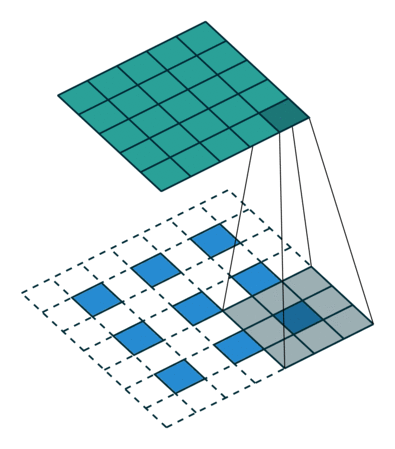
这表示的是卷积层在生成器中进行上采样(spatial unsampling),输入为3x3的矩阵,同样使用了3x3的过滤器,反向步长为2x2,故在每个输入矩阵的点之间填充一个0,最终输出为5x5。
那么使用公式表示如下:
\[o' = s(i-1) + k - 2p \]
之所以叫分数步长卷积,是因为反向卷积的步长变成了1/s。因此,我们需要在原始特征中插入数字0,使得内核比单位步幅移动更慢,具体在于在输入每两个元素之间插入s-1个0,如果卷积的步长是2,在反卷积的时候就应在元素之间插入1个0。
原始的输入特征经过数字0的插入后,输入的尺寸大小变为
\[i' = i + (i - 1)(s - 1) \]
再对该结果进行卷积,此时的步长应为1,进行空洞卷积后的结果如下:
\[o' = i' - 1 - 2p + k \]
空洞卷积的好处是,在不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息,同时使得参数的个数不变。
去除全连接层
全连接层的缺点在于参数过多,当神经网络层数深了以后运算速度变变得非常慢。此外它也会使得网络变得容易过拟合。论文中提出了一种折中的方案,也就是将生成器的随机输入直接与卷积层特征输入进行连接,同样地对于判别器的输出层也是与卷积层的输出特征连接。
使用批归一化
深度学习的神经网络层数很多,每一层都会使得输出数据的分布发生变化,随着层数的增加网络的整体偏差会越来越大。批归一化(batch normalization)可以解决这一问题,通过对每一层的输入都进行归一化的处理,能够有效使得数据服从某个固定的数据分布。
激活函数的设计
在DCGAN中,生成器和判别器使用不同的激活函数。生成器中使用ReLU函数,输出层使用Tanh激活函数。另外,判别器中对所有层均使用LeakyReLU。
上面这四点,在原文中就是:

DCGAN的框架结构
前面提到的,DCGAN的两个网络都是用了卷积层。注意,CNN包含卷积层,其后是归一化层或池化层,之后是激活函数。
DCGAN中,判别网络接收图像,使用卷积层和池化层对其进行下采样,然后使用全连接分类层将图像分类为真的或假的。生成网络从潜在空间中获取随机噪声向量,然后通过上采样机制进行上采样,最后生成一张图像。隐藏层是用LeakyReLU作为激活函数,并且使用系数介于0.4-0.7的随机失活来避免过拟合。
生成器架构图
如图所示,输入z是100位的随机数据,服从范围在[-1, 1]的均匀分布。经过一系列的空洞卷积之后,形成一张分辨率为64x64x3的图像的过程。

判别器架构图
首先看判别网络的架构:

上图展示了判别网络架构的顶层概况。
判别网络是包含10层(可以添加更多层)的CNN。简单说来,它接收维度为64×64×3的图像,使用2D卷积层对其进行下采样,然后传递给全连接层进行分类。判别网络输出估测,判断给定图像是真是假。输出值为0或1,输出1表示判别网络接收的图像为真,输出0表示该图像为假。
训练细节
参数设置
- 训练集:Large-scale Scene Understanding(LSUN)、Imagenet-1k and a newly assembled Faces dataset
- LeakyReLU斜率:0.2
- 优化器:Adam —— \(\beta_1 = 0.5\)
- 学习率:0.0001
- 初始输入:以0为中心的正态分布,标准差为0.02
- 梯度下降:SGD
实验结果
1. 漫游隐空间
通过使用插值微调噪音输入z 的方式可以导致隐空间结构发生变化从而引导生成图像发生语义上的平滑过度,比如说从有窗户到没窗户,从有电视到没电视等等。

2. 语义遮罩
通过标注窗口,并判断激活神经元是否在窗口内的方式来找出影响窗户形成的神经元,将这些神经元的权重设置为0,那么就可以导致生成的图像中没有窗户。从下图可以看到,上面一行图片都是有窗户的,下面一行通过语义遮罩的方式拿掉了窗户,但是空缺的位置依然是平滑连续的,使整幅图像的语义没有发生太大的变化。

3. 矢量算法
在向量算法中有一个很经典的例子就是【vector("King") - vector("Man") + vector("Woman") = vector("Queue")】,作者将该思想引入到图像生成当中并得到了以下实验结果:【smiling woman - neutral woman + neutral man = smiling man】

代码实现
(未完成)
标签:池化层,判别,卷积,论文,生成器,笔记,步长,DCGAN,图像 来源: https://www.cnblogs.com/recoverableTi/p/13509882.html