阿里云技术专家杨泽强:弹性计算云上可观测能力构建
作者:互联网
2022 年 7 月 4 日,【可观测,才可靠——云上自动化运维 CloudOps 系列沙龙_第一弹】正式推出。实现和保障系统的高可靠性和高稳定性,是上云后大家最关注的两项重要指标。如何通过云上的自动化 CloudOps 产品体系持续地提高可靠性和稳定性,是研发和运维需要共同努力的重要方向;持续提升可观测性则是达成目标的最直接和最有力的手段之一。
阿里云弹性计算 CloudOps 系列沙龙也将“可观测性与可靠性”作为第一弹的主题。本次沙龙直播覆盖四天,首位分享的嘉宾是阿里云弹性计算 SRE 技术专家杨泽强,他带来的主题分享是 《弹性计算云上可观测性能力构建》,以下是他的演讲内容整理,供大家阅览。

01 Why Observe?

可观测最早起源于农业时代气象观测,后来的电气时代、自动化时代都存在可观测性产品。控制理论中的可观察性指系统可以由其外部输出推断其内部状态的程度,系统的可观察性和可控制性是数学上的对偶概念。
以汽车为例,在驾驶过程我们无法直接感知到汽车系统的内部状态,而通过仪表盘可以获知当前发动机的转速、速度、油量以及其他系统的运行状态。
软件工程里,通过采集 logs、metrics 和 traces 三个维度来理解系统内部状态,即为可观测性。
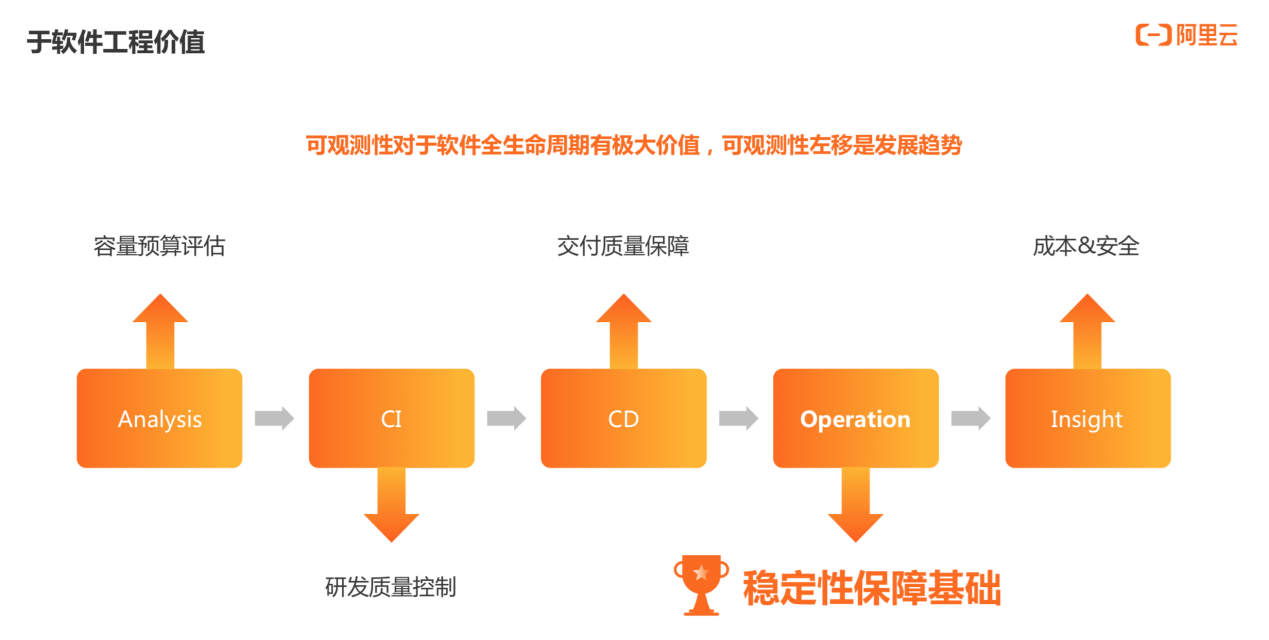
可观测性对于软件全生命周期有着极大价值。可以通过可观测性查看当前系统负载、异常链路、异常情况以及报警等;可以基于可观测性做预警,再基于预警进行分析,从而尽可能降低故障感知时间和定位时间,最终缩短故障 MTTR。
可观测性是软件系统稳定性保障的基础。而从软件工程整个视角看,可观测性能够提供的远不止稳定性保障。
软件工程最早期的需求分析阶段,可以通过可观测性进行容量预算评估;CI 阶段可以进行研发质量控制,比如构建成功、测试覆盖率等;交付过程中,可以通过可观测性对交付质量进行保障;同时成本和安全也能通过可观测性得到有效控制。
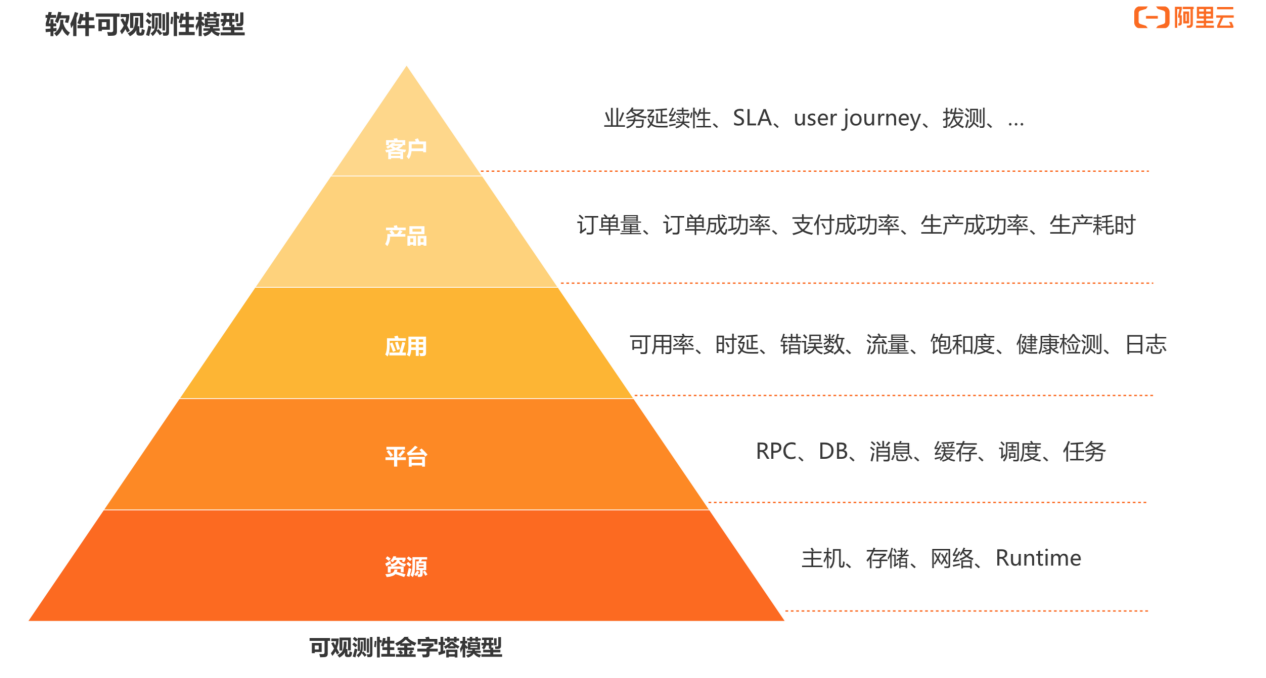
从软件的整个生命周期来看,如何构建自己理想的可观测性模型并没有标准答案。但是从单体应用或分布式应用到微服务等典型的软件架构来看,可以抽象出一个标准模型,如上图,由下至上分为 5 层:
⚫ 资源层:包括主机、存储、网络、Runtime 等。
⚫ 平台层:包括 RPC、DB、消息、缓存、调度等。
⚫ 应用层:包括可用率、时延、错误数、流量、饱和度、日志等。
⚫ 产品层:包括订单量、订单成功率、生产成功率、生产耗时等。
⚫ 客户层:包括业务延续性、SLA、拨测等。客户层是最容易被忽视但极具价值的一层。我们需要更多关注到客户业务的连续性、从用户视角如何使用可观测能力等。
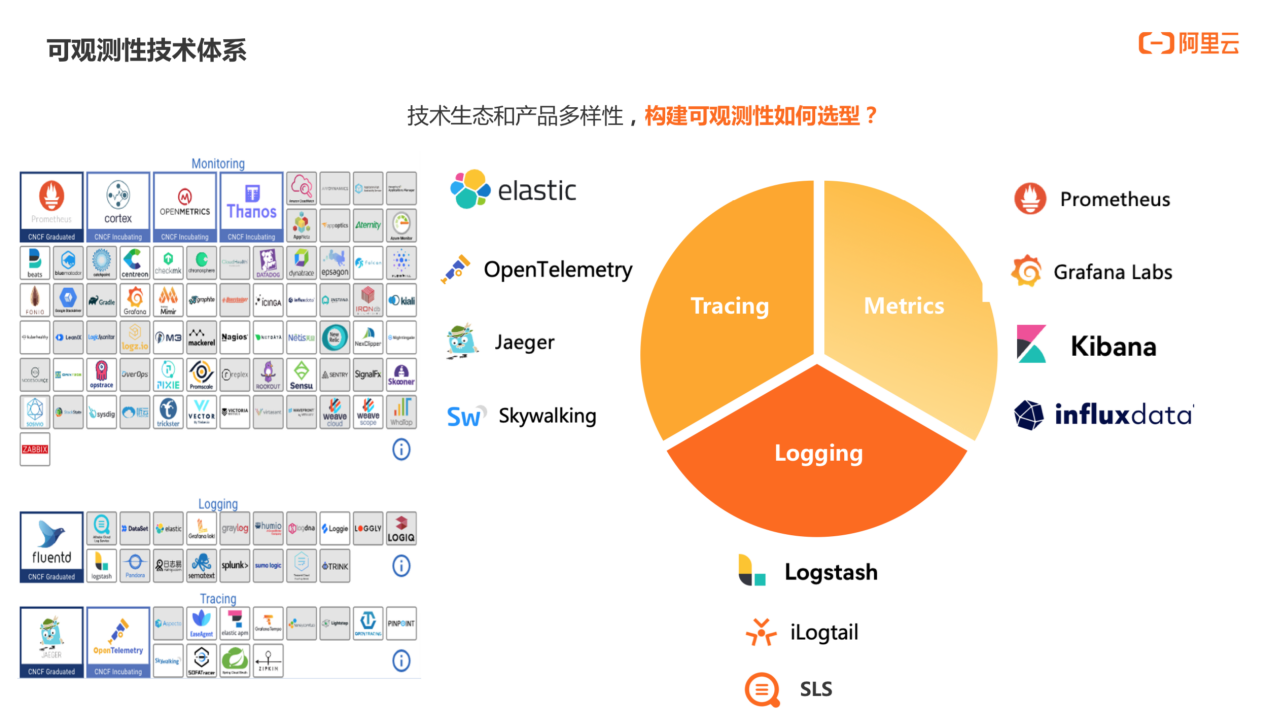
当前,可观测性技术体系的生态和产品已经十分丰富。Logging 侧有 Logstash、iLogtail、SLS 等,Metrics 侧有 Prometheus、Grafana、Kibana 等,Tracing 侧有 Elastic、Opentemeletry、Skywalking 等。
构建可观测性过程中如何选型没有标准答案,需要根据自己的实际需求来选择。
02 Observability on Cloud

2011 年,弹性计算可观测性上云的最初阶段,可观测性体系缺失,主要为单体应用模式,只有几个监控预警;2016 年,预警接入阿里自研监控平台,主要实现方式是传统的监控系统以及基于时序数据库的 metrics 采集和展示系统;2019 年,阿里开始逐步将 ECS 核心应用搬到云上,基于云构建体系,包括云监控和 SLS;2021 年,阿里开始了云原生改造,目前已经完成 90%左右的改造。另外,我们也整在云原生的基础上将技术体系改为开源的标准技术体系。
云上的弹性、可靠性以及天然具有多地域隔离等特性,为监控平台提供了极大的优势。另外,云原生的技术一直紧跟业界最新开源标准,其方案足够通用、足够先进,这也是自研平台研发节奏无法相比的。
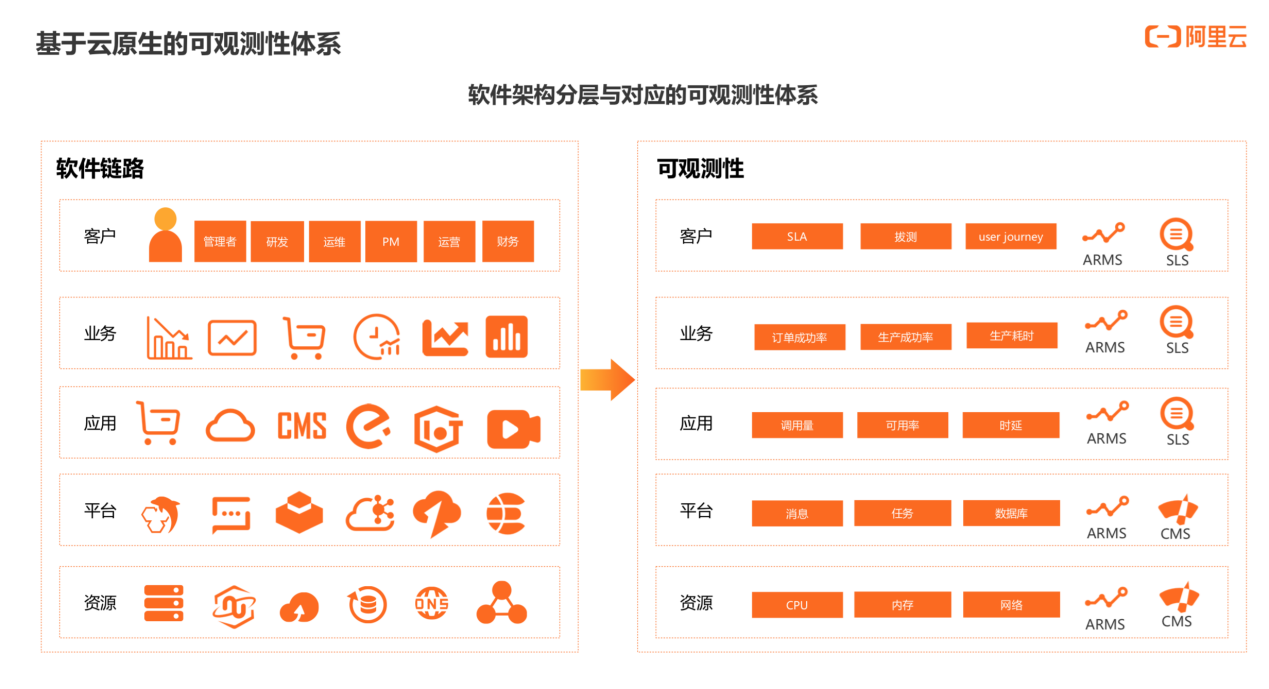
基础设施的监控主要通过云监控和 ARMS 两个产品来承载。ARMS 是一个 APM 工具,负责采集机器的 node 指标。
平台层包含诸多中间件、数据库等。此前,往往需要对接很多不同系统,而在云上,ARMS 提供的原生技术 eBPF 可以无缝采集全部指标,比如黄金三指标、数据库、MySQL 等,最终生成标准的 metrics 数据。
应用层的黄金三指标、可用率、时延、错误率、调用次数等,可以通过 ARMS 和 SLS 相互补充来构建。
业务层 ECS 实例的生产成功率、耗时等数据,是基于 ARMS 、SLS 的 trace 能力和 metrics 能力来构建。
客户层主要基于 ARMS 和 SLS 构建。我们需要从认知上进行转变,可观测性除了可以提供给 PM 使用,还可以提供给运营人员、财务人员以及管理者使用,它对于不同角色的意义和价值也不一样,这也是可观测性的价值所在。
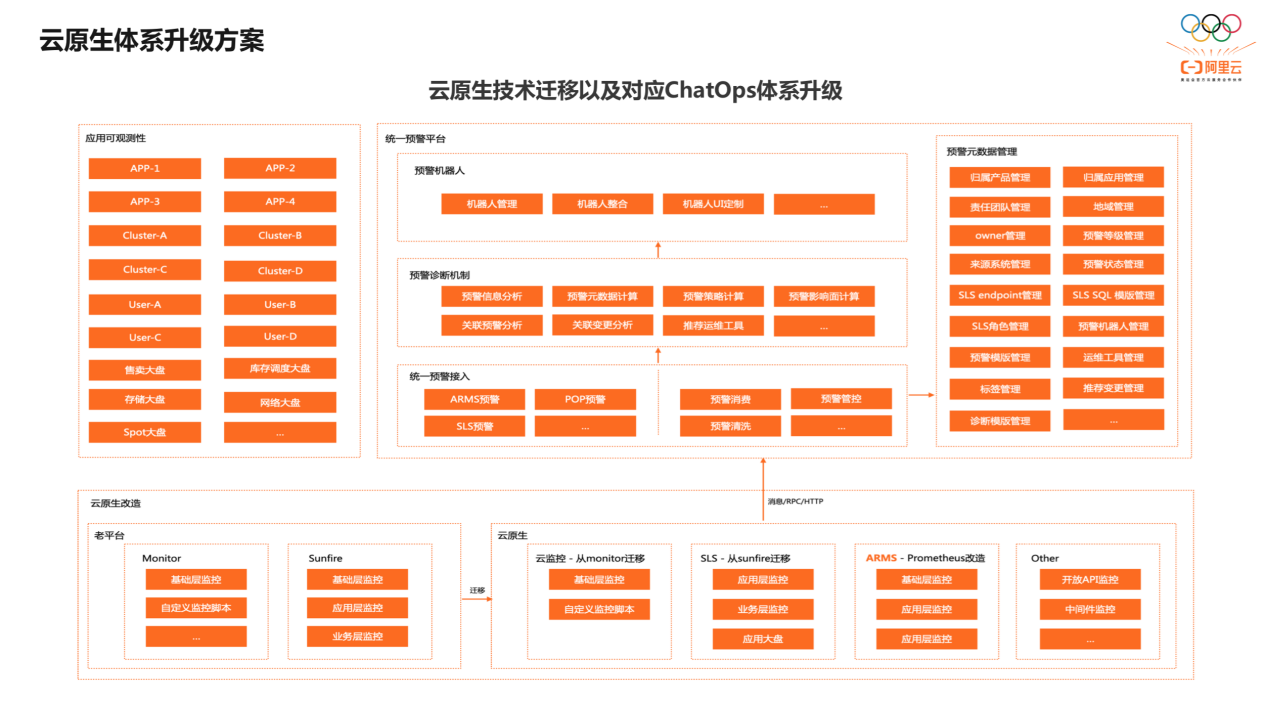
上图为 ECS 整体的升级方案。
老平台的 Monitor 和 Sunfire 迁移到云原生,主要为将基础监控迁到 CMS 云监控,将业务监控、应用监控迁到 ARMS ,trace 能力也会从最原始的日志编排服务迁到 ARMS trace 和基于 SLS 的日志库编排能力里。
除了云原生的开源技术标准,我们还基于基础能力自研了自动化运维体系,比如告警、故障诊断和快速恢复等。底层能力使用 SLS 和 ARMS 对外的 Open API 来构建。
可观测性比较好的观测视角是应用视角。另外,我们也基于一些业务的特殊性,从业务维度构建可观测性,比如 ECS 有集群,则基于 cluster 维度来构建可观测性。
构建完所有的可观测性后,我们还构建了统一的预警平台和自动化运维能力。
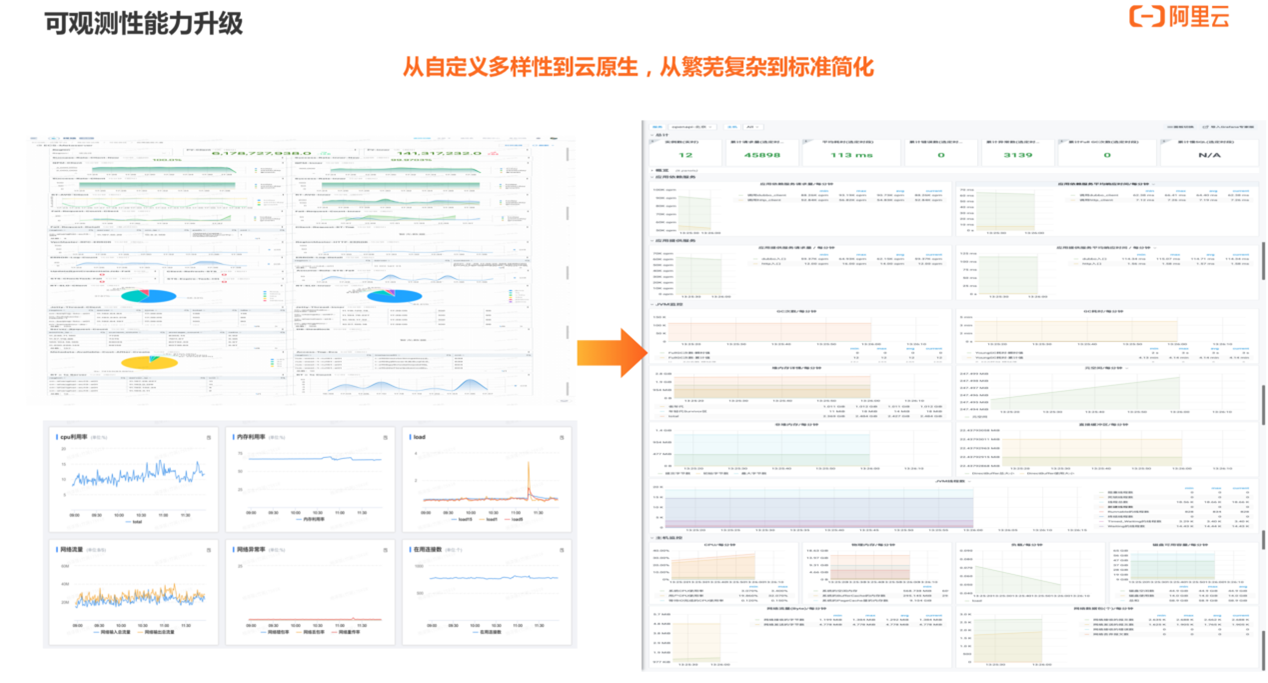
左侧最初的 Monitor 和 Sunfire 基于 log 构建,右边最新的可观测性系统是基于 Prometheus 和 Grafana 标准的开源方式构建。实现了从自定义多样性到云原生,从繁芜复杂到标准简化的转变。
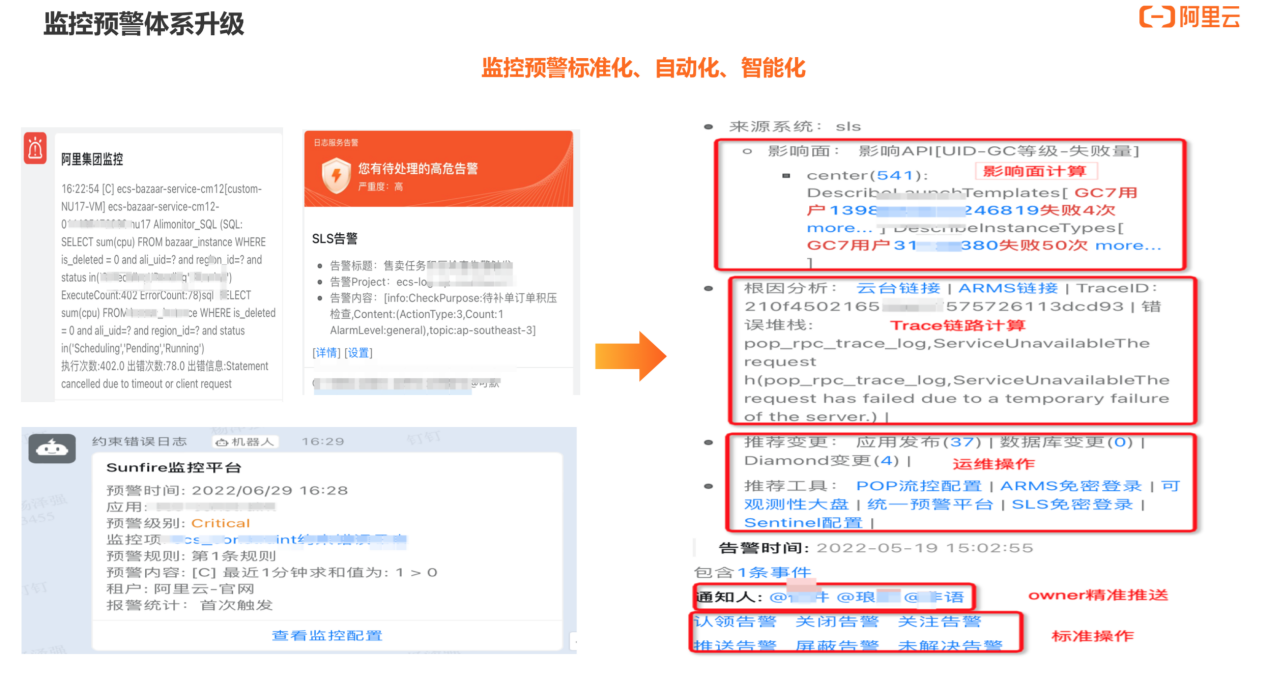
以监控预警为例,上图左侧为上云之前的监控预警体系,由阿里集团监控、Sunfire 监控平台和 SLS 告警构成。
上云后的监控预警体系如右侧所示。基于 Metrics 数据可以产生标准化的数据计算,比如计算影响面。运维操作里的数据也可以通过动态计算得出,可以查看原始堆栈、现场的关键指标、变更等。另外,我们还基于原生 API 构建了 owner 精准推送、预警标准化操作等能力。
03 Beyond Observability
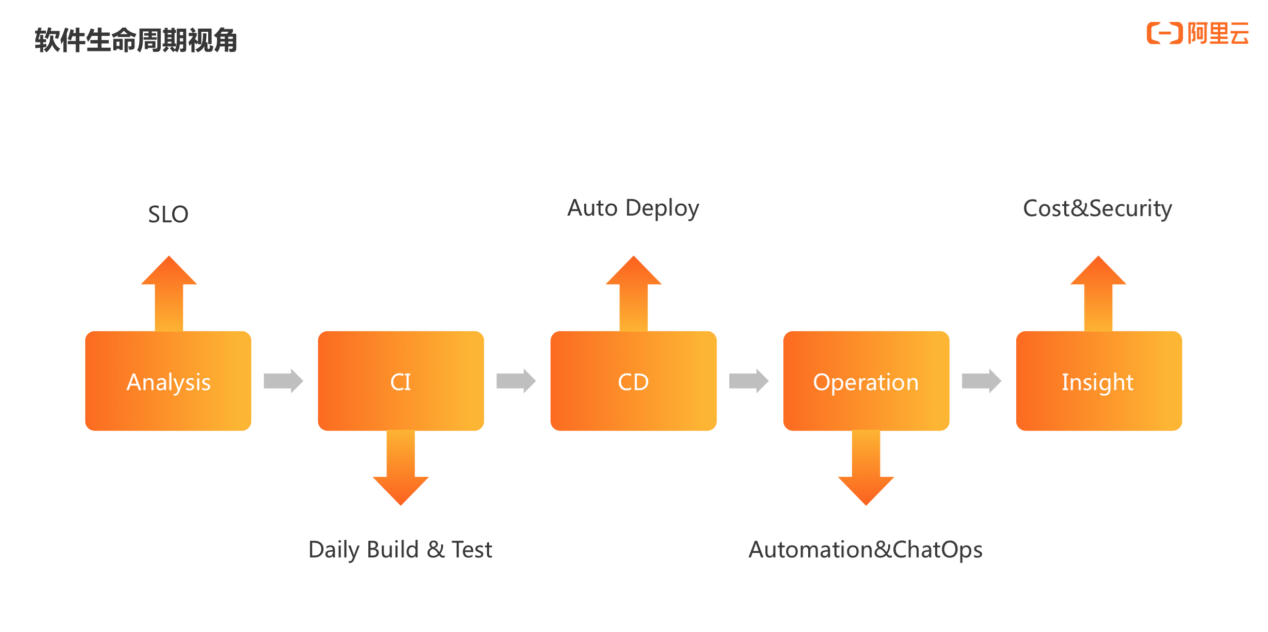
从软件生命周期视角看,CI 过程中会有每日构建和测试以及实时管理大盘;自动化发布会基于 Prometheus metrics 数据格式做自动化卡点;运行期提供了自动化运维和 Chat Ops ;当前,我们正在进行基于可观测性来建设安全度量和成本控制。
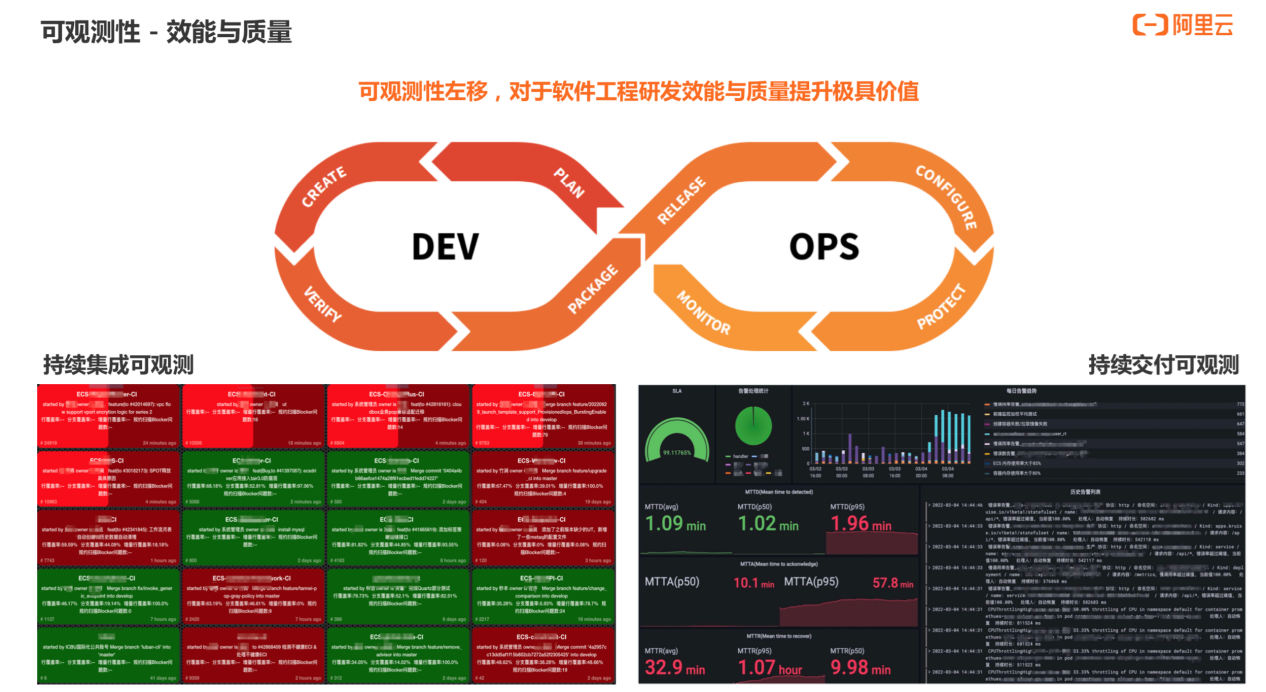
以效能和质量为例,DevOps 环中较为核心的两个环节是持续集成和持续交付,这也是直接影响软件工程质量的两个因素。
在持续集成方面,有 CI Dashboard ,每次输入代码都会触发 CI ,计算出代码行覆盖率、分支覆盖率、全复杂度以及成功或失败等状态,如上图右侧所示。
在持续交付方面,自动化发布的难点在于如何授信,因此我们实现了金丝雀发布。此外,我们认为发布过程中也需要可观测性,因此,我们将发布阶段的一些核心指标通过 metrics Dashboard 进行展示。同时会配合应用维度的 metrics 提供原子能力以及发布系统的卡点,以实现发布自动化。
上述功能的本质为将可观测性左移,从软件工程运行期的可观测性移到代码发布和交付阶段,以保障交付代码质量。
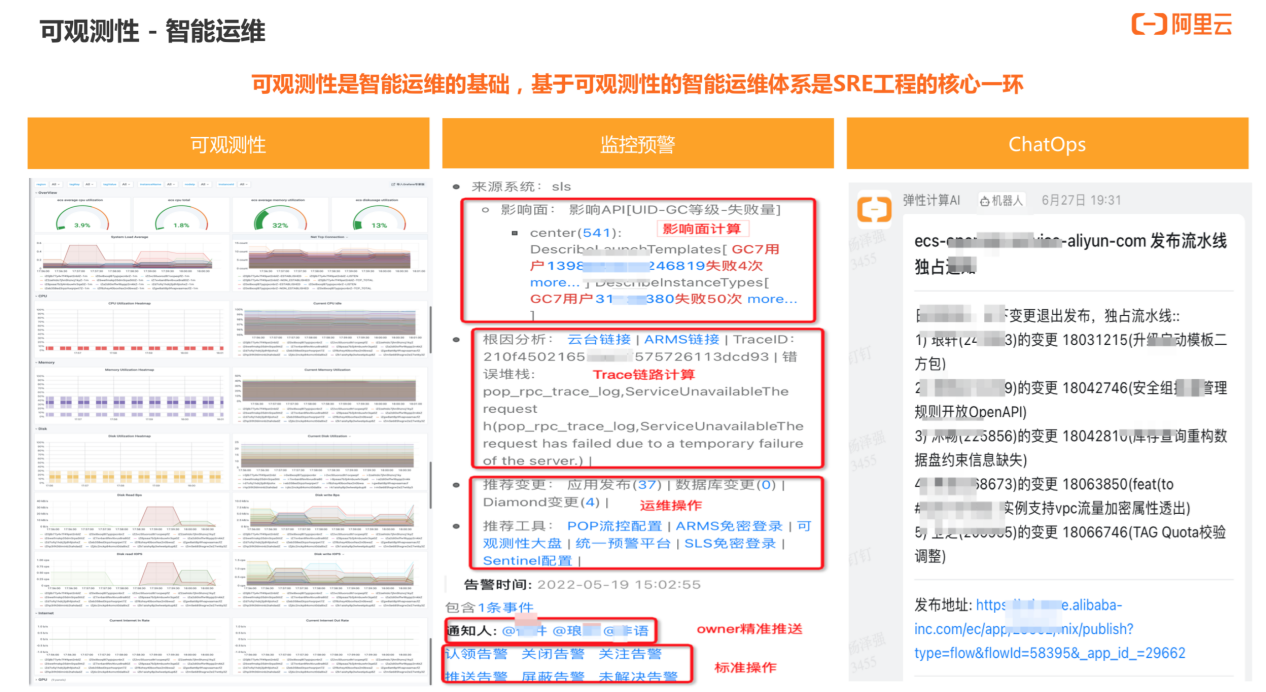
可观测性的大部分应用场景是运维场景,比如查看容量、水位、预警等指标。上图为上云之后可观测性在运维方面的应用。
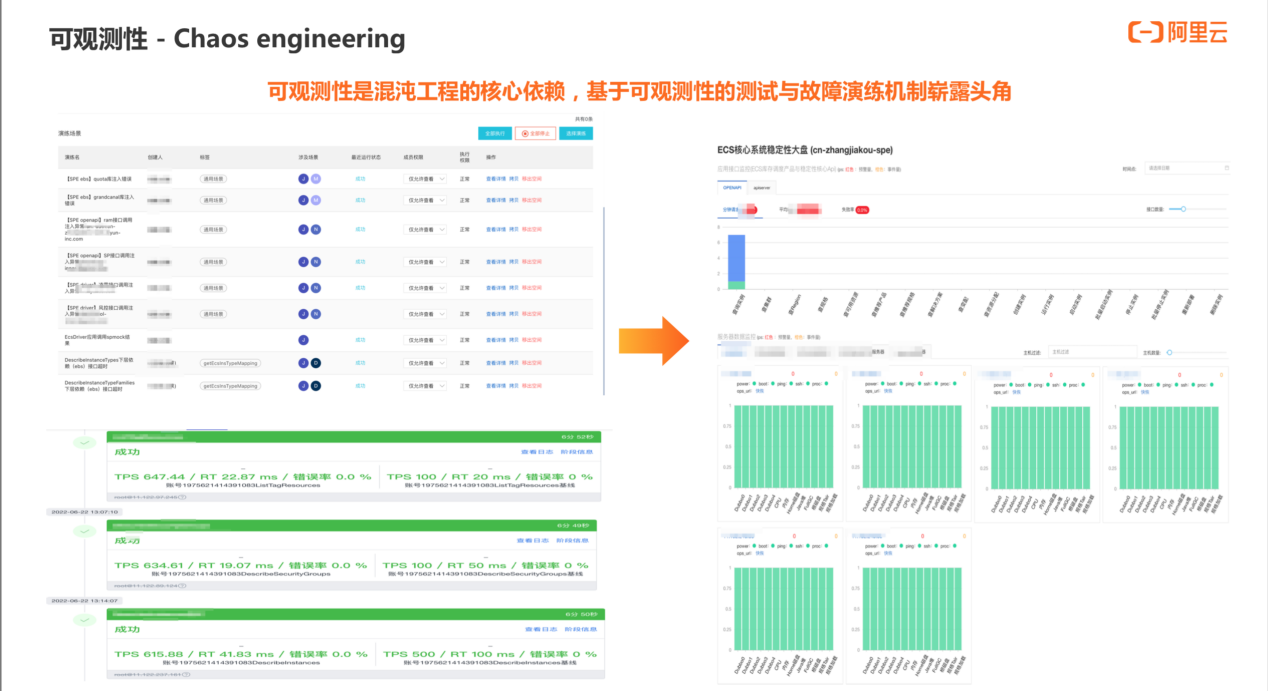
此外,可观测性还可运用于混沌工程,它是混沌工程的核心依赖。混沌工程的核心是故障演练机制,对服务注入故障,以查看是否出现异常。注入故障的前提为系统为稳态,这需要依赖于可观测性体系查看 metrics 指标来确保。其次,探索可能导致不稳定的因素时,需要通过可观测性来对比差异点,通过查看内部哪些系统、哪些环节有问题,发现内部真正隐患,实现提前的故障隐患挖掘。

成本管理和安全可观测是我们正在探索的两个场景。
如何降低成本是管理者关注的重点之一。首先需要明确当前成本,上云之后可能会有混合云场景或多云场景,需要从多个地方查看财务及数据。可以通过可观测性获取系统水位、资源消耗等情况,以进行下一步的成本优化。比如使用 SLS 会有很多日志存储,可以通过可观测性查看 SLS 使用率、哪些索引消耗资源等。
安全可观测性要求将安全前置,通过可观测性提前发现安全隐患,比如是否存在异常流量和异常攻击等,通过逐步迭代完善安全体系。
04 Future
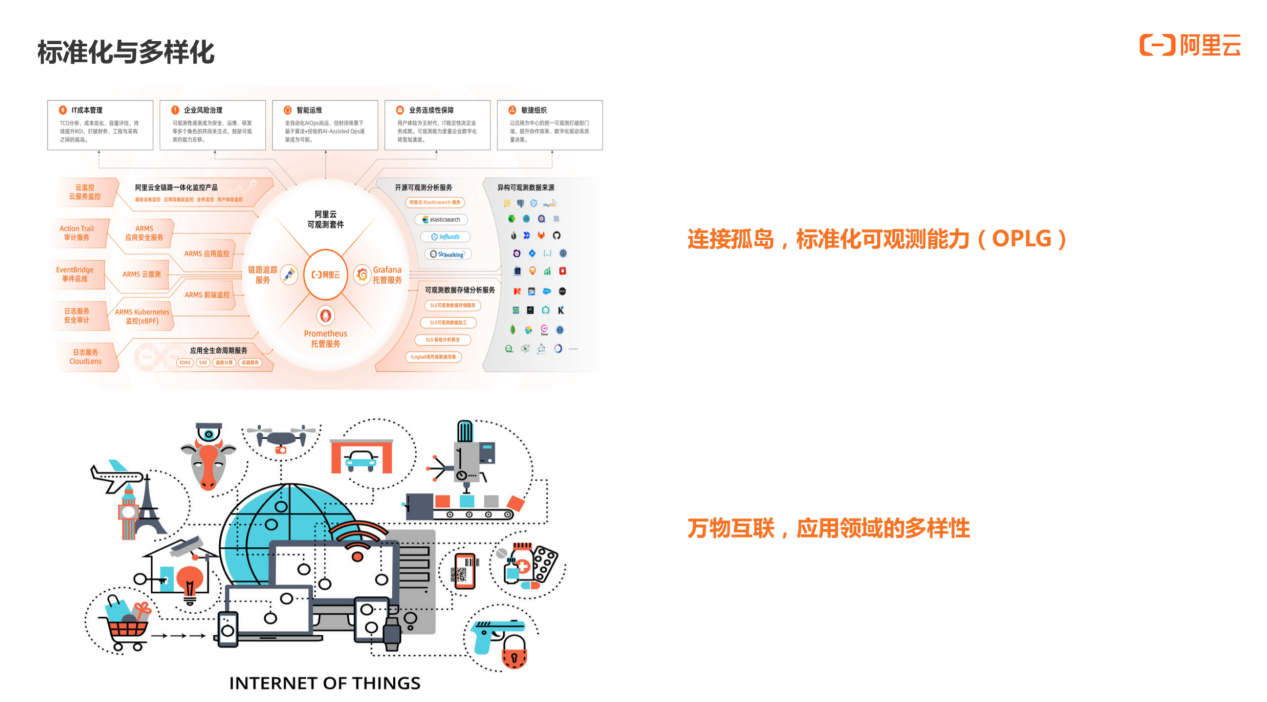
未来,可观测性的发展趋势为标准化与多样化。
可观测性将从多样化产品逐步转化为标准化的开源标准模型。Loging、metris、tracing 三个方面开源以及商业化的产品已经非常丰富。然而,可选择空间越大,做出决策或最佳实践的难度也更大。因此我们认为未来需要尽快建立可观测性的标准体系,比如 tracing 的 OpenTelemetry,metrics 的 Prometheus,多数据源展示的 Grafana。阿里云也提出了 OPLG 模型,其中 O 为 OpenTelemetry, P 为 Prometheus, L 为 Loki,G 为 Grafana。
多样化指可观测性的应用领域将呈多样性发展。从最初只观测单体应用,到后来的监控 APM 并逐渐衍生出各种各样的监控场景,实现万物可监控、可观测。
Q&A 环节,观众提问
Q1 可观测性具体应用于软件开发的哪个阶段?
答:传统的可观测性一般应用在运维阶段,关注线上的系统水位、监控运行等。而现在可观测性有左移趋势,在软件的架构设计、CI、CD 阶段都有应用,比如提供了 CI 大盘,交付和发布过程中有 metrics 指标的获取和自动化拦截。
Q2 如何获取可观测性不同维度的数据?
答:资源和平台层,开源的 eBPF 天然具备采集数据的能力,能够采集 MySQL、Redis、Kafka 流量、node 数据等。产品侧的数据需要通过一定的开发工作来采集。
Q3 阿里云的可观测体系建设使用了哪些商用产品?
答:有 SLS 和 ARMS 两个产品。SLS 既有 logging 功能,也有 trace 功能,另外它也可以构建 metrics 和 dashboard ,提供了完整的闭环。
ARMS 目前没有 logging ,只有 metrics 和 tracing,但它的优势为费用低于 SLS。另外 ARMS 提供了完整的 APM 工具链,不仅是 metric 这种数据,还有 insight 数据,比如可以看 JVM 的指标并进行分析,还提供了 Arthas 的 profile 能力以及智能识别系统异常的能力。
Q4 Prometheus、Grafana 链路与 ARMS 之间存在何种关系?
答:没有直接关系。ARMS 提供了托管 Prometheus 的服务,与 Grafana 实验室有商业合作,Grafana 的部分能力会直接托管在阿里云 ARMS 上。ARMS 基于这两个托管能力,结合其本身的链路追踪服务,可以很好地将三者进行结合,产生 1+1>2 的效果。
Q5 实现端到端监测需要统一哪些指标体系?
答:首先,链路的核心指标不能丢,包括资源、平台、应用等。其次,trace 指标也是必要的,将端到端的链路串联起来是技术难点,可以通过 OpenTelemetry、Skywalking 等产品来实现。此外,黄金三指标、 web 服务基于用户侧的拨测能力以及用户视角的可观测性路径也是必要的。以购物下单为例,用户视角的完整链路应该为从 C 端发起请求到下单完成支付整个链路相关的网关监控、支付监控、订单监控等串联而成,并且这些指标能够进行统一展示。
点击这里,观看嘉宾的演讲视频回放。
近期活动预告
【自动化,才高效——云上自动化运维 CloudOps 系列沙龙_第二弹】来袭,就在 7 月 25—28 日,敬请期待。
自动化即是通过运用工具或系统达到减少、甚至是完全取代人工的操作。在研发效能与运维工作中,自动化是降低成本、提升效率必不可少的方式,自动化还能减少人工带来的错误,提升团队满意度。因此,阿里云弹性计算云上自动化运维 CloudOps 系列沙龙,将以“自动化与智能化”作为第二弹的主题,分享相关思考与实践。
免费报名通道已经开启!即刻扫描下方海报中的二维码报名,进群还能获得最新讲师 PPT 资料。
沙龙小 Tips:观看直播时在弹幕区提出自己的疑问,被讲师抽中回答问题的同学,还会获得加湿器等精美礼品哦!同时在直播结束时填写问卷,也有机会获得便携玻璃杯等多重好礼。

标签:杨泽强,SLS,ARMS,观测,metrics,阿里,构建,监控,云上 来源: https://www.cnblogs.com/tanxingjisuan/p/16500866.html