awesome-exploration-rl 前沿追踪——如何高效地探索未知的奥秘
作者:互联网
引言
探索和利用的平衡 (The banlance between exploration and exploitation) 是强化学习中最核心的问题之一。 一般来说,利用指的是利用当前已知知识做出最优动作,探索指的是探索未知的环境以获取新的知识,从而潜在地可能得到回报更大的动作。探索与利用如何平衡的问题即是指:何时选择探索,何时选择利用,才能高效地探索未知的世界,使回报最大化?
首先来看生活中的这样一个例子:
A 地区一共有 10家餐馆,小明每去一家餐馆吃饭需要花费100元。到目前为止,小明在其中 5家餐馆吃过饭,并依据安全,卫生,营养,美味这4个维度进行了评分 (每维为0-10分,餐馆的最终得分取这4维的平均分),评分依次为6, 5, 4, 7, 9分,剩下的5家餐馆也许可以评到10分,也许只有2分。如果想在花费最少的情况下,吃到评分最高的餐馆,下一次吃饭小明应该选择去哪里呢?
在这个问题中,为了“吃到评分最高的餐馆” ,即获得更高的回报,小明需要
- 探索,即指选择以前从来没有去过的餐厅 (到达未访问过的状态动作空间)。
- 利用,即指选择当前评分最高的餐厅 (利用当前已知知识,选择能产生最大回报的动作)。
- 那么,小明到底该去哪家呢?这就是探索和利用的平衡问题。这样的问题在我们的日常生活中比比皆是,可以说也是我们人生的核心问题之一。
一般来说,一个强化学习智能体想要找到最优策略,需要保证遍历环境中的所有状态-动作空间:
- 在简单的表格环境上,实现此要求最简单的方法是采用随机探索策略,即在每个状态下选择所有可选动作的概率都是非零的,例如 epsilon-greedy 或 Boltzman Exploration。 虽然这种随机探索策略在表格环境中,最终会收敛到最优策略,但是它们收敛到最优策略所需的步数随着状态空间的大小呈指数增长,效率低下。
- 在复杂环境中这是开销很大甚至是不可能的,尤其是在探索困难的环境中:
- 环境给出的奖励很稀疏。智能体需要作出特定的序列动作才可能得到一个非零的奖励,如果每一步仅仅采用随机探索,很可能在整个学习过程中都遇不到一个非零的奖励。例如在图1所示的格子世界环境中,智能体需要执行"转向,移动障碍物,开箱子,拿钥匙,开门"等长序列动作,才能有一个正的奖励。
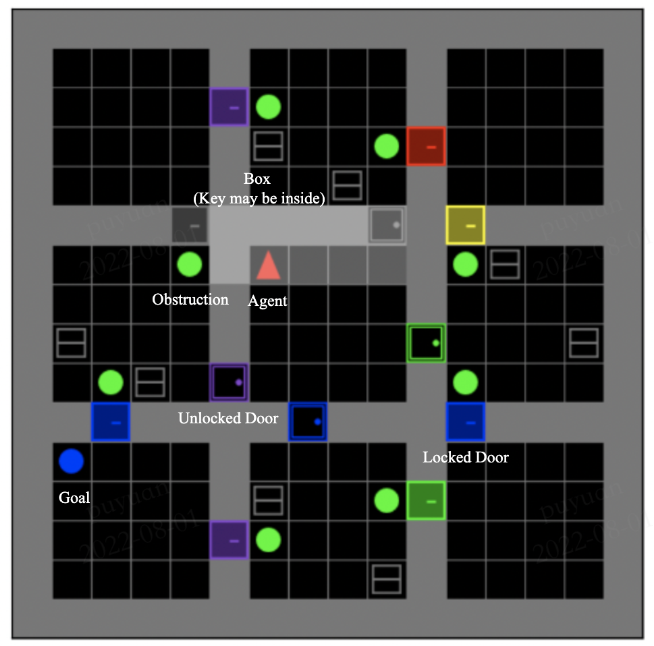 图1:MiniGrid-ObstructedMaze-Full-v0 环境示意图
图1:MiniGrid-ObstructedMaze-Full-v0 环境示意图
- 环境给出的奖励具有误导性。环境在智能体的初始点附近给出一些负的奖励或者小的正的奖励,容易导致智能体陷入局部最优解。
- 在图2所示的 Pitfall 游戏里面,不仅奖励很稀疏,而且智能体的很多动作会得到一个负的奖励,智能体在学习到如何获取一个正的奖励之前,可能会由于这些负的奖励的存在,停在原地不动,导致缺乏探索。
 tPitfall 环境示意图
tPitfall 环境示意图
- 在图3所示的 AppleKeyToDoorTreasure 环境中,红色的智能体的最终目标是到达绿色的目标位置(到达后奖励为+1),在方格世界中还有一个红色的苹果,拿到它奖励为+0.1,其他行为奖励都为0,如果智能体在拿到红色的苹果后便不再探索状态空间的其它部分,就无法找到最优的"拿钥匙开门达到绿色目标点"的最优策略。
 图3: AppleKeyToDoorTreasure 环境示意图
图3: AppleKeyToDoorTreasure 环境示意图
- 环境给出的状态具有误导性。例如在图4所示 "Noisy-TV" 问题中,环境的状态中包含一个输出随机噪声的 TV,它是不可控和不可预测的,将能够吸引基于好奇心的探索机制的智能体的注意力。
 图4: Noisy-TV 环境示意图
图4: Noisy-TV 环境示意图
在面对具有噪声,和复杂动力学转移属性的环境中(即不能遍历所有状态-动作空间) ,如何进行高效的探索即是强化学习中的探索机制 (Exploration in RL) 所研究的核心问题。
一般 RL 算法希望,最大化利用收集好的经验,将其抽象为值函数,模型,策略等知识,在访问状态-动作空间尽可能少的情况下,得到近似最优的策略。在这样观点的指导下,许多研究者提出了各种各样的探索机制,下面我们通过对近年来的强化学习书籍,论文的调研,对 Exploration in RL 进行了一个粗略的划分,以期望能给对强化学习探索机制感兴趣的人士提供一个入门指南。
强化学习中的探索机制分类
如图5所示,我们可以将强化学习过程分为两个阶段:经验收集 (collect) 阶段和模型训练 (train) 阶段:
- 在经验收集阶段,智能体根据当前的参数化策略直接给出动作 (policy gradient based method)或者根据学习到的最优值函数选择动作 (value based method),然后使用该动作与环境交互收集有用的经验。
- 在模型训练阶段,智能体使用收集到的经验来更新当前策略或值函数,以获得回报更高的策略。
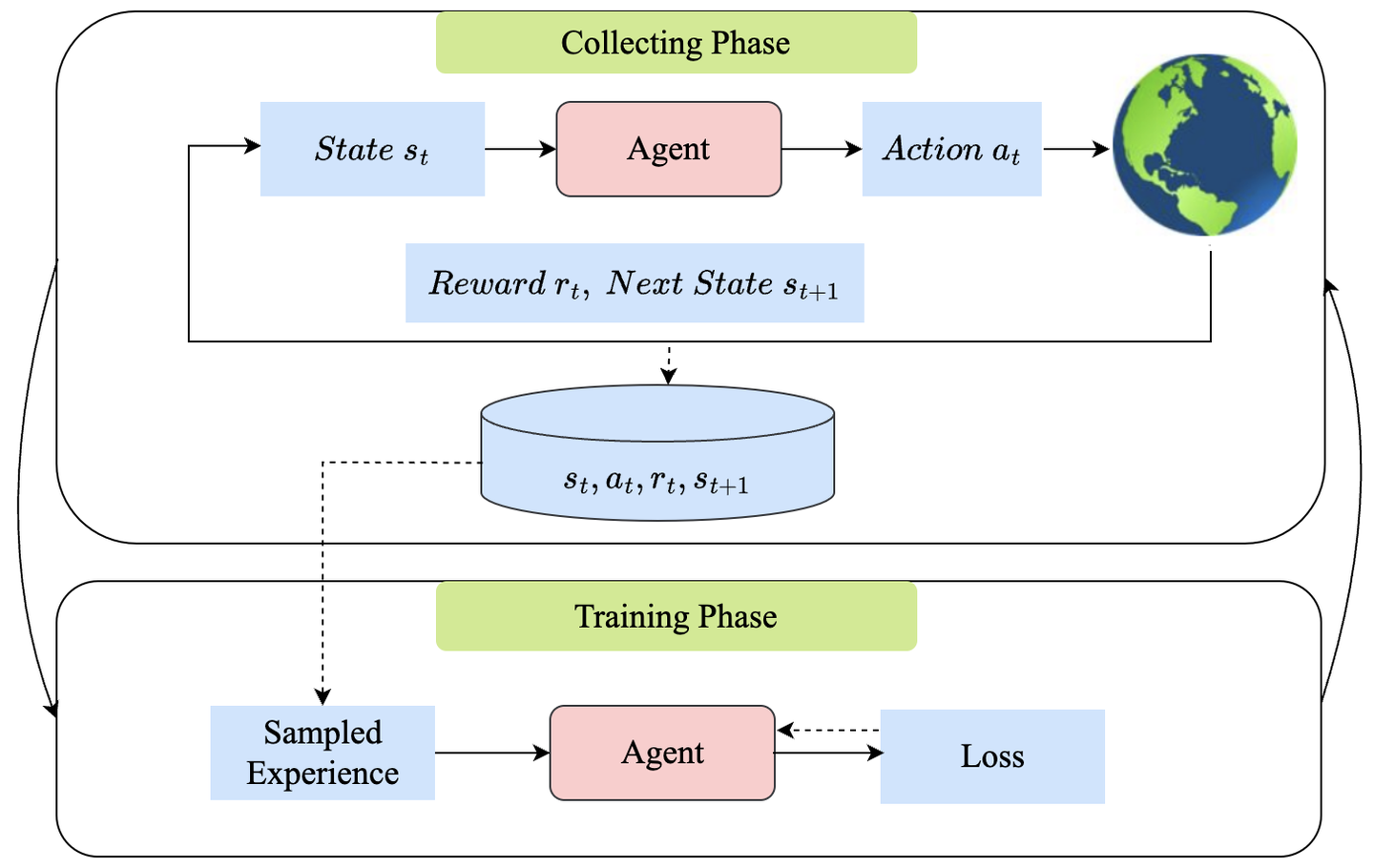 图5:强化学习中的经验收集 (collect) 阶段和模型训练 (train) 阶段
图5:强化学习中的经验收集 (collect) 阶段和模型训练 (train) 阶段
根据探索模块应用于RL算法的不同阶段,可以简单地将探索强化学习中的方法分为两大类,如图6所示:
- 增强收集策略 (Augmented Collecting Strategy) 类
- 增强训练策略 (Augmented Training Strategy) 类
增强收集策略类代表了经验收集阶段常用的各种不同的探索策略,我们将其进一步分为四个子类:
- 动作选择扰动 (Action Selection Perturbation)
- 动作选择指导 (Action Selection Guidance)
- 状态选择指导 (State Selection Guidance)
- 参数空间扰动 (Parameter Space Perturbation)
增强训练策略类代表了模型训练阶段常用的各种不同的探索策略,我们将其进一步分为七个子类:
- 基于计数 (Count Based)
- 基于预测 (Prediction Based)
- 基于信息论 (Information Theory Based)
- 熵 (Entropy Augmented)
- 基于贝叶斯后验 (Bayesian Posterior Based)
- 基于目标 (Goal Based)
- 专家演示数据 ((Expert) Demo Data)
 图6:强化学习中的探索机制概览图
图6:强化学习中的探索机制概览图
我们对每个不同的类别提供了一些示例方法,如上面的蓝色方块所示,更完整的论文链接可以参考 awesome-exploration-rl。值得注意的是,这些类别之间可能存在重叠,并且一个算法同时包含其中多个类别的相关思想。 此外,关于从其他角度对强化学习中的探索机制的相关分析,可以参考综述 Tianpei Yang et al 和 Susan Amin et al.
为了推动强化学习社区的发展,降低入门门槛,真正将 Exploration in RL 领域的算法成果推广到其他各个强化学习子领域和应用问题,我们对强化学习中的探索机制的一些经典论文和前沿进展进行梳理,主要侧重于 NeurIPS, ICLR, ICML 等机器学习顶会中的相关工作,相关论文列表已整理好放置于 GitHub 平台,并将会持续更新,也欢迎更多贡献者一起参与。
结语
我们将继续在 Awesome Exploration RL 仓库中推进强化学习中的探索相关问题的研究进展,包括一些算法文章解读,并结合 DI-engine 推出一系列探索与利用平衡相关的基准测试和代码,助力各位对 RL 有兴趣的人成为真正的强化学习探索家。
同时也欢迎志同道合的小伙伴 Pull Request 相关工作,共同营造健康、可持续的学术生态。
参考资料
[1] Go-Explore: Adrien Ecoffet et al, 2021
[2] NoisyNet, Meire Fortunato et al, 2018
[3] DQN-PixelCNN: Marc G. Bellemare et al, 2016
[4] #Exploration Haoran Tang et al, 2017
[5] EX2: Justin Fu et al, 2017
[6] ICM: Deepak Pathak et al, 2018
[7] RND: Yuri Burda et al, 2018
[8] NGU: Adrià Puigdomènech Badia et al, 2020
[9] Agent57: Adrià Puigdomènech Badia et al, 2020
[10] VIME: Rein Houthooft et al, 2016
[11] EMI: Wang et al, 2019
[12] DIYAN: Benjamin Eysenbach et al, 2019
[13] SAC: Tuomas Haarnoja et al, 2018
[14] BootstrappedDQN: Ian Osband et al, 2016
[15] PSRL: Ian Osband et al, 2013
[16] HER Marcin Andrychowicz et al, 2017
[17] DQfD: Todd Hester et al, 2018
[18] R2D3: Caglar Gulcehre et al, 2019
[19] ] https://lilianweng.github.io/posts/2020-06-07-exploration-drl/
标签:探索,awesome,al,学习,奖励,exploration,rl,et,强化 来源: https://www.cnblogs.com/OpenDILab/p/16623879.html