7个步骤建立可用的机器学习模型
作者:互联网
Netflix或Amazon Prime推送您喜欢看的电影,这背后的逻辑你不觉得惊讶吗?或者,你不好奇是什么让Google地图可以预测您所行驶的路线上的路况?
我们都知道机器学习是如何使用算法和统计模型来执行任务并提出完美的解决方案。同样,这种方法可以检测癌症,并有助于检测Facebook上的面孔以及多种用途。
机器学习:需求
机器学习算法模仿人类及其日常发展的规律。 简单来说,机器学习可分为两个概念:训练和预测。
机器学习已经出现在了我们的日常生活中,但我们几乎没有意识到。 例如,在社交媒体平台上给用户加标签只不过是机器学习简单的工作而已。 机器学习应用广泛如欺诈检测,推荐系统和识别。在不久的将来,机器学习将被用在自我纠正,提供有深刻见解的价值观念和个性化服务这些技术上。
机器学习算法是如何工作的
机器学习创建了一个可以回答用户提出的每个问题的系统。 然后,该系统通过训练最适当的算法来建立模型,并以此为基础回答问题。
准确地说,机器学习有一个需要遵循的七步模型:
从检测需要立即修复的自动扶梯到检测皮肤疾病,机器学习催生了计算机系统,它能够神奇地处理一些我们无法理解的事情。 但是机器学习如何工作? 在没有显式编程地情况下,将采取哪些步骤以及它们如何起作用? 这是您需要知道的。
在这里,我们将通过引用一个示例来演示机器学习的工作原理:我们拿啤酒和葡萄酒举例,通过它可以创建一个系统,系统将回答给定的饮料是葡萄酒还是啤酒。

1、数据收集
这里可以举一个简单的例子说明。要收集的数据是从装有啤酒或葡萄酒的玻璃杯中获取的。从分析玻璃杯的形状到检查泡沫的数量,收集的数据可以是任何东西。在这里,将这些液体的颜色选择为光的波长,并将内容物(酒精)作为特征。 第一步也是最重要的一步,包括从零售商店购买几种类型的酒精,以及配备可以进行正确测量的设备,例如用于测量颜色的分光计,以及用于测量酒精含量的比重计。
此步骤至关重要,因为所收集数据的质量和数量将有助于提高预测模型的准确性。 收集每种饮料的酒精含量和颜色是为了找出酒精或葡萄酒的成分,这和我们准备用来训练数据的系统是同一个系统。
2、数据准备
一旦收集了数据,就需要将其加载到系统中,并为机器学习训练做好准备。
这些数据是随机放置的,因此系统一开始不会知道饮料是葡萄酒还是啤酒的一部分。但是系统应该可以识别出饮料是葡萄酒还是啤酒。同时,可以进行可视化操作以确保变量之间不会存在不平衡。
然而,如果我们收集的啤酒数据比葡萄酒多,那么训练的模型可能会显示出对啤酒的一定程度的偏差,因为收集的大多数数据都是关于啤酒的。 但是在实时情况下,如果模型同时使用了相等数量的啤酒和葡萄酒数据,那么啤酒预测可能有一半是错误的。
因此,为两个变量提供正确的数据量同样重要。
3、选择合适的模型
如何知道哪种模型合适? 根据多位研究人员和数据科学家的说法,很明显,专家们会对选择正确模型有自己的想法。
例如,其中一些模型经过设计,最适合于音乐或文本之类的序列,而另一些则适合数字序列。 在我们的啤酒和葡萄酒示例中,它将是一个线性模型,因为您将看到啤酒和葡萄酒这两个不同的特征。
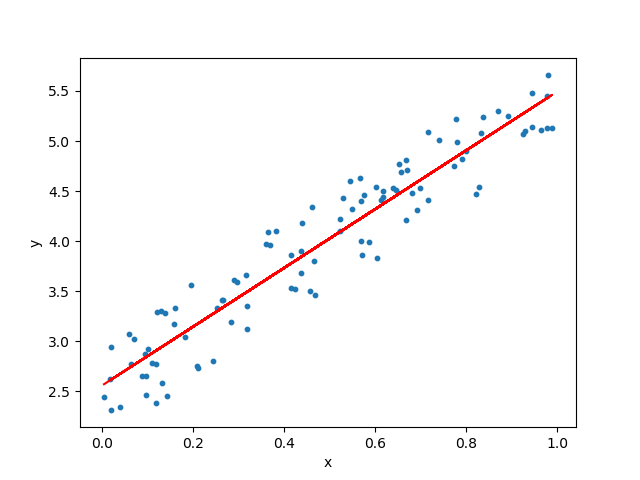
4、训练模型
这是一个至关重要的过程,因为它使用数据进一步改善了模型的性能-预测葡萄酒和啤酒。y=m*x+b
y是截距,m是直线的斜率,y也是直线在x位置的值,b是直线在X轴的截距。 m,b和y是唯一可以训练和评估的值。
在机器学习中,您将遇到多个m变量,可以从中构造w矩阵或权重矩阵。
5、评价
接下来是评价,评价过程需要检查模型是否得到有效的训练或是否可以完成任务。 通过这种方法,您可以轻松用训练中未出现过的数据来测试模型。这样是为了测试模型如何响应尚未遇到的数据。理想情况下,进行评价是为了分析模型如何实时执行。
6、超参数调整
这是为了检查正在训练的模型是否仍有改进的余地。可以通过调整某些参数(学习率或在训练过程中训练模型运行的次数)来实现。
在训练期间,你要考虑多个参数。对于每个参数,你要知道它们在模型训练中所起的作用,否则您可能会发现自己在浪费时间或经过调参后耗时更长了。
7、预测
最后一步,一旦遵循了上述参数,就可以对模型进行测试。给定颜色和酒精含量,机器可以预测哪种饮料是啤酒和哪种是葡萄酒。机器学习可借助模型而不是使用标准规则或人工判断来确定葡萄酒与啤酒之间的差异。
已知的机器学习应用
甚至在我们意识到之前,我们就已经使用机器学习了,这是令人难以置信的。 众所周知,机器学习在多种行业中都有应用,例如医学诊断,语音识别,学习协会,金融服务,预测等。
医学诊断
机器学习提供了有益于医疗领域的工具和技术,它有助于解决疾病预测和诊断问题。
它还被用来分析临床参数用于疾病预测,例如,它有助于预测疾病的进展,还有助于治疗计划的改进,总体上主要用于患者管理。
语音识别
在语音识别中,机器学习帮助将口语单词转化成文本,即自动化语音识别或语音成文本或计算机语音识别。
学习联想
这是一个将见解发展为产品之间关联的过程。 简而言之,无关的产品也可以揭示它们之间的关联。
金融服务
机器学习系统是一个良好的工具,通过持续监控个人活动来检测欺诈并评估该个人的活动是否属于本用户。
预测
机器学习能够预测客户拖欠贷款的可能性。但是,为了进行计算,系统需要对特定组的数据进行分类。
原文链接:https://imba.deephub.ai/p/18f788a063fe11ea83daff02656c39f6

微信扫描二维码,获取更多干货
标签:葡萄酒,训练,步骤,模型,学习,机器,啤酒 来源: https://www.cnblogs.com/deephub/p/12469220.html