熊猫 - 数据处理和分析
作者:互联网
介绍
Python的Pandas包用于操作数据收集。它提供了用于数据探索、清理、分析和操作的工具。Wes McKinney在2008年提出了“Pandas”这个名字,它指的是“面板数据”和“Python Data Analysis”。
如何安装熊猫
要安装 Pandas,首先,请确保系统中已安装 Python 和 Pip。如果已安装,则只需在命令行上运行此命令即可安装Pandas。
>> pip install pandas
您可以使用其他 Python 发行版,如 Spyder 或 Anaconda,其中已经安装了 pandas。
使用 Pandas 编写您的第一段代码

要在代码中使用 Pandas,首先,我们必须导入它。在这里,我们将熊猫导入为 .此处为 的别名。pdpdpanda
系列
熊猫中的序列就像表中的一列,可以像任何类型的一维数组一样保存数据。要创建一个熊猫系列,我们可以编写以下代码:
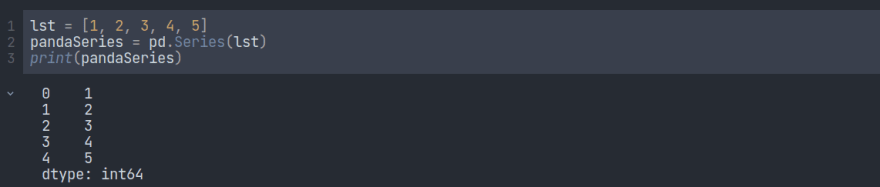
在这里,我们使用了一个名为将列表转换为系列的方法。之后,我们可以使用功能打印系列。如果我们观察输出,我们将看到有 5 行和 2 列。最后,它显示了列表中已转换为系列的元素的数据类型。第一列是标签列。如果未指定任何其他值,则使用其索引号标记值。第一个值具有索引 0,第二个值具有索引 1,依此类推。此标签可用于访问指定的值。Series()print()

现在,很明显,我们可以将标签用作索引,并使用它访问特定值。有趣的是,我们可以使用参数命名自己的标签。index

创建标签后,我们可以通过引用标签来访问项目,就像我们使用键访问字典值一样:

键/值对象作为系列
您还可以在创建序列时使用键值对象,如字典。
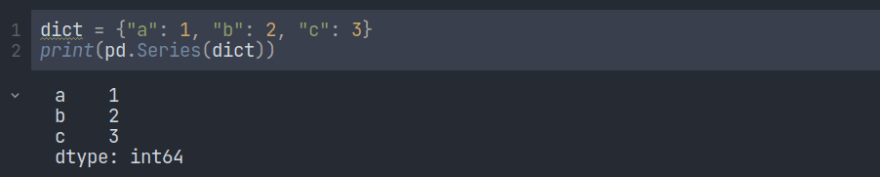
使用 index 选项仅指定您希望包含在系列中的单词,而忽略字典中的其余单词。

现在让我们看看当我们添加两个系列时会发生什么。
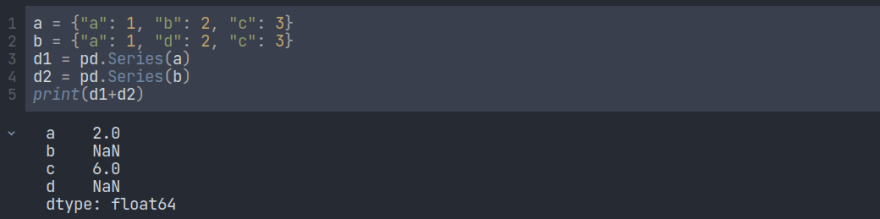
它通过将相同的标记数据添加到一起并将它们转换为浮点数来创建新系列。如果缺少相同的索引,则输出将为 。NaN
数据帧
Pandas 数据帧是一种二维数据结构,类似于二维数组或包含行和列的表。为了更好地理解它,首先,让我们将其与熊猫系列进行比较。
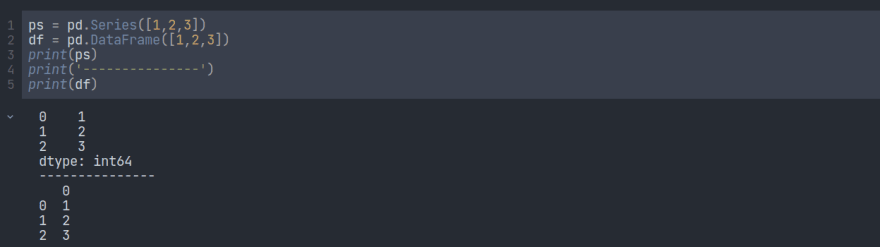
这里的第一个明显区别是序列具有特定的数据类型,但数据框没有。
字典和数据框

这里我们可以看到字典的键是列的标题,列表是列的数据。现在,这里发生的事情是,我们正在传递一个列表,它正在创建一个数据框。它还自行定义其索引和列名称。如果我们想使用我们自己的名称作为索引或列名,我们必须通过方法将其作为参数传递。DataFrame()
生成数据框

在上面的示例中,我们传递了一个 2D 数组、索引和列名。之后,该方法会自动分配索引和列名。DataFrame()
选择和索引
首先,数据帧列只是系列:

现在,让我们学习从数据帧中获取数据的各种方法

我们可以使用列名称抓取任何列。要访问多个列,我们必须传递如下列名称列表:
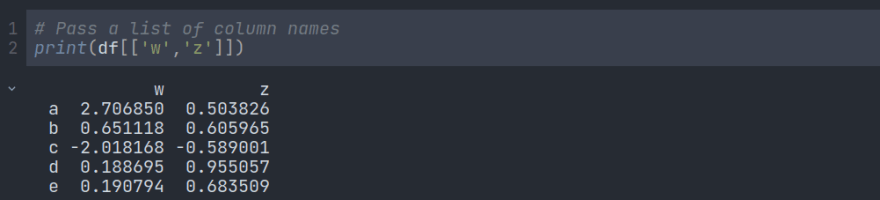
我们也可以使用SQL语法,但不建议这样做,因为它会造成混淆:
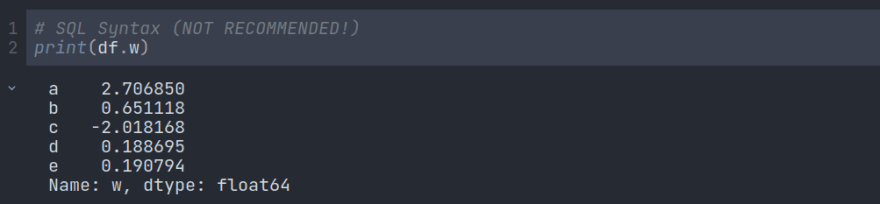
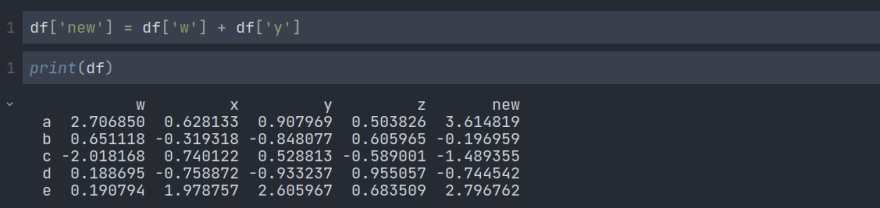
创建新列:
我们可以向数据帧添加一个新列,如下所示。我们可以分配数组或系列来定义新列。在下面的示例中,我们添加了两列,它们基本上是两个系列,并分配一个名为 :‘new’
删除列
我们必须使用方法来删除列或行。这里的意思是行,意思是列。如果我们想删除该列,我们必须提及它。默认值为 。.drop()axis=0axis=10
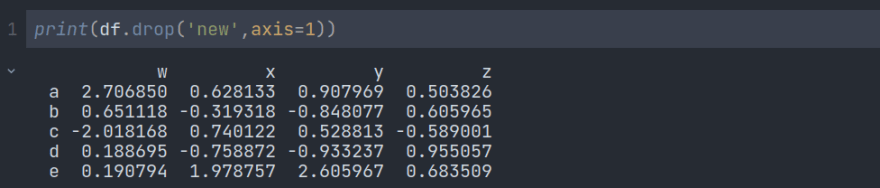
但是有一个问题。如果我们尝试再次打印,我们将看到该列仍然存在。