小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现
作者:互联网
在前两章中我们已经聊过对抗学习FGM,一致性正则Temporal等方案,主要通过约束模型对细微的样本扰动给出一致性的预测,推动决策边界更加平滑。这一章我们主要针对低密度分离假设,聊聊如何使用未标注数据来推动决策边界向低密度区移动,相关代码实现详见ClassicSolution/enhancement
半监督领域有几个相互关联的基础假设
- Smoothness平滑度假设:两个样本在高密度空间特征相近,则他们的label大概率相同,宏毅老师美其名曰近朱者赤近墨者黑。这里的高密度比较难理解,感觉可以近似理解为DBSCAN中的密度可达
- Cluster聚类假设:高维特征空间中,同一个簇的样本应该有相同的label,这里的簇其实对应上面平滑假设中的高密度空间。这个假设很强可以理解成Smoothness的特例,在平滑假设中并不一定要成簇
- Low-density Separation低密度分离假设:分类边界应该处于样本空间的低密度区。这个假设更多是以上假设的必要条件,如果决策边界处高密度区,则无法保证聚类簇的完整,以及样本近邻label一致的平滑假设
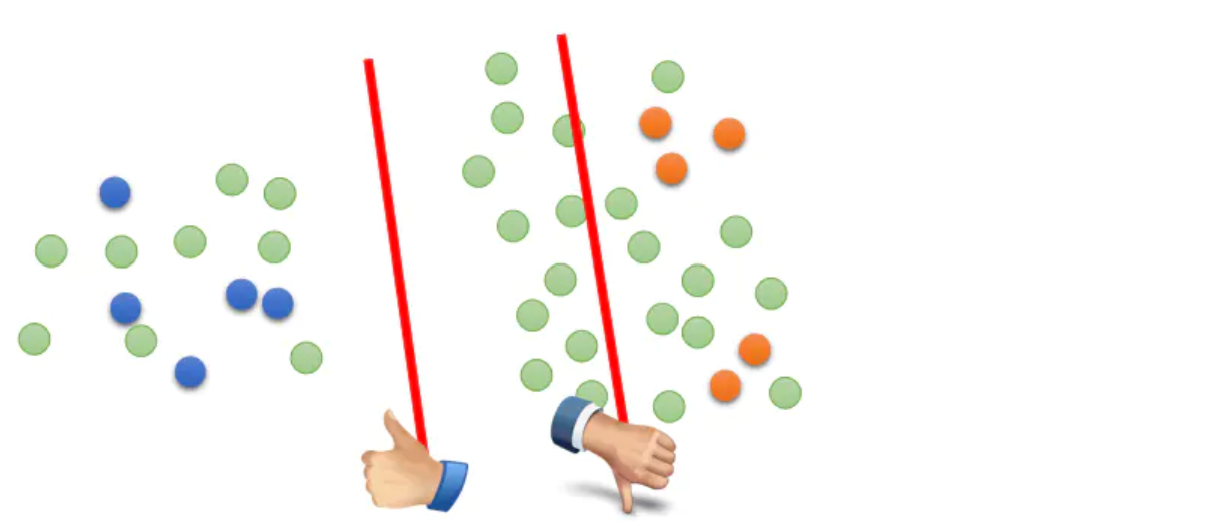
我们举个栗子来理解低密度分离,下图中蓝点和黄点是标注数据样本,绿点是未标注数据。只使用标注样本进行训练,决策边界可能处于中间空白的任意区域,包括未标注样本所在的高密度区。如果分类边界处于高密度区,模型在未标注样本上的预测熵值会偏高,也就是类别之间区分度较低。因此要推动模型远离高密度区,可以通过提高模型在无标注样本上的预测置信度,降低预测熵值来实现,以下给出两种方案MinEnt和PseudoLabel来实现最小熵正则
Entropy-Minimization
- Paper: Semi-supervised Learning by entropy minimization
在之后很多半监督的论文中都能看到05年这边Entropy Minimization的相关引用。论文的核心通过最小化未标注样本的预测概率熵值,来提高模型在以上聚类假设,低密度假设上的稳健性。
实现就是在标注样本交叉熵的基础上加入未标注样本的预测熵值H(y|x),作者称之为熵正则,并通过\(\lambda\)来控制正则项的权重
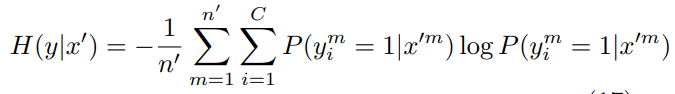
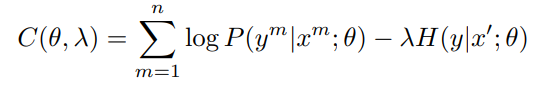
这篇paper咋说呢公式不少,不过都是旁敲侧击的从极大似然等角度来说熵正则有效的原因,但并没给出严谨的证明。。。
Pseudo-Label
- paper: Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
13年提出的Pseudo Label,其实和上面的MinEnt可以说是一个模子出来的。设计很简单,在训练过程中直接加入未标注数据,使用模型当前的预测结果,也就是pseudo label直接作为未标注样本的label,同样计算交叉熵,并和标注样本的交叉熵融合得到损失函数,如下
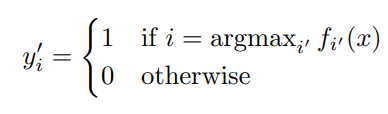
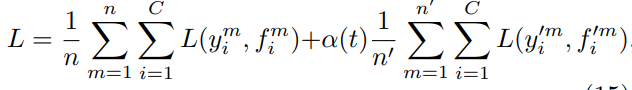
最开始读会比较疑惑,因为之前了解到对pseudo label多是self-training的路子,先用标注数据训练模型,然后在未标注样本上预测,筛选高置信的未标注样本再训练新模型,训练多轮直到模型效果不再提升,而这篇文章的实现其实是把未标注样本作为正则项。因为预测label和预测概率是相同模型给出的,因此最小化预测label的交叉熵,也就是最大化预测为1的class对应的概率值,和MinEnt直接最小化未标注样本交叉熵的操作可谓殊途同归~

正则项的权重部分设计的更加精巧一些,作者使用了分段的权重配置,epoch<T1时正则项的权重为0,避免模型最初训练效果较差时,预测的label准确率低正则项会影响模型收敛,训练到中段后逐渐提高正则项的权重,超过一定epoch之后,权重停止增长。

以上两个基于最小熵正则的实现方案都简单,不过在一些分类任务上尝试后感觉效果比较玄学,在kaggle上分技巧中有大神说过在一些样本很小, 整体边界比较清晰的任务上可能会有提升。主要问题是pseudo label中错误的预测值其实就是噪声样本,所以会在训练中引入噪声,尤其当epoch增长到一定程度后,噪声样本对模型拟合的影响会逐渐增加,而最小熵当样本本身处于错误的区域时,预测置信度的提高,其实是增加了错误预测的置信度。不过之后一些改良方案中都有借鉴最小熵,所以在后面我们会再提到它~
Reference
- https://github.com/iBelieveCJM/pseudo_label-pytorch
- https://zhuanlan.zhihu.com/p/72879773
- https://www.kaggle.com/code/cdeotte/pseudo-labeling-qda-0-969/notebook
- https://stats.stackexchange.com/questions/364584/why-does-using-pseudo-labeling-non-trivially-affect-the-results
标签:预测,假设,样本,MinEnt,label,正则,PseudoLabel,标注 来源: https://www.cnblogs.com/gogoSandy/p/16637294.html