10 Self-Attention(自注意力机制)
作者:互联网
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看
配套 github 链接:https://github.com/nickchen121/Pre-training-language-model
配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html


注意力机制
看一个物体的时候,我们倾向于一些重点,把我们的焦点放到更重要的信息上
第一眼看到这个图,不会说把所有的信息全部看完
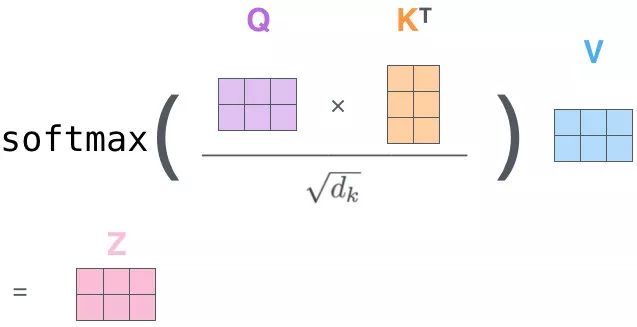
QK 相乘求相似度,做一个 scale(未来做 softmax 的时候避免出现极端情况)
然后做 Softmax 得到概率
新的向量表示了K 和 V(K==V),然后这种表示还暗含了 Q 的信息(于 Q 而言,K 里面重要的信息),也就是说,挑出了 K 里面的关键点
自-注意力机制(Self-Attention)(向量)
Self-Attention 的关键点再于,不仅仅是 K\(\approx\)V\(\approx\)Q 来源于同一个 X,这三者是同源的
通过 X 找到 X 里面的关键点
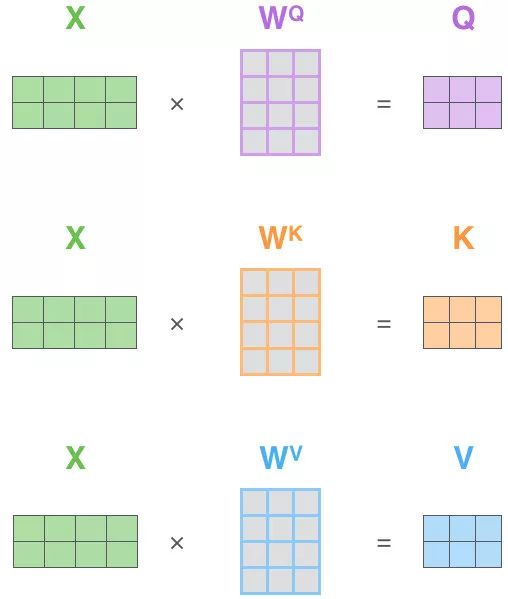
并不是 K=V=Q=X,而是通过三个参数 \(W_Q,W_K,W_V\)
接下来的步骤和注意力机制一模一样
-
Q、K、V的获取
-
-
Matmul:
-
-
Scale+Softmax:
-
-
Matmul:
-

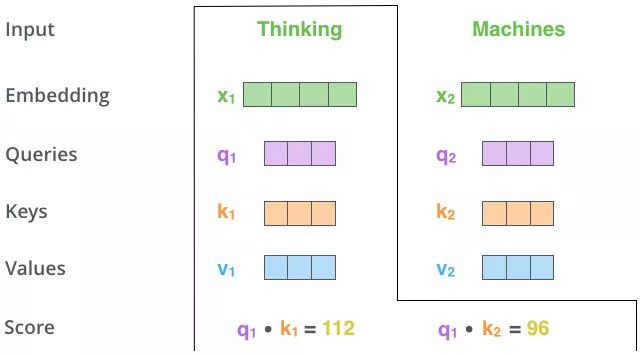


\(z_1\)表示的就是 thinking 的新的向量表示
对于 thinking,初始词向量为\(x_1\)
现在我通过 thinking machines 这句话去查询这句话里的每一个单词和 thinking 之间的相似度
新的\(z_1\)依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息
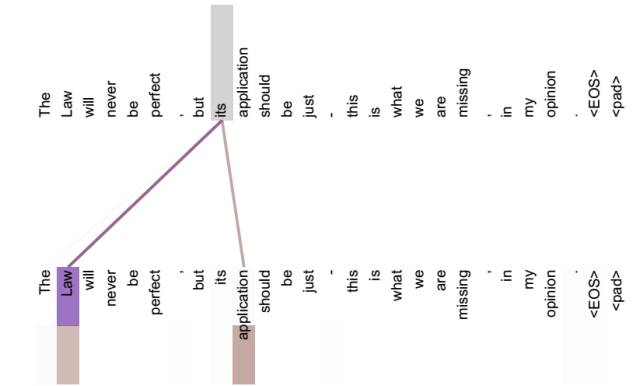
不做注意力,its 的词向量就是单纯的 its,没有任何附加信息
也就是说 its 有 law 这层意思,而通过自注意力机制得到新的 its 的词向量,则会包含一定的 laws 和 application 的信息
自注意力机制(矩阵)
标签:10,thinking,Self,Attention,信息,its,机制,注意力,向量 来源: https://www.cnblogs.com/nickchen121/p/16470711.html