nDCG——搜索评价指标
作者:互联网
nDCG - 搜索评价指标
原文地址: https://en.wikipedia.org/wiki/Discounted_cumulative_gain
Discounted cumulative gain(DCG, 累计折损增益)是一种排序质量的衡量标准。
在信息检索中,通常用来测量网页搜索引擎算法的有效性。
DCG对搜索结果集中的每个文档指定一个分级的相关性刻度(例如:好/中等/坏),
然后根据文档的相关性刻度和它在结果集中的位置来计算它的增益。
结果集中所有文档的增益都被累加,但是排序靠后的文档增益在累加时会有折扣。
DCG的2个假设:
- 对于高相关度的文档,出现越靠前则越有用(指标的值越大)
- 高相关度的文档比中等相关度的文档更有用,而中等相关度的文档比不相关的文档更有用。
CG - 累计增益
CG只考虑文档的相关性,不考虑文档所处的位置,计算公式为:
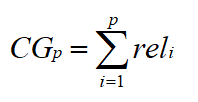
其中 reli 为位置i上的文档的相关度。
从CG的计算公式可以看出,前p个文档的位置如果发生了变化,CG的值并不会改变。
DCG - 累计折损增益
DCG在CG的基础上增加了对文档位置的考虑。计算公式为:
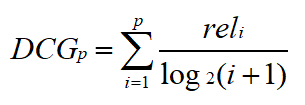
位置越靠后的文档,增益的折损越大。
Normalized DCG - 归一化累计折损增益
对于不同的query,搜索结果集的长度可能不同。因此,
使用DCG来比较不同Query的排序质量并不合适,需要进行归一化。
归一化过程:
将结果集中的所有文档按相关度降序排列,取相关度最高的p个文档,计算出DCG,
也叫位置p上的 理想化的DCG (IDCG)
nDCG计算公式:
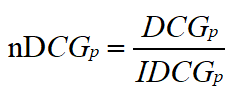
IDCG计算公式:

|REL|表示结果集中相关度最高的p个文档(按相关度降序排列)
对所有query的nDCG值计算一个平均值,可以得到一个排序算法的平均排序质量。
对于一个完美的排序算法, DCGp会等于IDCGp,这样计算出来的
nDCG值为1。所有的nDCG值落在[0,1]区间内,这样就可以对不同query的排序质量进行比较。
计算nDCG时最困难的地方在于:当只能获取结果集中的部分文档时,无法得到理想化的排序结果。
一个简单的例子
假设对于一个query,搜索结果的前6个为 (D1, D2, D3, D4, D5, D6)。
让一个经验丰富的人来判断每个文档的相关度并打分:
- 0:不相关
- 3:高度相关
- 1,2:介于0,3之间,中度相关。
打分的结果如下:
D1 : 3
D2 : 2
D3 : 3
D4 : 0
D5 : 1
D6 : 2
计算CG
CG6 = 3 + 2 +3 + 0 + 1 + 2 = 11, 任意调换2个文档的位置都不会影响CG的值。
计算DCG
| i | reli | log2(i+1) | reli / log2(i+1) |
|---|---|---|---|
| 1 | 3 | 1 | 3 |
| 2 | 2 | 1.585 | 1.262 |
| 3 | 3 | 2 | 1.5 |
| 4 | 0 | 2.322 | 0 |
| 5 | 1 | 2.585 | 0.387 |
| 6 | 2 | 2.807 | 0.712 |
DCG6 = 3 + 1.262 + 1.5 + 0 + 0.387 + 0.712 = 6.861
此时,如果交换D3和D4的位置,会导致DCG值的减少。
计算nDCG
假设结果集中还有2个文档:
D7 : 3
D8 : 2
则理想化的排序结果如下:
3, 3, 3, 2, 2, 2, 1, 0
IDCG6 = 8.740
nDCG6 = DCG6 ÷ IDCG6 = 6.861 ÷ 8.740 = 0.785
标签:搜索,相关度,DCG,CG,增益,文档,nDCG,评价 来源: https://blog.csdn.net/zx2011302580235/article/details/89714466