102万行代码,1270 个问题,Flink 新版发布了什么?
作者:互联网
阿里妹导读:
Apache Flink 是公认的新一代开源大数据计算引擎,可以支持流处理、批处理和机器学习等多种计算形态,也是Apache 软件基金会和 GitHub 社区最为活跃的项目之一。
2019 年 1 月,阿里巴巴实时计算团队宣布将经过双十一历练和集团内部业务打磨的 Blink 引擎进行开源并向 Apache Flink 贡献代码,此后的一年中,阿里巴巴实时计算团队与 Apache Flink 社区密切合作,持续推进 Flink 对 Blink 的整合。
2 月 12 日,Apache Flink 1.10.0 正式发布,在 Flink 的第一个双位数版本中正式完成了 Blink 向 Flink 的合并。在此基础之上,Flink 1.10 版本在生产可用性、功能、性能上都有大幅提升。本文将详细为大家介绍该版本的重大变更与新增特性。文末更有 Flink 实践精选电子书,现已开放免费下载~
Flink 实践精选电子书,现已开放免费下载~
下载地址
https://flink.apache.org/downloads.html
Flink 1.10 是迄今为止规模最大的一次版本升级,除标志着 Blink 的合并完成外,还实现了 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化等。
综述
Flink 1.10.0 版本一共有 218 名贡献者,解决了 1270 个 JIRA issue,经由 2661 个 commit 总共提交了超过 102 万行代码,多项数据对比之前的几个版本都有所提升,印证着 Flink 开源社区的蓬勃发展。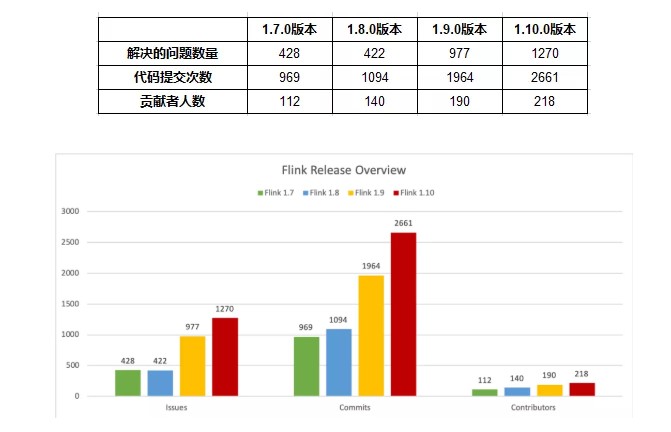
其中阿里巴巴实时计算团队共提交 64.5 万行代码,超过总代码量的 60%,做出了突出的贡献。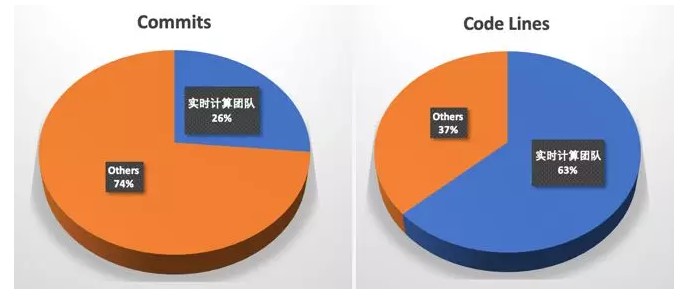
在该版本中,Flink 对 SQL 的 DDL 进行了增强,并实现了生产级别的 Batch 支持和 Hive 兼容,其中 TPC-DS 10T 的性能更是达到了 Hive 3.0 的 7 倍之多。在内核方面,对内存管理进行了优化。在生态方面,增加了 Python UDF 和原生 Kubernetes 集成的支持。后续章节将在这些方面分别进行详细介绍。
内存管理优化
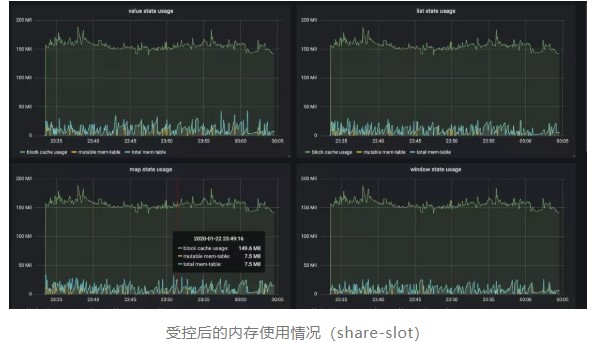
在旧版本的 Flink 中,流处理和批处理的内存配置是割裂的,并且当流式作业配置使用 RocksDB 存储状态数据时,很难限制其内存使用,从而在容器环境下经常出现内存超用被杀的情况。
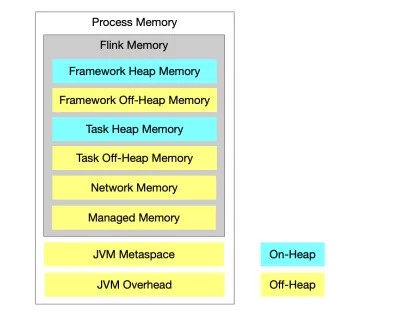
在 1.10.0 中,我们对 Task Executor 的内存模型,尤其是受管理内存(Managed Memory)进行了大幅度的改进(FLIP-49),使得内存配置对用户更加清晰:
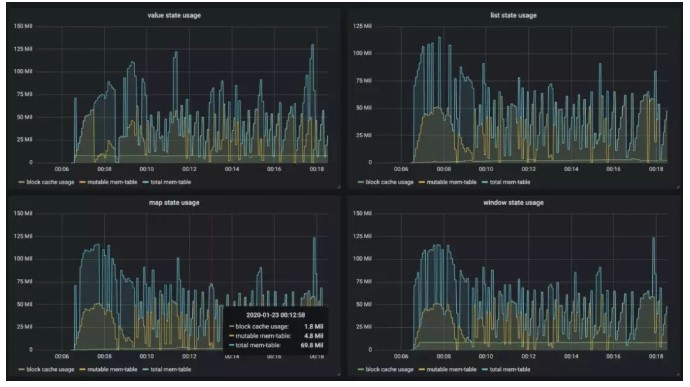
此外,我们还将 RocksDB state backend 使用的内存纳入了托管范畴,同时可以通过简单的配置来指定其能使用的内存上限和读写缓存比例(FLINK-7289)。如下图所示,在实际测试当中受控前后的内存使用差别非常明显。
Batch 兼容 Hive 且生产可用
Flink 从 1.9.0 版本开始支持 Hive 集成,但并未完全兼容。在 1.10.0 中我们对 Hive 兼容性做了进一步的增强,使其达到生产可用的标准。具体来说,Flink 1.10.0 中支持:
Meta 兼容 - 支持直接读取 Hive catalog,覆盖 Hive 1.x/2.x/3.x 全部版本
数据格式兼容 - 支持直接读取 Hive 表,同时也支持写成 Hive 表的格式;支持分区表
UDF 兼容 - 支持在 Flink SQL 内直接调用 Hive 的 UDF,UDTF 和 UDAF
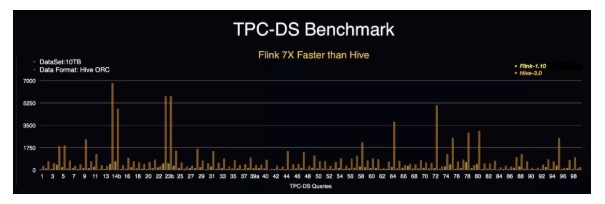
与此同时,1.10.0 版本中对 batch 执行进行了进一步的优化(FLINK-14133),主要包括:
向量化读取 ORC (FLINK-14135)
基于比例的弹性内存分配 (FLIP-53)
Shuffle 的压缩 (FLINK-14845)
基于新调度框架的优化 (FLINK-14735)
在此基础上将 Flink 作为计算引擎访问 Hive 的 meta 和数据,在 TPC-DS 10T benchmark 下性能达到 Hive 3.0 的 7 倍以上。
SQL DDL 增强
Flink 1.10.0 支持在 SQL 建表语句中定义 watermark 和计算列,以 watermark 为例:
CREATE TABLEtable_name (
WATERMARK FOR columnName AS
) WITH (
...
)
除此之外,Flink 1.10.0 还在 SQL 中对临时函数/永久函数以及系统/目录函数进行了明确区分,并支持创建目录函数、临时函数以及临时系统函数:
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION
[IF NOT EXISTS] catalog_name.function_name
AS identifier [LANGUAGE JAVA|SCALA]
Python UDF 支持
Flink 从 1.9.0 版本开始增加了对 Python 的支持(PyFlink),但用户只能使用 Java 开发的 User-defined-function (UDF) ,具有一定的局限性。在 1.10.0 中我们为 PyFlink 增加了原生 UDF 支持(FLIP-58),用户现在可以在 Table API/SQL 中注册并使用自定义函数,如下图所示:

同时也可以方便的通过 pip 安装 PyFlink:
pip install apache-flink
更多详细介绍,请参考:
https://enjoyment.cool/2020/02/19/Deep-dive-how-to-support-Python-UDF-in-Apache-Flink-1-10/
原生 Kubernetes 集成
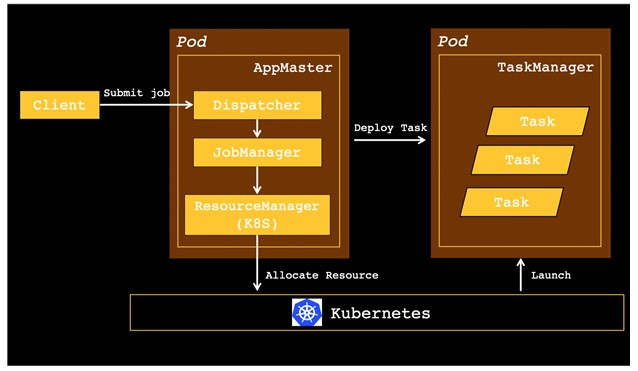
Kubernetes (K8S) 是目前最为流行的容器编排系统,也是目前最流行的容器化应用发布平台。在旧版本当中,想要在 K8S 上部署和管理一个 Flink 集群比较复杂,需要对容器、算子及 kubectl 等 K8S 命令有所了解。
在 Flink 1.10 中,我们推出了对 K8S 环境的原生支持(FLINK-9953),Flink 的资源管理器会主动和 Kubernetes 通信,按需申请 pod,从而可以在多租户环境中以较少的资源开销启动 Flink,使用起来也更加的方便。
查看更多:https://yqh.aliyun.com/detail/6274?utm_content=g_1000105428
上云就看云栖号:更多云资讯,上云案例,最佳实践,产品入门,访问:https://yqh.aliyun.com/
标签:1.10,1270,Flink,Hive,UDF,内存,支持,102 来源: https://www.cnblogs.com/yunqishequ/p/12372511.html