高并发下如何缩短响应时间
作者:互联网
定义
网站响应时间是指系统对请求作出响应的时间。通俗来讲就是我们把网址输入进浏览器然后敲回车键开始一直到浏览器把网站的内容呈现给用户的这段时间。网站响应时间是越短越好,因为网站页面打开速度越快,就意味着我们的用户可以更快的访问站点或者我们的服务器。一般我们网站的响应时间保持在100~1000ms即可。1m=1000ms,打开速度越快对用户体验度越好。据说响应时间还会影响到网站SEO效果(请行业专家留言告诉我)。
响应时间并不能直接反映网站性能的高低,但是在一定程度上反应了网站系统的处理能力,也是给用户最直观上的感受。如果网站的响应时间过长,比如10秒以上,用户的流失率会大大增加,所以把响应时间控制在一定范围内是提高用户体验度的第一要素。
解决方案
当用户请求一个网站数据的时候,实际上是发送了一个http请求,在宏观上可以分为两个部分:
-
1. http请求到达目标网站服务器之前
-
2. http请求到达目标网站服务器之后
如果忽略其中硬件部分和部分细节,请求一个网站数据的大体过程如下图所示(其中CDN和缓存部分可以省略): 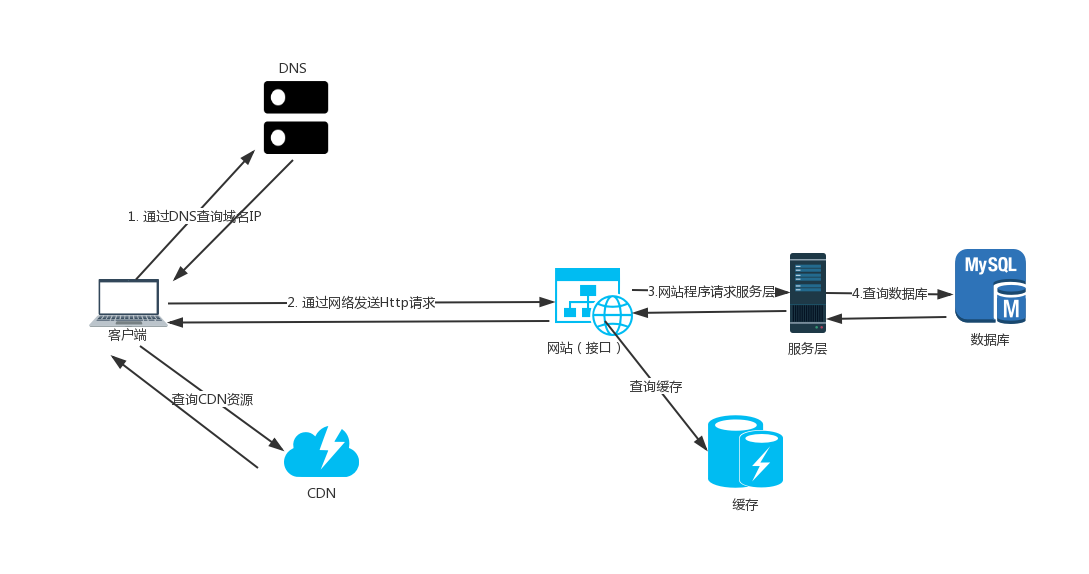
我们要想缩短一个网站的响应时间,本质上是提高数据的返回速度,说的直白一点就是要把请求数据过程中的各个步骤提高速度,这样整体下来响应时间就会缩短。
把数据放在离用户越近的地方响应时间越快
客户端
客户端是发起一个网站请求的源头,其实这个源头可以施加一定的策略来大大缩短某些数据的获取时间。其中最为常用的就是缓存,一些常用的,很少变动的资源缓存在客户端,不但能缩短获取资源的时间,而且在很大程度上能减轻服务端的压力。比如一些图片,css,js文件,甚至一些接口的数据或者整个网页内容都可以在客户端做缓存。另外http请求的合并也可以减少对服务端的请求次数,在一定程度上可以缩短请求的响应时间。
DNS
一般网站的访问方式都采用域名的方式(很少见IP方式),既然是域名就涉及到DNS解析速度的问题,如果DNS服务解析的速度比较慢,整体过程的响应时间也会加长,不过这个过程其实很少出现慢的问题(不是说没有)。
网络
客户端获取到网站IP之后通过网卡把Http请求发送出去,目标地址为相应的网站服务器。在这个过程当中如果客户端和服务器端有一方带宽比较小的话,就会加大响应时间。我司曾经就因为服务器带宽过小导致客户端响应时间很长的情况,当时排查了很长时间才发现。
当然网络是不可靠的,这个过程的响应时间其实取决于很多因素,比如路由器的路由策略是否最优,整个过程通过的网关数据量等。所以有很多网站其实是多地区多机房部署的,目的就是为了让用户通过很短的网络路径就能到达网站(其实这个过程运营商的选择也有影响)。
网站
当一个请求到达网站服务器,服务器便开始处理请求,一般会有专门处理业务请求的一个业务层,有的体现为rpc协议的微服务,有的体现为简单的一个代码分层。最终请求的数据会通过查询数据库来返回。其实这个过程和车站购票流程一样,每个窗口的处理能力是有限的,对应到服务器处理能力。由于这个原因,所以诞生了负载均衡的策略,核心思想就是:分。一台服务器不够,那就两台,三台,四台..... 直到并发的所有请求的响应时间都在可控范围之内。
数据库的情况类似,一个数据库扛不住压力,就加到N个数据库分散压力。一个表扛不住压力,就把这个表拆分开,拆分成多个表,甚至拆分到多个不同服务器数据库,这就是我们常用的拆表策略。有的时候在同一个数据库中进行表拆分,性能的提升并非最大化,因为一台服务器的磁盘IO是有上限的,就算拆成100个表,还是在同一个物理磁盘上,当然这样可缓解锁单表的情况。
现在有很多的场景采用NOsql代替关系型数据库来缩短响应时间,在正常情况下,由于关系型数据库的本身因素在特定场景下的读写速度比Nosql要慢很多,所以系统设计初期,可以考虑采用关系型数据库和Nosql混用的方案。
#include <locale.h>
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <wchar.h>
#include <string.h>
wchar_t* str2wstr(const char const* s) {
const size_t buffer_size = strlen(www.dfyl825.com ) + 1;
wchar_t* dst_wstr = (wchar_t *)malloc(buffer_size * sizeof (wchar_t));
wmemset(dst_wstr, 0, buffer_size);
mbstowcs(dst_wstr, s, buffer_size);
return dst_wstr;
}
void printBytes(const unsigned char const* s, int len) {
for (int i = 0; i < len; i++www.zzhehong.com) {
printf("0x%02x ", *(www.tianscpt.com + i));
}
printf("\n");
}
int main (www.yifa5yl.com) {
char s[10] = "你好"; //内存中对应0xe4 0xbd 0xa0 0xe5 0xa5 0xbd 0x00
wchar_t ws[10] = L"你好"; //内存中对应0x60 0x4f 0x00 0x00 0x7d 0x59 0x00 0x00 0x00 0x00 0x00 0x00
printf("Locale is: %s\n", setlocale(LC_ALL, "zh_CN.UTF-8")); //Locale is: zh_CN.UTF-8
printBytes(s, 7); www.jiaheylw.com //0xe4 0xbd 0xa0 0xe5 0xa5 0xbd 0x00
printBytes((char *)ws, 12); //0x60 0x4f 0x00 0x00 0x7d 0x59 0x00 0x00 0x00 0x00 0x00 0x00
printBytes((char *)str2wstr(s), 12); //0x60 0x4f 0x00 0x00 0x7d 0x59 0x00 0x00 0x00 0x00 0x00 0x00
缓存
当并发的请求到达一定程度,瓶颈大部分情况下发生在DB层面,甚至DB无论怎么优化总有上限。为了避免频繁查询数据库产生瓶颈,诞生了缓存。在访问数据库之前加入了缓存层,当然这里的缓存采用的方案在数据的响应时间上要比数据库小很多,比如常用的redis,Memcache,但是这些第三方的缓存组件还是要走网络,比起进程内的缓存还是要慢的多。
现在一般流行的设计在网站层和服务层都有缓存策略,只不过缓存的数据和策略有所不同,但是最终目的都是为了加快请求的响应。当然加了缓存之后,数据的一致性需要仔细设计才可以,如果发生数据不一致的情况,程序员可能要背锅了。
缓解数据库压力并不是引入缓存的唯一因素。
CDN加速
一些小厂可能用不到cdn,但是cdn带来的加速还是很客观的。cdn依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN就是把离用户最近的数据返回给用户。
写在最后
程序异步化其实并不能缩短响应时间,但是对提高吞吐量有很大作用。
标签:缓存,请求,响应,网站,0x00,并发,缩短,服务器 来源: https://www.cnblogs.com/qwangxiao/p/11150736.html