微软云基础架构Hyper-scale Datacenter
作者:互联网
每天醒来,可能很多人的习惯都是打开手机,看看微信,刷刷朋友圈,或者看看新闻,去咖啡店,打开电脑搜索一些关键字,观看视频,电视剧……可是你有没有想过你每一次键盘的敲击,每一次微信的语音的发送,数据会流向哪里,会怎么传播,我们怎么会快速的得到离我最近的餐厅信息?事实上,你所使用的所有这些服务,都运行在一个个的数据中心中,而数据中心正是信息世界中数据交换,流动,计算的心脏。
越来越多的大型IT公司将自己的数据中心和云端基础设施作为其重要的战略资产和核心竞争力的一部分,也有人可能看到过网上流出的google数据中心的图片,高科技,干净,整洁,很先进的感觉,还有Facebook的机房,其水冷系统,太阳能面板……作为软件巨无霸,行走在转型之路上的微软公司的数据中心又是怎么样的呢?
事实上,微软从1989年开始就运营自己的数据中心,1994年提供公共在线服务,总共有超过20多年的数据中心建设,管理和运营经验!
到今天为止,微软在全球90多个市场上运营管理着超过100个数据中心,100+万台服务器,向全球10亿多用户提供200+在线服务,包括Xbox,O365,Bing,Azure,Outlook,Skype等,是真正的超大规模数据中心(hyper-scale datacenter).
如果你想象一下,有100万台服务器,每天的电力消耗,就要按百万美金级别来计算,这不包括服务器的维护,升级,更新换代,计划之外的服务中断等等消耗,另外还有机房,人力等等成本,所以很多人讲云计算是规模经济,烧钱的游戏,用户规模上不去,其实就是死路一条,微软在超规模数据中心上的投入目前公布的数字是150亿美金,这些资金用来持续不断的为数据中心创新,为用户提供更好的服务。
当然庞大的数量并不是超大规模数据中心需要解决的唯一问题,每天全球大约会有10万新用户使用微软的云服务,并且微软为企业级用户提供具有财务保障的SLA云端服务,如何保证超大规模数据中心服务稳定可靠,可高度扩展,安全合规,并且能源消耗需要满足微软对生态可持续的企业责任并降低成本等等,这些问题才是关键,并且需要在设计之初就要考虑进去。
本文不揣浅陋,从微软云策略,hyper-scale数据中心建立的准则,能耗水平,开源云服务器和软件定义的高可用性等层面介绍一下微软的超规模数据中心。
微软的云策略
大家都在做云计算,都提供云服务,但微软相比其他各家云服务提供商,最大的差别在哪里呢?
第一个是企业级服务:微软在过去的几十年里,为全球几千万的企业级客户提供服务,深刻理解企业级客户对可靠性,安全性,高性能等方面的要求,在设计云计算服务和数据中心的时候,同样将这些需求带入到了其设计准则之中(见设计准则)
第二个是混合云:这个词最近几年很热,然而你如果看看目前市场上提供公有云服务,同事提供私有云服务又有完整的混合云解决方案的厂家,其实寥寥。
第三个是超规模:前面已经介绍了微软数据中心的概况。超规模的数据中心对用户的好处是什么呢?举一个例子,比如你是中国的一家企业,在Azure上部署了你的企业级应用,如果你想进军国家市场,又不熟悉当地的法规要求,那你不用担心,微软的Azure已经获得美国,欧洲等国家的大部分数据中心认证和合规性要求,你只需要平滑的把你的应用部署到Azure全球数据中心就可以快速开展你的业务而不用担心合规,并且成本很低。
Hyper-scale数据中心设计准则
在微软建规模数据中心之初,就制定了一些最基本准则,依照这些准则在全球建立统一标准的数据中心:
准则一:灵活可扩展。业务在不断增长,用户在不断增加,为此数据中心可以根据业务的需求快速的扩展计算,网络,存储等能力,另外一个很重要的点事,你所设计的基础架构应该是通用的,而不是只为特定的工作负载使用。
准则二:低成本。在保证服务水平和质量的情况下,就可能的降低成本,这部分实际上带入了很多创新,比如制冷,空调,服务器,后面详细介绍。由于规模效应,Every cent matters.
准则三:运营标准化。在全球如此多的数据中心,如何做到简化运营,提供高质量的服务是很重要的一个考量维度,微软无论是在美国,欧洲还是在中国,都按照一致的标准流程运营。
准则四:通用性基础架构。为服务更多用户,快速创新,微软的云基础架构适用于多种不同的负载,比如HPC。
准则五:软件容错性。这是最基本的原则,就是我们Designed for failures,无论是硬件,软件还是人为错误。软件要有能力自我恢复和修复。
准则六:软件定义的高可用性。在一个地区或者跨地区,在云平台之上,让用户定义或者默认设置相应的服务策略,提供软件定义的高可用性。比如冗余备份,高可用集合等。
数据中心能效水平
数据中心都是电力消耗大户,并且是数据中心运营成本的主要部分,其中空调,制冷,配电等占大头。对于一些有责任的企业来说,降低数据中心的能耗,除了成本是主要考虑因素之外,对环境可持续发展的承诺也是一家有责任心的企业需要做的事情。
目前对于数据中心能耗的测量,业内公认的最具有影响力的是绿色网格组织(http://www.thegreengrid.org/)定义的PUE,即Power Usage Efficieniveness,PUE是个什么概念呢?非常简单的说,就是你的数据中心总的电力消耗除以用于服务器的电力消耗。也就说服务器计算每消耗1度电,那么一般额外会有0.5到1度或者更多的电力被用于传输损耗,制冷等,所以一般情况下PUE越小,代表你的数据中心能耗越高效。

所以PUE是一个总体指标衡量,可以体现你的数据中心设计的先进程度和对于能耗节约的创新考量指标,那么我国数据中心目前的平均PUE是什么水平呢?我们看看一些专家的调研(http://www.docin.com/p-435617076.html),我国数据中心的平均PUE是2.2,那么今天微软的数据中心PUE可以达到多少呢?目前是第五代数据中心,可以达到1.07到1.19!

大家可以看到,冰冻三尺非一日之寒,微软的数据中心也经过了漫长的演进路线,在2007年以后由于数据中心的急剧增多,PUE所带来的成本和问题也凸显出来,因此微软的数据中心和运营团队做了大量的创新来降低PUE,比如:
- 对数据中心设备进行追踪采样,获得100多万个样本值进行大数据分析获得能源损耗评估和策略优化建议
- 服务器优化:定制化服务器(见开放云服务器),去除不必要的部分,优化设计
- 制冷优化设计:降低电力制冷,利用外部空气制冷,机柜水冷,优化风道设计等等
-
电力分布优化:降低传输损耗
如果大家有兴趣了解详情,请参考:http://www.microsoft.com/en-us/server-cloud/cloud-os/global-datacenters.aspx#Fragment_Scenario6
开放云服务器
开放计算项目(Open Compute Project,http://www.opencompute.org/)是由Facebook于2011年发起的一个致力于打造开放式数据中心硬件的计算项目,包括服务器,存储,机柜,网络等等。如果对于OCP不太了解,你的疑问可能会是,已经有那么多服务器提供商比如DELL,HP,IBM,Lenovo,为什么换需要自己做服务器呢?对大部分互联网数据中心来讲,他们所需要的服务器是高度可定制化的,需要满足其scale的要求,而目前的标准服务器无法满足这种高度可定制化的要求;在中国,其实BAT三家也发起了类似的项目,叫"天蝎计划",有兴趣的同学可以了解下(http://baike.baidu.com/subview/14210482/15764055.htm)。
微软在构建超规模数据中心的时候,对于云服务器的要求希望是简化,高效,模块化,可管理,可持续,比如去除不必要的组件,降低店里消耗等,然而标准服务器无法满足这些要求,于是自行设计第一代云服务器,并部署在全球数据中心。
为构建良好的生态系统,微软于2014年1月加入OCP,并把第一代Open Cloud Server的规范捐献给了OCP,而在2014年10月又将OCS V2献给了OCP。
如果有兴趣,可以参考下面的信息:
http://www.opencompute.org/wiki/Motherboard/SpecsAndDesigns#Open_CloudServer
这两部分图片是OCS V2版本的一些新特性,微软新的一些数据中心开始采用OCS V2的服务器:


那么这些变革和创新,对微软和客户带来的价值是什么?仅OCS,其固定成本下降40%,而电力消耗下降15%,部署和服务时间降低50%。
软件定义的高可用性
对于超规模的数据中心,在做设计的时候,其实我们有三个基本假设前提:
- 所有的硬件都会失败
- 所有的软件都有bug
- 人都会犯错误
在这些假设前提之下,如何从数据中心层面,利用软件和策略保证用户的服务高可用呢?尤其对于企业级客户,这一点至关重要。
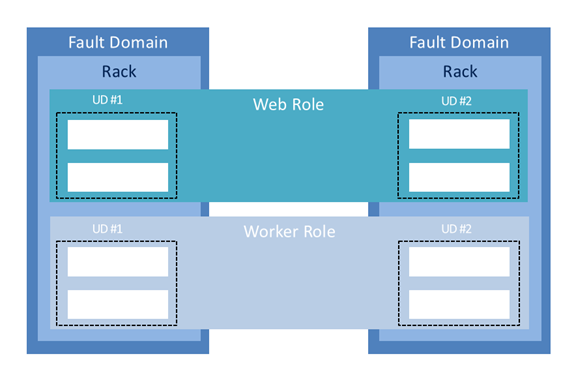
在介绍Azure的软件定义的高可用之前,先简单介绍一下微软的数据中心架构,对于Azure的来讲,每个地区(region)下会有多个数据中心,而每个数据中心由多个集群(cluster)组成,每个集群下面会有多个Rack,而Rack里面是服务器。
Fault Domain:错误域,你可以把FD看做一组会同时失败的资源组合,比如同样一个Rack,同样一个服务器。
Update Domain:更新域,代表一组会同时被更新的资源组合,比如同样一个主机。
Availability Set: 有效集,当你有超过一个虚拟机部署在有效集中时,他们会被分布在不同的Rack上,以保证当一个Rack发生故障后,服务的高可用
下图比较清晰的展示了FD和UD,web role和worker role是两个可用集:
了解了这些概念之后,我们看看在Azure的数据中心如何利用一些策略和软件定义来保证服务的高可用性:
云服务的部署:在云服务中,虚拟机会被自动部署在不同的FD中,默认也会设置5个更新域,你也可以通过csdef对更新域进行设置,这样即使一个RACK发生问题,你至少还有一个服务在运行;或者更新的时候,对于提供相同服务的VM,你可以将他们定义在不同的UD,这会告诉云平台在更新的时候只能选择相应的VM
虚拟机的部署:对于多个VM的部署,你可以将他们部署在一个有效集中,以保证当数据中心的单个Rack发生故障或者需要升级时,有另外一个VM可以提供服务
服务自我修复:当数据中心的服务发生故障时,系统会自动检测和修复,包括重启服务和自动回复,而不需要人工干预
数据的本地同步复制: 对于存储在Azure上的数据,默认会在本地数据保留三份备份
异步跨地区复制:对于存储在Azure上的数据,如果开启了异地备份,那么你的数据会在异地复制三份,总共6份数据拷贝
跨地区的高可用性:如果你有两个跨地区的站点互为备份,Azure的Traffic manager能够自动监测两个站点的可用性,当一个站点发生故障时,TM可以将用户请求直接转发到可用站点
所有上述这些服务,是在Azure上面所定义的保证用户服务高可用的服务和策略,都通过软件定义来实现,唯一的目的就是在发生故障的情况下,提供高可用的服务。
上述介绍只是微软的Azure超规模数据中心的一部分,限于篇幅关系,无法详述,感兴趣的同学可到上述链接自行学习修炼~
公有云的服务越来越普遍,已经成为IT的"新常态",用户在做业务转型或者开发新服务的时候,其实从速度,灵活和经济效益来讲,可以更多的考虑公有云服务,使用具有SLA保障的久经考验的云服务,将主要的精力放在业务创新,行业颠覆上,而不是IT基础建设上,毕竟对于大部分用户而言,IT并非其核心业务。
转载于:https://my.oschina.net/stevenL/blog/615183
标签:Datacenter,数据中心,Hyper,服务,微软,PUE,基础架构,Azure,服务器 来源: https://blog.csdn.net/chiliang1877/article/details/100796870