什么是机器学习中的回归算法?scikit-learn中的四大回归算法学习
作者:互联网
回归是一种稳健的统计测量,用于研究一个或多个独立(输入特征)变量和一个因变量(输出)之间的关系。在 AI 中,回归是一种有监督的机器学习算法,可以预测连续的数值。简而言之,来自数据集的输入特征被输入机器学习回归算法,预测输出值。
在这篇文章中,我们将分享一个包含重要回归技术的机器学习算法列表,并讨论如何使用 scikit-learn 库实现监督回归。
1. 线性回归
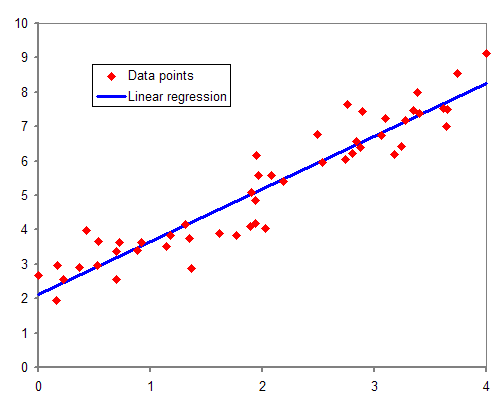
线性回归是一种机器学习算法,它通过估计线性方程的系数来确定一个或多个自变量与单个因变量之间的线性关系,以预测因变量的最合适值。
以下直线方程定义了一个简单的线性回归模型,该模型估计因变量 (y) 和自变量 (x) 之间的最佳拟合线性线。
y=mx+c+e
回归系数 (m) 表示我们期望 y 随着 x 增加或减少而变化的程度。回归模型找到截距 (c) 和回归系数 (m) 的最佳值,以使误差 (e) 最小化。
在机器学习中,我们使用普通最小二乘法,这是一种线性回归,可以通过最小化 y 的实际值与 y 的预测值之间的误差来处理多个输入变量。
以下代码片段使用 scikit-learn库实现线性回归:
# Import libraries
import numpy as np
from sklearn.linear_model import LinearRegression
# Prepare input data
# X represents independent variables
X = np.array([[1, 1], [1, 2], [1, 3], [2, 1], [2, 2], [2, 3]])
# Regression equation: y = 1 * x_0 + 2 * x_1 + 3
# y represents dependant variable
y = np.dot(X, np.array([1, 2])) + 3
# array([ 6, 8, 10, 7, 9, 11])
reg = LinearRegression().fit(X, y)
reg.score(X, y)
# Regression coefficients
reg.coef_
# array([1., 2.])
reg.intercept_
# 2.999999999999999
reg.predict(np.array([[4, 4]]))
# array([15.])
reg.predict(np.array([[6, 7]]))
array([23.])
2. Lasso回归——最小绝对收缩和选择算子
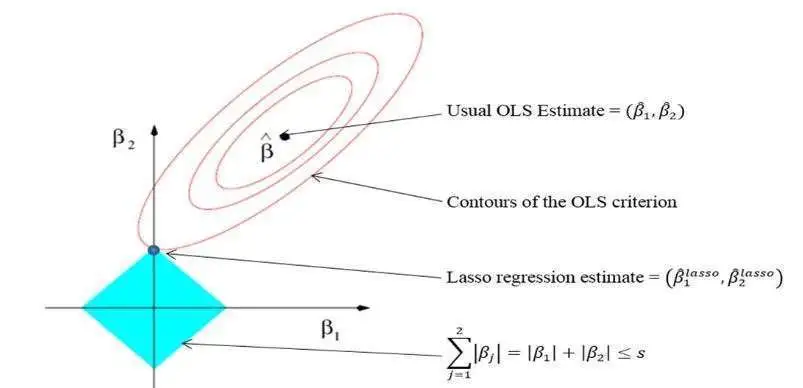
线性回归会高估回归系数,从而增加机器学习模型的复杂性。模型变得不稳定、庞大并且对输入变量非常敏感。
LASSO 回归是线性回归的扩展,它在模型训练期间向损失函数添加惩罚(L1)以限制(或缩小)回归系数的值。此过程称为 L1 正则化。
L1 正则化缩小了对预测任务没有显着贡献的输入特征的回归系数值。它将这些系数的值降为零,并从回归方程中删除相应的输入变量,从而鼓励使用更简单的回归模型。
以下代码片段显示了scikit-learn如何在 Python 中实现套索回归。在 scikit-learn 中,L1 惩罚是通过改变alpha超参数(机器学习中的可调参数,可以提高模型性能)的值来控制的。
# Import library
from sklearn import linear_model
# Building lasso regression model with hyperparameter alpha = 0.1
clf = linear_model.Lasso(alpha=0.1)
# Prepare input data
X = np.array([[1, 1], [1, 2], [1, 3], [2, 1], [2, 2], [2, 3]])
y = [ 6, 8, 10, 7, 9, 11]
clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2])
# Regression coefficients
clf.coef_
# array([0.6 , 1.85])
clf.intercept_
# 3.8999999999999995
clf.predict(np.array([[4, 4]]))
# array([13.7])
clf.predict(np.array([[6, 7]]))
# array([20.45])
3.岭回归算法
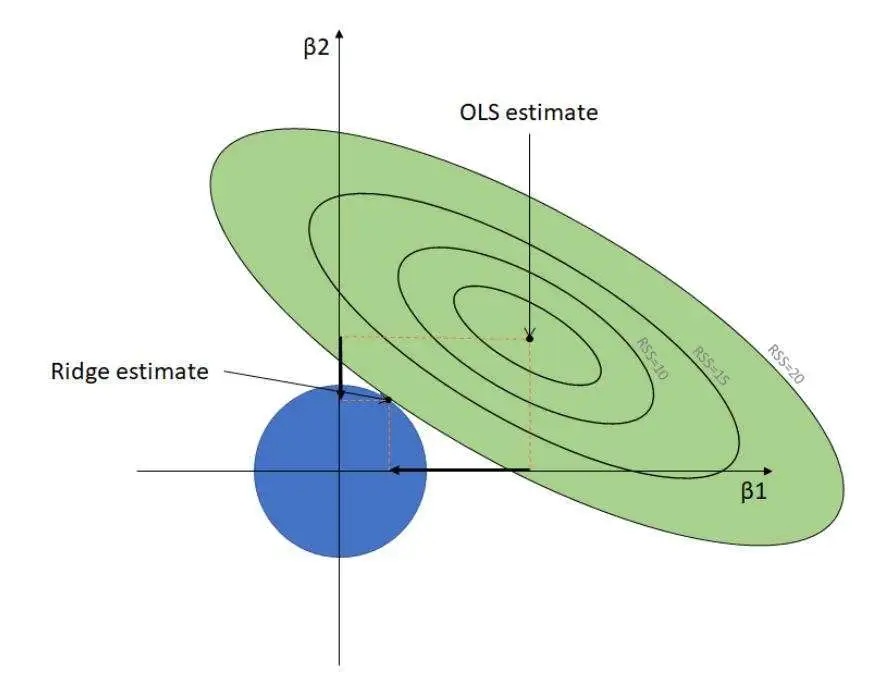
岭回归是另一种正则化机器学习算法,它在模型训练阶段向损失函数添加 L2 正则化惩罚。与套索一样,岭回归也最大限度地减少了多重共线性,当多个独立变量彼此显示出高度相关性时,就会发生这种情况。
L2 正则化通过最小化此类自变量的影响来处理多重共线性,将相应回归系数的值降低到接近于零。与 L1 正则化不同,它防止完全删除任何变量。
以下代码片段使用 scikit-learn 库实现岭回归。在 scikit-learn 中,L2 惩罚由alpha超参数加权。
# Import library
from sklearn.linear_model import Ridge
# Building ridge regression model with hyperparameter alpha = 0.1
clf = Ridge(alpha=0.1)
# Prepare input data
X = np.array([[1, 1], [1, 2], [1, 3], [2, 1], [2, 2], [2, 3]])
y = [ 6, 8, 10, 7, 9, 11]
clf.fit(X, y)
clf.coef_
# array([0.9375, 1.95121951])
clf.intercept_
# 3.1913109756097553
clf.predict(np.array([[4, 4]]))
# array([14.74618902])
clf.predict(np.array([[6, 7]]))
# array([22.47484756])
4. 弹性网络回归算法
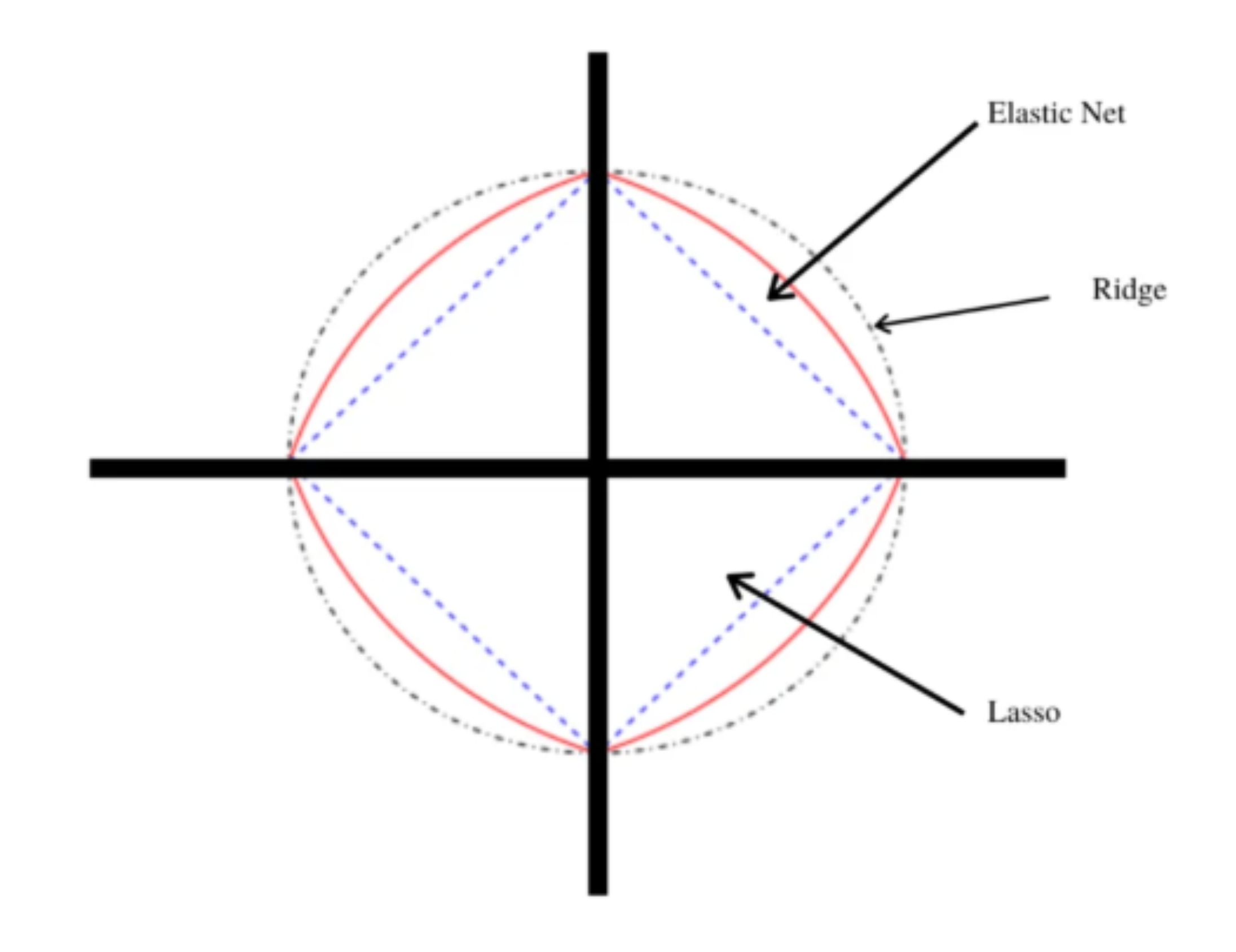 弹性网络回归是一种正则化线性回归算法,在训练过程中将 L1 和 L2 惩罚项线性组合并添加到损失函数中。它通过为每个惩罚分配适当的权重来平衡套索回归和岭回归,从而提高模型性能。
弹性网络回归是一种正则化线性回归算法,在训练过程中将 L1 和 L2 惩罚项线性组合并添加到损失函数中。它通过为每个惩罚分配适当的权重来平衡套索回归和岭回归,从而提高模型性能。
Elastic net 有两个可调超参数,即 alpha 和 lambda。Alpha 确定赋予每个惩罚的权重百分比,而 lambda 控制对模型性能有贡献的两种负债的加权和的百分比。
以下代码片段演示了使用 scikit-learn 的弹性网络回归:
# Import library
from sklearn.linear_model import ElasticNet
# Building elastic net regression model with hyperparameter alpha = 0.1
regr = ElasticNet(alpha=0.1)
# Prepare input data
X = np.array([[1, 1], [1, 2], [1, 3], [2, 1], [2, 2], [2, 3]])
y = [ 6, 8, 10, 7, 9, 11]
regr.fit(X, y)
regr.coef_
# array([0.66666667, 1.79069767])
regr.intercept_)
# 3.9186046511627914
regr.predict([[4, 4]])
# array([13.74806202])
regr.predict([[0, 0]])
# array([20.45348837])
回归可以处理线性依赖
回归是一种用于预测数值的稳健技术。上面提供的机器学习算法列表包含强大的回归算法,可以使用 scikit-learn Python 库对各种机器学习任务进行回归分析和预测。