利用深度学习实现手绘数据可视化的生成
作者:互联网
个人博客导航页(点击右侧链接即可打开个人博客):大牛带你入门技术栈
前一段时间,我开发了Sketchify, 该工具可以把任何以SVG为渲染技术的可视化转化为手绘风格。(参考手绘风格的数据可视化实现 Sketchify)
那么问题来了,很多的chart是以Canvas为渲染技术的,那要怎么办?
我拍脑袋一想,为什么不使用深度学习技术来做呢?
原理很简单:
- 首先用相同的数据分别生成原始的和手绘风格的数据可视化图数据。
- 然后利用深度神经网络,使用该数据训练一个模式,输入是数据图,输出的手绘风格的图。这样就可以训练一个生成手绘风格数据可视化的神经网络了。
- 然后对于任何新的数据图,输入该网络就可以输出一个手绘风格的图。
这听起来就像如何把大象放到冰箱里一样的简单直接。
废话少说,开始干。
准备数据
数据准备要生成一定数量的原始图和手绘图,利用Sketchify就可以完成功能,但是具体如何做到?参考如下架构:
- VizServer是一个web服务,用nodejs开发,代码在这里https://github.com/gangtao/handyModel/tree/master/vizService
VizServer使用restify提供RestAPI接口,利用squirrelly.js的模版引擎生成一个包含可视化的Html页面。模版如下:<!doctype html> <html> <head> <title>{{sketchify}}</title> <meta charset="UTF-8"> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/rough.js/3.1.0/rough.js"></script> <script src="https://gw.alipayobjects.com/os/lib/antv/g2/3.4.10/dist/g2.min.js"></script> <script src="https://gw.alipayobjects.com/os/antv/pkg/_antv.data-set-0.10.1/dist/data-set.min.js"></script> <script src="https://cdn.jsdelivr.net/gh/gangtao/sketchify/dist/sketchify.min.js"></script> </head> <body> <div id="chart" style="height: 400px; width: 600px"></div> </body> <script> $(function() { var data = {{dataset| safe}}; var chart = new G2.Chart({ container: 'chart', forceFit: true, height: 400, animate: false, renderer: 'svg' }); chart.source(data); chart.scale('sales', { tickInterval: 20 }); chart.interval().position('{{grammar}}'); //'year*sales' chart.render(); {{if(options.sketchify === 1)}} const container = $('#chart')[0]; const handler = Sketchifier(container, {}); handler.handify(); {{/if}} }); </script> </html> - DataGen负责生成随机的图表数据,发送请求到VizServer,把返回的网页利用puppeteer的headless browser渲染,并截图。代码在这里
其中,数据生成部分我是用了mockjs,我发现另一个比较有趣的库可以做类似的功能是casual
训练神经网络
数据准备好以后就可以训练神经网络了。
深度神经网络的训练往往比较消耗资源。最好有相当大的内存和GPU。有俩个免费的选择:
- google colab
 转存失败重新上传取消
转存失败重新上传取消
colab就不需要介绍了,大家都很熟悉了,有免费GPU - paperspace转存失败重新上传取消
paperspace是一个新的深度学习的免费环境,我试用了以下,免费的GPU配置还是很不错的,大家可以试试看。
有了训练环境,导入数据,设一个神经网络,然后就可以训练了。这里省去若干介绍如何加载数据png,转换成tensor或tf的dataset。大家可以参考这些代码。
总之,大象还是没能顺利的放入冰箱,我训练的模型大都输出这样的手绘图。

离我的设想的输入差距比较大。为什么会失败呢?我想大概有以下这些原因。
- 我的神经网络比较简单,受限于硬件,我不可能训练非常复杂的神经网络。
- 我的损失函数选择不好
- 我的网络不收敛
- 我的训练时间不够
总之,完成图像到图像的翻译任务,我们需要更复杂和高深的技术。
图像到图像的翻译
经研究我发现,这个任务是一个典型的图像到图像的翻译,例如前些日子火遍大江南北的deepfake,就是基于图像到图像的翻译。
有一些专门的的研究针对图像到图像的翻译任务。一个是CycleGan,另一个是pix2pix(Conditional GAN),这两个都是基于GAN(生成对抗网络)的,所以我们先简单讲讲GAN。 (参考 在浏览器中进行深度学习:TensorFlow.js (八)生成对抗网络 (GAN))
如上图所示,GAN包含两个互相对抗的网络:G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
- Generator是一个生成器的网络,它接收一个随机的噪声,通过这个噪声生成图片。
- Discriminator是一个鉴别器网络,判别一张图片或者一个输入是不是“真实的”。它的输入是数据或者图片,输出D表示输入为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。在最理想的状态下,G可以生成足以“以假乱真”的图片
CycleGan
https://github.com/junyanz/CycleGAN
 转存失败重新上传取消
转存失败重新上传取消
实现图像间的翻译,借助GAN,应该有两个domain的鉴别器,每个鉴别器单独判断各自domain的数据是否是真实数据。至于generator,图像的翻译需要将domain A的图像翻成domain B的图像,所以generator有点像自编码器结构,只是decoder的输出不是domain A的图像,而是domain B的图像。为了充分利用两个discriminator,还应该有一个翻译回去的过程,也就是说,还有一个generator,它将domain B的数据翻译到domain A。
CycleGAN作者做了很多有意思的实验,包括horse2zebra,apple2orangle,以及风格迁移,如:对风景画加上梵高的风格。
Pix2pix
https://github.com/phillipi/pix2pix
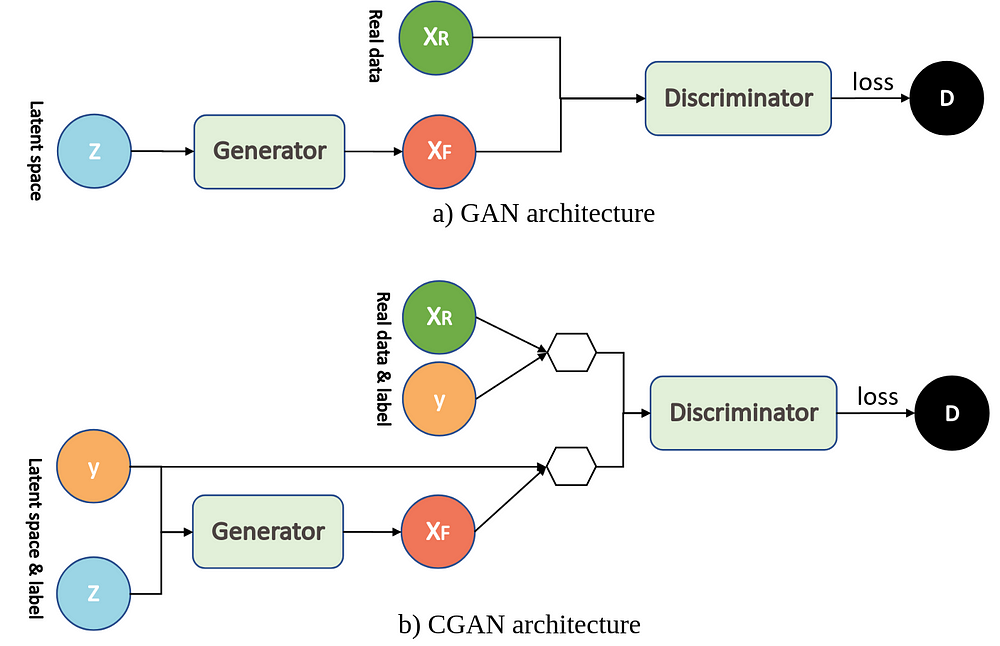
pix2pix是基于条件对抗生成网络,关于CGAN和GAN的架构区别可以参考下图:
 正在上传…重新上传取消
正在上传…重新上传取消
CGAN与GAN非常相似,除了生成器和鉴别器均以某些额外信息y为条件。可以通过将鉴别器和生成器作为附加输入层输入来执行这种调节。“ y”可以是任何种类的辅助信息,例如类别标签或来自其他模态的数据。在本教程中,我们将类标签用作“ y”。这里条件信息y是添加的额外条件信息,生成器G和鉴别器D都学会了以某些模式进行操作。例如,在面部生成应用程序的情况下,我们可以要求生成器生成带有微笑的面部,并询问鉴别器特定图像是否包含带有微笑的面部。
作者举了几个图像到图像翻译的应用例子,都挺有趣的。
好了拥有了强大的工具以后,后面的事情就比较简单了。
我利用前面提到的生成工具生成了400对bar chart的原始和手绘图,另外分别有100对测试和验证数据集。利用paperspace的免费GPU,运行https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix的pix2pix代码,使用缺省的参数,训练了200个epoch,每个epoch大概50秒,总共耗时3小时左右。
[Network G] Total number of parameters : 54.414 M
[Network D] Total number of parameters : 2.769 M
缺省的网络的参数数量如上图所示。
训练结果如下图:
上面两个是我的测试数据中的两个例子。A是原始域,B是手绘域。中间的fakeB是pix2pix模型根据原始A图生成的结果。我们看到该生成图形几乎可以乱真。
下一步
到这里是不是大功告成了呢?还没有,想想我们之前要解决的问题,对于任意的基于Canvas渲染的可视化图表,我们改如何运用该模型呢?这里我列出还需要做的工作:
- 增强数据生成功能,生成更多不同类型,数据,风格的图数据来训练一个更通用的模型(在本例子中,我们只有Bar Chart的缺省风格的训练数据)
- 部署该模型为一个服务,在客户端浏览器中利用JS把Canvas数据发送请求至该服务来获得手绘风格的输出。
- 或者利用Keras训练该模型并利用tensorflowJs直接部署到浏览器,这样做就不需要服务器端的交互,更利于集成。
总结
本文给出了一个利用深度学习实现数据可视化到手绘风格转化的实际例子,利用机器学习或者深度学习解决一个具体的问题很有趣,但是要完成端到端的功能,需要很多很琐碎的知识和系统思考的能力。希望这个故事对你有所帮助。有问题请发评论给我。
参考:
- 手绘风格的数据可视化实现 Sketchify
- 训练数据生成代码
- Pix2pix 原始论文 https://phillipi.github.io/pix2pix/
- 利用深度学习实现从图像到图像的翻译
- 条件对抗网络的图像到图像翻译 Pix2Pix
- 图像到图像的翻译 CycleGANS和Pix2Pix
- Pix2pix论文的Pytorch代码 https://github.com/junyanz/pytorch-CycleGA
- 一篇关于pix2pix的介绍 https://machinelearningmastery.com/a-gentle-introduction-to-pix2pix-generative-adversarial-network/
- 另一篇关于pix2pix的介绍 https://ml4a.github.io/guides/Pix2Pix/
- 在浏览器中进行深度学习:TensorFlow.js (八)生成对抗网络 (GAN)
附Java/C/C++/机器学习/算法与数据结构/前端/安卓/Python/程序员必读/书籍书单大全:
(点击右侧 即可打开个人博客内有干货):技术干货小栈
=====>>①【Java大牛带你入门到进阶之路】<<====
=====>>②【算法数据结构+acm大牛带你入门到进阶之路】<<===
=====>>③【数据库大牛带你入门到进阶之路】<<=====
=====>>④【Web前端大牛带你入门到进阶之路】<<====
=====>>⑤【机器学习和python大牛带你入门到进阶之路】<<====
=====>>⑥【架构师大牛带你入门到进阶之路】<<=====
=====>>⑦【C++大牛带你入门到进阶之路】<<====
=====>>⑧【ios大牛带你入门到进阶之路】<<====
=====>>⑨【Web安全大牛带你入门到进阶之路】<<=====
=====>>⑩【Linux和操作系统大牛带你入门到进阶之路】<<=====天下没有不劳而获的果实,望各位年轻的朋友,想学技术的朋友,在决心扎入技术道路的路上披荆斩棘,把书弄懂了,再去敲代码,把原理弄懂了,再去实践,将会带给你的人生,你的工作,你的未来一个美梦。
 JKX_geek
发布了45 篇原创文章 · 获赞 17 · 访问量 3608
私信
关注
JKX_geek
发布了45 篇原创文章 · 获赞 17 · 访问量 3608
私信
关注
标签:深度,生成,pix2pix,可视化,大牛带,图像,手绘,数据 来源: https://blog.csdn.net/JKX_geek/article/details/104618652