基于Hadoop与Spark的大数据开发概论
作者:互联网
Hadoop
什么是Hadoop?
Hadoop是一套开源的用于大规模数据集的分布式储存和处理的工具平台。他最早由Yahoo的技术团队根据Google所发布的公开论文思想用Java语言开发,现在则隶属于Apache基金会
Hadoop的核心组成
Hadoop框架主要包括三大部分:分布式文件系统、分布式计算系统、资源管理系统
-
分布式文件系统HDFS
提供高可靠性(多副本)、高扩展性(添加机器达到线性扩展)、高吞吐率的数据服务,并且可以部署在通用硬件上
原理是将数据文件以指定大小拆(默认64MB,也有128MB)分成数据块,并将数据块以副本的方式存储到多台机器上
-
分布式计算系统MapReduce (已边缘化)
MapReduce是一个编程模型,用以进行大数据量计算
MapReduce有两个核心操作:Map(映射)和Reduce(归纳)
-
资源管理系统YARN
全称为Yet Another Resource Negotiator,是一个通用资源管理系统,可为运行在YARN之上的分布式应 用程序提供统一的资源管理和调度
YARN之上可以运行各种不同的类型作业,比如:MapReduce、Spark、Tez等不同的计算框架
Hadoop生态圈
1.狭义的Hadoop:HDFS、MapReduce、YARN
- 广义的Hadoop:指以Hadoop为基础的生态圈:
- HDFS(Hadoop分布式文件管理系统)
- MapReduce(Hadoop分布式计算框架)
- YARN(Hadoop新特性)
- HBase(Hadoop分布式数据库)
- ZooKeeper
- Hive(数据仓库)
- Pig
- Sqoop(数据迁移框架,大数据离线处理辅助系统之一)
- Flume
- Oozie
- Mahout
HDFS
HDFS的优缺点
优点:
- 处理超大文件
- 运行于廉价机器上
- 流式地访问数据
缺点:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
HDFS基础
-
数据块(Block)
是HDFS最基本的存储单位,默认大小为64MB(也有些版本是128MB)
-
元数据节点(NameNode)
管理文件系统的命名空间(存储数据的数据),将所有文件与文件夹的元数据保存在一个文件系统中
- 数据节点(DataNode)
真正存储数据的地方
-
从元数据节点(Secondary NameNode)
不是元数据节点的备用节点。而是周期性地将NameNode的namespace image和edit log合并,防止日志文件过大。合并后的namespace也会在元数据节点备份一次
HDFS架构
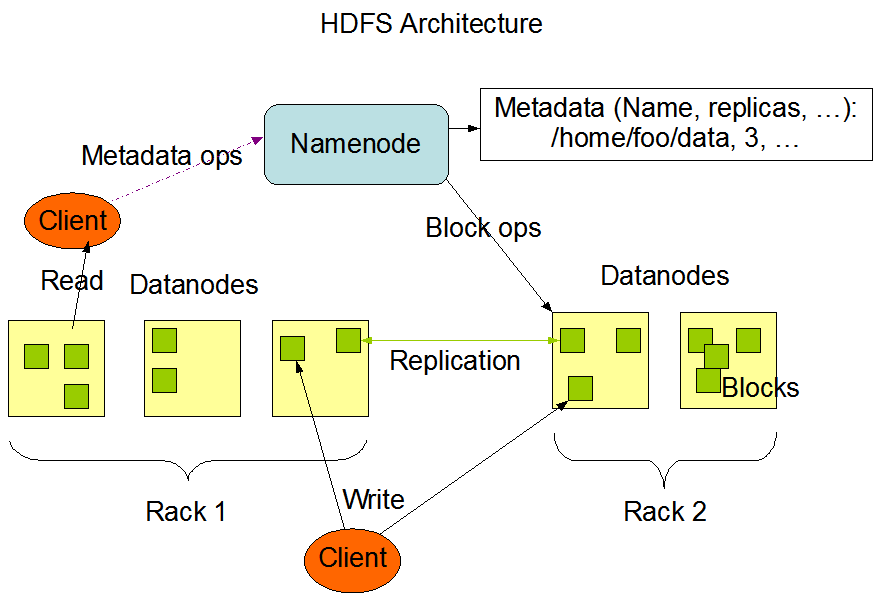
HDFS NameNode高可用机制体系架构(HDFS新特性)
1. **隔离性**:
在典型的高可用集群中,两个独立的机器作为NameNode。任何时刻,只有一个NameNode处于Active状态,另一个处于Standby状态。Active NameNode负责所有客户端操作,而Standby NameNode只是简单地充当Slave
- 共享存储系统:
Standby NameNode与Standby NameNode保存状态同步
-
主备切换控制器(ZKFailoverController):
...ZKFailoverController会在检测到主NameNode故障时借助ZooKeeper实现自动的主备选举和切换
-
DataNode节点:
...
ZooKeeper (P124)
- 分布式协调管理软件(动物园管理员),协助ZKFailoverConteroller,是HDFS NameNode高可用机制环境的必备软件(服务)之一
- 安装ZooKeeper时所有服务必须在ZK注册(MapReduce、HDFS等)
MapReduce
是一个编程模型,用以进行大数据量计算
YARN
是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,取代了以前Hadoop1.x中JobTracker的角色。并且YARN支持多种计算框架(离线计算框架MapReduce、DAG计算框架Tez、流式计算框架Storm、内存计算框架Spark),JobTracker只支持MapReduce
YARN架构
ResourceManager只管理调度资源,具体的作业控制执行都交给ApplicationMaster
YARN由Client、ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)组成,也是采用Master/Slave架构,一个ResourceManager对应多个NodeManager

图解:
Client向ResourceManager提交任务、终止任务等
ApplicationMaster由对应的应用程序完成;每一个应用程序对应一个ApplicationMaster,ApplicationMaster向RescurceManager申请资源用于在NodeManager上启动相应的任务
NodeManager通过心跳信息向ResourceManager汇报自身情况
YARN核心组件功能
- ResourceManager:整个集群只有一个,负责集群资源的统一管理调度 (类似校长)
- 处理来自客户端(Client)的请求(启动/终止应用程序)
- 启动/监控ApplicationMaster;一旦某个AM出现故障,RM将会在另一个节点上启动AM
- 监控NodeManager,接收NodeManager汇报的心跳信息并分配任务给NodeManager去执行
- NodeManager:整个集群有多个,负责单节点资源管理和使用 (类似院长)
- 周期向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态
- 接收并处理来自ResourceManager的Container启动/停止的各种命令
- 处理来自ApplicationMaster的命令
- ApplicationMaster:每个应用一个,负责应用程序的管理 (类似老师)
- ...
- Container:对运行任务环境的抽象
- ...
ResourceManager高可用机制(YARN新特性)
- 和NameNode高可用机制一模一样
- 也是需要基于ZooKeeper
HBase
Hive
-
使用MapReduce门槛高,所以产生了Hive
-
是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,可以将SQL语句转化为MapReduce任务运行,是一种可以存储、查询和分析存储在Hadoop中大规模数据的机制
-
数据仓库是一个面向主题的、集成的、随时间变化的,但信息本身相对稳定的数据集合,它用于支持企业或组织决策分析处理
Hive特点
- 可扩展:Hive可以自由扩展集群的规模,一般不需要重启服务
- 延展性:Hive支持用户自定义函数
- 容错性:即使节点出现问题SQL仍可完成执行
Hive架构
- Hive的查询性能通常很低,这是因为它会把SQL转换为运行较慢的MapReduce任务
- ...
Hive与传统关系型数据库
| Hive | RDMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据储存 | HDFS | Raw Device or Local FS |
| 执行 | MapReuce | Executor |
| 执行延迟 | 高 | 低 |
| 数据处理规模 | 大(关联100+表) | 小 |
| 索引 | 0.8版本后加入 | 有复杂的索引 |
| 数据更新 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
Hive数据存储模型
比数据库更高级
Hive所有数据都存储在HDFS中,没有专门的数据存储格式;只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据
Hive操作(代码)
在Hive控制台或者外链数据库软件里输入,HQL语句结尾要有";"
Hive DDL
// 1.创建表
CREATE [TEMPORARY][EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [COMMENT col_comment], ...)];
// 1)CREATE TABLE创建一个指定名字的表,如果表已经存在则会抛出异常,可以用IF NOT EXISTS参数选项来忽略这个异常
// 2)EXTERNAL参数会创建一个外部表
// 3)LIKE参数复制一个表结构
// 4)...
// 例子
create table emp(
empno int,empname string,empjob string,empsalary double
)row format delimited fields teminated by '\t';
// 2.修改表
// 重命名表语法
ALTER TABLE table_name RENAME TO new_table_name;
// 添加/更新列语法
ALTER TABLE table_name ADD|REPALCE COLUMNS (col_name data_type [COMMENT col_comment],...);
// ADD代表新增一个字段,字段位置在所有列后面(partition列前面)
// REPLACE则表示替换所有字段
//例子
//添加一列
alter table emp add colums (empaddress string);
//更新所有列
alter table emp replace columns (id int,name string);
// 3.显示命令
// 查看所有数据库
show databases
// 切换到数据库内
use database_name
// 查看某个数据库中的所有表
show tables
// 查看某个表的所有分区信息
show partitions
// 查看Hive支持的所以函数
show functions
// 查看表的信息
desc extended table_name;
// 查看更加详细的表信息
desc formatted table_name;
Hive DML
// 1.load
// 使用load可以将文本文件的数据加载到Hive表中
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (...)];
// 1) filepath 文件路径,可以用绝对路径或者相对路径
// 2) LOCAL参数,有就查找本地文件中的filepath,没有就根据inpath中的url查找文件,包含模式的完整URL(例 hdfs://namenode:8020/user/hive/data1)
// 3) OVERWRITE参数,覆盖原有的数据/文件
// 例子
load data local inpath '/home/hadoop/data/emp.txt' into table emp;
// 2.insert
// 将查询结果插入到hive表(支持多重插入,动态分区插入)
INSERT [OVERWRITE] TABLE table_name [PARTITION (...)] select_statement1 FORM from_statement;
// 例子
insert into table else_table partition(even_month='2022-06') select * from emp;
// 3.导出数据
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...
// LOCAL参数,有就是到本地,无就是到hdfs
// 例子
insert overwrite directory '/hivetemp/' select * from emp;
// 4.select
SELECT [ALL|DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list [HAVING condition]] [CLUSTER BY col_list|[DISTRIBUTE BY col_list][SORT BY|ORDER BY col_list]] [LIMIT number]
// 1) ORDER BY会对输入做全局排序,因此只会有一个reducer,大量数据会导致缓慢
// 2) SORT BY不是全局排序,其在数据进入reducer前会完成排序,不能保证全局有序
// 3) DISTRIBUTE BY根据指定内容将数据分到同一个reducer
// 4) CLUSTER BY = DISTRIBUTE BY + SORT BY
// 例子
select * from emp;
select empno,empname from emp;
select * from emp where deptno=10;
select empno,empsalary from emp where empsalary between 8000 and 150000;
select * from emp limit 4;
select empno,empname from emp where empname in ('张三','李四'); // in/not in
select empno,empname from emp where empname is null; // is null/is not null
// 聚合统计函数:max/min/count/sum/avg
select count(*) from emp where empsalary>10000;
select max(empsalary),avg(empsalary) from emp;
select empjob,avg(empsalary) from emp group by empjob;
// 5.join
// 多表关联查询
...
Hive shell
// 1.Hive命令行
hive [参数]
// -e 执行hql命令
// -f 执行hql文件里的命令
// 例子
hive -e 'select count(*) from emp';
hive -f select_count.hql
Spark
-
也是Apache基金会旗下的一个顶级项目,是用Scala语言开发的开源项目,社区活跃,是一个基于内存的分布式计算框架
-
Spark中的分布式编程模型是RDD(Resilient Distributed Datasets,弹性分布式数据集)
Spark优势
-
速度快:内存充足就比MapReduce快100倍以上
-
易用性:支持Java、Scala、Python、R语言进行快速开发
-
通用性:提供了一个强有力的一栈式通用的解决方案,可以完成批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、图计算(GraphX)和机器学习(MLlib),并且这些组件都可以在一个Spark程序内无缝对接、综合使用
-
随处运行:可以使用Hadoop的YARN、Mesos作为资源管理和调度
Scala
多范式的编程语言,类似Java
Scala基础
# 1.HELLO WORLD
# println是scala预定义导入的类,可以直接使用
println("Hello World!")
# 2.值和变量
# 值(val)赋值后不可用改变;变量(var)赋值后可以改变
val MAX:Int = 100
var name:String = "Hello!"
-
常用数据类型
Scala与Java有相同的数据类型
数据类型 描述 Byte Short Int Long Float Double Char String Boolean Unit 表示无值,和其他语言void一样,用作不返回任何结果的方法的结果类型 Null Nothing Any AnyRef Scala函数定义
// 在Scala中使用def关键字定义函数 // def 函数名(参数名:参数类型...):返回值类型={函数体} def addXY(x:Int,y:Int):Int={ x + y // 函数最后一行就是返回值,不需要return } // 无返回值函数定义 // def 函数名(参数名:参数类型){函数体} def sayHello(){ println("Hello!") }Scala面向对象操作
...
...
...
Spark RDD
-
RDD是弹性分布式数据集,具备容错特性,能在并行计算中高效地进行数据共享进而提升计算性能。RDD中提供了一些转换操作,在转换过程中记录“血统”关系,但在RDD中并不会存储真实的数据,只是对数据和操作的描述
-
RDD是只读的、分区记录的集合。RDD只能基于稳定于物理存储中的数据集和其他已经有的RDD执行确定性操作来创建
-
RDD有三种算子:转换算子、动作算子、控制算子
RDD特性
- 一系列的分区(Partition)信息。对于RDD来说,每一个分区都会被一个任务处理,这决定了并行度。用户可以在创建RDD时指定RDD的分区个数
- 由一个函数计算每一个分片
- RDD之间有依赖关系
- Partitioner是RDD中的分区函数,类似于Hadoop中的Partitioner,可以使得数据安装一定规则分配到指定的Reducer上去处理
- 最佳位置列表
RDD的创建
// 1.由集合创建RDD
val rdd = sc.parallelize(List(1,2,3,4,5))
rdd.count // 显示rdd内容
val rdd = sc.parallelize(List(1,2,3,4,5),5) // 指定创建的RDD拥有5个分区
// 2.加载文件成RDD
val distFile = sc.textFile("file:///home/hadoop/data/hello.txt")
distFile.count
// 同样可以指定分区数量
RDD的转换算子
-
RDD中的所有转换都不会直接计算结果,只是记录了作用于RDD上的操作,只有遇到一个动作算子(Action)时才会计算
-
常用的RDD转换算子
转换算子 描述 map(func) filter(func) flatMap(func) mapPartitions(func) sample(...) union(otherDataset) distinct([numTasks]) groupByKey(numTasks) reduceByKey(func,[numTasks]) sortByKey([ascending],[numTasks]) join(otherDataset,[numTasks]) cogroup(otherDataset,[numTasks]) cartesian(otherDataset) -
map算子
map对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD,新旧RDD每个元素都是一一对应的
val a = sc.parallelize(1 to 9) val b = a.map(x=>x*2) // 简化写法(_*2) a.collect b.collect // map也可以把Key变成Key-Value对 val a = sc.parallelize(List("dog","lion","cat","eagle","panda")) val b = a.map(x=>(x,1)) b.collect -
filter算子
对元素进行过滤,对每个元素应用函数,返回值为true的元素保留在RDD中,返回值为false的将被过滤掉
val a = sc.parallelize(1 to 10) // _%2==0相当于x=>x%2==0(?) a.filter(_%2==0).collect // 求偶数 a.filter(_<4).collect // 求小于4的数 -
mapValues算子
原RDD中的Key保持不变,与新的Value一起组成新的RDD元素(旧的Key不变,只改变Value值)。因此该算子只适用于为键值对元素的RDD
val a = sc.parallelize(List("doge","popcat","cheems")) val b = a.map(x=>(x.length,x)) b.mapValues("x"+_+"x").collect // 等同于y=>"x"+y+"x"
RDD的动作算子
-
本质上是在动作算子中通过SparkContext执行提交作业的runJob操作,触发了RDD DAG的执行,就是说使用动作算子会导致RDD直接执行立刻计算
-
常用的RDD动作算子
动作算子 描述 reduce(func) collect() count() first() take(n) takeSample(withReplacement,num,seed) saveAsTextFile(path) saveAsSequenceFile(path) countByKey() foreach(func)
-
collect
返回RDD中所有的元素到Driver端,打印在控制台
-
count
返回RDD中元素的数量
-
reduce
根据函数,对RDD中元素进行两两计算,返回计算结果
-
first
返回RDD中第一个元素,不排序
-
take
返回RDD中前n个元素,不排序
-
lookup
用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值
-
最值
返回最大、最小值
-
保存RDD数据到文件系统
-
标签:...,Hadoop,Hive,RDD,select,Spark,概论,emp 来源: https://www.cnblogs.com/aoner/p/16428935.html