分享: 利用Readability解决网页正文提取问题
作者:互联网
原文链接:http://www.cnblogs.com/iamzyf/p/3529740.html
做数据抓取和分析的各位亲们, 有没有遇到下面的难题呢?
- 如何从各式各样的网页中提取正文!?
虽然可以用SS为各种网站写脚本做解析, 但是互联网各类网站何止千万种, 纵使累死我们也是做不完的. 这里我给大家热情推荐使用Readability来彻底解决这个难题 (呵呵, 不是做广告, 真心热爱这个好东东)
Raedability网站(www.readability.com)最引以为傲的就是其强大的解析引擎, 号称世界上最强大的文本解析神器. Safari中的"阅读器"功能就是用它来实现的! 他们还提供了API可以调用解析器的功能, 而我做了一个c#的代理类来方便大家使用.
开始之前请大家自行注册readability并申请appkey, 免费的.
代理类代码:
public static class ReadabilityProxy
{
public static Article Parse(string url, string token) //token就是各位的appkey
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
var encUrl = HttpUtility.UrlEncode(url);
Uri u = new Uri(string.Format("https://readability.com/api/content/v1/parser?url={0}&token={1}", encUrl, token));
var json = wc.DownloadString(u);
JavaScriptSerializer se = new JavaScriptSerializer();
return se.Deserialize(json, typeof(Article)) as Article;
}
}
public class Article
{
public string Domain;
public string Next_Page_Id;
public string Url;
public string Content;
public string Short_Url;
public string Excerpt;
public string Direction;
public int Word_Count;
public int Total_Pages;
public string Date_Published;
public string Dek;
public string Lead_Image_Url;
public string Title;
public int Rendered_Pages;
public virtual void Decode()
{
this.Excerpt = HttpUtility.HtmlDecode(this.Excerpt);
this.Content = HttpUtility.HtmlDecode(this.Content);
}
}
由于readability返回的Content, Excerpt都是编码过的, 因此我提供了Article.Decode方法来解码.
在ConsoleApp中测试效果:
class Program
{
static void Main(string[] args)
{
var article = ReadabilityProxy.Parse("http://www.mot.gov.cn/st2010/shanghai/sh_zhaobiaoxx/201203/t20120330_1219097.html", "***此处省略n个字***");
article.Decode();
Console.WriteLine(article.Title);
Console.WriteLine(article.Excerpt);
Console.WriteLine(article.Content);
Console.ReadLine();
}
}
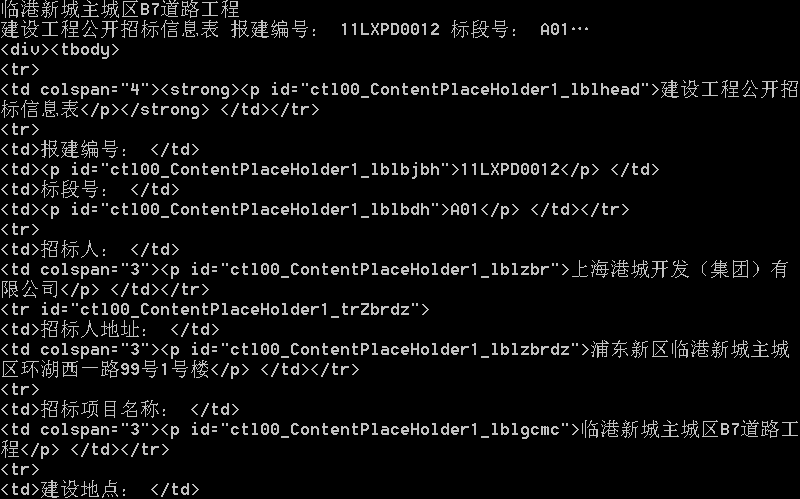
怎么样? 效果不错吧, 赶快试试吧!
转载于:https://www.cnblogs.com/iamzyf/p/3529740.html
标签:网页,string,Excerpt,正文,public,Content,article,Article,Readability 来源: https://blog.csdn.net/weixin_30660027/article/details/97783514