微信「扫一扫」识物为什么这么快?背后的秘诀竟然是
作者:互联网
微信“扫一扫”识物已上线一段时间,受到了外界极大的关注。相比于行内相关竞品的“拍”,“扫一扫”识物的特点在于“扫”,带来更为便捷的用户体验。“扫”离不开高效的移动端物体检测,本文将为你揭秘。
作者 | arlencai,腾讯 WXG 应用研究员
一、背景
“扫”是“扫一扫”识物的亮点,带来更为便捷的用户体验。相比于“拍”的交互方式,“扫”的难点在于如何自动地选择包含物体的图像帧,这离不开高效的移动端物体检测。
二、问题
“扫一扫”识物是一种面向开放环境的通用物体检测——复杂多样的物体形态要求模型具有强的泛化性,移动端的计算瓶颈又要求模型保持高的实时性。
“扫一扫”识物需要一个什么样的移动端检测(Class-wise or Object-ness)呢?
Class-wise 检测(即传统意义上的物体检测)的优势在于同时输出物体的位置和类别,然而开放环境下的物体类别很难准确定义和完整覆盖。
因此,我们将问题定义为Object-ness 检测(即主体检测):只关注是否为物体和物体的位置,并不关心物体的具体类别。
Object-ness 的物体检测对多样化的物体具有更强的普适性,同时大大减轻模型的负担来保证其实时性。这是“扫一扫”识物相比于相关竞品在移动端检测问题上定义的不同。
三、选型
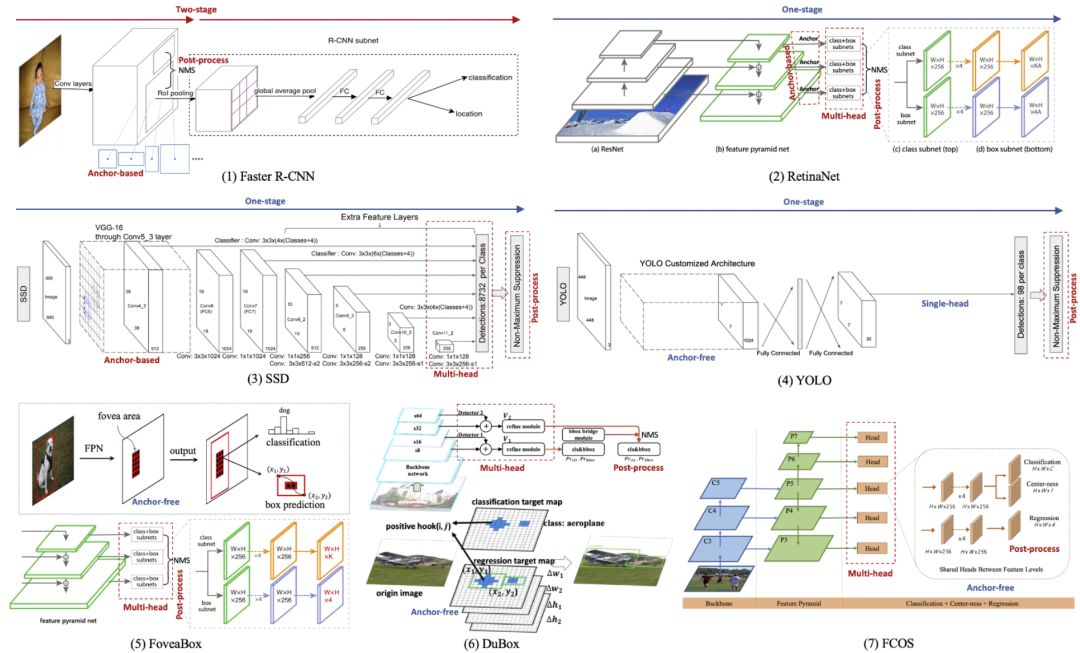
近几年物体检测算法日新月异,面对琳琅满目的检测模型(见图 1),合适的才是最好的。
1. One-stage
从模型的层次结构上,可分为两阶段(two-stage)和单阶段(one-stage)。
(1)Two-stage 检测器以 R-CNN 系列(Fast R-CNN [1]、Faster R-CNN [2]、Mask-RCNN[3])为代表,其模型的第一阶段输出粗糙的物体候选框(proposal),第二阶段进一步回归物体坐标和分类物体类别。
Two-stage 检测器的优势在于:RoIPool 的候选框尺度归一化对小物体具有较好的鲁棒性;进一步的区域(region)分类对于较多类别的检测需求更为友好。
(2)One-stage 检测器以 YOLO 和 SSD 系列(YOLO V1-V3 [4-6]、SSD [7]、RetinaNet[8])为代表,其特点是全卷积网络(FCN)直接输出物体的坐标和类别,为移动端加速提供了便利。
对于“扫一扫”识物中主体检测的应用场景,小物体和多类别的需求不如实时性来得强烈,因此我们选择 one-stage 的模型结构。
2. Anchor-free
(1)锚点(anchor)是 R-CNN 系列和 SSD 系列检测方法的特点:在 one-stage 检测器中,通过滑动窗口(slide window)产生各式各样的 anchor 作为候选框;在 two-stage 检测器中,RPN 从 anchor 中挑选合适的候选框进行第二阶段的分类和回归。
Anchor 为检测器提供物体的形状先验,可有效地降低检测任务的复杂度,但经验性的 anchor 参数会极大地影响模型的性能。
(2)无锚点(anchor-free)的检测器随着网络结构(如:FPN[9]、DeformConv [10])和损失函数(如:Focal Loss [8]、IOU Loss[11])的发展逐渐焕发出新的生机。其中,尺度鲁棒的网络结构增强模型的表达能力,训练鲁棒的损失函数解决样本的平衡和度量问题。
Anchor-free 方法以 YOLOV1-V2 [4-5]及其衍生(DenseBox [12]、DuBox [13]、FoveaBox [14]、FCOS[15]、ConerNet [16]、CenterNet[17]等)为代表。他们抛开候选框的形状先验,直接分类物体的类别和回归物体的坐标。
在“扫一扫”识物的应用场景中,复杂多样的物体形状对 anchor 的设计提出了巨大挑战,因此我们选择 anchor-free 的模型结构。
3. Light-head
近一年来,anchor-free 的检测器日新月异。然而,在移动端的应用场景下,大部分 one-stage 且 anchor-free 的检测器仍存在以下不足:
(1)多输出(Multi-head):为了增强模型对多尺度物体的检测能力,大部分检测器(如:FoveaBox[14]、DuBox [13]、FCOS[15])普遍采用多头输出来提高模型的尺度鲁棒性。
其中,低层特征满足小物体检测需求,高层特征应对大物体检测。然而,多头输出的网络结构对于移动端加速并不友好。
(2)后处理(Post-process):为了解决 anchor 先验缺失和 multi-head 结果整合的问题,大部分检测器都需依赖复杂的后处理,如:非极大值抑制(NMS)和各式各样的奇技淫巧(trick),但它们普遍不适合并行化加速。
综上,我们选取CenterNet作为“扫一扫”识物的移动端检测模型(见图 2)。CenterNet 是 one-stage 的 anchor-free 检测方法,single-head 的输出和高斯响应图的回归使其不依赖 NMS 的后处理。
CenterNet 将目标检测问题变成一个标准的关键点估计问题:通过全卷积网络得到中心点的热力图(峰值点即中心点),并预测峰值点对应的物体宽高信息。
此外,我们引进了 TTFNet[18]中高斯采样、高斯加权和 GIOU Loss[19]等技术实现 CenterNet 的训练加速,仅需 5 小时即可在 4 块 Tesla P4 下完成 MS-COCO 的训练,这为模型调参和优化节省了大量的时间。
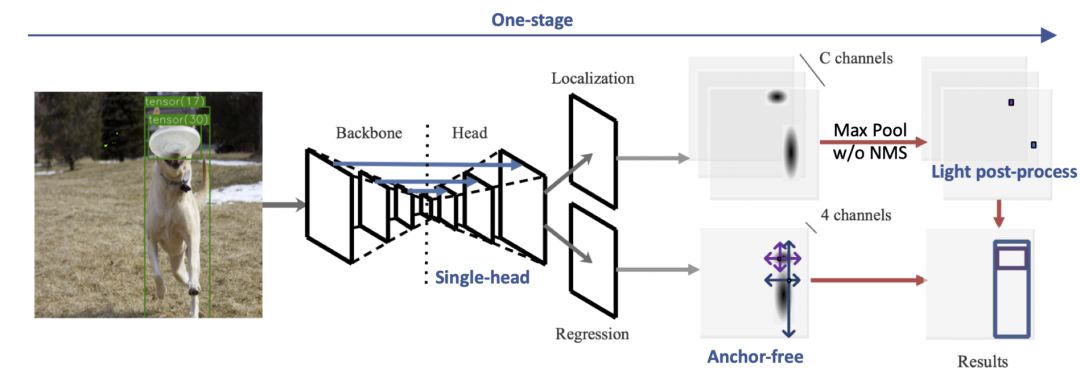
四、优化
针对移动端的检测需求,首先我们将 CenterNet 的骨干网络(backbone)从 ResNet18 更换为对移动设备更为友好的 ShuffleNetV2[20]。
然而,仅仅依赖 backbone 带来的效能提升是有限的,对此我们进行针对性的模型优化。
1. 大感受野(Large RF)
从 ResNet 到 ShuffleNetV2 主要影响了模型的深度和感受野。在以热力图回归的 CenterNet 中,模型的感受野显得异常重要。
如何在保持网络轻量的前提下提高模型的感受野呢?
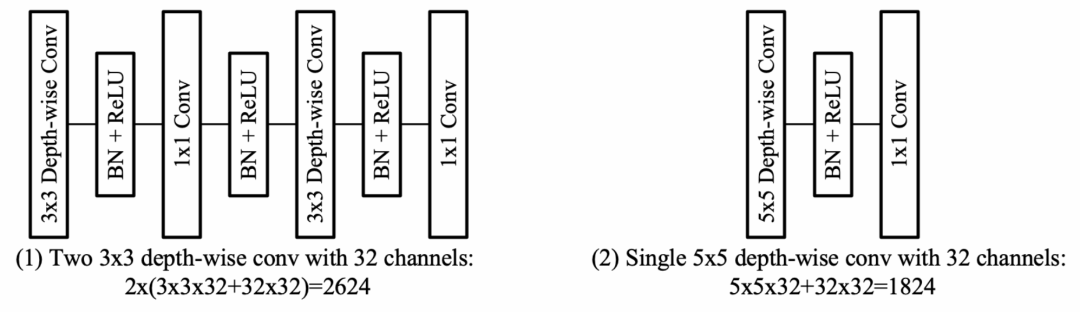
从 AlexNet 到 VGG,VGG 通过将大尺度的卷积核拆解为多个小尺度的卷积核(1 个 5x5→2 个 3x3):在相同感受野下,2 个 3x3 卷积的参数量和计算量均只有 1 个 5x5 的 18/25。
然而,这在深度(depth-wise)卷积的时代并不适用。
在 ShuffleNet 中,5x5 的 depth-wise 卷积获得两倍感受野,仅比 3x3 的 depth-wise 卷积增加极少的计算量(如图 3)。
因此,我们将 ShuffleNetV2 中所有的 depth-wise 卷积均替换为 5x5 卷积。
因为缺少 ImageNet 预训练的 5x5 模型,我们取巧地将 3x3 的 ShuffleNetV2 预训练模型进行卷积核的零扩边(zero padding),得到 5x5 的大卷积核 ShuffleNetV2。
2. 轻检测头(Light Head)
CenterNet 的检测头使用类 U-Net[21]的上采样结构,可有效地融合低层细节信息,从而提高对小物体的检测性能。
然而,CenterNet 的检测头并未针对移动端进行优化,因此我们对其进行 ShuffleNet 化改造(见图 4 红框)。
首先,将检测头的所有普通 3x3 卷积替换为 5x5 的 depth-wise 卷积,并将可形变卷积(DeformConv)也改造为 depth-wise 的可形变卷积。
其次,参照 ShuffleNet 通道压缩的技巧,将 CenterNet 中多层特征的残差融合(residual)改造为通道压缩的连接融合(concat)。
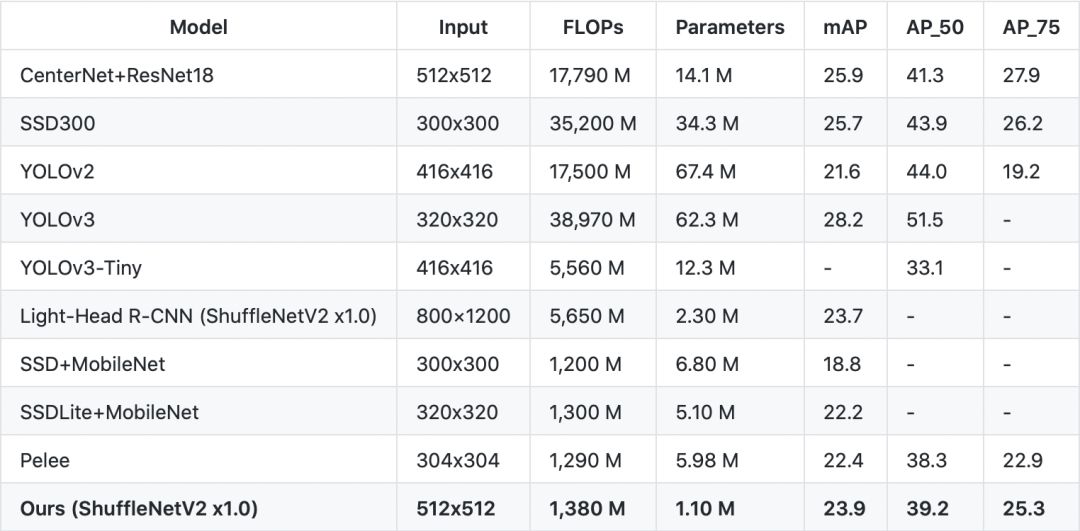
通过大感受野(Large RF)和轻检测头(Light Head),优化后的模型在 MS-COCO 数据库在计算量(FLOPs)、参数量(Parameters)和检测性能(mAP)均取得优异的结果,见表 1。
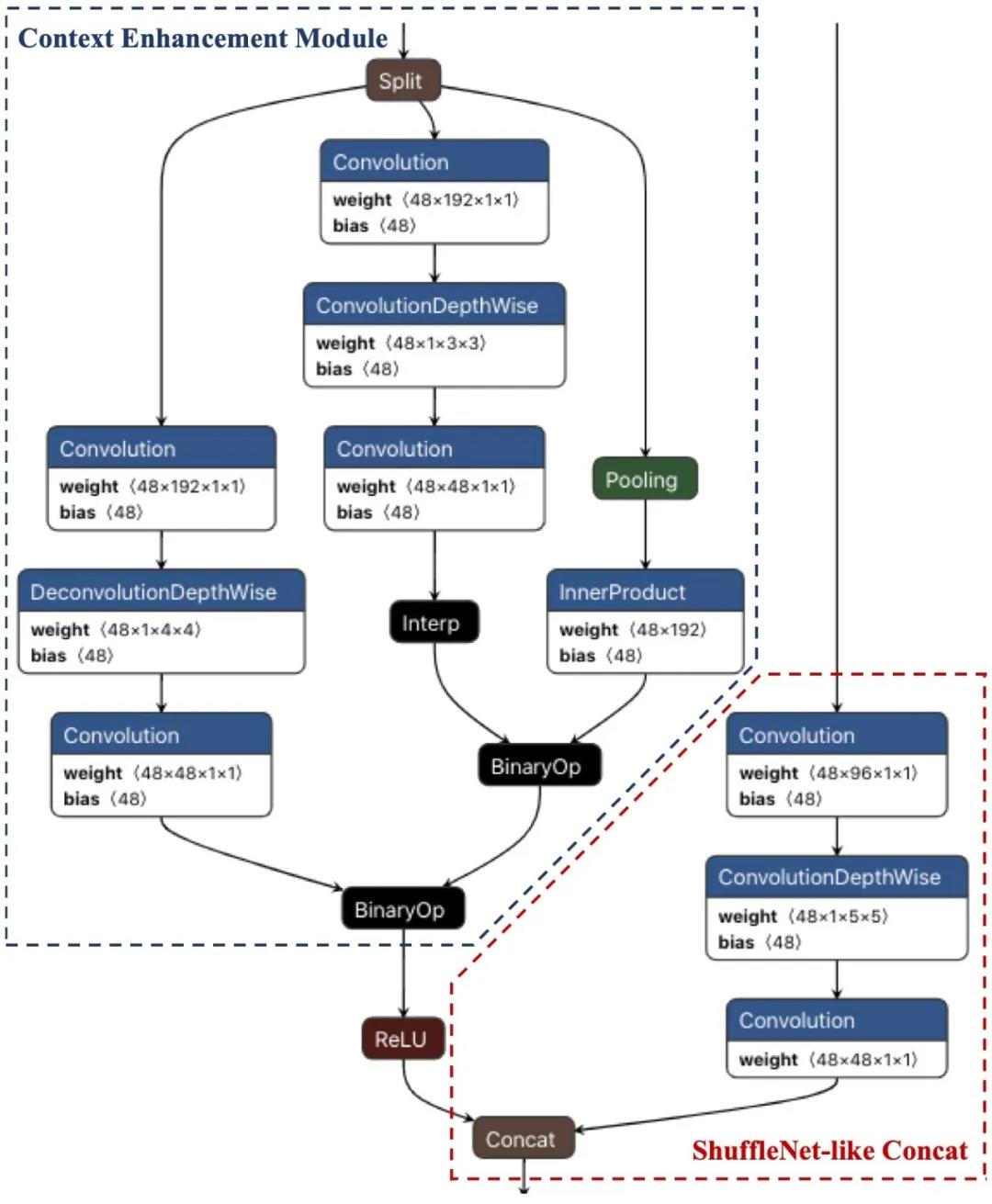
图4:CenterNet检测头的结构优化
3. 金字塔插值(Pyramid Interpolation Module,PIM)
然而,可形变卷积(DeformConv)对移动端加速并不友好,因此我们需要重新设计 DeformConv 的替代品。
DeformConv 可自适应地对多尺度信息进行抽取,在 MS-COCO 中的小物体检测起到巨大作用。“扫一扫”识物对小物体的检测需求并不是非常强烈,DeformConv 更多的是提供多样化的尺度特征。
对此,我们借鉴图像分割方法 PSPNet[22](见图 5)的金字塔池化(Pyramid PoolingModule,PPM),提出了金字塔插值(Pyramid Interpolation Module,PIM)同时实现多尺度特征的融合和特征图的插值(见图 4 蓝框)。
PIM 中主要包括三条分支进行 2 倍上采样:空洞解卷积,卷积+上采样,全局平均池化+全连接。
其中,“空洞解卷积”对应大尺度特征;“卷积+上采样”对应小尺度特征;“全局平均池化+全连接”对应全局特征。
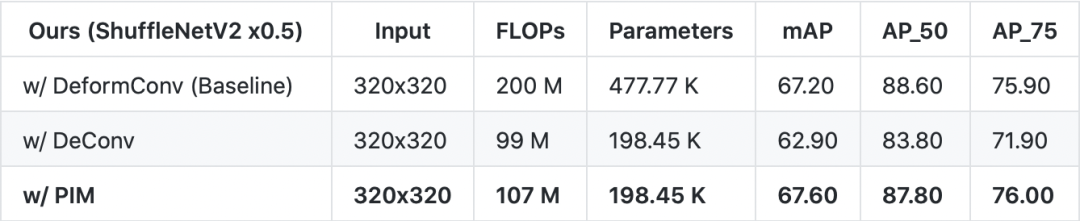
在 ShuffleNetV2 x0.5 的骨干网络下,表 2 对比了各种上采样方法对检测性能的影响,可见 PIM 有效地替代 DeformConv 在“扫一扫”识物中的作用。
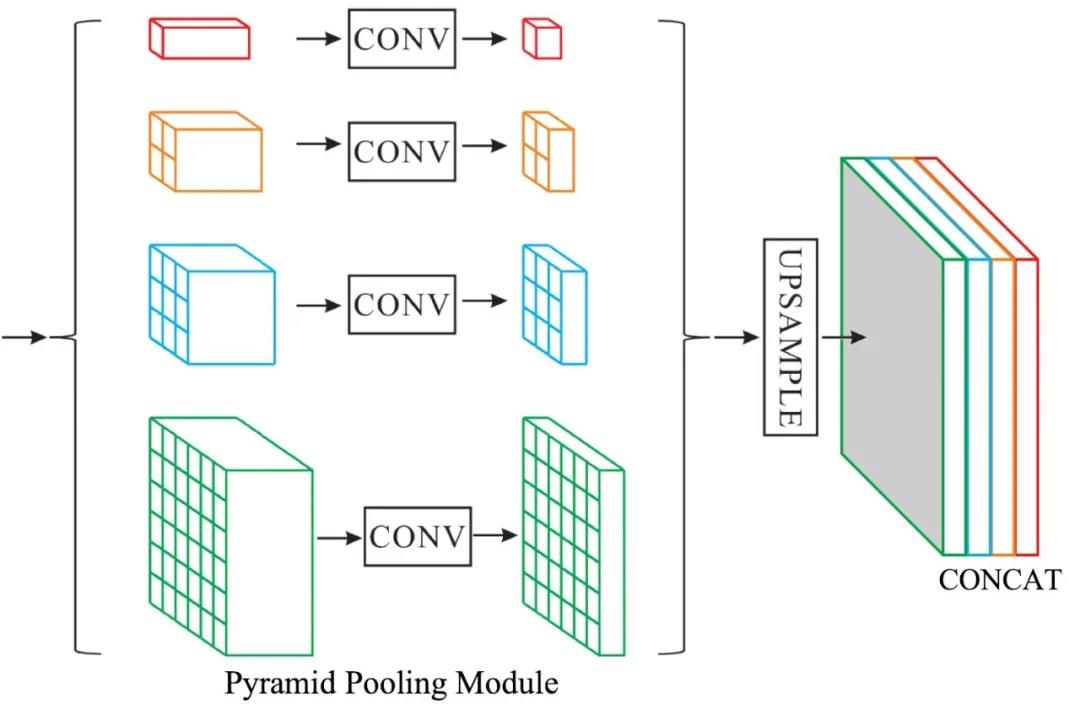
图5:PSPNet的金字塔池化模块
五、部署
通过以上优化,我们最终采用表 2 中最优结果作为“扫一扫”识物的移动端检测模型。
该模型采用基于 pytorch 框架的 mmdetection 作为训练工具。在移动端部署上,我们采用 ncnn 框架,将 pytorch 模型转换为 onnx 模型再转换为 ncnn 模型,并在转换过程中将参数量化到 16bit。
此外,为了进一步减小模型体积和加速,我们将网络中 conv/bn/scale 三个连续的线性操作融合为一个 conv 层,在不影响效果的同时可减少约 5%的参数量,并提速约 5%~10%。
最终,“扫一扫”识物的移动端检测模型仅 436 KB,在 iphone8 的 A11 CPU 上的单帧检测时间仅 15ms。
六、展望
目前“扫一扫”移动端检测只是开端,移动端物体检测的发展也才刚刚开始。
抛开“扫一扫”识物的场景,CenterNet 在通用的物体检测上仍存在以下问题:
如何解决类别增加带来的检测头爆炸性增长?可形变卷积(DeformConv)是否存在更通用的替代品?U-Net 式的上采样结构是否可进一步优化?
路漫漫其修远兮,在我们后续工作中将针对这些问题进行探索。
欢迎大家交流,更欢迎加入我们。微信长期招收计算机视觉和自然语言处理的人才,简历请投至arlencai@tencent.com。
参考文献:
[1] Girshick, Ross. "Fast R-CNN." international conference on computer vision
(2015): 1440-1448.
[2] Ren, Shaoqing, et al. "Faster R-CNN: Towards Real-Time Object Detection with
Region Proposal Networks." IEEE Transactions on Pattern Analysis and Machine
Intelligence 39.6 (2017): 1137-1149.
[3] He, Kaiming, et al. "Mask R-CNN." international conference on computer
vision (2017): 2980-2988.
[4] Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object
Detection." computer vision and pattern recognition (2016): 779-788.
[5] Redmon, Joseph, and Ali Farhadi. "YOLO9000: Better, Faster, Stronger."
computer vision and pattern recognition (2017): 6517-6525.
[6] Redmon, Joseph, and Ali Farhadi. "YOLOv3: An Incremental Improvement."
arXiv: Computer Vision and Pattern Recognition (2018).
[7] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." european conference
on computer vision (2016): 21-37.
[8] Lin, Tsungyi, et al. "Focal Loss for Dense Object Detection." international
conference on computer vision (2017): 2999-3007.
[9] Lin, Tsungyi, et al. "Feature Pyramid Networks for Object Detection."
computer vision and pattern recognition (2017): 936-944.
[10] Dai, Jifeng, et al. "Deformable Convolutional Networks." international
conference on computer vision (2017): 764-773.
[11] Yu, Jiahui, et al. "UnitBox: An Advanced Object Detection Network." acm
multimedia (2016): 516-520.
[12] Huang, Lichao, et al. "DenseBox: Unifying Landmark Localization with End to
End Object Detection." arXiv: Computer Vision and Pattern Recognition (2015).
[13] Chen, Shuai, et al. "DuBox: No-Prior Box Objection Detection via Residual
Dual Scale Detectors." arXiv: Computer Vision and Pattern Recognition (2019).
[14] Kong, Tao, et al. "FoveaBox: Beyond Anchor-based Object Detector." arXiv:
Computer Vision and Pattern Recognition (2019).
[15] Tian, Zhi, et al. "FCOS: Fully Convolutional One-Stage Object Detection."
international conference on computer vision (2019): 9627-9636.
[16] Law, Hei, and Jia Deng. "CornerNet: Detecting Objects as Paired Keypoints."
european conference on computer vision (2019): 765-781.
[17] Zhou, Xingyi, Dequan Wang, and Philipp Krahenbuhl. "Objects as Points."
arXiv: Computer Vision and Pattern Recognition (2019).
[18] Liu, Zili, et al. "Training-Time-Friendly Network for Real-Time Object
Detection." arXiv: Computer Vision and Pattern Recognition (2019).
[19] Rezatofighi, Hamid, et al. "Generalized Intersection Over Union: A Metric
and a Loss for Bounding Box Regression." computer vision and pattern recognition
(2019): 658-666.
[20] Ma, Ningning, et al. "ShuffleNet V2: Practical Guidelines for Efficient CNN
Architecture Design." european conference on computer vision (2018): 122-138.
[21] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-Net: Convolutional
Networks for Biomedical Image Segmentation." medical image computing and
computer assisted intervention (2015): 234-241.
[22] Zhao, Hengshuang, et al. "Pyramid Scene Parsing Network." computer vision
and pattern recognition (2017): 6230-6239.
[23] Li, Zeming, et al. "Light-Head R-CNN: In Defense of Two-Stage Object
Detector." arXiv: Computer Vision and Pattern Recognition (2017).
[24] Wang, Jun, Xiang Li, and Charles X. Ling. "Pelee: A Real-Time Object
Detection System on Mobile Devices." neural information processing systems
(2018): 1967-1976.
推荐阅读
腾讯云技术社区:微信扫物上线,全面揭秘扫一扫背后的识物技术!
标签:卷积,微信,物体,扫一扫,al,et,检测,识物 来源: https://www.cnblogs.com/qcloud1001/p/12564604.html