004-GoingDeeperConvolutions2014(googLeNet)
作者:互联网
Going Deeper with Convolutions #paper
1. paper-info
1.1 Metadata
- Author:: [[Christian Szegedy]], [[Wei Liu]], [[Yangqing Jia]], [[Pierre Sermanet]], [[Scott Reed]], [[Dragomir Anguelov]], [[Dumitru Erhan]], [[Vincent Vanhoucke]], [[Andrew Rabinovich]]
- 作者机构::
- Keywords:: #DeepLearning , #GoogLeNet
- Journal:: -
- Date:: [[2014-09-16]]
- 状态:: #Doing
- 链接: PDF
1.2 Abstract
We propose a deep convolutional neural network architecture codenamed Inception, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
设计了一个更宽更深的网络,设计原则符合Hebbian principle和多尺度处理原则。在2014的ImageNet比赛上取得了第一的好成绩。(分类和探测)
https://zh.m.wikipedia.org/zh-my/赫布理论
Hebbian principle
1.3 Introduction
GoogLeNet在分类和目标检测中都取得了重大的突破;并且算法复杂度和计算机资源利用率上都取得了重要的成功。最重要的一点,该算法由于优秀的性能,能够很好的部署到端设备中,方便使用。
提出了一种新的网络结构,命名为Inception,改名字来源于Network in network 和盗梦空间的台词we need to go deeper。

图 1-1 表情包
1.4 Motivation
增加网络深度最容易的方法就是增加网络层数,但这容易带来过拟合和计算量过大的问题。解决问题的方法是从完全连接的架构转向稀疏连接的架构,即使在卷积内部也是如此。
The fundamental way of solving both issues would be by ultimately moving from fully connected to sparsely connected architectures, even inside the convolutions.
但是这种稀疏结构模型对计算机来说计算并不高效。
Also, non-uniform sparse models require more sophisticated engineering and computing infrastructure.
并且卷积是由密集连接的集合来实现的。
Inception 架构最初是作为第一作者的案例研究开始的,用于评估复杂网络拓扑构建算法的假设输出,该算法试图近似稀疏结构,并通过密集的,可读的可用组件覆盖假设的结果。
The Inception architecture started out as a case study of the first author for assessing the hypothetical output of a sophisticated network topology construction algorithm that tries to approximate a sparse structure implied by [2] for vision networks and covering the hypothesized outcome by dense, readily available components.
换句话说就是,Inception model 既可以满足构建稀疏连接的架构,又能够满足卷积在计算机上的密集计算。(全都要)
2. Architecture
Inception架构的主要思想是找出卷积视觉网络中的最佳局部稀疏结构,并近似由现成的密集组件替代。
所以提出了一种更wider的网络架构Inception module
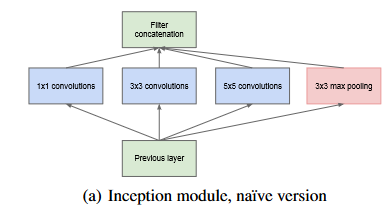
图 2-1 the naive version
由于这些Inception module彼此堆叠在一起,他们的输出相关性统计数据必然也会有所不同:随着更高抽象的特征被高层捕捉,他们的空间集中度预计将会降低,这表明3x3.5x5卷积的比率应该随着层数的增加而增加。
As these “Inception modules” are stacked on top of each other, their output correlation statistics are bound to vary: as features of higher abstraction are captured by higher layers, their spatial concentration is expected to decrease suggesting that the ratio of 3×3 and 5×5 convolutions should increase as we move to higher layers.
最初的模型有一个问题就是:即使是 5×5 卷积也会导致在计算方面需要大量资源。一旦添加池化,这个问题就会更多地出现。
解决办法就是:明智地运用维度缩减和投影。
This leads to the second idea of the proposed architecture: judiciously applying dimension reductions and projections wherever the computational requirements would increase too much otherwise.
为了解决这种问题,在3x3,5x5卷积的前面添加了1x1卷积。模型结构改进后如图 2-2
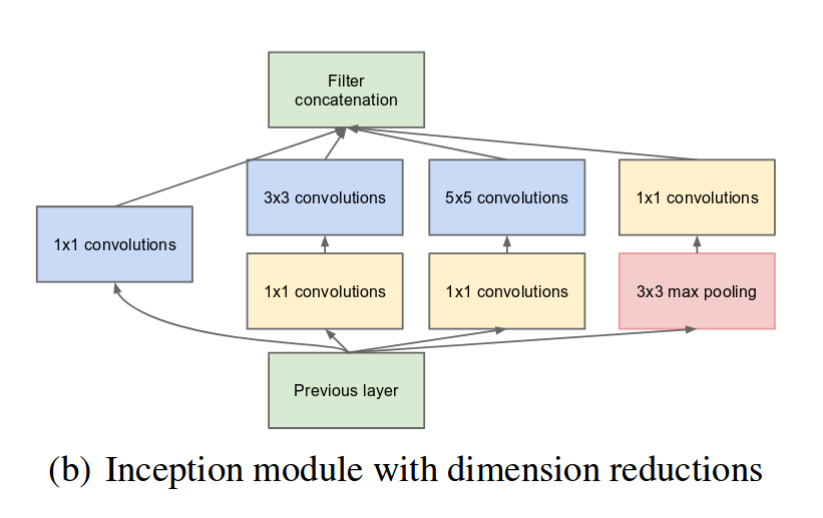
图 2-2 Inception module with dimension reductions
Inception网络就由上述类型的模块堆叠而成,偶尔会加入最大池化层,步幅为2。
而且由于设备处理效率低下,最好是将Inception module放在网络的higher layer,前面由传统的卷积神经网络替代。
Inception module的优点:允许显著增加每个阶段的单元数量,而不会产生参数爆炸的问题。并且由于是多卷积堆叠,抽取的特征是来自不同的尺度。
3. GoogLeNet
该名字是为了致敬 LeNet。
GoogLeNet 由 22 层深度网络(包括池化层的 27 层)组成。所有的卷积,包括 inception 模块内部的卷积,都使用ReLU激活函数。
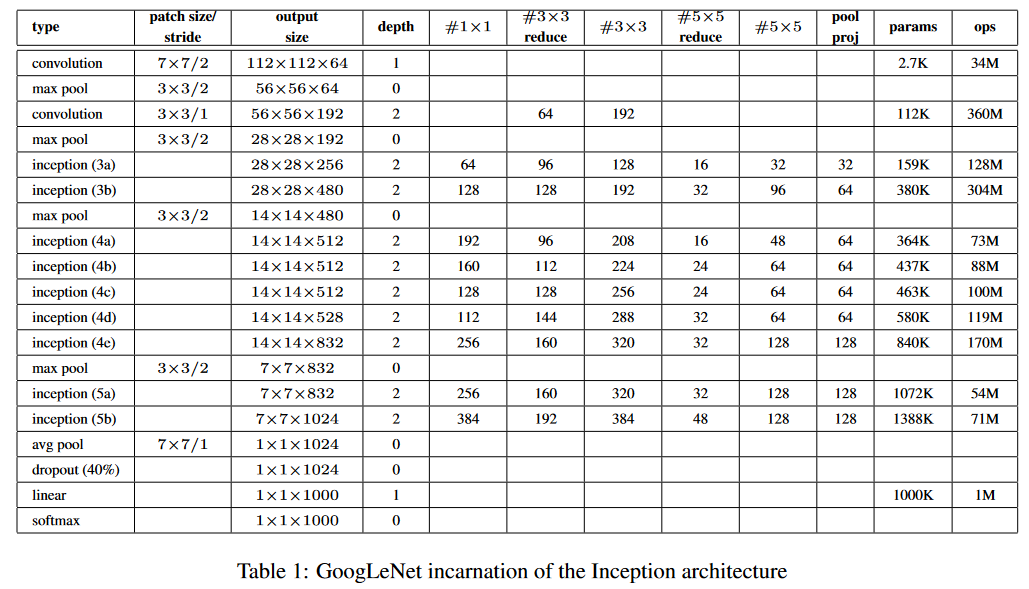
图 3-1 GoogLeNet 配置图
GoogLeNet 是一个 22 层的深度,只计算带有参数的层。使用如此深的网络,可能会出现诸如梯度消失之类的问题。为了消除这种情况,作者引入了连接到中间层的辅助分类器,并帮助梯度信号向后传播。这些辅助分类器添加在Inception (4a) 和 (4d)模块的输出之上。辅助分类器的损失在训练期间被添加并在推理期间被丢弃。
边上额外网络的确切结构,包括辅助分类器,配置如下:

图 3-2 辅助分类器配置
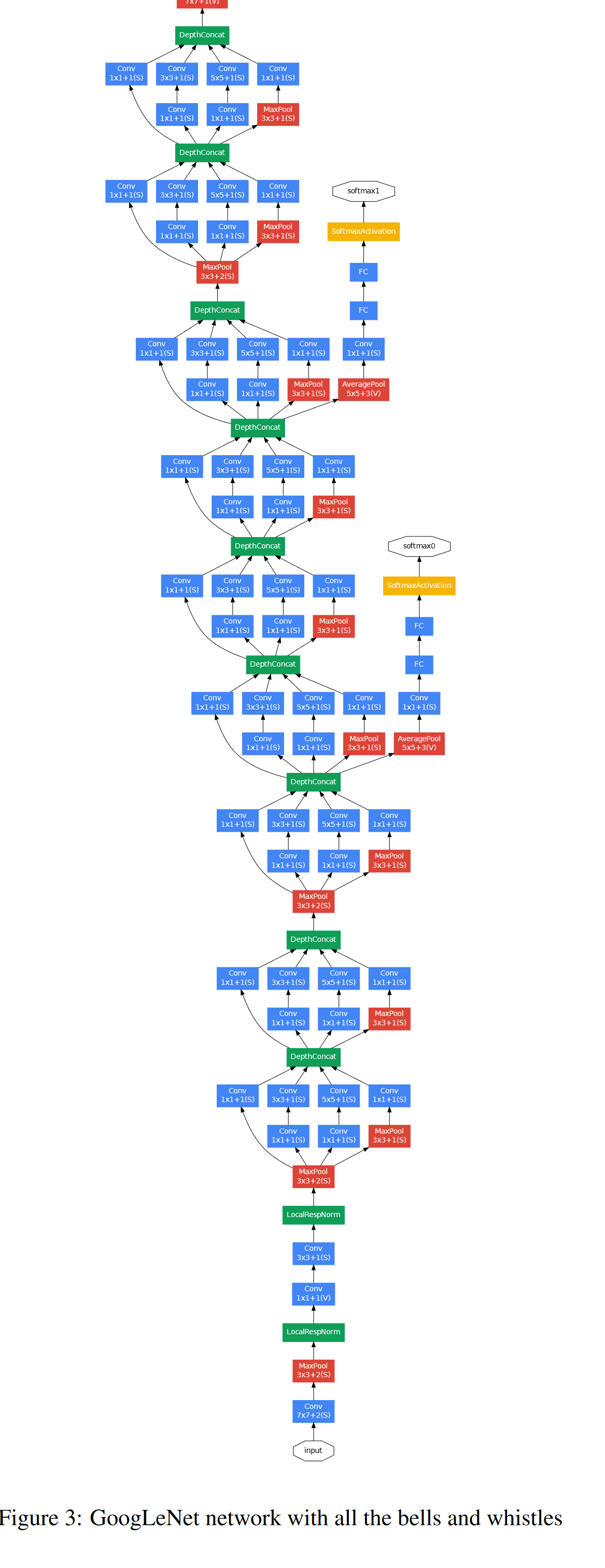
图 3-3 GoogLeNet
4. 代码实现
import torch
import torch.nn as nn
class Inception(nn.Module):
def __init__(self, input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj):
super().__init__()
#1x1conv branch
self.b1 = nn.Sequential(
nn.Conv2d(input_channels, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(inplace=True)
)
#1x1conv -> 3x3conv branch
self.b2 = nn.Sequential(
nn.Conv2d(input_channels, n3x3_reduce, kernel_size=1),
nn.BatchNorm2d(n3x3_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n3x3_reduce, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(inplace=True)
)
#1x1conv -> 5x5conv branch
#we use 2 3x3 conv filters stacked instead
#of 1 5x5 filters to obtain the same receptive
#field with fewer parameters
self.b3 = nn.Sequential(
nn.Conv2d(input_channels, n5x5_reduce, kernel_size=1),
nn.BatchNorm2d(n5x5_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5_reduce, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5, n5x5),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(inplace=True)
)
#3x3pooling -> 1x1conv
#same conv
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(input_channels, pool_proj, kernel_size=1),
nn.BatchNorm2d(pool_proj),
nn.ReLU(inplace=True)
)
def forward(self, x):
return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], dim=1)
class GoogleNet(nn.Module):
def __init__(self, num_class=100):
super().__init__()
self.prelayer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 192, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(192),
nn.ReLU(inplace=True),
)
#although we only use 1 conv layer as prelayer,
#we still use name a3, b3.......
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
##"""In general, an Inception network is a network consisting of
##modules of the above type stacked upon each other, with occasional
##max-pooling layers with stride 2 to halve the resolution of the
##grid"""
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
#input feature size: 8*8*1024
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout2d(p=0.4)
self.linear = nn.Linear(1024, num_class)
def forward(self, x):
x = self.prelayer(x)
x = self.maxpool(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool(x)
x = self.a4(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
x = self.e4(x)
x = self.maxpool(x)
x = self.a5(x)
x = self.b5(x)
#"""It was found that a move from fully connected layers to
#average pooling improved the top-1 accuracy by about 0.6%,
#however the use of dropout remained essential even after
#removing the fully connected layers."""
x = self.avgpool(x)
x = self.dropout(x)
x = x.view(x.size()[0], -1)
x = self.linear(x)
return x
5. 总结
为了能够将稀疏性和计算的密集性结合起来,拓宽了网络结构。并且采用了1x1,3x3,5x5的小卷积形式。并且加入了1x1卷积层降低维度。在防止梯度消失时加入了辅助分类器。
参考
https://medium.com/analytics-vidhya/paper-explanation-going-deeper-with-convolutions-googlenet-the-ai-blog-b79574ac8fe0 # Paper Explanation: Going deeper with Convolutions (GoogLeNet)
https://towardsdatascience.com/deep-learning-googlenet-explained-de8861c82765 # Deep Learning: GoogLeNet Explained
https://machinelearningmastery.com/batch-normalization-for-training-of-deep-neural-networks/ # A Gentle Introduction to Batch Normalization for Deep Neural Networks
https://github.nowall.world/weiaicunzai/pytorch-cifar100 # 代码实现
标签:nn,卷积,self,googLeNet,64,004,Inception,GoingDeeperConvolutions2014,size 来源: https://www.cnblogs.com/guixu/p/16689418.html