ECCV 2022 | OA-MIL:目标感知多实例学习方法
作者:互联网
前言 针对定位精度受到不准确边界框的严重影响,而分类精度受影响较小,因此本文提出利用分类作为指导信号来改进定位结果。
通过将目标视为实例包,作者提出了一种目标感知多实例学习方法(OA-MIL),其特点是目标感知实例选择和目标感知实例扩展。前者旨在为训练选择准确的实例,而不是直接使用不准确的框标注。后者侧重于生成用于选择的高质量实例。
在合成噪声数据集(即有噪声的PASCAL VOC和MS-COCO)和真实的有噪声wheat head数据集上进行的大量实验证明了OA-MIL的有效性。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
QQ交流群: 444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。

原文:https://arxiv.org/pdf/2207.09697.pdf
代码:https://github.com/cxliu0/OA-MIL
创新思路
目前目标检测是做得非常好的方向,其主要受益于标注数据非常多,但对于其他方向来说,标注是很困难的事,尤其对于一些专业领域的数据,例如农业,医学图像,如果不是专业人员,甚至都不知道应该标注哪些。
这种情况导致了一个困境,即没有计算机视觉背景的从业者不确定如何标注高质量的框,而没有领域知识的标注者也很难标注精确的目标框。另一方面,在自然环境中标注大量常见目标既昂贵又耗时。为了降低标注成本,数据集制作者可能依赖社交媒体平台或众包平台。然而,上述战略将导致标注质量低下。
最近,具有噪声数据的学习目标检测器引发了极大的兴趣,已有几种方法尝试处理噪声标注。这些方法通常假设噪声出现在类别标签和边界框标注上,并设计一个分离的体系结构来学习目标检测器。与之前的工作不同,作者主要关注带噪边界框标注的目标检测。
原因有两方面:
1.由于目标的模糊性和众包标注过程,现实中普遍存在盒噪声;
2.目标检测数据集经常涉及目标类验证,因此有噪声的类别标签比不准确的边界框更严重。
由于观察到定位精度显著受到不准确边界框的影响,而分类精度受影响较小,因此,作者提出利用分类作为定位的指导信号。具体而言,提出了一种目标感知多实例学习方法,将每个目标视为实例包。其思想是从目标包中选择准确的实例进行训练,而不是使用不准确的框标注。
本文的主要贡献
1、通过将目标视为一实例包,为学习具有不精确边界框的目标检测器提供了一种新的视图;
2、提出了一种目标感知多实例学习方法,其特点是目标感知实例选择和目标感知实例扩展OA-MIL在现成的目标检测器上具有通用性,并在合成和真实噪声数据集上获得了有前景的结果。
方法
目标感知多实例学习
由于观察到分类在噪声框标注下保持高精度(图2),作者提出利用分类来指导定位。也就是说,作者期望分类分支选择更精确的框进行训练,而不是使用不准确的ground-truth框。这个想法衍生了目标包的概念,其中每个目标都被描述为一个实例包。在目标包的基础上,作者提出了一种目标感知多实例学习方法,该方法具有目标感知实例选择和目标感知实例扩展。
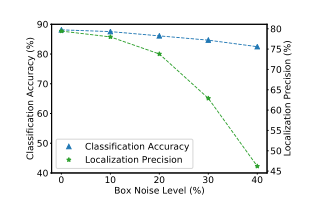
图2:Faster RCNN在模拟的“有噪”PASCAL VOC 2007数据集上的分类精度和定位精度,其中框标注被随机扰动。
预备工作
给定图像级标签,WSOD中的MIL方法将每个图像视为一实例包。学习过程在实例选择和实例分类器学习之间交替。将具有参数ωf的实例选择器f应用于正包Bi,以选择最正的实例,指数j∗通过以下方式获得:

所选实例用于训练具有参数ωg的实例分类器g。总损失函数定义为:
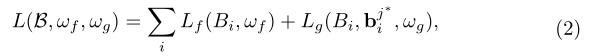
目标感知MIL公式
尽管将目标检测描述为一个MIL问题,但WSOD中现有的MIL范式不能解决噪声盒标注下的学习问题。首先,由于在WSOD中将图像定义为袋,因此忽略了目标的定位先验。其次,WSOD中的包只是由现成的目标建议生成器生成的目标建议的集合,这限制了检测性能。
与WSOD不同,在本文的目标包的上下文中,需要解决两个挑战:i)如何在每个目标包中选择准确的实例进行训练;以及ii)如何为每个目标包生成高质量实例。
为了解决上述挑战,作者提出了一种目标感知的MIL公式,该公式联合优化了实例选择器、实例分类器以及实例生成器。图3给出了OA-MIL的概述。
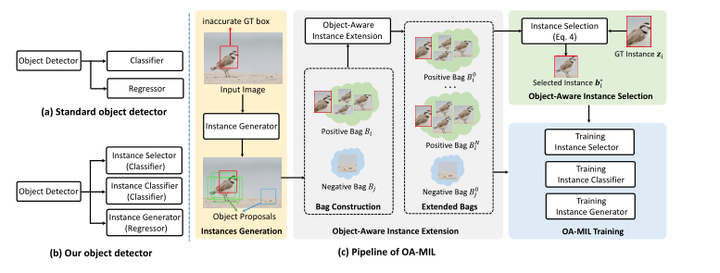
图3:OA-MIL的概述。
目标感知实例选择
作者期望所选实例尽可能紧密地覆盖实际目标。然而由于实例选择器在训练的早期阶段具有差的辨别能力,实例分类器和实例生成器将不可避免地受到低质量正实例的影响。在某些情况下,不好的实例初始化可能会导致训练失败。
由于不准确的ground-truth框提供了目标定位的强先验,因此,联合考虑它和所选实例,以获得更适合训练的正实例。具体而言,将zi表示为不准确的ground-truth实例。通过合并zi和bj来执行目标感知实例选择,如下:
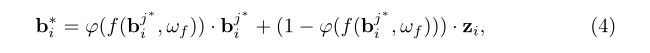
作者的目标是选择高质量的正向实例进行训练,因此φ(·)需要满足两个条件。首先,当f(bj∗i, ωf)的值较大时,应赋予bj∗i较高的权重。其次,当f(bj∗i, ωf)接近1时,φ(·)应平衡bj∗i和zi的权重,而不是依赖于bj∗i。为满足上述条件,采用如下有界指数函数:

目标感知实例扩展
实例的质量是影响训练过程的另一个因素。在公式中,包是根据实例生成器的输出动态构造的。因此,包实例的质量不能总是得到保证。但正包中的实例是同构的,也就是说,实例在空间位置和类信息上彼此密切相关。因此,可以通过扩展积极的实例来促进正包的质量。
作者提出了两种实例扩展策略。
第一种策略是通过递归构造正包来获得新的正实例。首先根据有噪声的ground-truth框获得初始的目标包,然后利用Eq.(4)选取的最正的实例构造一个新的正包。这个过程重复,直到达到终止条件。这种策略是通用的,适用于任何现有的目标检测器。
第二种策略是以多阶段的方式细化正实例,这适用于具有包围盒细化模块的目标检测器(如Faster RCNN)。扩展的目标包随后用于训练实例选择器。
假设进行了N次实例扩展,产生了一组扩展的正包{B0i, B1i,…, BNi}。利用扩展的目标包对实例选择器进行优化,因此损失为:
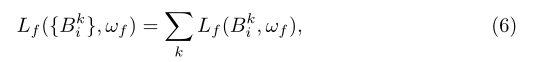
OA-MIL训练
OA-MIL涉及到联合优化实例选择器、实例分类器和实例生成器。实例选择器使用Eq.(6)进行训练。当使用实例分类器g对目标进行分类时,采用二进制对数损失对其进行训练:
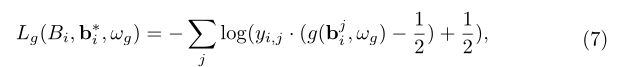
实例生成器的loss函数如下:
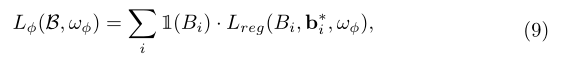
Lreg定义为:
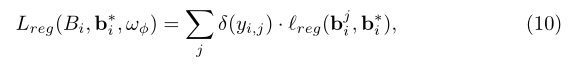
综上所述,整体损失函数为:
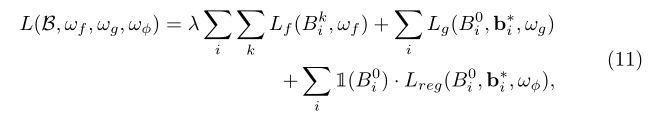
实验
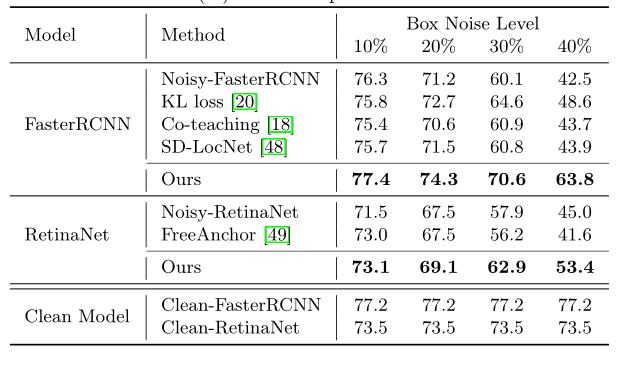
表1:PASCAL VOC 2007测试集上的性能比较。
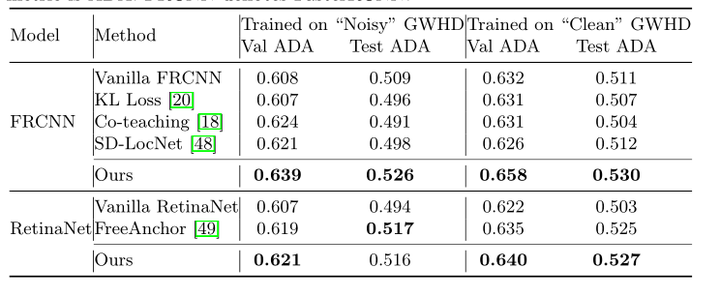
表3:GWHD验证和测试集的比较结果。
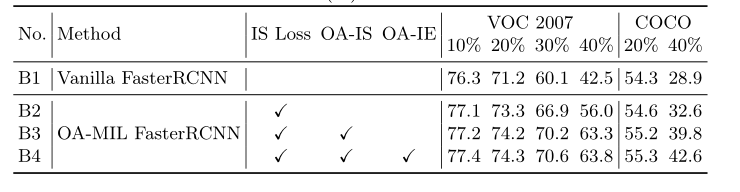
表4:VOC 2007测试集和COCO验证集的消融实验。

图6:(a) OA-MIL FasterRCNN(红色方框)和vanilla FasterRCNN(黄色方框)在COCO数据集上的定性结果。(b)故障案例。
结论
本文通过将一个目标视为一组实例,提出了一种具有目标感知的实例选择和目标感知的实例扩展的目标感知多实例学习方法。该方法是通用的,可以配合现有的目标检测器。在合成噪声数据集和真实噪声GWHD数据集上的大量实验表明,在边界框标注不准确的情况下,OA-MIL可以获得良好的结果。
搞了个QQ交流群,打算往5000人的规模扩展,还专门找了大佬维护群内交流氛围,大家有啥问题可以直接问,主要用于算法、技术、学习、工作、求职等方面的交流,征稿、公众号或星球招聘、一些福利也会优先往群里发。感兴趣的请搜索群号:444129970
加微信群加知识星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
其它文章
ECCV 2022 | MorphMLP:一种有效的用于视频建模的MLP类架构
CVPR 2022 | BatchFormerV2:新的即插即用的用于学习样本关系的模块
CVPR 2022|RINet:弱监督旋转不变的航空目标检测网络
ECCV 2022 | FPN:You Should Look at All Objects
ECCV 2022 | ScalableViT:重新思考视觉Transformer面向上下文的泛化
ECCV 2022 | RFLA:基于高斯感受野的微小目标检测标签分配
迁移科技-工业机器人3D视觉方向2023校招-C++、算法、方案等岗位
文末赠书 |【经验】深度学习中从基础综述、论文笔记到工程经验、训练技巧
ECCV 2022 | 通往数据高效的Transformer目标检测器
ECCV 2022 Oral | 基于配准的少样本异常检测框架
CVPR 2022 | 网络中批处理归一化估计偏移的深入研究
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
标签:MIL,ECCV,OA,目标,实例,2022,感知,标注 来源: https://www.cnblogs.com/wxkang/p/16685849.html