2019-05-16-日常零碎知识点
作者:互联网
版权声明:本文为 Jiawei Xu 于2019年5月16日所写,未经允许不得转载。
Linux网络编程
socketaddr
socktaddr_in
socketaddr_un
UNIX Domain Socket,虽然网络socket也可以用于同一台主机的进程间通讯(通过loopback地址127.0.0.1),但是UNIX Domain Socket用于IPC更有效率:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答,只是将应用层数据从一个进程拷贝到另一个进程。这是因为,IPC机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。Unix Domain Socket也提供面向流和面向数据包两种API接口,类似于TCP和UDP,但是面向消息的UNIX Domain Socket也是可靠的,消息既不会丢失也不会顺序错乱。X Window服务器和GUI程序之间就是通过UNIX Domain Socket通讯的。
使用UNIX Domain Socket的过程和网络socket十分相似,也要先调用socket()创建一个socket文件描述符,address family指定为AF_UNIX,type可以选择SOCK_DGRAM或SOCK_STREAM,protocol参数仍然指定为0即可。
UNIX Domain Socket与网络socket编程最明显的不同在于地址格式不同,用结构体sockaddr_un表示,网络编程的socket地址是IP地址加端口 号,而UNIX Domain Socket的地址是一个socket类型的文件在文件系统中的路径,这个socket文件由bind()调用创建,如果调用bind()时该文件已存 在,则bind()错误返回。
参考资料:
Linux C中内联汇编 Inline Assembly
基本语法规则:
内联汇编(或称嵌入汇编)的基本语法模板比较简单,如下所示:
123456
asm [ volatile ] ( assembler template [ : output operands ] [ : input operands ] [ : list of clobbered registers ] );
由5部分组成:
1)关键字asm和volatile
asm为gcc关键字,表示接下来要嵌入汇编代码。为避免keyword asm与程序中其它部分产生命名冲突,gcc还支持__asm__关键字,与asm的作用等价。
volatile为可选关键字,表示不需要gcc对下面的汇编代码做任何优化。同样出于避免命名冲突的原因,__volatile__也是gcc支持的与volatile等效的关键字。
2)assembler template
这部分即我们要嵌入的汇编命令,由于我们是在C语言中内联汇编代码,故需用双引号""将命令括起来,以便gcc以字符串形式将这些命令传给汇编器AS。例如可以写成这样:"movl %eax, %ebx" 有时候,汇编命令可能有多个,则通常分多行写,每行的命令都用双引号括起来,命令后紧跟”nt”之类的分隔符(当然,也可以只用1对双引号将多行命令括起来,从语法来说,两种写法均有效,我们可自行决定用哪种格式来写)。示例代码如下所示:
1234
__asm__ __volatile__ ( "movl %eax, %ebxnt" "movl %ecx, 2(%edx, %ebx, $8)nt" "movb %ah, (%ebx)" );
还有时候,根据程序上下文,嵌入的汇编代码中可能会出现一些类似于魔数(Magic Number) )的操作数,比如下面的代码:
1234567
int a=10, b;asm ("movl %1, %%eax; /* NOTICE: 下面会说明此处用%%eax引用寄存器eax的原因 movl %%eax, %0;" :"=r"(b) /* output 该字段的语法后面会详细说明,此处可无视,下同 */ :"r"(a) /* input */ :"%eax" /* clobbered register */ ); movl指令的操作数(operand)中,出现了%1、%0。在内联汇编中,操作数通常用数字来引用,具体的编号规则为:若命令共涉及n个操作数,则第1个输出操作数(the first output operand)被编号为0,第2个output operand编号为1,依次类推,最后1个输入操作数(the last input operand)则被编号为n-1。
具体到上面的示例代码中,根据上下文,涉及到2个操作数变量a、b,这段汇编代码的作用是将a的值赋给b,可见,a是input operand,而b是output operand,那么根据操作数的引用规则,不难推出,a应该用%1来引用,b应该用%0来引用。 还需要说明的是:当命令中同时出现寄存器和以%num来引用的操作数时,会以%%reg来引用寄存器(如上例中的%%eax),以便帮助gcc来区分寄存器和由C语言提供的操作数。
3)output operands
该字段为可选项,用以指明输出操作数,典型的格式为: ` : "=a" (out_var)` 其中,"=a"指定output operand的应遵守的约束(constraint),out_var为存放指令结果的变量,通常是个C语言变量。本例中,“=”是output operand字段特有的约束,表示该操作数是只写的(write-only);“a”表示先将命令执行结果输出至%eax,然后再由寄存器%eax更新位于内存中的out_var。关于常用的约束规则,本文后面会给出说明。 若输出有多个,则典型格式示例如下:1234
asm ("cpuid" : "=a" (out_var1), "=b" (out_var2), "=c" (out_var3) : "a" (op) );>可见,我们可以为每个output operand指定其约束。 > >4)input operands > 该字段为可选项,用以指明输入操作数,其典型格式为: > `: "constraints" (in_var)` > 其中,constraints可以是gcc支持的各种约束方式,in_var通常为C语言提供的输入变量。 > 与output operands类似,当有多个input时,典型格式为: > `: "constraints1" (in_var1), "constraints2" (in_var2), "constraints3" (in_var3), …` > 当然,input operands + output operands的总数通常是有限制的,考虑到每种指令集体系结构对其涉及到的指令支持的最多操作数通常也有限制,此处的操作数限制也不难理解。此处具体的上限为max(10, max_in_instruction),其中max_in_instruction为ISA中拥有最多操作数的那条指令包含的操作数数目。 > 需要明确的是,在指明input operands的情况下,即使指令不会产生output operands,其:也需要给出。例如asm ("sidt %0n" : :"m"(loc)); 该指令即使没有具体的output operands也要将:写全,因为有后面跟着: input operands字段。 > > > >5)list of clobbered registers > 该字段为可选项,用于列出指令中涉及到的且没出现在output operands字段及input operands字段的那些寄存器。若寄存器被列入clobber-list,则等于是告诉gcc,这些寄存器可能会被内联汇编命令改写。因此,执行内联汇编的过程中,这些寄存器就不会被gcc分配给其它进程或命令使用。参考资料:
-
In computer programming, the term magic number has multiple meanings. It could refer to one or more of the following:
- Unique values with unexplained meaning or multiple occurrences which could (preferably) be replaced with named constants
- A constant numerical or text value used to identify a file format or protocol; for files, see List of file signatures
- Distinctive unique values that are unlikely to be mistaken for other meanings (e.g., Globally Unique Identifiers)
- Variable values used to accumulate values of register (e.g. variable)). It can be changed at any point in time.
常用非易失内存编程指令
clflush(Cache Line Flush,缓存行刷回)
在处理器缓存层次结构(数据与指令)的所有级别中,使包含源操作数指定的线性地址的缓存线失效。失效会在整个缓存一致性域中传播。如果缓存层次结构中任何级别的缓存线与内存不一致(污损),则在使之失效之前将它写入内存。源操作数是字节内存位置。
CLFLUSHOPT(Optimized CLFLUSH,优化的缓存行刷回)
作用与 CLFLUSH 相似,但其之间的指令级并行度更高,比如在访问不同 CacheLine 时,CLFLUHOPT 可以乱序执行。
CLWB(Cache Line Write Back,缓存行写回)
作用与 CLFLUSHOPT 相似,但在将缓存行中的数据写回之后,该缓存行仍将呈现为未被修改过的状态;支持现状
NT STORES(NonTemporal stores)
NT STORES 是一系列用于存储不同字长数据的指令,其包括 MOVNTDQ等。NT Stores 指令在传输数据时能够绕过缓存,而直接将数据写入主存。
FENCE
FENCE 指令,也称内存屏障(Memory Barrier),起着约束其前后访存指令之间相对顺序的作用。其包括 LFENCE(约束 Load 指令), MFENCE(约束 L/S 指令), SFENCE(约束 Store 指令)。
参考资料:
-
计算机存储器,典型访问时间,典型容量:
- 寄存器:1ns,几十~几百B
- 一级Cache:5~10ns,几十~几百KB
- 二级Cache:40~60ns,几百KB~几MB
- 内存:100~150ns,几百MB~几GB
- 硬盘:3~15ms,几百GB~几TB
Cache:高速缓冲存储器,为了更好的利用局部性原理,减少CPU访问主存的次数。
Cache分成多个组,每个组分成多个行,line size是cache的基本单位,从主存向cache迁移数据都是按照line size为单位替换的。比如line size是32Byte,那么迁移必须一次迁移32Byte到cache。同个cache的line size总是相同的。
8路相连,8-way set associative,每个组有8个行。
主存中的地址和cache的映射关系:拿到一个地址,首先是映射到一个组里面去。cache总大小32KB,8路组相连(每组有8个line),每个line的大小line size为64Byte。一共有32K/8/64=64个组。对于32位的内存地址,每个line有2^6=64Byte,所以[0,5]区分line中的那个字节,一个64个组,我们取内存地址中间6位来hash查找地址属于哪个组。即内存地址的[6,11]位来确定属于64组的哪一个组。组确定了以后,[12,31]的内存地址与组中8个line挨个对比,如果[12,31]位与某个line一致,并且这个line位有效,那么缓存命中。
cache分成三类:
- 直接映射高速缓存(direct-mapped),每个组只有一个line,选中组之后不需要和组中的每个line比对,因为只有一个line。
- 组相连高速缓存(set-associative),S个组,每个组E个line
- 全相连高速缓存(fully-associative),只有一个组,不用hash来确定组,直接挨个比对高位地址,来确定是否命中,这种方式不适合大的缓存。
内存地址: 假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位)
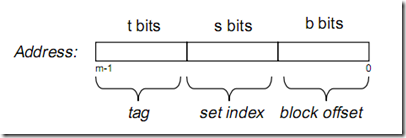
cache的逻辑结构:
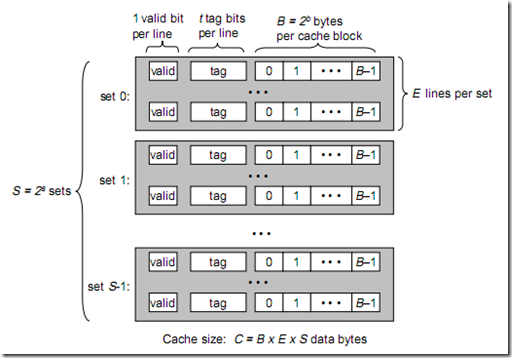
将此图与上图做对比,可以得出各参数如下:
B = 2^b
S = 2^s
现在来解释一下各个参数的意义:
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中,有B个存储单元,现代处理器中,这个存储单元一般是以字节(通常8个位)为单位的,也是最小的寻址单元。因此,在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功是,我们称为cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)。当不命中的情况发生时,系统就会从内存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。
标签:知识点,操作数,缓存,operands,05,cache,16,output,line 来源: https://www.cnblogs.com/chinatrump/p/11584477.html