《xDeepFM:名副其实的 ”Deep” Factorization Machine》
作者:互联网
xDeepFM:名副其实的 ”Deep” Factorization Machine
刺猬 All things happen for the best 鱼遇雨欲语与余 、 谢玉强 、 dragonfly 、 老昶信 等今天介绍 中科大、北大 与 微软 合作发表在 KDD’18 的文章《xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems》。Paper写得很流畅,还清晰梳理了FNN / PNN / Wide&Deep / DeepFM / DCN等CTR预估典型NN结构,阅读体验很棒。
xDeepFM开源代码: https://github.com/Leavingseason/xDeepFM
一、Motivation
一看paper名字,很容易联想到华为在 IJCAI’2017 提出的模型DeepFM,但论“血缘关系”,xDeepFM 的一级近亲首先是 Deep & Cross Network。之前的专栏文章介绍过这两个模型:
DeepFM的思想比较直观,从专栏文章名你已经知道它是怎么做的了,另外一个细节就是模型中FM与Deep共享Embedding。DCN的设计非常巧妙,引入Cross层取代 Wide & Deep 的Wide层,Cross层的独特结构使其可以显示、自动地构造有限高阶的特征叉乘。不理解 DCN的精髓,就没法很好地理解 xDeepFM,这里就不重复搬砖了,强烈建议不熟悉DCN的读者先先阅读上面列出的DCN解读。
假设你已经知道DCN怎么干的、有哪些优点,我们再来看 xDeepFM 想干啥。DCN 的Cross层接在Embedding层之后,虽然可以显示自动构造高阶特征,但它是以bit-wise的方式。例如,Age Field对应嵌入向量<a1,b1,c1>,Occupation Field对应嵌入向量<a2,b2,c2>,在Cross层,a1,b1,c1,a2,b2,c2会拼接后直接作为输入,即它意识不到Field vector的概念。Cross 以嵌入向量中的单个bit为最细粒度,而FM是以向量为最细粒度学习相关性,即vector-wise。xDeepFM的动机,正是将FM的vector-wise的思想引入Cross部分。
二、Model
xDeepFM的整体结构如图1所示,基本框架依然基于标准的Embedding&MLP,其中Linear、Plain DNN分别类似Wide和Deep部分,而 CIN 部分是我们要讨论的重点。
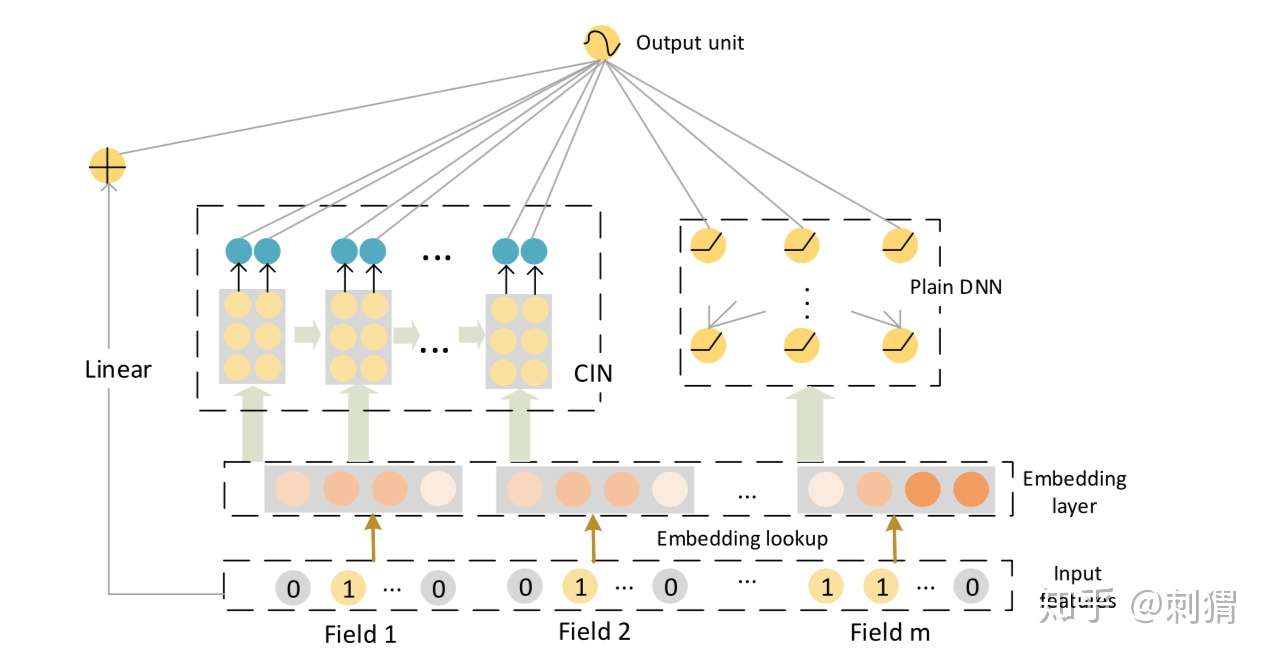 图1. xDeepFM 网络结构图
图1. xDeepFM 网络结构图
CIN:Compressed Interaction Network
如图1所示,CIN层的输入来自Embedding层,假设有 个field,每个field的embedding vector维度为
,则输入可表示为矩阵
。
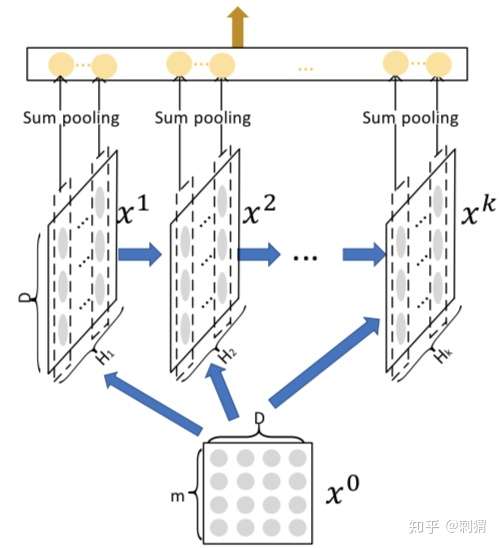 图2. CIN 结构
图2. CIN 结构
CIN 结构如上图所示,咋一看图2可能有点蒙,我们先看一下CIN每层是这么计算的。
令 表示第
层的输出,其中
表示第
层的vector个数,vecor维度始终为
,保持和输入层一致。具体地,第
层每个vector的计算方式为:
(1)
其中 表示第
层的第
个vector的权重矩阵,
表示Hadamard乘积,即逐元素乘,例如
。
看懂了这个计算公式,就理解了图2的CIN结构,我们先看这个公式到底干了什么:
- 取前一层
中的
个vector,与输入层
中的
个vector,进行两两Hadamard乘积运算,得到
个 vector,然后加权求和。
- 第
层的不同vector区别在于,对这
即对应有多少个不同的权重矩阵
, 是一个可以调整的超参。
为什么这么设计,好处是什么?CIN与DCN中Cross层的设计动机是相似的,Cross层的input也是前一层与输出层。至于为什么这么搞,在之前的DCN解读里已经讲解得很清楚。CIN 保持了DCN的优点:有限高阶、自动叉乘、参数共享。
再来看看CIN与Cross的几个主要差异:
- Cross是bit-wise的,而CIN 是vector-wise的;
- 在第
层,Cross包含从 1 阶 ~
阶 的所有组合特征,而CIN只包含
造成差异2的原因是,Cross层计算公式中除了与CIN一样包含“上一层与输入层的✖️”外,会再额外“➕输入层”。 这是两种涵盖所有阶特征的不同策略,CIN和Cross其实也可以使用对方的策略,两种方式的优缺点,大家可以发表自己的看法一起交流。
注意图2的CIN结构,可以思考两个问题,这涉及到CIN的另一位亲戚FM:
- 每层通过sum pooling对vector的元素加和输出,这么做的意义或合理性?可以设想,如果CIN只有1层, 只有m个vector,即
,且加和的权重矩阵恒等于1,即
,那么sum pooling的输出结果,就是一系列的两两向量内积之和,即标准的FM(不考虑一阶与偏置)。
- 除了第1层,中间层的这种基于vector高阶组合有什么物理意义?回顾FM,虽然是二阶的,但可以扩展到多阶,例如考虑三阶FM,是对三个嵌入向量作Hadamard乘再对得到的vector作sum,CIN基于vector-wise的高阶组合再作sum pooling与之是类似的,这也是模型名字 “eXtreme Deep Factorization Machine (xDeepFM) ”的由来。
为啥取名CIN
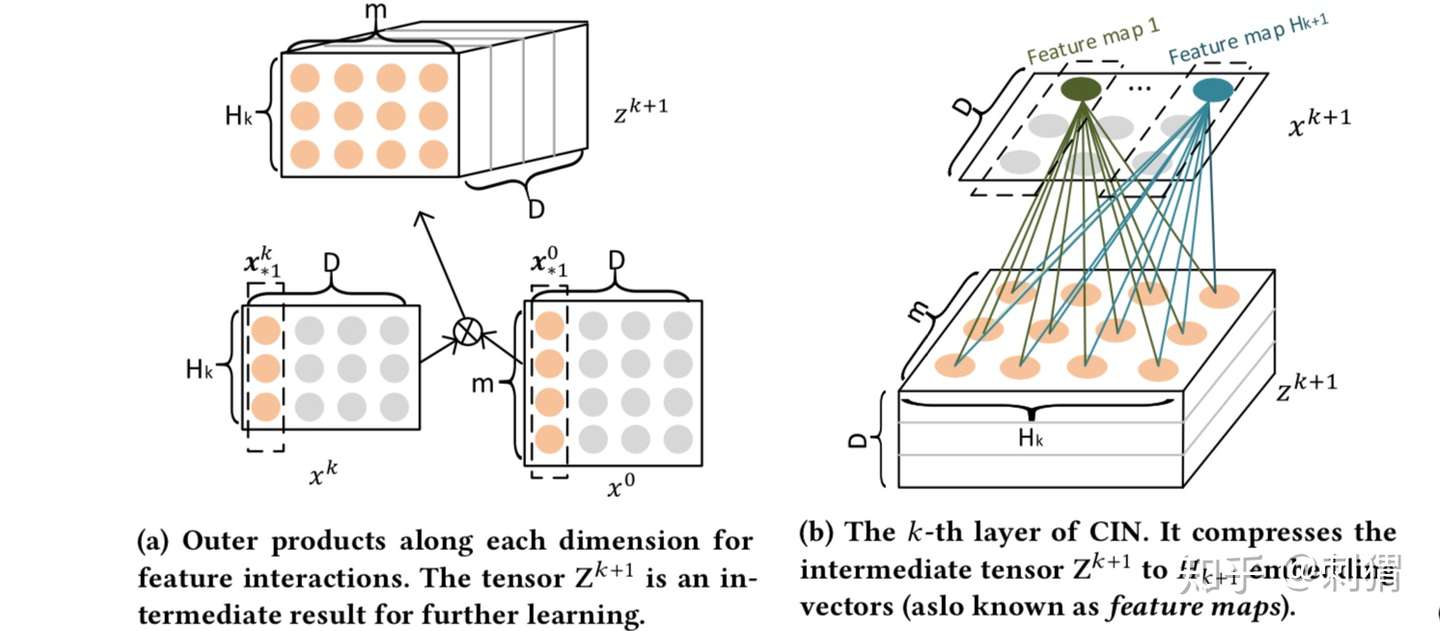
CIN名字由来与它特定的计算方式有关,不感兴趣的读者可以直接跳过这部分,不影响模型理解。回顾式(1),同层不同vector的区别仅仅在于不同的加和权重矩阵 ,我们可以提前计算好两两向量间Hadamard乘的结果。
具体的方式如下图所示,首先如图 a 计算中间结果—— tensor ,然后使用权重矩阵
顺着tensor的维度
,逐层相乘加和,得到 k+1 层的第
个vector,如图 b 所示。如果把
看成filter,这和CNN的方式很像。可以看到,最后
被压缩成了一个矩阵,这是名字中“Compressed”的由来。
复杂度分析
假设CIN和DNN每层神经元/向量个数都为 ,网络深度为
。那么CIN的参数空间复杂度为
,普通的DNN为
,CIN的空间复杂度与输入维度
无关,此外,如果有必要,CIN还可以对权重矩阵
进行
阶矩阵分解从而能降低空间复杂度。
CIN的时间复杂度就不容乐观了,按照上面介绍的计算方式为 ,而DNN为
,时间复杂度会是CIN的一个主要痛点。
三、Experiment
数据集
- 公开数据集 Criteo 与 微软数据集 BingNews
- DianPing 从大众点评网整理的相关数据,收集6个月的user check-in 餐厅poi的记录,从check-in餐厅周围3km内,按照poi受欢迎度抽取餐厅poi作为负例。根据user属性、poi属性,以及user之前3家check-in的poi,预测用户check-in一家给定poi的概率。

实验设置
- 不进行任何人工特征叉乘,通过gird-search on 验证集为每个模型确定最佳超参
- 使用Adam,relu,学习率=0.001,mini-batch=4096,嵌入维度= 10
- DNN每层200神经元,CIN对Criteo每层200神经元 ,对其他数据集每层100神经元
- 对PNN使用0.5的dropout,对其他NN模型,使用
的L2正则
实验结果
单个模型模块的实验结果如表1所示,完整模型实验结果如表2所示,都显示了CIN与xDeepFM的有效性,优势明显。
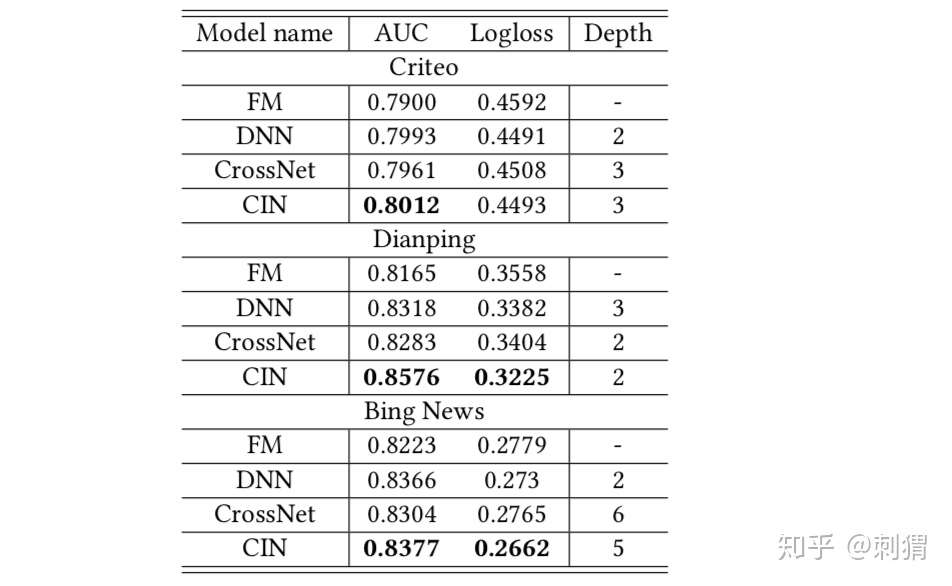 表1. 单个模型部分的实验结果
表1. 单个模型部分的实验结果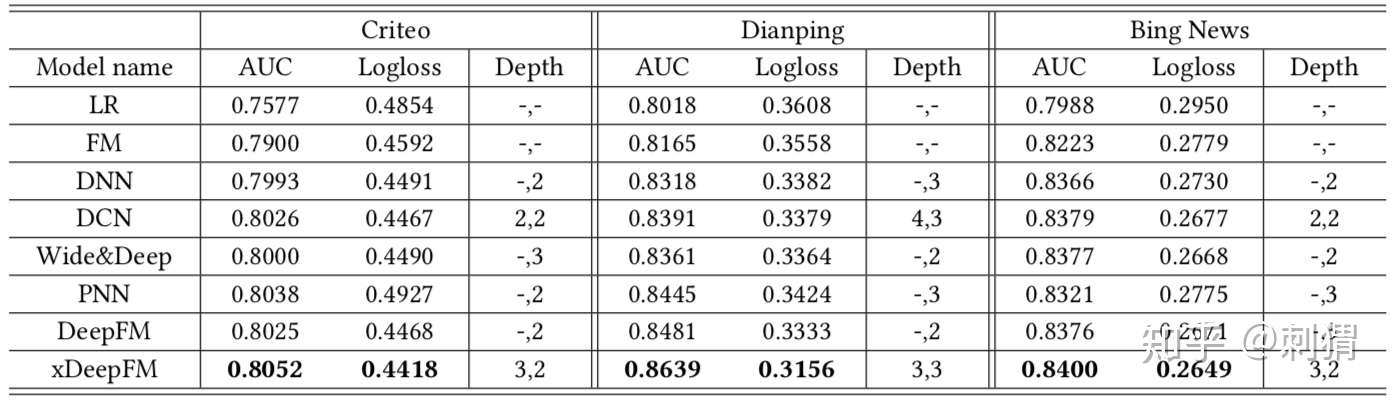 表2. 不同模型的实验结果
表2. 不同模型的实验结果
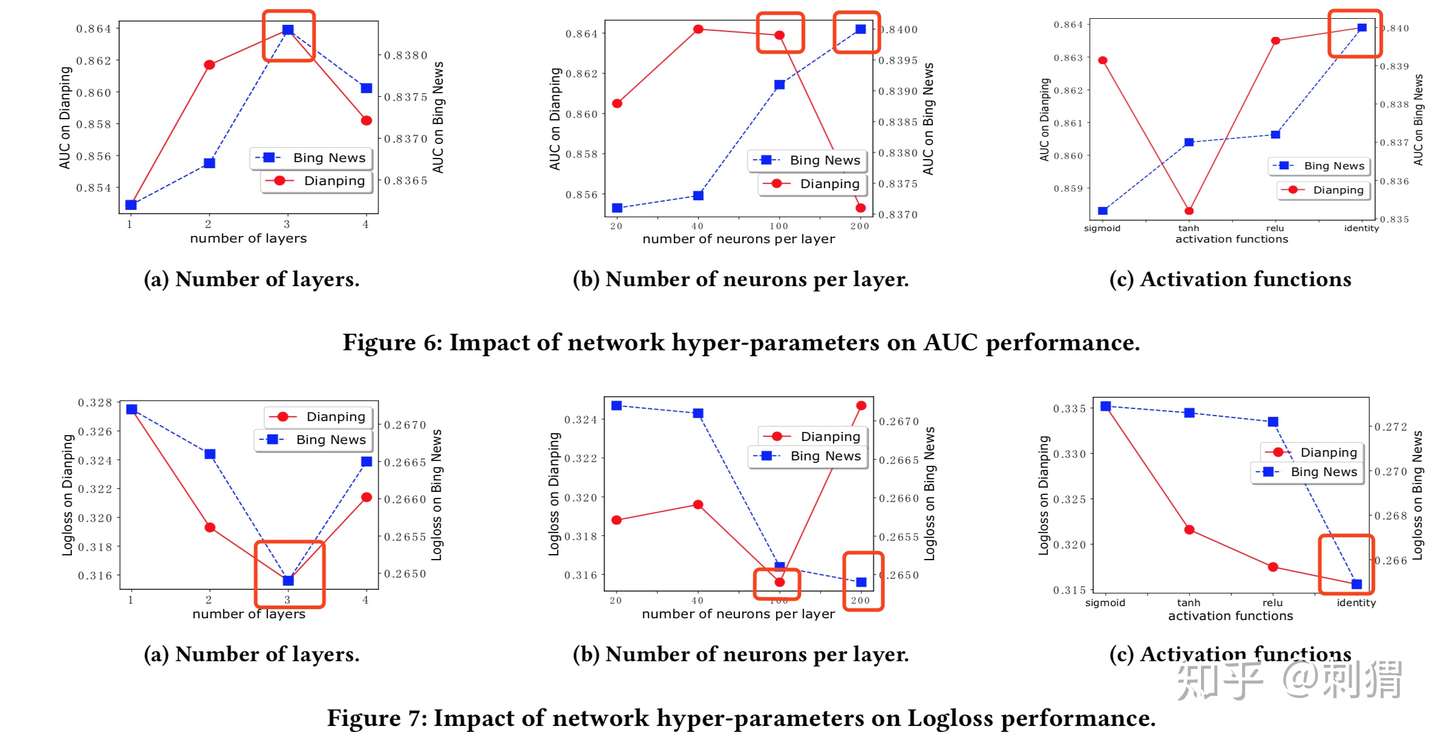
文中也探索了层数、神经元(向量)个数(固定层数=3),不同激活函数对CIN的影响。
四、Conclusion
- xDeepFM将基于Field的vector-wise思想引入Cross,并且保留了Cross的优势,模型结构也很elegant,实验效果也提升明显。如果说DeepFM只是“Deep & FM”,那么xDeepFm就真正做到了”Deep” Factorization Machine。
- xDeepFM的时间复杂度会是其工业落地的一个主要性能瓶颈,需要重点优化
文章被以下专栏收录
推荐阅读
揭秘 Deep & Cross : 如何自动构造高阶交叉特征
本文介绍斯坦福与Google联合发表在AdKDD 2017上的论文《Deep & Cross Network for Ad Click Predictions》。这篇论文是Google 对 Wide & Deep工作的一个后续研究,文中提出 Deep &a…
刺猬
CTR论文精读(七)--DeepFM
杜博亚
(读论文)推荐系统之ctr预估-XDeepFM模型解析
Jesse看Google如何实现Wide & Deep模型(1)
之前在一家公司做个性化新闻推荐,决定尝试一下Wide & Deep模型。当时的TensorFlow还没自带Wide & Deep实现,所以,我用TensorFlow从头到尾实现了一遍。Wide & Deep理论上并不…
石塔西发表于石独数语39 条评论
写下你的评论...-
 张德伦2019-03-12
张德伦2019-03-12
看CIN那块的时候眼睛都要花了,感觉和何向南的那篇Outer Product-based Neural Collaborative Filtering有异曲同工之处
-
 bigliam回复张德伦2019-07-05
bigliam回复张德伦2019-07-05
he的论文,说实话,很水。
-
 狗傻回复bigliam2019-11-18
狗傻回复bigliam2019-11-18
哈哈哈,我看了他好多篇,深有同感,没有本质性进展,但还是很羡慕
-
 JR Lee2019-03-23
最近在看相关工作,感觉CIN的设计比较巧妙啊
JR Lee2019-03-23
最近在看相关工作,感觉CIN的设计比较巧妙啊
-
 impo2019-03-26
impo2019-03-26
您好,FM好像也是以bit-wise作为最小粒度,您说的vector-wise是否应该是FFM?
-
 刺猬 (作者) 回复impo2019-07-05
刺猬 (作者) 回复impo2019-07-05
其实没必要纠结严谨怎么个叫法,论文只是使用了这个称呼,想传达的意思是,FM是以embedding向量为操作粒度,比如“embedding之间”做内积,而对于 crossnet / nn来说,embedding只是普通的多个输入特征
-
 willys2019-04-17
willys2019-04-17
还是没太明白xdeepfm是vector-wise的交叉? dcn是bit-wise的交叉?
-
刺猬 (作者) 回复willys2019-07-05
找个退一步的例子理解,例如DeepFM部分的FM与Deep,见上面的回复
-
 DJy4ever2019-08-21
DJy4ever2019-08-21
"tensor Z^k+1 ,然后使用权重矩阵W^k,i顺着tensor的维度.... "中的权重矩阵W的shape是不是应该更正为Hk+1*m,还有这句话下面对应的图b中的m和Hk是不是标反了
-
 莫西01-18
莫西01-18
话说论文里推DCN的输出形式的时候特意省略了偏置项,感觉加上偏置推不出那样的形式

-
 赵小谦Peter回复莫西04-11
赵小谦Peter回复莫西04-11
感觉偏置项的作用可能就是防止这个问题
-
 WitselW回复莫西04-29
WitselW回复莫西04-29
你好,请问你说的哪一步的偏置?
-
 zxyscz04-07
zxyscz04-07
楼主没有尝试过xdeepFM,线上效果如何?
-
 zsqkal04-30
zsqkal04-30
你好请问一下如果是vector-wise 的话,那么这里的连续的特征和离散的特征需要分别进行处理吗,感觉按照上述的介绍,cin是纯粹进行了离散的embed的交叉,这里如何将连序的考虑进行,难道只能对连续尽心离散化然后统一进行相同维度的embed吗?还有所有的id在embed成相同维度的时候是ok的吗,总感觉奇怪
-
 double07-07
double07-07
CIN的模型复杂度是怎么计算出来的?
-
 付童07-30
付童07-30
写的很好,但是有些细节,不看论文是真的不行啊
-
 Linker07-31
CIN本质上就是穷举了所有可能得交叉结果,并给出w供模型记录学习结果。
Linker07-31
CIN本质上就是穷举了所有可能得交叉结果,并给出w供模型记录学习结果。
标签:xDeepFM,CIN,Factorization,Cross,Machine,vector,回复,Deep,举报 来源: https://www.cnblogs.com/cx2016/p/13506102.html