SLA 99.99%以上!饿了么实时计算平台3年演进历程
作者:互联网
作者介绍
倪增光,饿了么BDI-大数据平台研发高级技术经理,曾先后就职于PPTV、唯品会。15年加入饿了么,组建数据架构team,整体负责离线平台、实时平台、平台工具的开发和运维,先后经历了唯品会、饿了么数据平台从无到有到不断完善的过程。
一、背景
饿了么BDI-大数据平台研发团队目前共有20人左右,主要负责离线&实时 Infra 和平台工具开发,其中包括20+组件的开发和维护、2K+ Servers 运维及数据平台周边衍生工具研发&维护。离线 Infra 和平台工具这一块对外分享的比较多。
今天主要给大家讲讲饿了么在实时计算平台方面的一些演进经验,整个实时平台也是经历了从无到有→快速发展→平台化的阶段,每个阶段都面临了不同的问题。
二、整体规模和架构
首先介绍下目前饿了么实时平台的整体规模:
4 Kafka 集群,单 Kafka 高峰100wmsg/s;
2 ELK 集群用来做日志检索,全网索引量86w/s;
4 Storm 集群,根据业务 SLA 进行物理拆分,全网高峰计算量1.6kw/s;
2 Spark Streaming 集群和2个 Flink 集群,都是 On Yarn 模式,其中 Flink 在做一些线上业务尝试;
20个以上业务方接入,共120+ Storm 任务(包括双活 & DataPipeline 业务)、26+ Spark Streaming 任务、10+ Streaming SQL 任务,涉及实时搜索推荐、实时风控、实时监控、实时营销等项目。
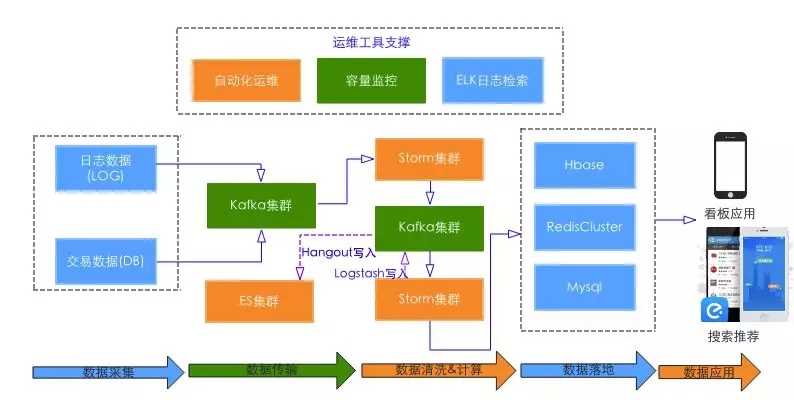
整体架构图如下:
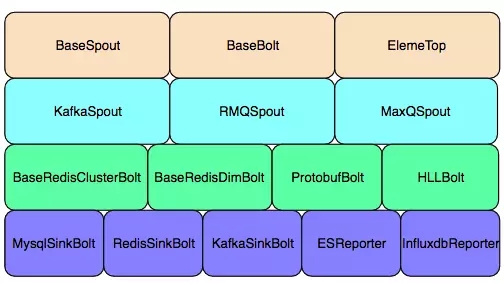 封装组件列表
运维管理方面:
为了解整体的容量情况,开发实时容量看板,通过实时获取 Zabbix Item LastValue 来监控 Storm & RedisCluster 实时压力情况;
为方便用户可以快速查看任务 Log 引入 ELK,同时在 Kafka2es 这一层引入 Hangout 替代 Flume (可支持3x以上性能提升),最终实现了 Storm Top Log->Logstash->Kafka->Hangout->ES->Kanbana 的整个 Log 链路。
整体 SLA 增强方面:
数据采集侧和计算侧均引入限速 & 反压功能,防止流量暴涨导致的雪崩效应;
从数据采集到数据最终落地使用双链路的方式,并采用多机房方式:比如数据采集端分布在异地两机房,使用本地计算+最终 Merge 或者数据双向传输+全量计算的方式;
配合 Kafka Binlog 数据的重放和 Nginx 模拟访问,对全链路进行模拟压测,配合实时监控 & 业务表现来关注各组件的性能临界点;
基于3的数据进行容量规划,同时做好资源的隔离;
完善各层面的监控和报警策略,包括模拟用户的访问来验证链路的情况,同时为了避免口径不一致导致的数据问题,开发离线&实时数据质量对比 Report,监控数据质量问题;
在业务端&后端增加降级策略,同时后端服务 Auto Failover;
完善各紧急预案 SOP,并针对性演练:比如通过切断 Active 的数据落地层来确定应用是否可以 Auto Failover;
数据层利用缓存,比如把一些 Storm 中间计算态数据写入 Redis 中;
同时为了防止应用 Crash 导致数据断层问题,开发了补数功能,在异常恢复后可以通过离线的数据补齐历史数据。
通过上述的一系列调整,最终抗住业务几倍的流量增长,保证了整体服务的稳定性。
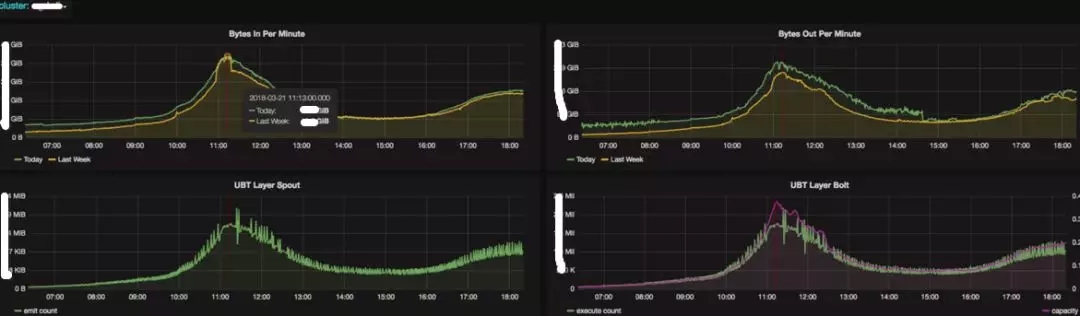
业务监控 Dashboard 部分示例:
封装组件列表
运维管理方面:
为了解整体的容量情况,开发实时容量看板,通过实时获取 Zabbix Item LastValue 来监控 Storm & RedisCluster 实时压力情况;
为方便用户可以快速查看任务 Log 引入 ELK,同时在 Kafka2es 这一层引入 Hangout 替代 Flume (可支持3x以上性能提升),最终实现了 Storm Top Log->Logstash->Kafka->Hangout->ES->Kanbana 的整个 Log 链路。
整体 SLA 增强方面:
数据采集侧和计算侧均引入限速 & 反压功能,防止流量暴涨导致的雪崩效应;
从数据采集到数据最终落地使用双链路的方式,并采用多机房方式:比如数据采集端分布在异地两机房,使用本地计算+最终 Merge 或者数据双向传输+全量计算的方式;
配合 Kafka Binlog 数据的重放和 Nginx 模拟访问,对全链路进行模拟压测,配合实时监控 & 业务表现来关注各组件的性能临界点;
基于3的数据进行容量规划,同时做好资源的隔离;
完善各层面的监控和报警策略,包括模拟用户的访问来验证链路的情况,同时为了避免口径不一致导致的数据问题,开发离线&实时数据质量对比 Report,监控数据质量问题;
在业务端&后端增加降级策略,同时后端服务 Auto Failover;
完善各紧急预案 SOP,并针对性演练:比如通过切断 Active 的数据落地层来确定应用是否可以 Auto Failover;
数据层利用缓存,比如把一些 Storm 中间计算态数据写入 Redis 中;
同时为了防止应用 Crash 导致数据断层问题,开发了补数功能,在异常恢复后可以通过离线的数据补齐历史数据。
通过上述的一系列调整,最终抗住业务几倍的流量增长,保证了整体服务的稳定性。
业务监控 Dashboard 部分示例:
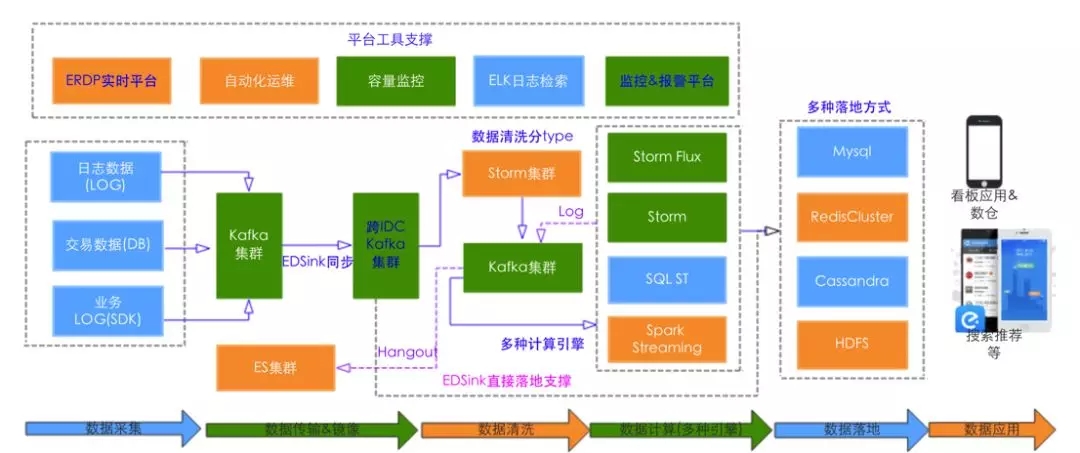
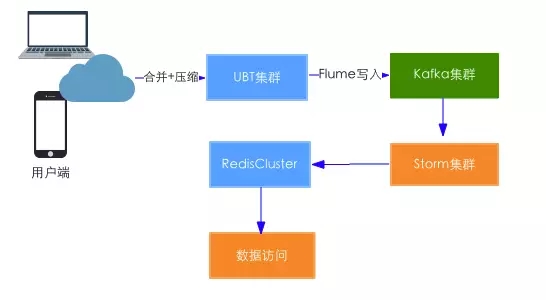
封装组件列表
运维管理方面:
为了解整体的容量情况,开发实时容量看板,通过实时获取 Zabbix Item LastValue 来监控 Storm & RedisCluster 实时压力情况;
为方便用户可以快速查看任务 Log 引入 ELK,同时在 Kafka2es 这一层引入 Hangout 替代 Flume (可支持3x以上性能提升),最终实现了 Storm Top Log->Logstash->Kafka->Hangout->ES->Kanbana 的整个 Log 链路。
整体 SLA 增强方面:
数据采集侧和计算侧均引入限速 & 反压功能,防止流量暴涨导致的雪崩效应;
从数据采集到数据最终落地使用双链路的方式,并采用多机房方式:比如数据采集端分布在异地两机房,使用本地计算+最终 Merge 或者数据双向传输+全量计算的方式;
配合 Kafka Binlog 数据的重放和 Nginx 模拟访问,对全链路进行模拟压测,配合实时监控 & 业务表现来关注各组件的性能临界点;
基于3的数据进行容量规划,同时做好资源的隔离;
完善各层面的监控和报警策略,包括模拟用户的访问来验证链路的情况,同时为了避免口径不一致导致的数据问题,开发离线&实时数据质量对比 Report,监控数据质量问题;
在业务端&后端增加降级策略,同时后端服务 Auto Failover;
完善各紧急预案 SOP,并针对性演练:比如通过切断 Active 的数据落地层来确定应用是否可以 Auto Failover;
数据层利用缓存,比如把一些 Storm 中间计算态数据写入 Redis 中;
同时为了防止应用 Crash 导致数据断层问题,开发了补数功能,在异常恢复后可以通过离线的数据补齐历史数据。
通过上述的一系列调整,最终抗住业务几倍的流量增长,保证了整体服务的稳定性。
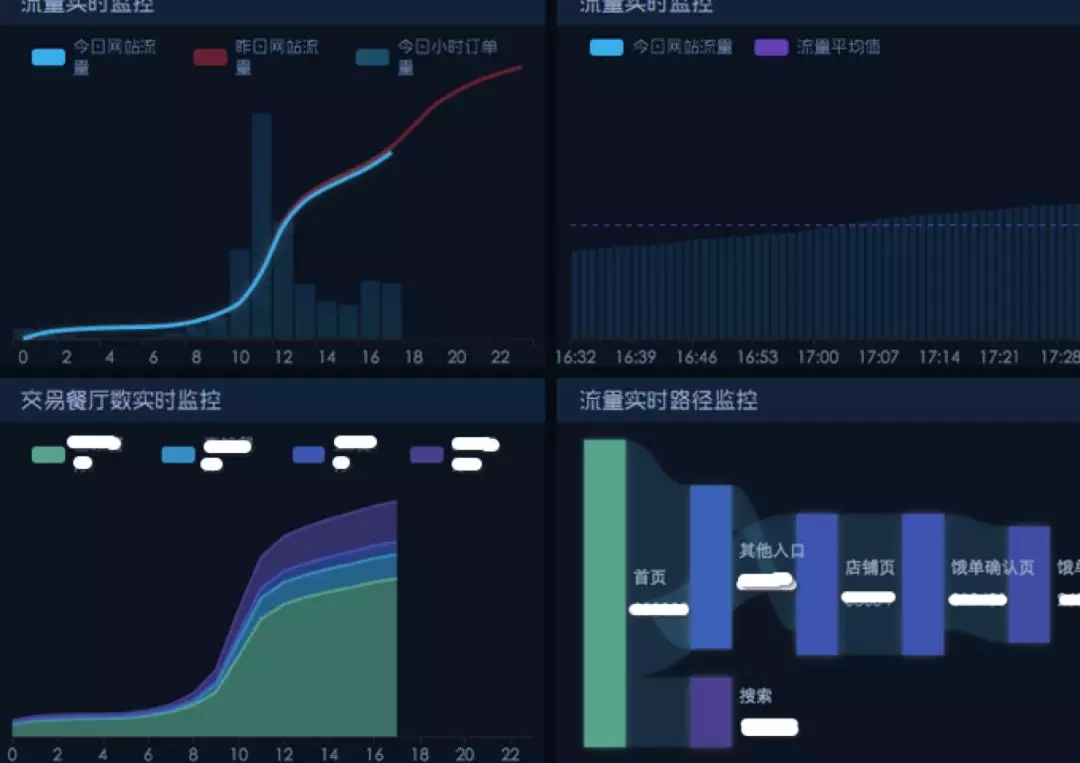
业务监控 Dashboard 部分示例:
标签:演进,平台,离线,用户,实时,SLA,Kafka,数据,99.99% 来源: https://www.cnblogs.com/ExMan/p/11923935.html