YOLOV:图像对象检测器在视频对象检测方面表现也很不错
作者:互联网
前言 与传统的两段pipeline不同,论文提出了在一段检测之后再进行区域级的选择,避免了处理大量低质量的候选区域。此外,还构建了一个新的模块来评估目标帧与参考帧之间的关系,并指导聚合。
作者进行了大量的实验来验证该方法的有效性,并揭示了其在有效性和效率方面优于其他最先进的VID方法。在ImageNet VID数据集上,采用单个2080Ti GPU,达到了超过30帧/秒的87.5% AP50。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
QQ交流群: 444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。

论文:https://arxiv.org/pdf/2208.09686.pdf
代码:https://github.com/YuHengsss/YOLOV
创新思路
基于区域的CNN系列(R-CNN)是两阶段物体检测器的先驱,具有多种后续功能给定区域级特征,这些静止图像检测器可以很容易地转移到更复杂的任务,如分割和视频对象检测。然而,由于两阶段性质,效率是实际应用的瓶颈,而对于单阶段目标检测器,定位和分类是由特征图的密集预测联合直接产生的。
视频对象检测可以被视为静止图像对象检测的高级版本。可以通过将帧一帧一帧地馈送到静止图像对象检测器中来处理视频序列。但是,通过这种方式,跨帧的时间信息将被浪费,这可能是消除/减少单个图像中出现的模糊性的关键。
如图1所示,诸如运动模糊、相机散焦和遮挡等劣化经常出现在视频帧中,显著增加了检测的难度。例如,仅通过查看图1中的最后一帧,人类很难甚至不可能分辨出物体在哪里和是什么。另一方面,视频序列可以提供比单个静止图像更丰富的信息。也就是说,同一序列中的其他帧可能支持特定帧的预测。

图1:帧遭受各种退化,如运动模糊和遮挡,使基础YOLOX无法完成任务
帧聚合有两种主要类型,即框级和特征级。这两种技术路线可以从不同角度提高检测精度。关于框级方法,它们通过链接边界框来连接静止对象检测器的预测以形成tubelet,然后在同一tubelet中细化结果。盒级方法可被视为后处理,可灵活应用于一级和两阶段检测器。
而对于特征级方案,关键帧的特征通过从其他帧(也称为参考帧)中查找和聚集相似特征来增强。两阶段方式以由区域建议网络(RPN)提取的主干特征图的显式表示,得益于这种性质,两阶段检测器可以很容易地迁移到视频对象检测问题。因此,大多数视频对象检测器构建在两阶段检测器上。
然而,由于引入了寻求方案之间的关系,这些两阶段视频对象检测器进一步减速,因此难以满足实时场景的需要。与两阶段基础不同,提出了由一阶段检测器的特征图元素隐式表示。尽管没有对象的显式表示,但特征图的这些元素仍然可以从聚集VID任务的时间信息中受益。
在这些考虑的驱动下,自然产生了一个问题:能否使这种区域级设计适用于仅包含像素级特征的单阶段检测器,以构建实用(准确和快速)视频对象检测器。
本文通过设计一种简单而有效的策略来聚集单阶段检测器在这项工作中生成的特征,回答了上述问题。
本文主要的贡献
1. 提出了一个特征相似性度量模块来构建亲和矩阵,然后用该矩阵来指导聚合。
2. 为了进一步缓解余弦相似性的限制,定制了参考特征上的平均池算子。
3. YOLOV可以在单个2080Ti GPU上以40+FPS的速度在ImageNet VID数据集上实现85.5%的AP50,通过进一步引入后处理,其精度在超过30fps时达到87.5%的AP50。
方法
考虑视频特征(各种退化与丰富的时间信息)的方法,而不是单独处理帧,如何从其他帧中为目标帧(关键帧)寻找支持信息,在提高视频检测精度方面起着关键作用。大多数现有方法是基于两阶段的技术。
如前所述,它们的主要缺点是与单阶段基础相比,推理速度相对较慢。为了缓解这一限制,作者将区域/特征选择放在单阶段检测器的预测头之后。框架如图3所示。
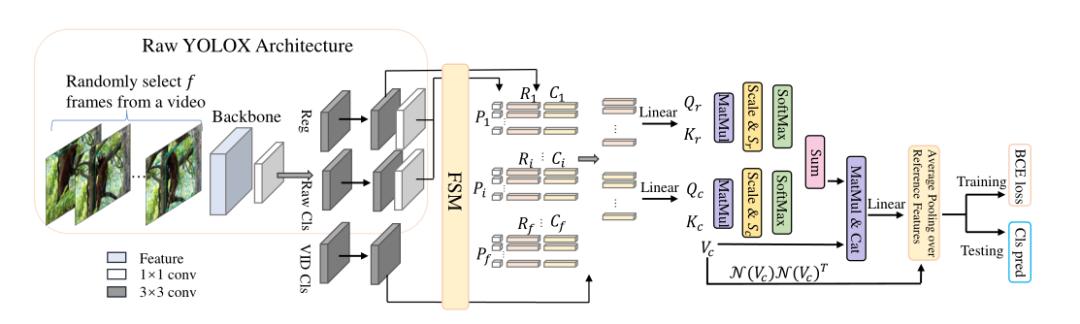
图3:本文的设计框架。以YOLOX为基础检测器,相应的模型称为YOLOV。从视频中随机采样若干帧,并将其输入基础检测器以提取特征。
传统的两阶段管道:首先“选择”大量候选区域作为 proposals;确定每个 proposal是否为对象,以及它属于哪个类别。计算瓶颈主要来自处理大量的低置信度区域候选。
如图3所示,pipeline 还包含两个阶段。不同的是,其第一阶段是预测(丢弃大量具有低置信度的区域),而第二阶段可以被视为区域级细化(通过聚合利用其他帧)。
根据这一原理,作者的设计可以同时受益于单阶段检测器的效率和从时间聚集获得的精度。所提出的策略可以推广到许多基本检测器,如YOLOX、FCOS和Pyoloe。
FSM:特征选择模块
由于大多数预测的可信度较低,单阶段检测器的检测头是从特征图中选择(高质量)候选的自然和合理的选择。在RPN过程之后,首先根据置信度得分选出前k(例如750)个预测。然后,非最大值抑制(NMS)选择固定数量a的预测(例如,a=30),以减少冗余。为了获得用于视频对象分类的特征,基本检测器的精度应得到相应保证。
在实践中,作者发现直接聚集分类分支中的选定特征并反向传播聚集特征的分类损失将导致不稳定的训练。
为了解决上述问题,作者将两个3×3卷积(Conv)层作为一个新分支插入模型颈部,称为视频对象分类分支,它生成用于聚合的特征。然后,将视频分类和回归分支中与位置相关的特征输入到特征聚合模块中。
FAM:功能聚合模块
当关键帧出现某些退化时,与这些相似特征相对应的选定方案很可能出现相同的问题。将这种现象称为同质性问题。
为了克服这个问题,进一步考虑了来自基础的预测置信度Pi,Pi的每一列仅包含2个分数,即分别来自分类和回归头的分类分数和IoU分数。然后,构建查询、键和值矩阵,并将其输入多头注意力。通过注意的标度点积,得到了相应的Ac和Ar,收集P中的所有分数得到一个大小为2×FA的矩阵[P1,P2,…,Pf]。
为了使这些分数适合注意力权重,作者构建了两个矩阵,即Sr和Sc。然后,得到分类和回归分支的自我关注结果:
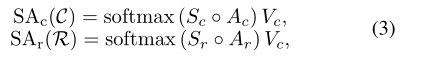
将Vc与等式(3)的输出连接起来,以便通过以下方式更好地保留初始表示:
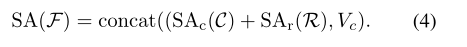
此外,考虑到softmax的特性,它常常忽略具有低权重的特征,这限制了可能后续使用的参考特征的多样性。
为了避免此类风险,作者引入了一种基于参考特征的平均池(A.P.)。选择所有相似度得分高于阈值τ的参考,并将平均合并应用于这些参考。这样,可以维护来自相关功能的更多信息。然后将平均合并特征和关键特征传输到一个线性投影层中进行最终分类。该过程如图4所示。
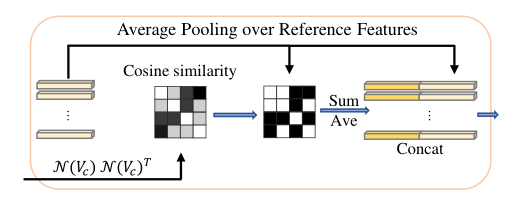
图4:对参考特性的平均池。
实验
为了观察不同采样策略的效果,在全局和局部模式下改变参考帧的数量。数值结果如表1所示。

表1:全局fg和局部fl参考系数量的影响。
将FSM中每个帧a保留的最有信心建议的数量从10调整到100,以查看其对性能的影响。如表2所示,随着a的增加,精度不断提高并趋于稳定,直到达到75。

表2:FSM中帧a数量的影响。
测试了不同阈值对参考特征平均池的影响。表3列出了数值结果。可以看出,当所有特征都参与平均池时,即τ=0,AP50仅为73.1%。提高选择标准会带来更好的性能。当τ落在[0.75,0.85]时,精度保持稳定,高达77.3%。
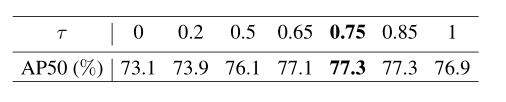
表3:平均汇集中阈值τ对参考特征的影响。
为了验证关联方式(A.M.)和参考特征平均池(A.P.)的有效性,评估了使用和不使用这些模块的性能。表4中的结果表明,这些设计都可以帮助特征聚合从一级检测器捕获更好的语义表示。与YOLOX-S(69.5%AP50)相比,仅配备A.M.的YOLOV-S的精确度提高了7.4%。

表4:亲和力方式(A.M.)和参考特征的平均池(A.P.)的有效性。
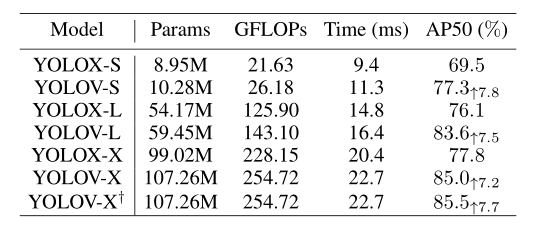
表5:与 bases相比,本文策略的有效性。表5显示了Yolox和Yolov之间的详细比较。

图5:通过三种不同方法为给定关键方案选择的参考方案之间的视觉比较。
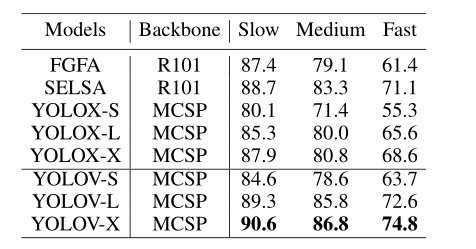
表7:不同速度下检测物体的精度。如表7所示,模型的有效性在每个类别上都得到了明确验证。随着移动速度的增加,该改进增大。
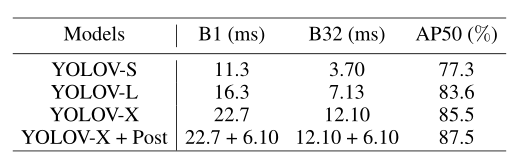
表8:具有批量推理的离线模式下的时间成本。后处理在i7-8700K CPU上进行测试。
结论
论文提出了一种实用的视频对象检测器,它综合考虑了检测精度和推理效率。为了提高检测精度,设计了一个特征聚合模块来有效地聚合时间信息。
为了节省计算资源,与现有的两阶段检测器不同,本文将区域选择放在(粗)预测之后。这种细微的变化使检测器效率显著提高。
搞了个QQ交流群,打算往5000人的规模扩展,还专门找了大佬维护群内交流氛围,大家有啥问题可以直接问,主要用于算法、技术、学习、工作、求职等方面的交流,征稿、公众号或星球招聘、一些福利也会优先往群里发。感兴趣的请搜索群号:444129970
加微信群加知识星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
其它文章
ECCV 2022 | ScalableViT:重新思考视觉Transformer面向上下文的泛化
ECCV 2022 | RFLA:基于高斯感受野的微小目标检测标签分配
迁移科技-工业机器人3D视觉方向2023校招-C++、算法、方案等岗位
文末赠书 |【经验】深度学习中从基础综述、论文笔记到工程经验、训练技巧
ECCV 2022 | 通往数据高效的Transformer目标检测器
ECCV 2022 Oral | 基于配准的少样本异常检测框架
CVPR 2022 | 网络中批处理归一化估计偏移的深入研究
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
标签:视频,参考,对象,检测,检测器,特征,阶段,YOLOV 来源: https://www.cnblogs.com/wxkang/p/16631569.html