YOLOv3
作者:互联网

对三层作监督,分别重点检测大中小物体。
如果从未接触过检测算法,一定会对YOLOv3有别于其它CNN的诸多方面深表惊奇。惊奇可能意味着巧妙,也可能意味着不合理或者局限。在YOLOv3身上二者兼备。
Output and loss
需要监督的输出层如下。The shape of the detection kernel is 1 x 1 x (B x (5 + C) ).

这里有如下令人惊奇之处。
- 输出格式。训练,总是把预测输出与ground truth作比对。我们通常碰到的任务,一个样本通常只(预测)输出一个值,例如,分类中的类别,回归中的实值。而YOLOv3的预测输出N个结构(可以把它理解为c语言的struct),N= cell number * B个,其中B一个cell能预测的bounding box数目(即每一层的anchor数目,实现中一般是取为3)。cell number三层分别为13*13, 26*26, 52*52。结构中有3类成员:bounding box attributes (x, y, w, h),置信度,类别。总共有(5+C)个,5是4 bounding box attributes and one object confidence,C是类个数。
- feature map用途。通常CNN的feature map往往只存在hidden层,最后在输出层通过full connection层或者average polling层转换为vector。而YOLOv3的feature map直接作为输出。通常不同channel用于表示图像的不同特征。而YOLOv3的不同channel不仅可以表达是图像特征,例如人、车这种类别,还可以表达坐标和置信度。
很多情况下,我们不创新,并不是没有想法,而是没有想到可以这么实现。有时,我们说,在网络结构上改进余地不大,但在怎么使用网络来作表征上,YOLOv3大大拓宽了我们的思路。
以上说过,YOLOv3的输出结构中有3个,bbox attribute, object confidence, class score。loss就是以上三部分的加权和,其中bbox attribute (x, y, w, h)用MSE,后二者用交叉熵。
看起来比较简单,里面还是有些trick。
首先,output有cell number * B(对第一层是13*13*3)个这样的结构,而ground truth才有目标个数(假定对一幅图的最大检测目标个数为20)个。13*13*3与20如何作MSE或者交叉熵?通常我们能想到的是,对13*13*3作某种grouping算法得出与ground truth相同shape的scalar或者tensor与ground truth比较。但YOLOv3的作法正好与此相反,是为20个找到13*13*3个格子中的20格,来安放ground truth,然后把其余格子全部置0。如何找到这些格子呢?对于width和height这2个维度很容易,就是根据中心点重合。而对于depth(即B)这个维度,它是找到与gound truth的bbox有最大IOU的anchor box对应的格式。这里第一处用到IOU。它有一个局限,一个格子只能容纳一个目标。假如一个人坐在一张椅子上,中心位置和宽高大小比例都相若,本来同属于一个格子,那么即使打标时打了2个标,在训练时,也只有一个标(样本)会生效,后面一个样本会覆盖前面一个样本。从设计上就注定了训练时的这种局限。不过,这不是什么大问题,顶多就是浪费了一个训练样本而已。那么在预测时,能否检测出2个来?设计上是可以的,因为结构中包括了C个class score。但我看到的有的编码实现都只保留class score最大的那个,这是可以作微改进的。
其次,不知你有没有注意到,object confidence有点奇怪,不仅算法奇怪,它的存在就很奇怪。BBOX可以用回归,class可以用交叉熵,怎么突然冒出个confidence?它是对目标从属于哪个格子的confidence,还是对(x, y, w, h)的值的confidence?YOLOv1论文上有解释,These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts. Formally we define confidence as Po * IOU.
在计算confidence的loss时,对于正样本(即该格子有目标),计交叉熵,这很正常。对于负样本(即该格子没有目标),只有bbox与ground truth的IOU小于阈值ignore threshold(通常取为0.5),才计交叉熵。这里第一处用到threshold,第二处用到IOU。为啥对正负样本区别对待呢?我的理解是,对于有目标的格子,如果预测出有目标的可能性低,即输出值的Po小,不正常,需要作惩罚。而对于没目标的格子,如果预测出有目标的可能性高,即输出值的Po高,这有可能是正常的,因为目标的中心点不在这个格子,可能在附近的格子,是否需要惩罚要视情况而定。如果IOU小于阈值,说明附近的格子没有目标,Po高不正常,需要惩罚,即参与计算交叉熵。大于阈值,说明附近的格子有目标,Po高正常,不需要处罚,即计算交叉熵时忽略。这一点与我看到的文章的说法以及同事们的看法正好相反,而与我理解的keras代码和pytorch代码一致。
这里还有一个问题,上文中提到,对于没有包含目标的格子,它的5+C全部置0,因此bbox也为0,那如何计算它与预测输出的bbox的IOU呢?实际上,此处计算IOU时,它不是与本格子的ground truth的bbox计算IOU,而是与所有目标的bbox都计算IOU,并取最大值。YOLOv1论文上的这段话the confidence prediction represents the IOU between the predicted box and any ground truth box.证实了该解释。
总结一下loss公式。
loss = bbox loss + confidence loss + class loss
bbox loss =
![]()
其中,bx, by, bw, bh是我们预测的x,y中心坐标,宽度和高度。lx, ly, lw, lh是ground truth的x,y中心坐标,宽度和高度。 代表该格子是否有目标,有为1,无为0。
confidence loss =
![]()
其中,同上,分别为object confidence的ground truth和预测输出的概率,为二者的交叉熵,m为mask,即如上段中所说,正样本恒为1,负样本依条件而0或1。
class loss =
![]()
其中,同上,C为类个数,p(c), q(c)分别为各类的ground truth和预测输出的概率,KL同上。
尽管在道理上解释得通,我觉得不太合理,一方面过于复杂,另一方面多了个超参ignore threshold。也许有简洁的改进方案,object confidence这个loss可以反过来算,不是把预测输出值与ground truth双方统一到格子上,而是统一到目标(即最多20个)上来。
最后再提醒一下,一个没有被ground truth占的格子,它不参与计算BBOX的loss和class的loss,但参与计算object confidence的loss。
预测
For an image of size 416 x 416, YOLO predicts ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 bounding boxes. 这么多个预测输出如何缩减到目标个数呢?经过2道工序。
- object confidence threshold
过滤掉小于object confidence threshold的格子。这里第二处用到threshold。
- NMS,即Non-maximum Suppression
大名鼎鼎的NMS的目的是消除掉不同格子中预测出的同一个目标。

一般介绍Non-Maximum Suppression的文章会这样介绍NMS算法。首先,NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中。(这里的score = object confidence * class score, class score实际是指P(Class | Object), 因此P(Class) = P(Object) * P(Class | Object))接下来,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的nms threshold的bounding box。这里第三处用到IOU和threshold。然后重复上面的过程,直至候选bounding box为空。
NMS就这么简单?有没有忽略了什么重要的东西?会不会发生这种情况,过于邻近的N个目标中N-1个被无辜地过滤掉?为了防止这种可能,NMS在过滤时分类过滤的,即在同一个类的检测输出中执行上述算法。即便如此,仍然避免不了过于邻近的N个同类目标中N-1个被无辜地过滤掉。这是另一个局限。
顺便说一下,NMS仅用于预测,并未用于训练。
anchor box
我们面临2个疑问
- 为何需要有anchor box?
It might make sense to predict the width and the height of the bounding box, but in practice, that leads to unstable gradients during training.
因此,需要pre-defined default bounding box作为锚点。
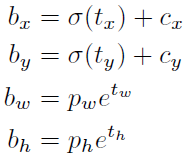
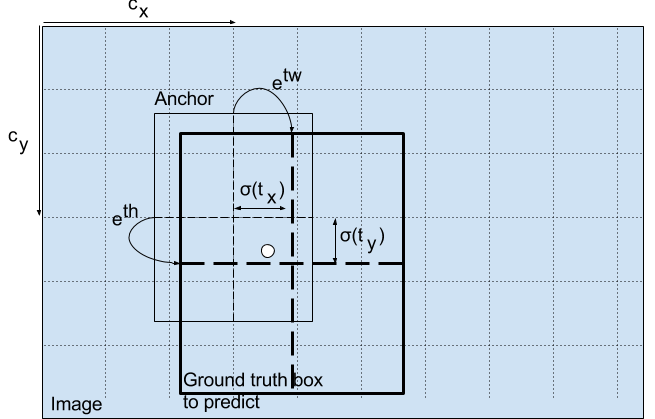
bx,by,bw,bh是我们预测的x,y中心坐标,宽度和高度。 tx,ty,tw,th是网络输出的内容。 cx和cy是网格的左上角坐标。 pw和ph是anchor box的宽度和高度。
- anchor box是怎么来的?
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
k-means无论是算中心还是重新选择cluster,都会用到距离,我们通常见到的距离是欧氏距离。但这里是BBOX,BBOX间怎么算距离呢?
d(box; centroid) = 1 - IOU(box; centroid)。这是第四处用到IOU。
YOLOv3整个思路让人匪夷所思。正如它的名字,You Only Look Once,它不是先切割再分类。实际上,它是根据中心的一个格子来预测它的BBOX和分类,这怎么可能呢?
标签:box,loss,confidence,YOLOv3,格子,IOU,truth 来源: https://www.cnblogs.com/ziwh666/p/12493825.html