day007 列表类型、元祖类型、 字典类型、 集合类型的内置方法
作者:互联网
目录
今天的课程主要针对部分数据类型的内置方法进行了讲解,包括列表、元组、字典以及集合。
下面详细对以上提到的几种数据类型进行讲解。
列表数据类型的内置方法
作用
可以使用列表存储多个元素,如兴趣爱好。
列表既可以存数据,也可以取数据。
定义方式
元素之间以,号隔开。元素可以是任意类型的数据。
hobby_list = ['run','read','sleep']优先掌握的方法
- 索引取值(正向取值 + 反向取值)
hobby_list[0]- 切片
hobby_list[:2] # ['run','read']
hobby_list[-2:] # ['read','sleep']
hobby_list[-1:-3:-1] #['sleep','read']- 长度
len(hobby_list)- 成员运算
in或not in
print('run' in hobby_list) # 打印 True,因为'run' 在列表内
print('hh' not in hobby_lst) # 打印 True,“hh”不在列表内,因为使用了 not in,所以为 True- 追加 append
hobby_list.append('swimmng') # 在列表的最后添加一个值- 删除del
# 想要删除指定的元素,将对应元素的索引值传入即可。没有对应的索引时会报错
hobby_list.pop() # 默认删除列表中最后一个元素,默认值为-1
hobby_list.pop(2)
# del 根据索引删除对应的元素,没有对应的索引时会报错
del hobby_list[2]
print(hobby_list)
# remove 删除一个元素,如果不存在则报错
hobby_list.remove('sleep') - 循环
for i in hobby_list:
print(i)需要掌握的方法
insert 在索引的前面插入一个值
hobby_list.insert(1,'shopping')count 获取指定元素的个数
hobby_list.count('run') # 获取‘run’元素在hobby_list列表中出现的次数index 获取指定元素的索引,但是只会获取第一次
# 获取‘run’元素在hobby_list列表中首次出现的位置的索引。 hobby_list.index('run')clear 清空列表
hobby_list.clear() print(hobby_list) # hobby_list列表已经被清空,打印空列表copy 复制(浅拷贝)
如果l2是l1的浅拷贝对象,当l1内的可变元素发生变化时,l2也跟着变化。当l1内的不可变元素发生变化时,l2不变化。
```Python
lis1 = hobby_list.copy() # 浅拷贝
print(lis1)
```
extend 扩展,把extend里的列表的元素添加到原列表中
lis1 = [1,2,3] lis2 = [4,2,3] lis1.extend(lis2) print(lis1) # lis1打印的结果为[1,2,3,4,2,3]reverse 反转列表
hobby_list = ['run','read','sleep'] hobby_list.reverse() print(hobby_list) # 打印结果为 ['sleep','read','run']sort 对列表进行排序
hobby_list.sort() # 排序,需要注意的是,使用sort进行排序的列表的元素必须是同类型的
列表可以存多个值,并且为有序序列。属于可变数据类型,因为它内部的元素变化时,列表的ID地址并没有变,索引它是可变数据类型。
元祖类型的内置方法
作用
类似于列表,可以取数据,但是无法修改数据
定义方式
在()内以,逗号分隔任意类型的元素
优先掌握的方法(参考列表方法)
- 索引取值
- 切片
- 长度
- 成员运算
- for循环
- count
- index
元组可以存多个值,并且按照一定的顺序进行排列,是有序序列。因为元组内部的元素不允许修改,也就不存在可变不可变这一说。
字典类型的内置方法
作用
当存储的数据量太大时,可以使用字典进行存取
定义方式
在{}内以,号分隔key:value形式的元素。key必须具有可描述性,为不可变数据类型,一般为字符串。value可以为任意数据类型的数据。
优先掌握的方法
- 按键取值,可存可取
- 长度
- keys/values/items 去所有的值取出当成列表
# 循环打印所有的keys值
for i in dict.keys:
print(i)
# 循环打印所有的values值
for i in dict.values:
print(i)
# 循环打印所有的键值对
for k,v in dict.items():
print(k,v)
- for 循环
- 成员运算 比较的是key
- del 删除
需要掌握的方法
- fromkeys
默认把给定列表内的元素取出来当成key,然后使用一个默认value新建一个字典
# 新建一个字典,在原字典的基础上根据给出的key和默认值新增元素。如果键已存在,则覆盖key之前的value值。不存在,则新增。
dic1 = {1: 'o', 2: 'or'}
dic2 = dic1.fromkeys([1, 2, 3], '默认值')
print(dic2)
- get 如果键不存在,返回None,不会报错;如果键不存在,可以给定默认值
dic1 = {1: 'o', 2: 'or'}
dic1.get(3) #
update 有就更新,没有则添加
dic1 = {1: 'o', 2: 'or'} dic1.update({1:'t',3:'k'}) print(dic1)setdefault 如果字典中有该key的话,则key对应的值不变;如果没有,则增加
kingzong_info_dict.setdefault('a', 'b')
kingzong_info_dict.setdefault('height', 'b')
print(kingzong_info_dict)
print('*' * 50)
当我们需要存储大量数据的时候,优先使用字典类型进行存储。字典类型可以存多个值。
字典是通过键key取值,没有索引,所以字典属于无序序列。
字典属于可变数据类型,当字典含有的键值对中的值变化时,字典的内存地址不变。
集合类型内置方法
首先集合类型是可以存储多个值的,为了集合之间做运算(如求交集、并集、差集等等)
定义方式
我们一般定义集合类型是使用下面两种方式
s = set()
s = {1,2,3}
# 不能使用下面的方式,这是表示空字典
s = {}
优先掌握的方法
- 去重
去重的同时,打乱了列表元素原有的顺序
- 并集 |
- 交集 &
- 差集 -
- 对称差集 ^
- 父集
>和>= - 子集
<和<= - ==
需要掌握的方法
add 添加元素
difference_update
pythoner = {'fanping', 'wangdapao', 'wangwu', 'zhaoliu', 'zhangsan', 'wangba'} linuxer = {'ruiixng', 'lisi', 'wangba', 'wangdapao'} pythoner.difference_update(linuxer) print(pythoner) print('*' * 50)isdisjoint
print(pythoner.isdisjoint(linuxer)) print('*' * 50)remove #移除,值不存在会报错
discard #删除,值不存在不会报错
集合类型可以存多个值。当定义一个集合时,其内部的元素是无序排列的。集合类型可以存储任意类型的元素,当元素发生变化时,集合的内存地址不变,即集合为可变数据类型。
布尔类型
作用
一般用于逻辑判断,除了0、None、空和False自带布尔值False外,其他的数据类型自带布尔值为True。
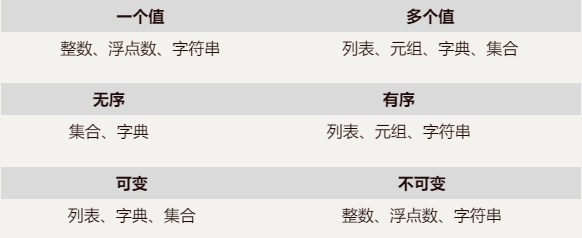
数据类型总结
可变、不可变的判断方式:
值变ID不变的数据类型为可变数据类型
值变ID也变的数据类型为不可变数据类型
知识拓展
- 拷贝、浅拷贝、深拷贝都是针对可变数据类型而言
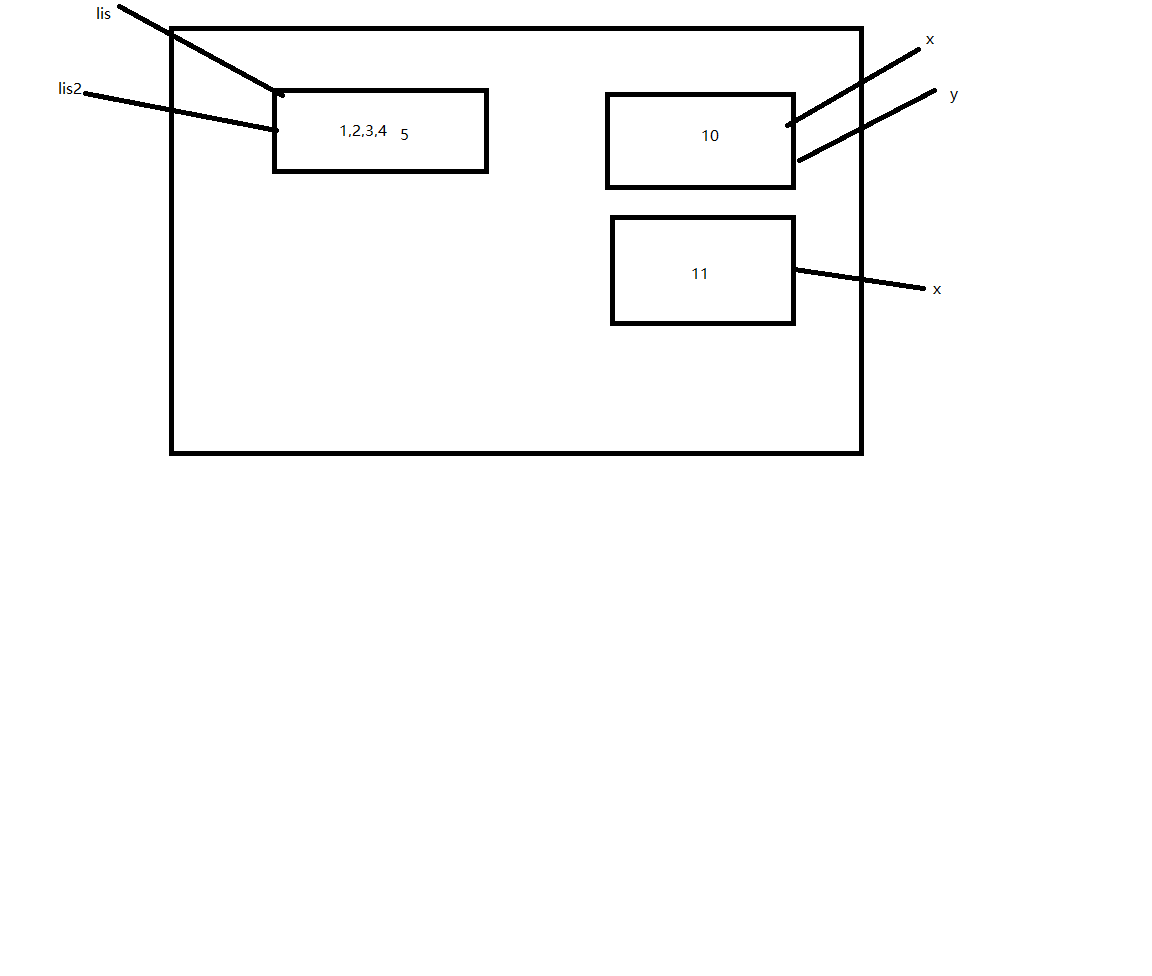
l1 = ['a','b','c',['d','e','f']]
l2 = l1
l1.append('g')
print(l1) # ['a','b','c',['d','e','f'],'g']
print(l2) # ['a','b','c',['d','e','f'],'g']
拷贝
我们一般的赋值操作都是这个拷贝
总结:如果l2是l1的拷贝对象,当l1内部的任何数据类型的元素变化时,l2内部的元素也随之变化。因为可变类型值变ID不变
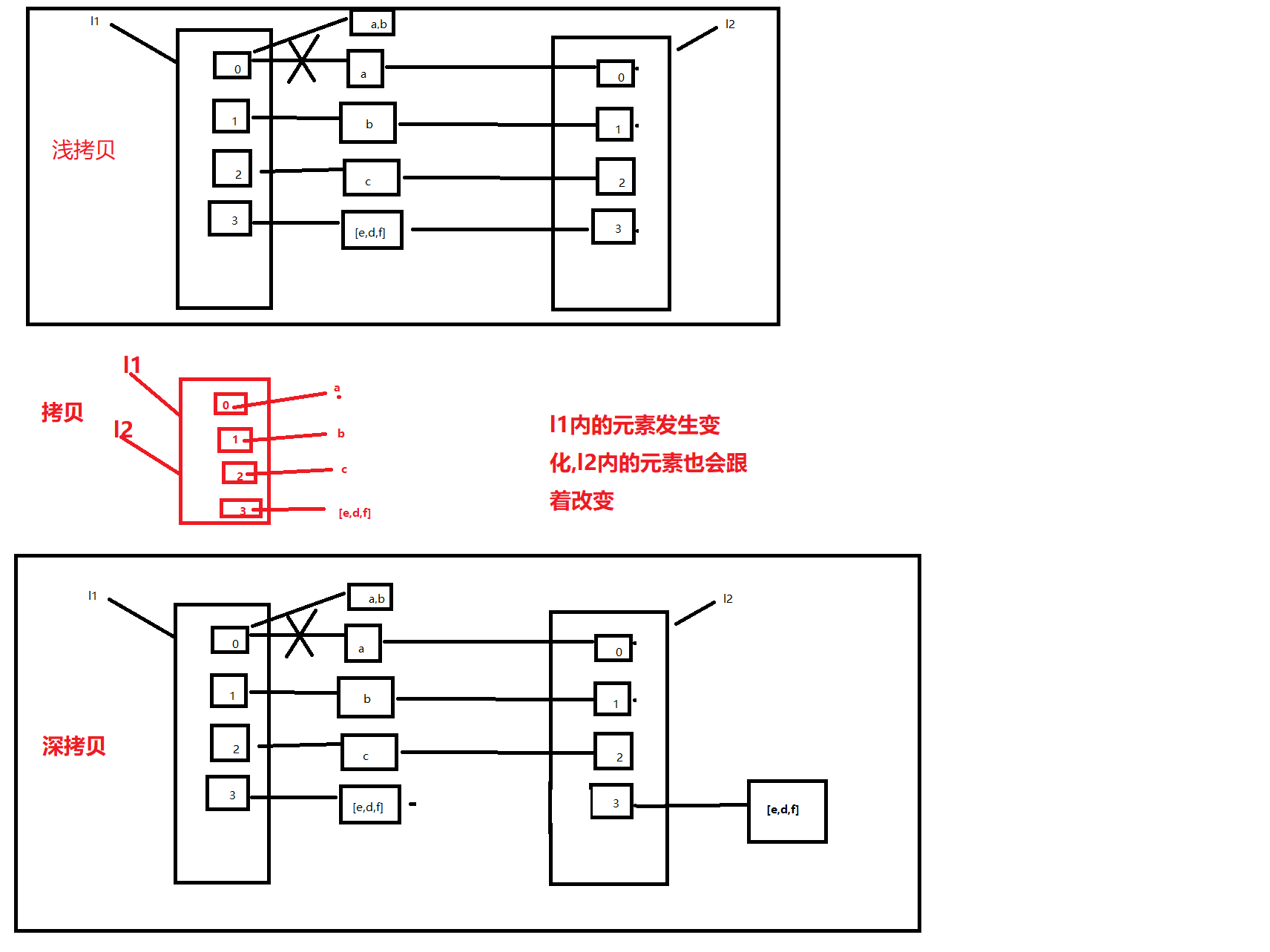
浅拷贝
需要使用copy模块
import copy
l1 = ['a','b','c',['d','e','f']]
l2 = copy.copy()
l1.append('g')
print(l1) # ['a','b','c',['d','e','f'],'g']
print(l2) # ['a','b','c',['d','e','f']]
l1[3].append('g')
print(l1) # ['a','b','c',['d','e','f','g'],'g']
print(l2) # ['a','b','c',['d','e','f','g']]
总结:如果l2是l1的浅拷贝对象,则l1内的不可变元素发生改变,l2不变。如果l1内的可变元素发生变化时,则l2也跟着改变。
深拷贝
import copy
l1 = ['a','b','c',['d','e','f']]
l2 = copy.deepcopy(l1)
l1.append('g')
print(l1) # ['a','b','c',['d','e','f'],'g']
print(l2) # ['a','b','c',['d','e','f']]
l1[3].append('g')
print(l1) # ['a','b','c',['d','e','f','g'],'g']
print(l2) # ['a','b','c',['d','e','f']]
总结:如果l2是l1的深拷贝对象,则当l1内的不可变元素发生变化时,l2不变;当l1内的可变元素发生变化时,l2不变。即l2永远不会因为l1的变化而发生变化
附图(灵魂画师提供)
拷贝示意图
浅拷贝示意图

深拷贝

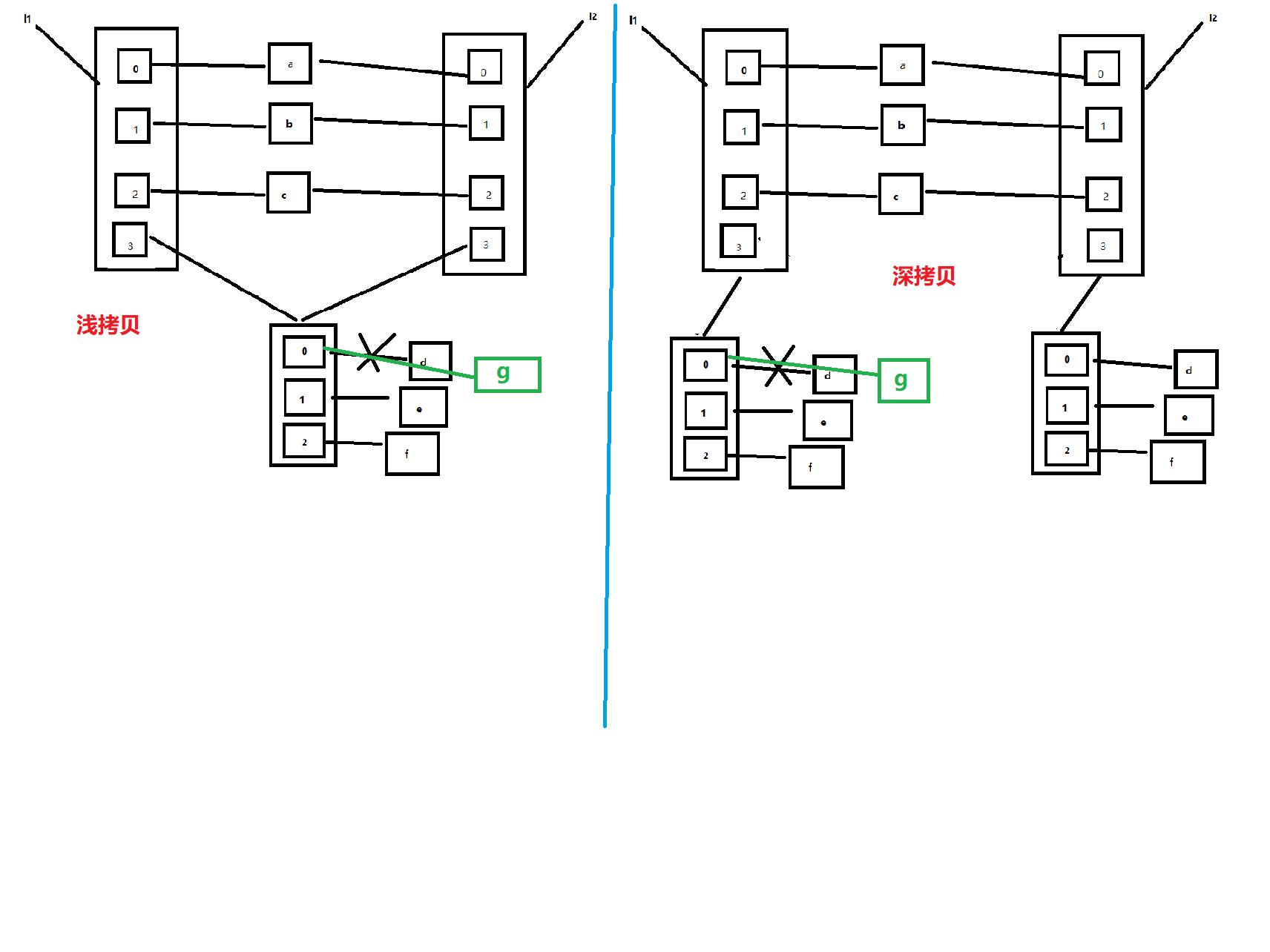
三者合一
至尊无敌超级VIP联合版
标签:list,列表,print,l2,l1,类型,hobby,day007,元祖 来源: https://www.cnblogs.com/chenych/p/10921887.html