关系抽取 ---远程监督 ---《Robust Distant Supervision Relation Extraction via Deep Reinforcement Learning》
作者:互联网
概述:
本文主要是设计了一个深度强化学习框架,用于移除原始训练集中的假阳性实例,并重建一个纯净的训练(测试)数据集,以提高关系分类的精度。
该算法独立于关系抽取模型的,是一种即插即用的技术,可应用于任何一个现有的远程监督关系抽取模型
- 问题引入
关系抽取是知识图谱构建的关键模块之一,同时它也是许多自然语言处理应用的重要组成部分,诸如情感分析、问答系统和自动摘要等。其核心任务是预测句子中实体间的关系。例如,给定一个句子“Barack Obama is married to Michelle Obama.”,关系抽取的任务即预测出句中两个实体间的关系为“配偶”关系。
关系抽取算法最为突出的特点之一是对标注实例存在着数量上的巨大需求,这一任务对于手工标注几乎是不可能完成的。在此背景下,远程监督关系抽取算法应运而生。但该技术并不是完美无缺——远程监督数据集始终无法摆脱噪声数据的影响。
为了抑制噪声,人们尝试利用注意力机制对含有噪声的句子集合赋予权重以选择出有效的训练样本。但是,文章认为这种只选择出一个最佳样本的思路并不是最优的策略。为了提高模型的鲁棒性,对于假正例不应只是简单的移除,而是应把它们放在正确的位置——负例集合中。
- 远程监督中的强化学习

与之前未充分利用远程监督样本的算法相比,该策略利用 RL agent 来进行远程监督关系抽取。这里 agent 的目标是根据关系分类器性能的变化,决定是保留还是移除当前的实例(即一个句子)。然后,框架进一步使基于深度强化学习策略的 agent 学会如何重建一个纯净的远程监督训练数据集。
对于强化学习(RL),其拥有的两个必备组件分别是:外部环境(external environment)和 RL agent,而一个具有良好鲁棒性的 agent 正是通过这两个组件的动态交互而训练出来的。
- 文章提出的 RL 方法各基本组成部分描述如下:
状态(States):为了满足马尔可夫决策过程(Markov decision process,MDP)的条件,状态 s 同时包含当前句子和早期状态中移除的句子的信息。句子的语义和句法信息由一个连续实值向量表示。文章参考一些性能较好的监督关系抽取算法,同时使用词嵌入和位置嵌入以将句子转换为向量。有了这些句子向量,可以将当前句子向量与早期状态中移除句子的平均向量级联起来,用以表示当前状态。对于当前句子的向量,给予相对较大的权重,以增大当前句子信息对决策行为的支配性影响。
行为(Actions):在每一步中,agent 都会去判定实例对于目标关系类型是否为假阳性。每一个关系类型都拥有一个 agent,每个 agent 都有两个行为:对于当前实例,作出是删除或是保留的决定。
由于初始的远程监督数据集中包含有被错误标注的实例,期望 agent 能利用策略网络过滤掉这些噪声实例,由此得到的纯净数据集,以使远程监督获得更好的性能。
奖励(Rewards):如前所述,对于文章提出的模型可简单的理解为:当错误标注数据被过滤掉后,关系分类器便能获得更好的性能。因此,文章中的模型采用结果驱动策略,以性能变化为依据,对 agent 的一系列行为决策进行奖励。奖励通过相邻 epochs 的差值来表示:
![]()
如上式所示,在第 i 步时,F1 增加,则 agent 将收到一个正奖励;反之,则 agent 将收到一个负奖励。通过这样的设置,奖励值将与 F1 的差值成比例,α 的作用是将 F1 的差值转换到有理数的范围内。为了消除 F1 的随机性,文章使用最近 5 个 epochs 的 F1 值的平均值来计算奖励。
策略网络(Policy Network):对于每个输入的句子,策略网络负责判断该句子是否表述了目标关系类型,然后对于与目标关系类型无关的句子启动移除操作。这样,多元分类器就转换为了二元分类器。文章使用一个窗口大小为、kernel size 为的 CNN 来对策略网络 π(s;θ) 建模。
-
- 预训练策略
这里的预训练策略,是受到了 AlphaGo 的启发,是 RL 中加快 agent 训练的一种常见策略。对于某一具体的关系类型,直接将远程监督正例集合作为正例集合,同时随机选取远程监督负例集合的一部分作为负例集合。
为了在预训练过程中能更好的考虑初始信息,负实例的数量是正实例数量的 10 倍。这是因为,通过学习大量负例样本,agent 更有可能朝着更好的方向发展。文章利用交叉熵代价函数来训练这一二元分类器,其中,负标签对应于删除行为,正标签对应于保留行为。


-
- 基于奖励的agent再训练
如上图所示,为了能够识别出噪声实例,这里引入一种基于 RL 策略的算法,其中的 agent 主要用于过滤出远程监督正例集合中的噪声样本
首先,将该集合分解为训练正例集合![]() 和验证正例集合
和验证正例集合![]() ,这两个集合中都会包含有噪声。相应地,训练负例集合
,这两个集合中都会包含有噪声。相应地,训练负例集合![]() 和验证负例集合
和验证负例集合![]() 是通过从远程监督负例集合中随机抽取获得。在每一个epoch中,通过随机策略 π(a|s) 从
是通过从远程监督负例集合中随机抽取获得。在每一个epoch中,通过随机策略 π(a|s) 从![]() 中过滤出噪声样本集合,进而获得新的正例集合
中过滤出噪声样本集合,进而获得新的正例集合 。由于是被识别出的错误标注实例,因而将其补充进负例集合
。由于是被识别出的错误标注实例,因而将其补充进负例集合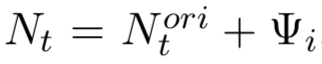 。此时,每一个epoch中,训练集的规模是恒定的。之后,使用纯净数据集
。此时,每一个epoch中,训练集的规模是恒定的。之后,使用纯净数据集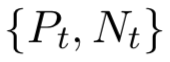 来训练关系分类器。预期的情况是,通过 RL agent 转移假正例,以提升关系分类器的性能。为此,利用验证集合
来训练关系分类器。预期的情况是,通过 RL agent 转移假正例,以提升关系分类器的性能。为此,利用验证集合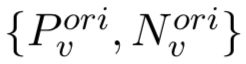 来测试当前 agent 的性能。首先,利用当前agent对验证集中的噪声实例进行识别和转移,获得
来测试当前 agent 的性能。首先,利用当前agent对验证集中的噪声实例进行识别和转移,获得 ;然后:利用该集合计算当前关系分类器的F1得分。最后,通过计算当前和上一 epoch 的 F1 得分的差值以获得奖励值。
;然后:利用该集合计算当前关系分类器的F1得分。最后,通过计算当前和上一 epoch 的 F1 得分的差值以获得奖励值。
在上述训练过程中,为避免 agent 将正例集合中的真正例误删,在每一个 epoch 中,对 RL agent 移除句子的数目设置一个阈值,即一个 epoch 中移除的句子数目不能超过该值。这样,如果 agent 决定移除当前实例,则其他实例被移除的概率将变小。
经过上面的强化学习过程,对于每一种关系类型,都得到了一个可作为假正例指示器的 agent(二分类器),利用这些 agent 来识别出远程监督数据集中的假正例。

标签:agent,分类器,Extraction,实例,Relation,Supervision,移除,集合,句子 来源: https://www.cnblogs.com/dhName/p/11891046.html