06 Word2Vec模型(第一个专门做词向量的模型,CBOW和Skip-gram)
作者:互联网
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看
配套 github 链接:https://github.com/nickchen121/Pre-training-language-model
配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html
神经网络语言模型(NNLM)--》为了预测下一个词
NNLM()--》预测下一个词
神经网络+语言模型:用神经网络去解决和人说话有关的两个任务的一个东西
softmax(w2(tanh((w1x+b1)))+b2)
得到一个副产品(词向量)
Q 矩阵,对于任何一个独热编码的词向量都可以通过 Q 矩阵得到新的词向量
- 可以转换维度
- 相似词之间的词向量之间也有了关系
Word2Vec --》 为了得到词向量
神经网络语言模型--》主要目的就是为了得到词向量
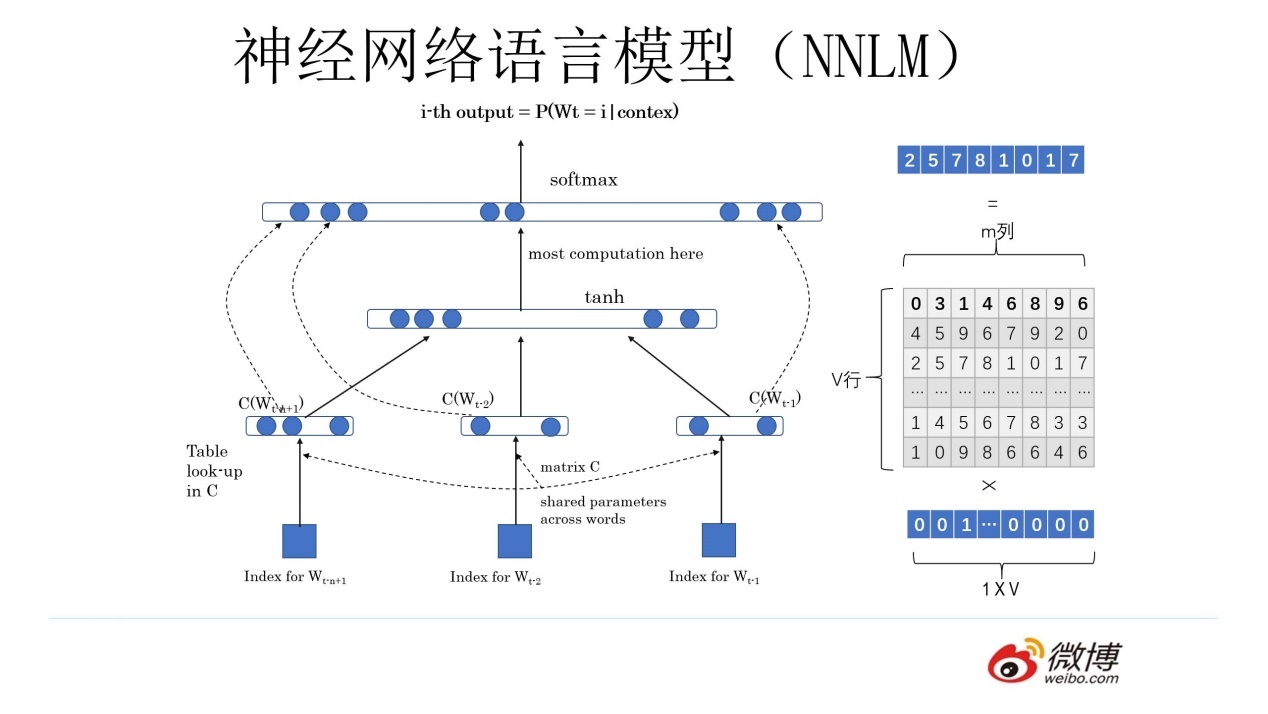

NNLM 和 Word2Vec 基本一致(一模一样),不考虑细节,网络架构就是一模一样
CBOW
给出一个词的上下文,得到这个词
“我是最_的Nick”
“帅” \(w_t\)
Skip-gram
给出一个词,得到这个词的上下文
“帅”
“我是_的Nick”
NNLM 和 Word2Vec 的区别
NNNL --》 重点是预测下一词,双层感知机softmax(w2(tanh((w1(xQ)+b1)))+b2)
Word2Vec --》 CBOW 和 Skip-gram 的两种架构的重点都是得到一个 Q 矩阵,softmax(w1 (xQ) +b1)
- CBOW:一个老师告诉多个学生,Q 矩阵怎么变
- Skip:多个老师告诉一个学生,Q 矩阵怎么变
Word2Vec的缺点
Q 矩阵的设计

00010 代表 apple × Q = 10,12,19
apple(苹果,)
假设数据集里面的 apple 只有苹果这个意思,没有这个意思(训练)
(测试,应用)10,12,19 apple, 无法表示这个意思
词向量不能进行多意 ---》 ELMO
标签:做词,Word2Vec,--,NNLM,模型,矩阵,CBOW,向量 来源: https://www.cnblogs.com/nickchen121/p/16470584.html