Generative Face Completion
作者:互联网
文章基本信息
文章来源: CVPR 2017
下载链接: Download paper Download code
摘要
解决问题:从随机噪声中修复面部缺失的区域。
论文背景:
- 基于
Patch-based的图像补全,该类方法主要是从源图像中寻找相似的patch,然后将该patch贴到缺失的区域。当源图像中没有类似的区域时,该方法就无法填充看上去合理的洞。Patch-based方法的不足:(1)Depend on low-level features;(2)Unable to generate novel objects; - 基于
Context Encoder的图像补全,该方法基于深度学习生成相似的纹理区域,在一定程度上可以补全缺失的区域,而且效果还不错。但是不能够保持局部一致性。Context Encoder方法的不足:(1)Can generate novel objects but fixed low resolution images;(2)Masks region must in the center of image;(3)补全的区域不能保持与周围区域的局部一致性。
论文目的:传统以复制-粘贴的方式来进行图片补全在背景填充方面效果不错,但在面对填充脸部图片这种目标图片比较独特时却效果不佳。作者于是想用深度生成模型构建一个有效的目标补全算法,能不需要参照外部数据集快速完成对图片的补全。
解决办法:在这项工作中,作者提出了一种深度生成网络来修复面部表情。该网络以GAN为基础,以自动编码器作为生成器,两种对抗损失函数(局部和全局)和语义解析正则化作为鉴别器。所提出的模型能够从随机噪声中成功地合成语义上有效且视觉上合理的缺失面部关键部分的内容。
数据集: Celeb A,Helen test(这两个数据集都是面部图片的集合,并且后者还有segment label)
试验结果:定性和定量实验都表明,该模型可以生成高感知质量的修复结果,并且可以处理各种掩蔽或遮挡的情景。
论文贡献:
- 首先提出了一个深度生成补全图片补全模型,这个模型通过encoding-decoding 生成器、两个对抗判别器来合成用随机噪声遮挡的部分;
- 其次对挑战性的脸部补全任务进行处理,并且实现提出的模型能够根据学习到的目标特征,产生整体比较和谐的图片;
- 最后,作者证明了生成semantic parsing部分的有效性。
网络结构
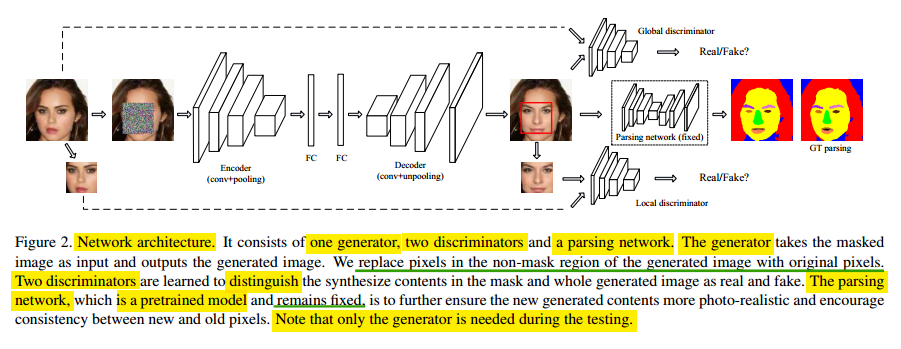
该网络主要由三个模块构成:Generator,Discriminator,Parsing network
Generator
该模型中的 Generator 被设计为一个 autoencoder,有encoder层、两个全连接层和decoder层。作者使用VGG19的前半部分网络结构,外加2个卷积层,一个池化层,一个全链接层。decoder 和 encoder 是对称的,并使用 unpooling 层 用于放大特征图尺寸。输入残缺的图像,通过encoder层映射成隐藏特征,然后再通过decoder层得出修复后的图片。
Generator loss function
Reconstruction loss Lr采用L2损失函数。计算网络输出和原始图像之间的L2距离。由于L2损失严重地惩罚了异常值,并且鼓励网络平滑各种假设以避免较大的处罚,因此只采用Lr损失函数会使生成的内容趋于模糊和平滑。
Discriminator
如果只有一个生成器,那么生成的图片将会非常模糊,只有一个粗略的轮廓。因此,采用了两个判别器来对生成图片的细节进行完善,使得生成的图片更加真实。
作者使用了两个 Discriminator,一个 local Discriminator, 一个 global Discriminator。(采样两个鉴别器的灵感来自<<用深度卷积生成对抗网络来进行非监督表征学习>>)
local Discriminator 是针对缺失图像区域(为了让生成器生成图片中补全的部分更加真实);
global Discriminator 是针对整个图像区域(为了让整个生成的图片看起来更加真实);
Discriminator loss function
通过使用两个Discriminator,作者采用了对抗性损失,这反映了发生器如何最大限度地愚弄鉴别器以及鉴别器如何区分真假。它们的定义如下所示:
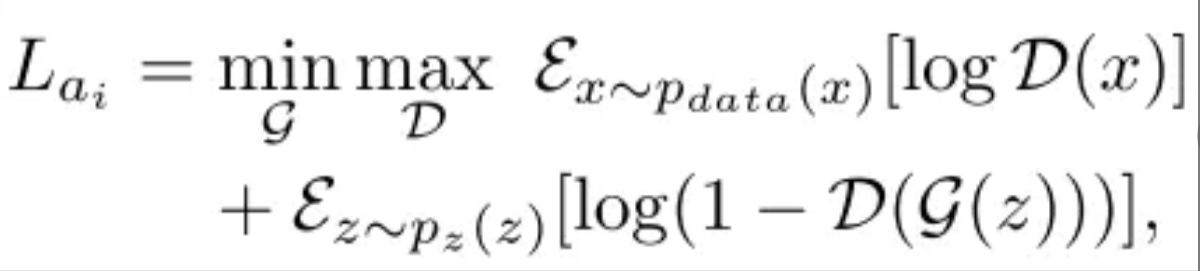
其中,p_data(x)和p_z(z)表示噪声变量z和实际数据x的分布。两个鉴别网络{a1,a2}具有相同的损失函数定义。唯一的区别是局部鉴别器只为丢失的区域提供训练信号(损失梯度),而全局鉴别器在整个图像上反向传播损耗梯度。
两个鉴别器的损失函数的不同之处在于:局部鉴别器的损失函数 (L_a1) 仅仅反向传播图像缺失区域的损失梯度,而整体鉴别器的损失函数 (L_a2) 反向传播整个图像的损失梯度。
semantic Parsing network(语义解析网络)
前面的两个部分其实就是原始GAN的变形,作者设计Parsing network 主要是用于进一步完善缺失区域的生成图像的真实性。在Parsing network中,损失Lp是简单以像素为单位像素的softmax损失(分类网络常用)。(灵感来自<<使用全连接卷积编码-解码网络进行物体轮廓检测>>)
Global loss function(整体损失函数)
因此整体损失函数可以定义为:
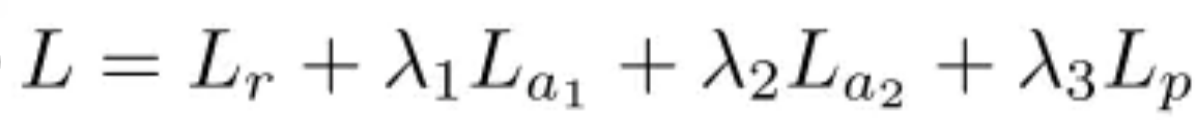
其中λ1,λ2和λ3是平衡不同损失效应的权重。L_a1和l_a2是两个判别器的损失。Lp是semantic parsing network的损失,就是简单的softmax层损失。
Training Neural Networks
为了有效地训练所提出的网络,作者使用curriculum策略,逐渐增加难度级别和网络规模。训练过程分三个阶段进行。(pix2pix两步走的训练步骤类似)
- 首先,使用重建损失来训练网络,以获得模糊的内容。
- 其次,采用局部对抗性损失微调网络。
- 最后,利用全局对抗性损失和语义解析损失正则化上述所得的输出。
这样训练的作用:这个方法据说可以避免训练开始阶段判别器的作用过强。
实验结果
作者将自己模型产生的结果与CE模型产生的结果进行直接对比,并用了三种测量标准测试,证明作者提出的模型效果更好。作者还做了遮挡不同面积的图片,来观察结果的效果,并得出在size是32×32时效果是最好的,因为此时的遮挡面积刚好是面部器官的一部分,比如半只眼睛。
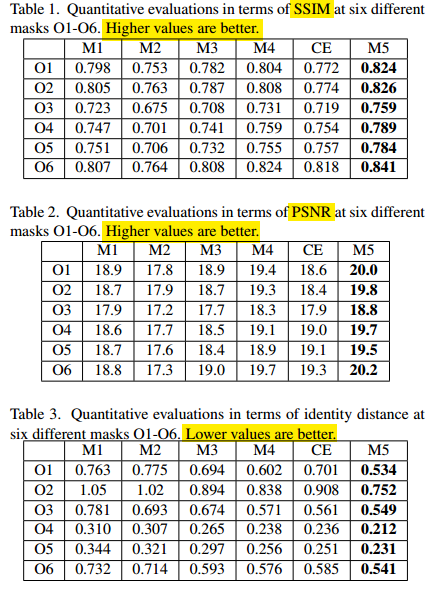
表格参数解释:
o1到o7代表不同的masks。如图下图所示:
M1-M4分别代表M1: Lr.M2: Lr + La1.M3: Lr + La1 + La2.M4:Lr + La1 + La2 + Lp
- 三个指标分别为:
the peak signal-to-noise ratio (PSNR)(directly measures the difference in pixel values)the structural similarity index (SSIM)(estimates the holistic similarity between two images)the identity distance(measured by the OpenFace toolbox to determine the high-level semantic similarity of two faces)
文章特点
该模型可以从随机噪声中成功地合成语义上有效且视觉上合理的缺失面部关键部分的内容,并且可以处理各种现实中遮挡情景的案例。该文章主要的贡献有:
- 首先,作者提出了一个深度生成补全模型,它由一个编码-解码生成器和两个敌对鉴别器组成,用于从随机噪声中合成缺失的内容。
- 其次,解决了具有挑战性的人脸补全任务,并展示了所提出的模型能够根据这个对象类的学习表示生成语义有效的模式。
- 最后,作者展示了在生成过程中语义分析的有效性,这使得补全结果看起来更合理并且与周围的上下文一致。
存在不足
- 所提出的模型的性能随着掩模尺寸的增加而逐渐下降,这是因为随着掩模尺寸的增大,像素值的不确定性逐渐增大。
- 本文实现了各种数据增强来提高学习的鲁棒性,但是发现该模型仍然不能很好地处理一些未对齐的面孔。效果欠佳的合成内容表明该网络不识别脸部及其相应内容的位置/方向。
- 该模型没有充分利用相邻像素之间的空间相关性。
改进意见
- 这个模型一个局限是并不能处理一些未对齐的人脸,可以增加一个面部变形的网络来将输入的人脸规范化。
- 使用其他类型的图像 (如建筑或风景) 来训练这个模型,来判断其对其他类型的修复任务是否具有鲁棒性。
总结
- 论文本身:基于生成对抗网络的模型具有两个鉴别器和一个语义解析正则化网络,能够处理人脸修复任务。它能够在随机噪声中成功地合成缺失的人脸部分。
- 提供了一个设计生成对抗网络模型的新方式:同时使用多个鉴别器达成不同目标。例如,传统的自编码器使用 L_2 距离来重构图像,所以经常输出非常平滑的结果。之前的工作经常使用从深度分类神经网络中得到的映射向量来改善这个结果。但是在这篇论文中,作者证明使用不同的鉴别器也能够得到更低的平滑度,从而结果更好。
- 论文作者把训练过程分成了几个阶段,这对训练生成对抗网络而言确实是一个好想法。这就像人类学习的方式:人们首先学习一个物体的轮廓 (和这个项目中的图像重建类似),然后一步一步地学习每一部分的细节 (类似于这个项目中第二阶段的微调以及第三阶段)。
- 训练步骤也有一个预训练部分(只训练生成器)。以前一直以为只是用来让后面的训练时间更短,论文中提到这样训练也可以避免在训练的初始阶段,判别器的作用太强,影响训练效果。
- 论文对GAN的变形方式值得借鉴,采用两个判别器的模型分别完成对局部和整体的训练,思路很好。
- 作者在模型的最后部分还采用了一个
semantic parsing networks结构,这个部分能让整体的输出更加和谐。 语义解析网络能够在生成对抗网络的随机噪声上提供一些额外的 (语义) 限制,以得到更加逼真的结果,论文中的[图10]。 - 论文的目的是对独特的目标图片进行补全,以面部图片为例,但是论文一直是以脸部图片作为实验训练集,如果能加入其他比较独特的图片,比如建筑、动物等,可能说服力会更强。
- 论文作者还证明了「峰值信噪比 (
PSNR)」和「结构性相似指数(SSIM)」不足以评价重构或生成结果,因为这两个指标是倾向于平滑和模糊的结果。如图 3、表 1 和表 2 所示,子图 M1 比 M2 和 M3 具有更高的 SSIM 和 PSNR。但是 M2 和 M3 明显具有语义层面更加合理的生成结果。
标签:Completion,补全,训练,模型,损失,Face,鉴别器,Generative,生成 来源: https://www.cnblogs.com/wenshinlee/p/12496703.html