章节十二:协程
作者:互联网
章节十二:协程
目录1. 复习回顾
照旧来回顾上一关的知识点!上一关我们学习如何将爬虫的结果发送邮件,和定时执行爬虫。
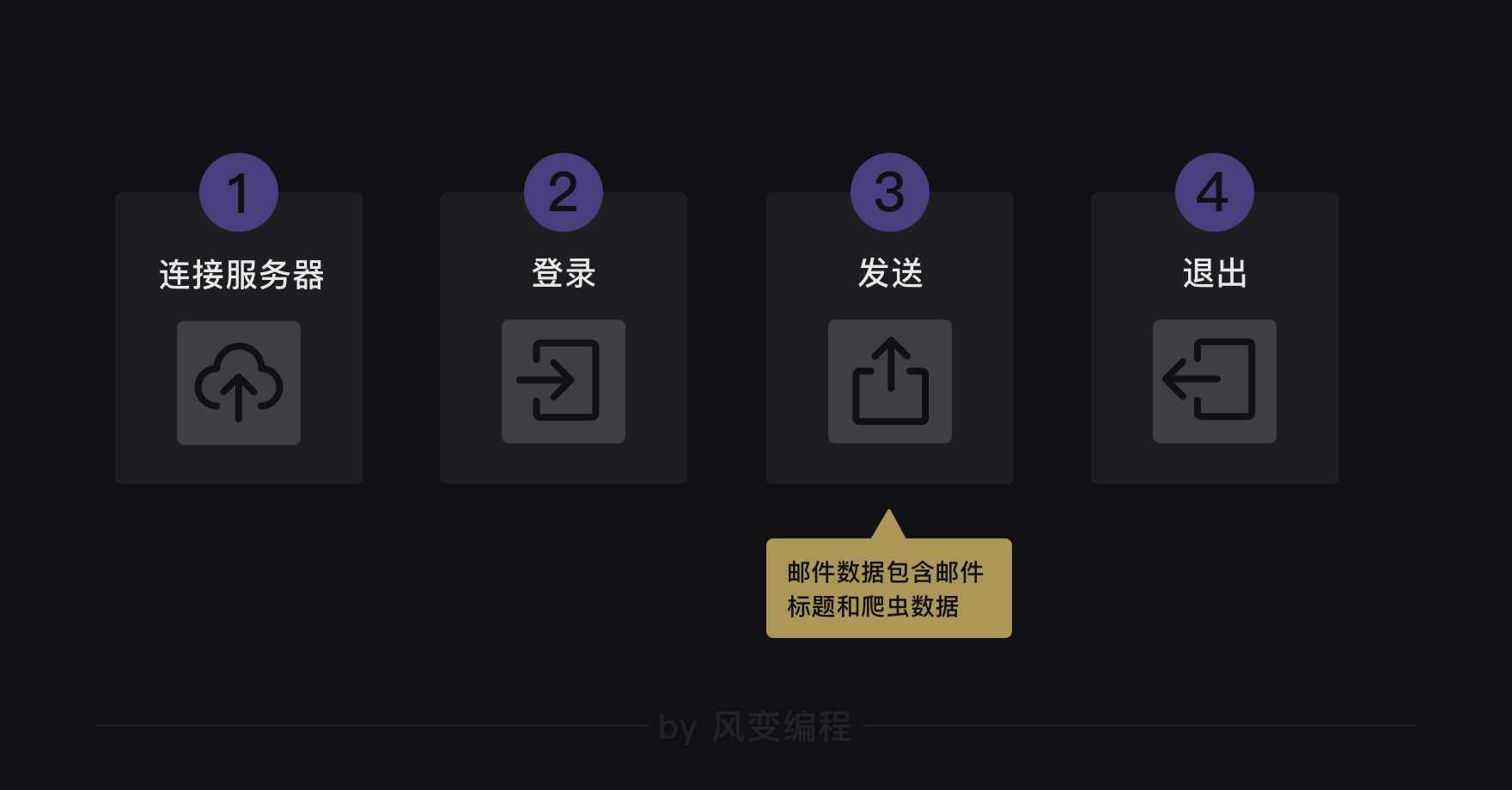
关于邮件,它是这样一种流程:

我们要用到的模块是smtplib和email,前者负责连接服务器、登录、发送和退出的流程。后者负责填输邮件的标题与正文。
最后一个示例代码,是这个模样:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMETex和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
对于定时,我们选取了schedule模块,它的用法非常简洁,官方文档里是这样讲述:
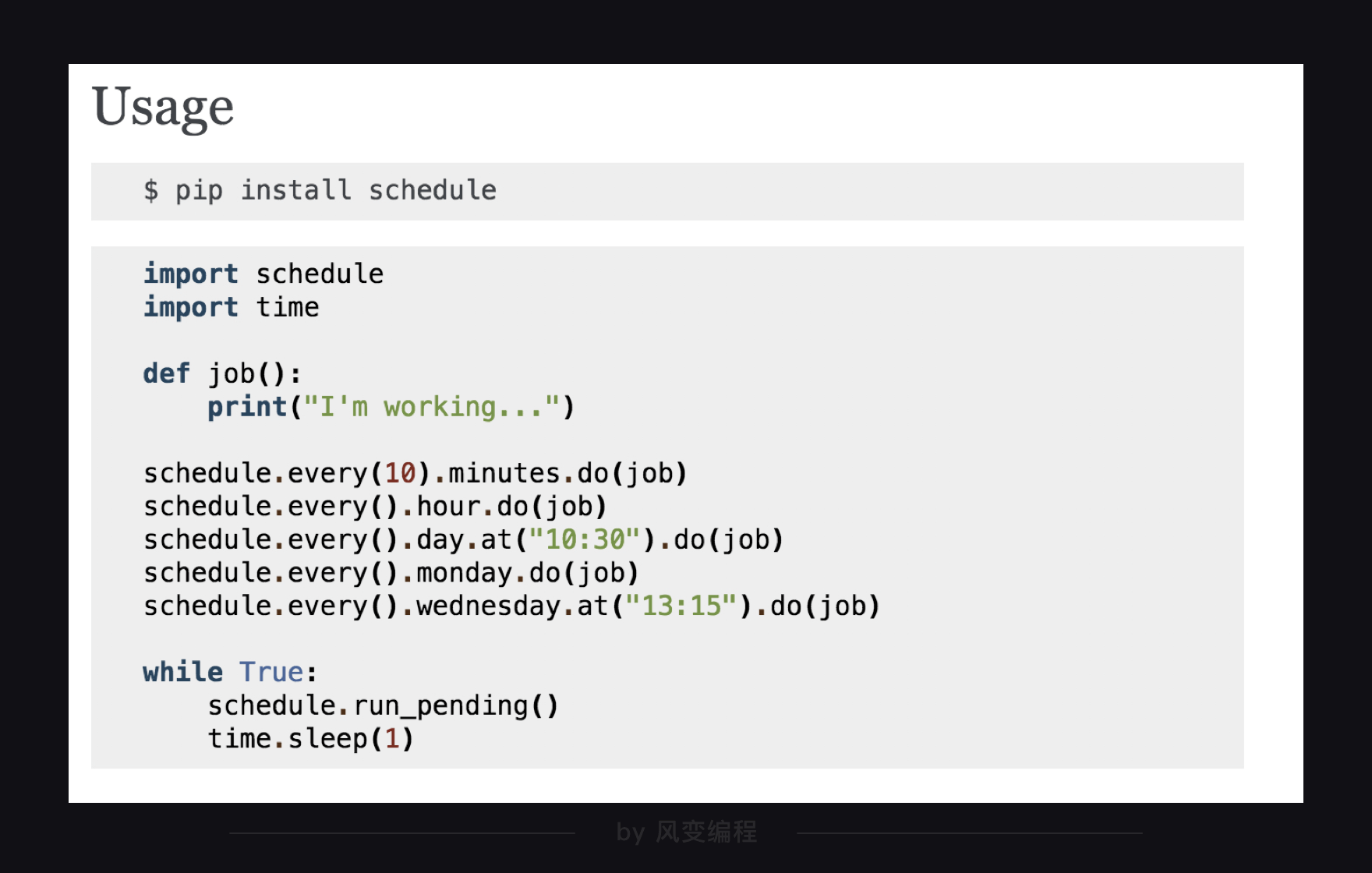
下面的代码是示例:
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
2. 协程是什么
我们已经做过不少爬虫项目,不过我们爬取的数据都不算太大,如果我们想要爬取的是成千上万条的数据,那么就会遇到一个问题:因为程序是一行一行依次执行的缘故,要等待很久,我们才能拿到想要的数据。
既然一个爬虫爬取大量数据要爬很久,那我们能不能让多个爬虫一起爬取?
这样无疑能提高爬取的效率,就像一个人干不完的活儿,组个团队一起干,活一下被干完了。
这是一个很好的思路——让多个爬虫帮我们干活。但具体怎么用Python实现这事呢?
我们可以先别急着想怎么实现这件事,后面我会跟你说。
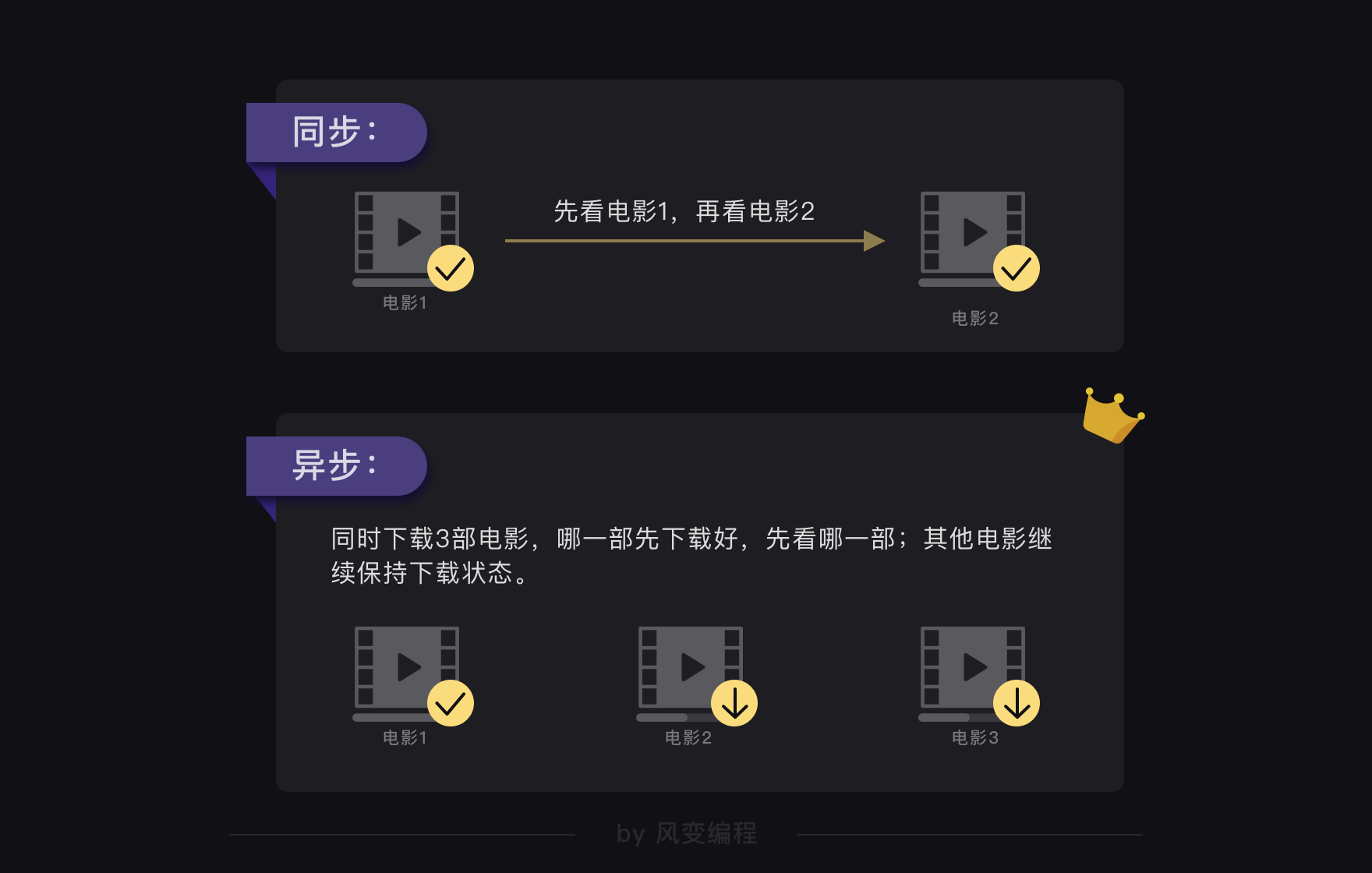
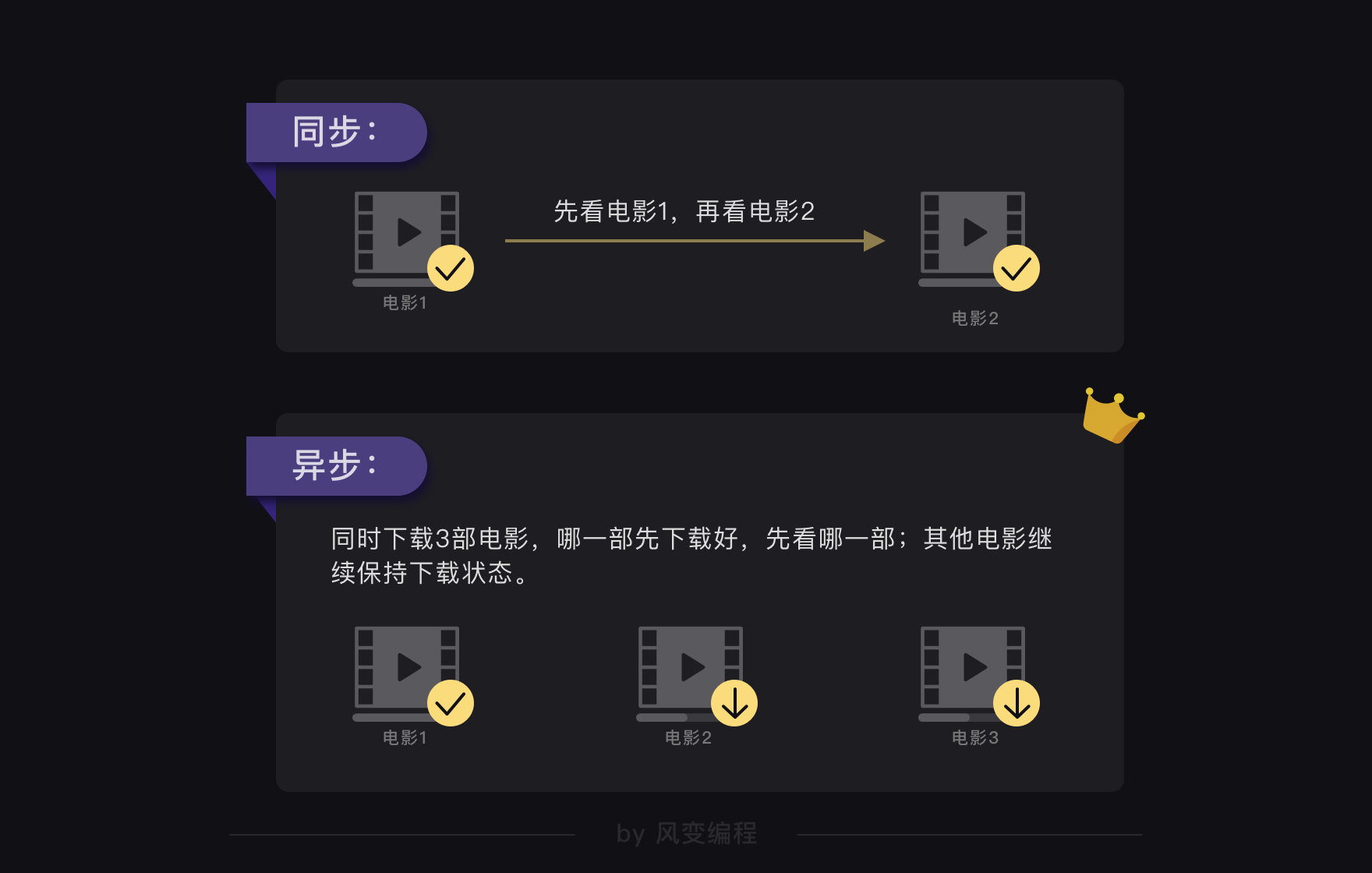
现在,你先跟我想象一个情景:

相信你肯定会这么做:把三部电影都点击下载。看哪一部先下载好了,就先看哪一部,让还没有下载完的电影持续保持下载状态。
如果用计算机里的概念来解释这件事的话:在一个任务未完成时,就可以执行其他多个任务,彼此不受影响(在看第一部下载好的电影时,其他电影继续保持下载状态,彼此之间不受影响),叫异步。
有异步的概念,那应该也有同步的概念吧?是的,同步就是一个任务结束才能启动下一个(类比你看完一部电影,才能去看下一部电影)。
显然,异步执行任务会比同步更加节省时间,因为它能减少不必要的等待。如果你需要对时间做优化,异步是一个很值得考虑的方案。
如果我们把同步与异步的概念迁移到网络爬虫的场景中,那我们之前学的爬虫方式都是同步的。
爬虫每发起一个请求,都要等服务器返回响应后,才会执行下一步。而很多时候,由于网络不稳定,加上服务器自身也需要响应的时间,导致爬虫会浪费大量时间在等待上。这也是爬取大量数据时,爬虫的速度会比较慢的原因。

那我们是不是可以采取异步的爬虫方式,让多个爬虫在执行任务时保持相对独立,彼此不受干扰,这样不就可以免去等待时间?显然这样爬虫的效率和速度都会提高。
怎样才能实现异步的爬虫方式,提高爬虫的效率呢?要回答这个问题的话,得了解一点点计算机的历史小知识。
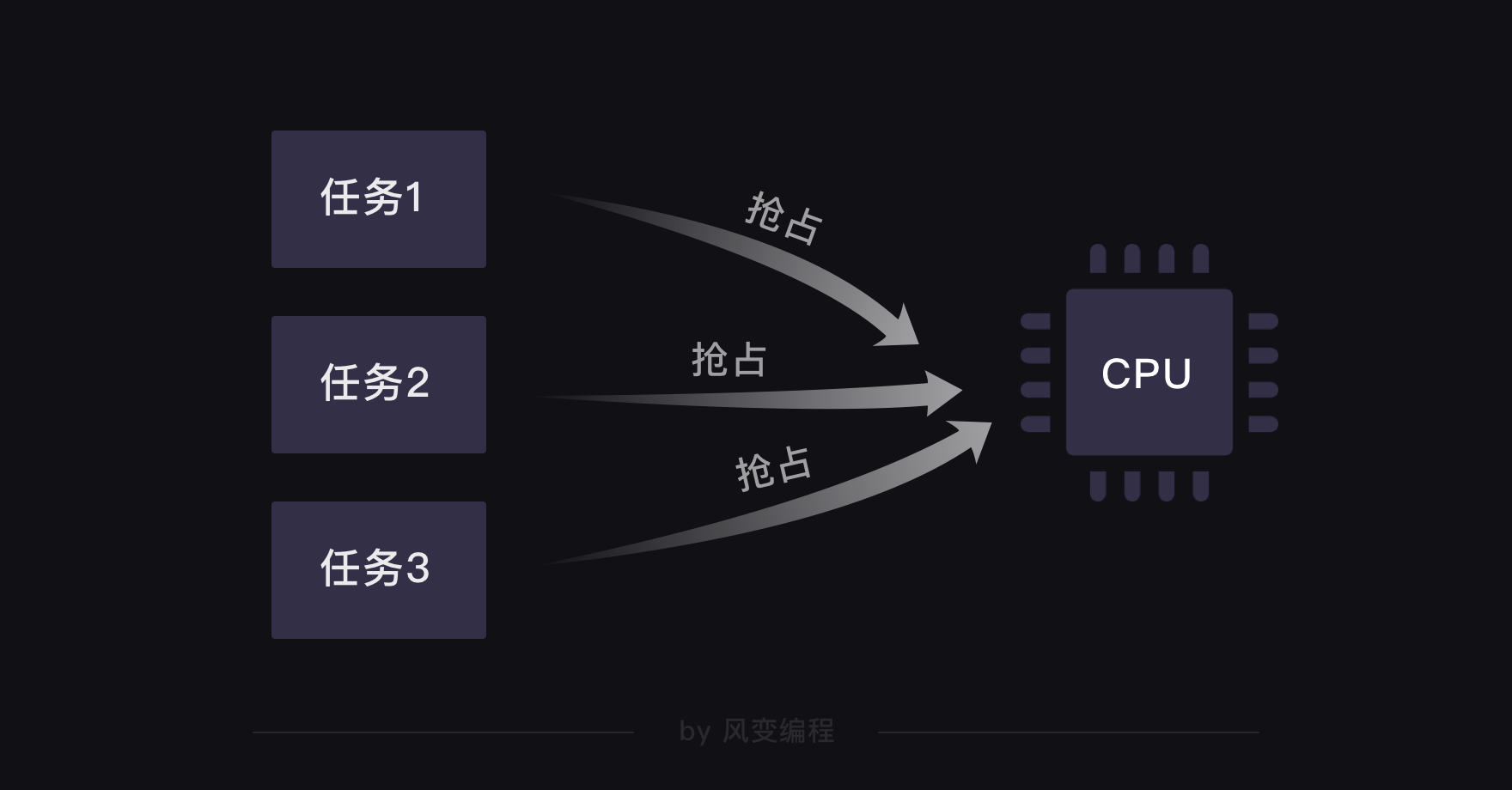
我们知道每台计算机都靠着CPU(中央处理器)干活。在过去,单核CPU的计算机在处理多任务时,会出现一个问题:每个任务都要抢占CPU,执行完了一个任务才开启下一个任务。CPU毕竟只有一个,这会让计算机处理的效率很低。
为了解决这样的问题,一种非抢占式的异步技术被创造了出来,这种方式叫多协程(在此,多是多个的意思)。
它的原理是:一个任务在执行过程中,如果遇到等待,就先去执行其他的任务,当等待结束,再回来继续之前的那个任务。在计算机的世界,这种任务来回切换得非常快速,看上去就像多个任务在被同时执行一样。
这就好比当你要做一桌饭菜,你可以在等电饭煲蒸饭的时候去炒菜。而不是等饭做好,再去炒菜。你还是那个你,但工作时间就这样被缩短了。多协程能够缩短工作时间的原理,也是如此。
所以,要实现异步的爬虫方式的话,需要用到多协程。在它的帮助下,我们能实现前面提到的“让多个爬虫替我们干活”。
那么,新的问题来了——怎么使用多协程?
3. 多协程的用法
3.1 gevent库

所以,接下来我会带你了解gevent的用法,和实操一个多协程案例:爬取8个网站(包括百度、新浪、搜狐、腾讯、网易、爱奇艺、天猫、凤凰)。
我们先用之前同步的爬虫方式爬取这8个网站,然后等下再和gevent异步爬取做一个对比。
请你先认真看一遍左边的代码,再点击运行。
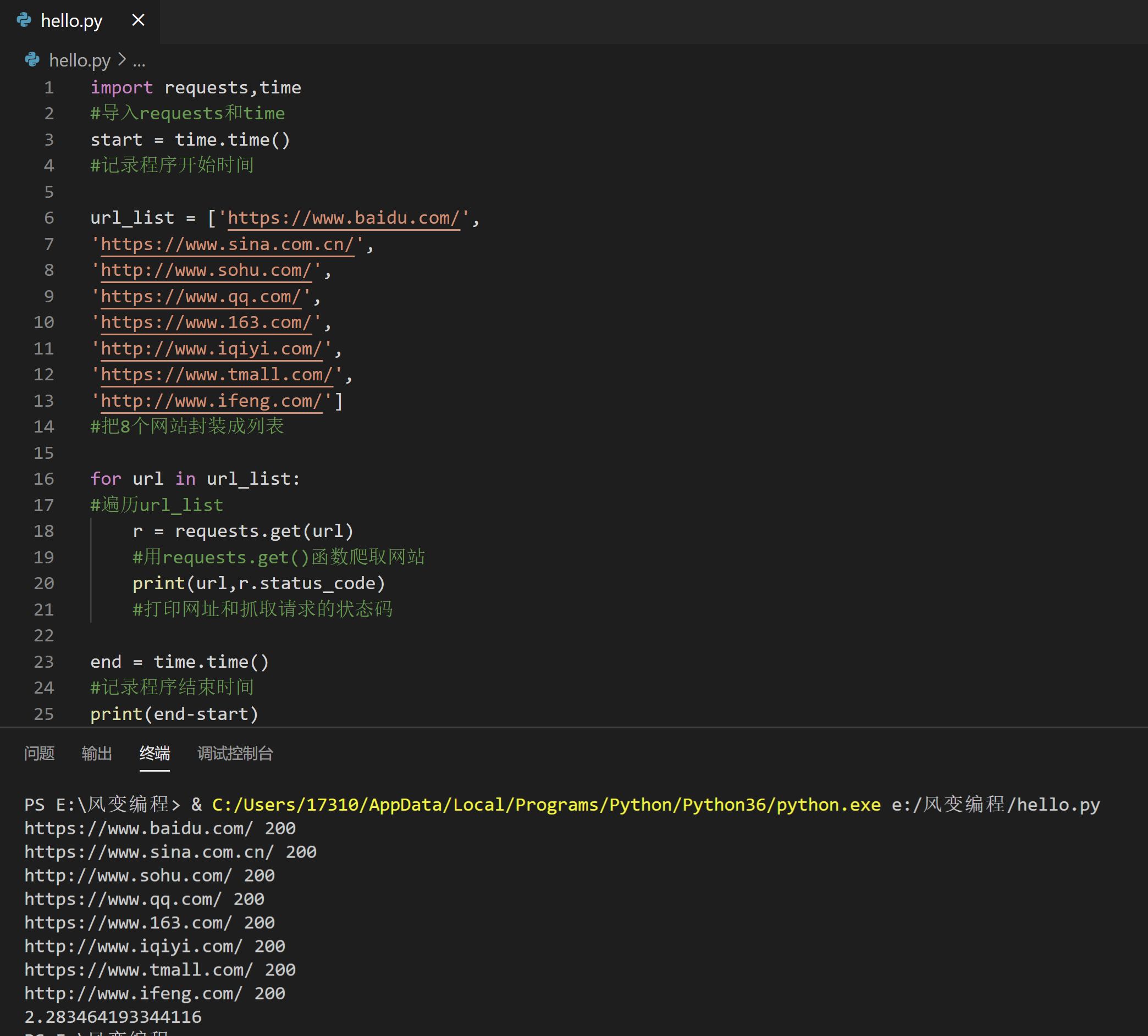
import requests,time
#导入requests和time
start = time.time()
#记录程序开始时间
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
#把8个网站封装成列表
for url in url_list:
#遍历url_list
r = requests.get(url)
#用requests.get()函数爬取网站
print(url,r.status_code)
#打印网址和抓取请求的状态码
end = time.time()
#记录程序结束时间
print(end-start)
#end-start是结束时间减去开始时间,就是最终所花时间。
#最后,把时间打印出来。
程序运行后,你会看到同步的爬虫方式,是依次爬取网站,并等待服务器响应(状态码为200表示正常响应)后,才爬取下一个网站。比如第一个先爬取了百度的网址,等服务器响应后,再去爬取新浪的网址,以此类推,直至全部爬取完毕。
为了让你能更直观地看到爬虫完成任务所需的时间,我导入了time模块,记录了程序开始和结束的时间,最后打印出来的就是爬虫爬取这8个网站所花费的时间。
如果我们用了多协程来爬取会有什么不同?
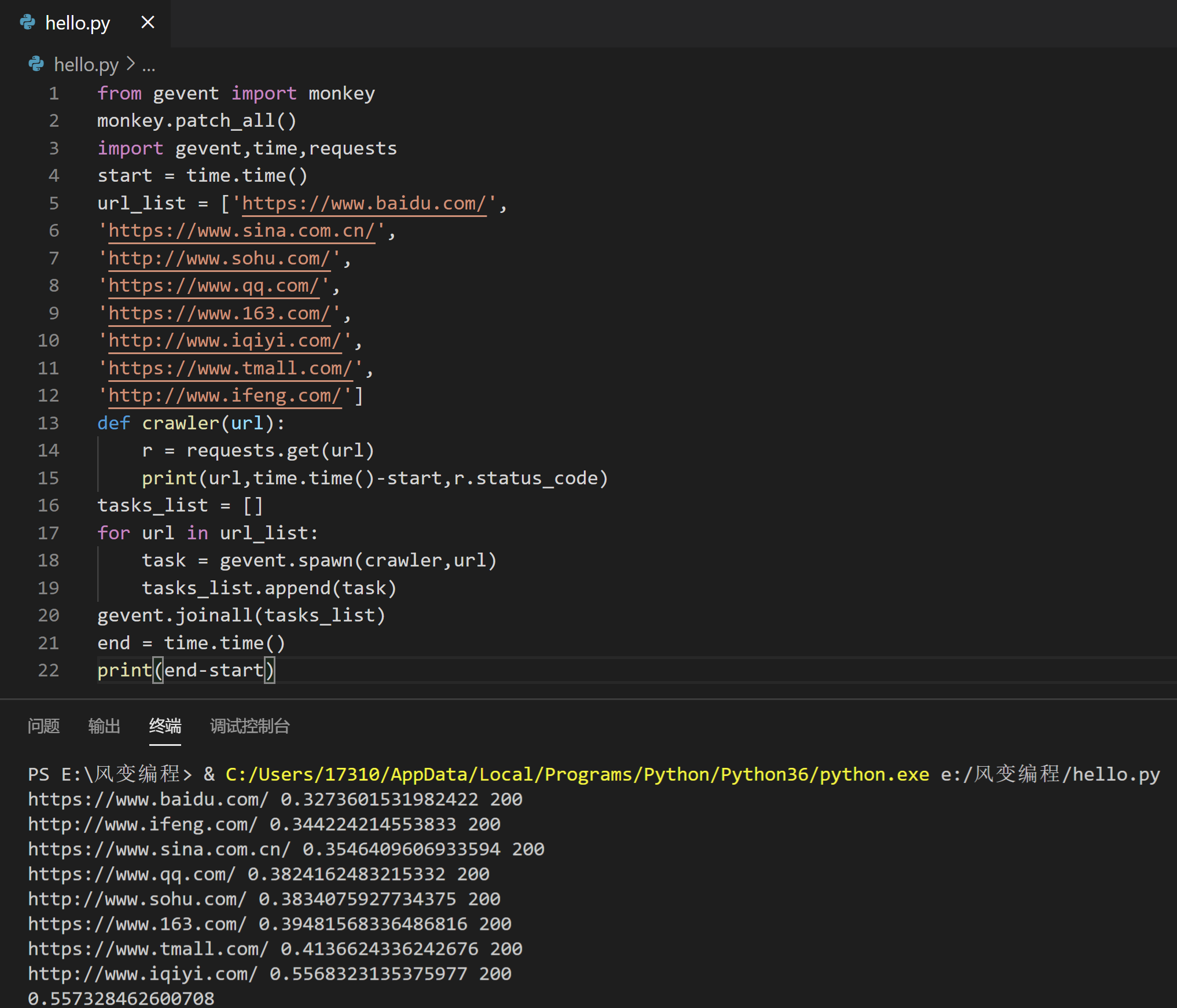
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
def crawler(url):
r = requests.get(url)
print(url,time.time()-start,r.status_code)
tasks_list = []
for url in url_list:
task = gevent.spawn(crawler,url)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
程序运行后,打印出了网址、每个请求运行的时间、状态码和爬取8个网站最终所用时间。
通过每个请求运行的时间,我们能知道:爬虫用了异步的方式抓取了8个网站,因为每个请求完成的时间并不是按着顺序来的。
且每个请求完成时间之间的间隔都非常短,你可以看作这些请求几乎是“同时”发起的。
通过对比同步和异步爬取最终所花的时间,用多协程异步的爬取方式,确实比同步的爬虫方式速度更快。
其实,我们案例爬取的数据量还比较小,不能直接体现出更大的速度差异。如果爬的是大量的数据,运用多协程会有更显著的速度优势。
比如我做了一个测试:把爬取8个网站变成爬取80个网站,用同步的爬取方式大概需要花17.3秒,但用多协程异步爬取只需大概4.5秒,整个爬取效率提升了280%+。

现在,我们一行行来看刚刚用了gevent的代码。
提醒:导入gevent库前,得先安装它。课程的终端是已经安装好了。但如果你想要在自己本地电脑操作的话,就需要在本地上安装。(安装方法:window电脑:在终端输入命令:pip install gevent,按下enter键;mac电脑:在终端输入命令:pip3 install gevent,按下enter键)
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests。
start = time.time()
#记录程序开始时间。
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
#把8个网站封装成列表。
def crawler(url):
#定义一个crawler()函数。
r = requests.get(url)
#用requests.get()函数爬取网站。
print(url,time.time()-start,r.status_code)
#打印网址、请求运行时间、状态码。
tasks_list = [ ]
#创建空的任务列表。
for url in url_list:
#遍历url_list。
task = gevent.spawn(crawler,url)
#用gevent.spawn()函数创建任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
#记录程序结束时间。
print(end-start)
#打印程序最终所需时间。
上面代码涉及到gevent的语法,有些可能你还看不懂,不要慌,我跟你一个个具体解释一遍。
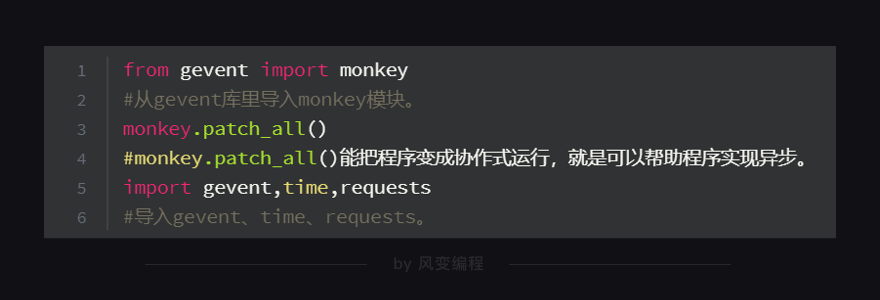
第1、3行代码:从gevent库里导入了monkey模块,这个模块能将程序转换成可异步的程序。monkey.patch_all(),它的作用其实就像你的电脑有时会弹出“是否要用补丁修补漏洞或更新”一样。它能给程序打上补丁,让程序变成是异步模式,而不是同步模式。它也叫“猴子补丁”。
我们要在导入其他库和模块前,先把monkey模块导入进来,并运行monkey.patch_all()。这样,才能先给程序打上补丁。你也可以理解成这是一个规范的写法。
第5行代码:我们导入了gevent库来帮我们实现多协程,导入了time模块来帮我们记录爬取所需时间,导入了requests模块帮我们实现爬取8个网站。
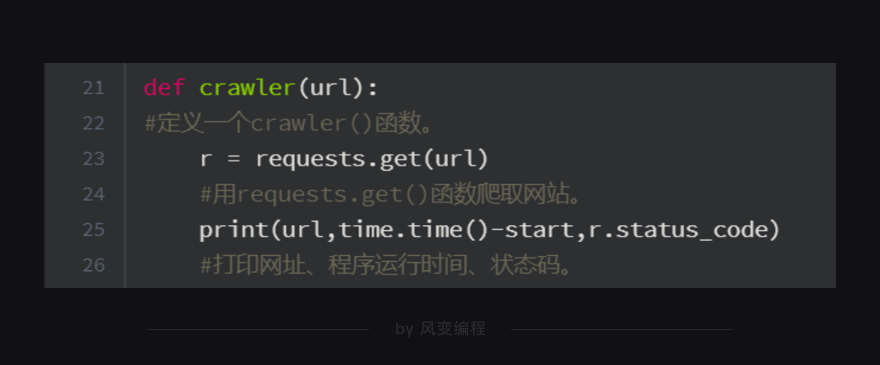
第21、23、25行代码:我们定义了一个crawler函数,只要调用这个函数,它就会执行【用requests.get()爬取网站】和【打印网址、请求运行时间、状态码】这两个任务。
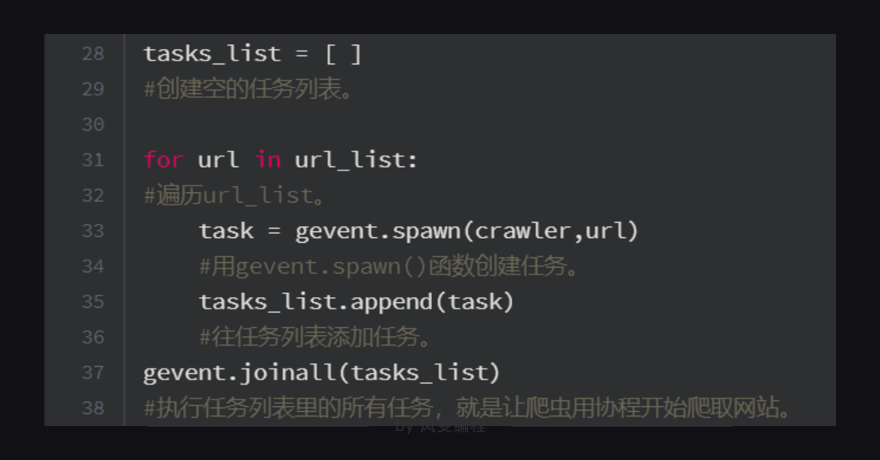
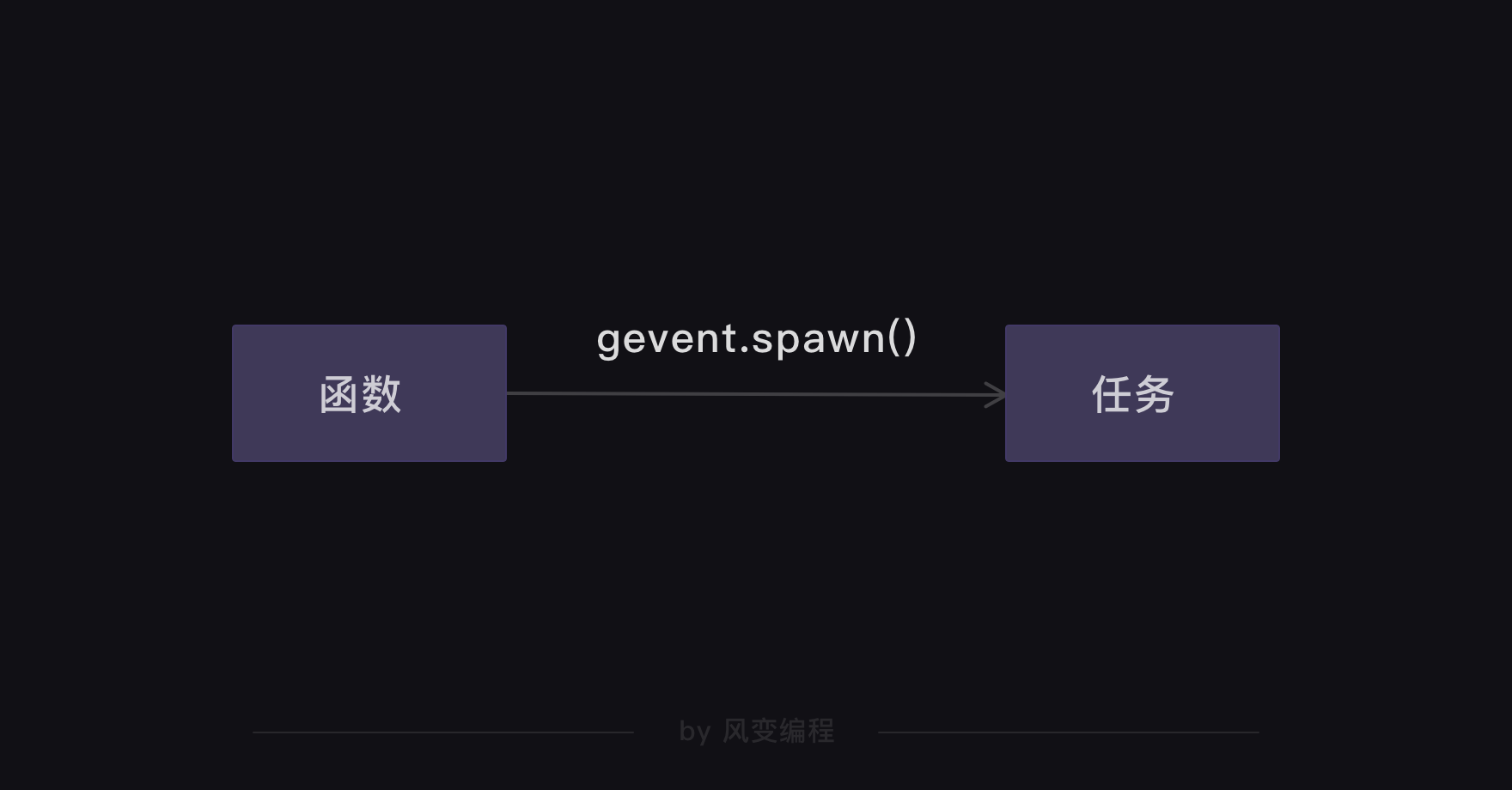
第33行代码:因为gevent只能处理gevent的任务对象,不能直接调用普通函数,所以需要借助gevent.spawn()来创建任务对象。
这里需要注意一点:gevent.spawn()的参数需为要调用的函数名及该函数的参数。比如,gevent.spawn(crawler,url)就是创建一个执行crawler函数的任务,参数为crawler函数名和它自身的参数url。
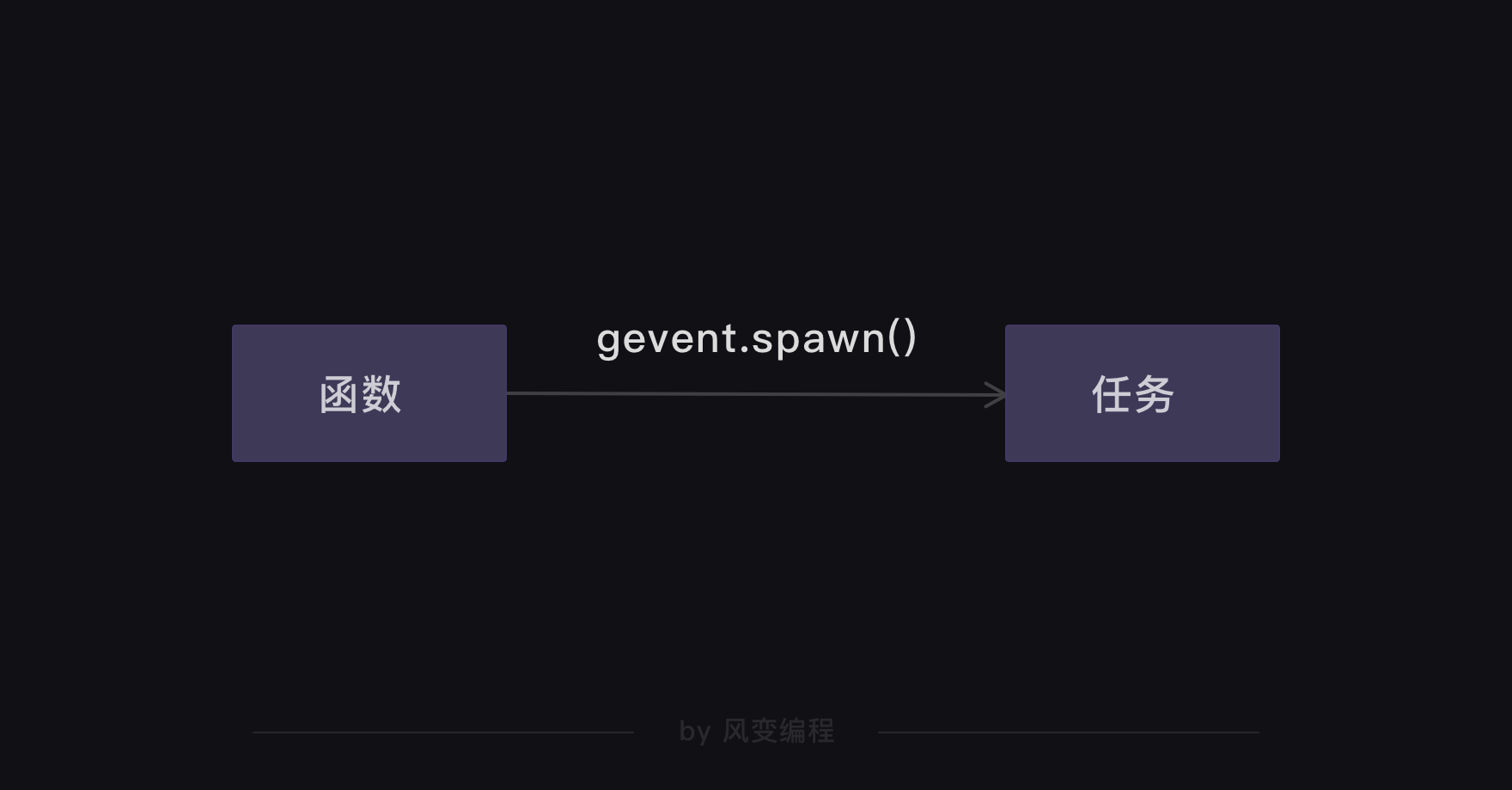
第35行代码:用append函数把任务添加到tasks_list的任务列表里。
第37行代码:调用gevent库里的joinall方法,能启动执行所有的任务。gevent.joinall(tasks_list)就是执行tasks_list这个任务列表里的所有任务,开始爬取。

总结一下用gevent实现多协程爬取的重点:

到这里,用gevent实操抓取8个网站我们已经完成,gevent的基础语法我们也大致了解。
那如果我们要爬的不是8个网站,而是1000个网站,我们可以怎么做?
用我们刚刚学的gevent语法,我们可以用gevent.spawn()创建1000个爬取任务,再用gevent.joinall()执行这1000个任务。
但这种方法会有问题:执行1000个任务,就是一下子发起1000次请求,这样子的恶意请求,会拖垮网站的服务器。

既然这种直接创建1000个任务的方式不可取,那我们能不能只创建成5个任务,但每个任务爬取200个网站?
遗憾地告诉你,这么做也还是会有问题的。就算我们用gevent.spawn()创建了5个分别执行爬取200个网站的任务,这5个任务之间是异步执行的,但是每个任务(爬取200个网站)内部是同步的。
这意味着:如果有一个任务在执行的过程中,它要爬取的一个网站一直在等待响应,哪怕其他任务都完成了200个网站的爬取,它也还是不能完成200个网站的爬取。
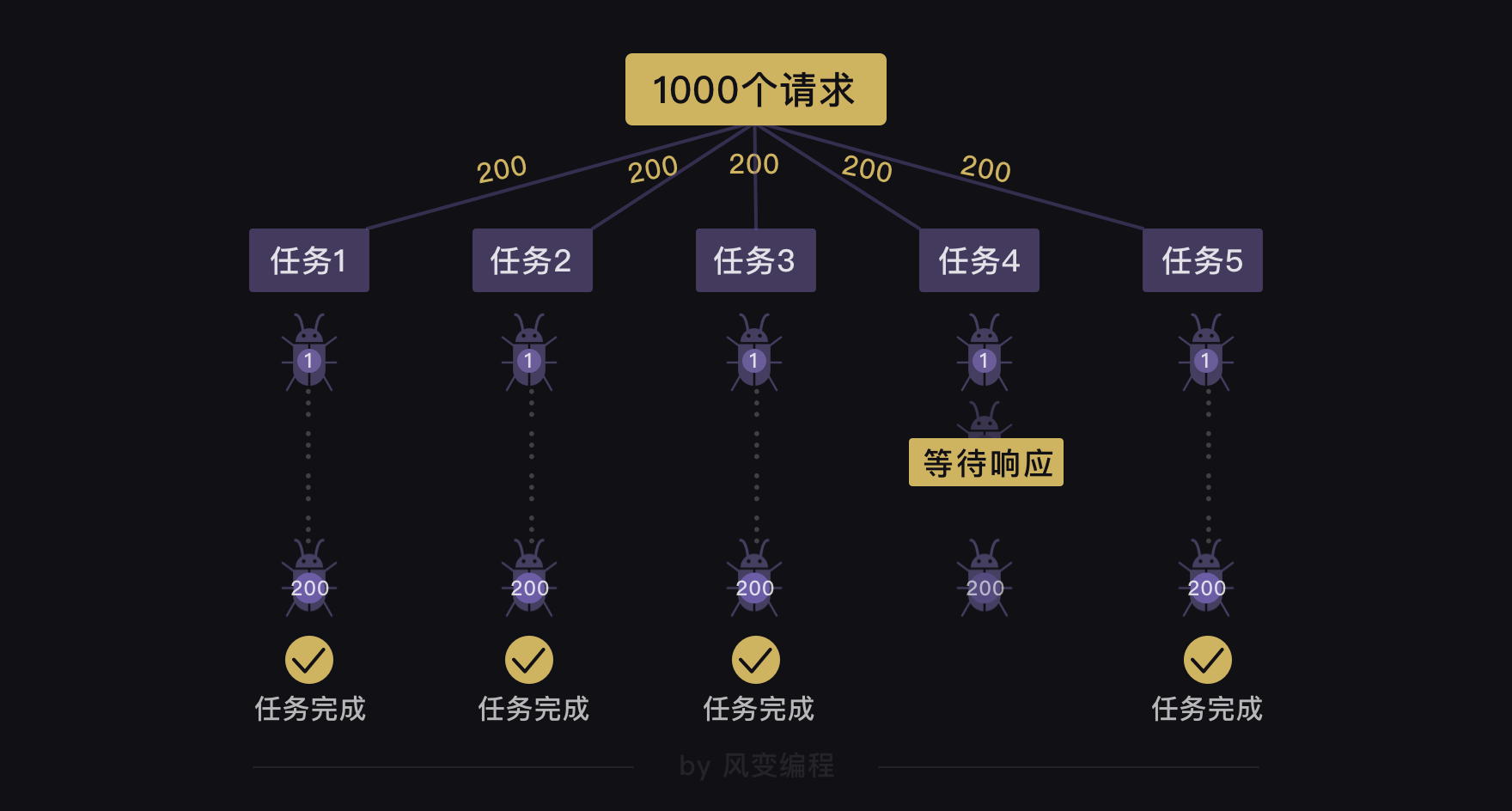
这个方法也不行,那还有什么方法呢?
这时我们可以从实际生活的案例中得到启发。想想银行是怎么在一天内办理1000个客户的业务的。
银行会开设办理业务的多个窗口,让客户取号排队,由银行的叫号系统分配客户到不同的窗口去办理业务。
在gevent库中,也有一个模块可以实现这种功能——queue模块。
3.2 queue模块
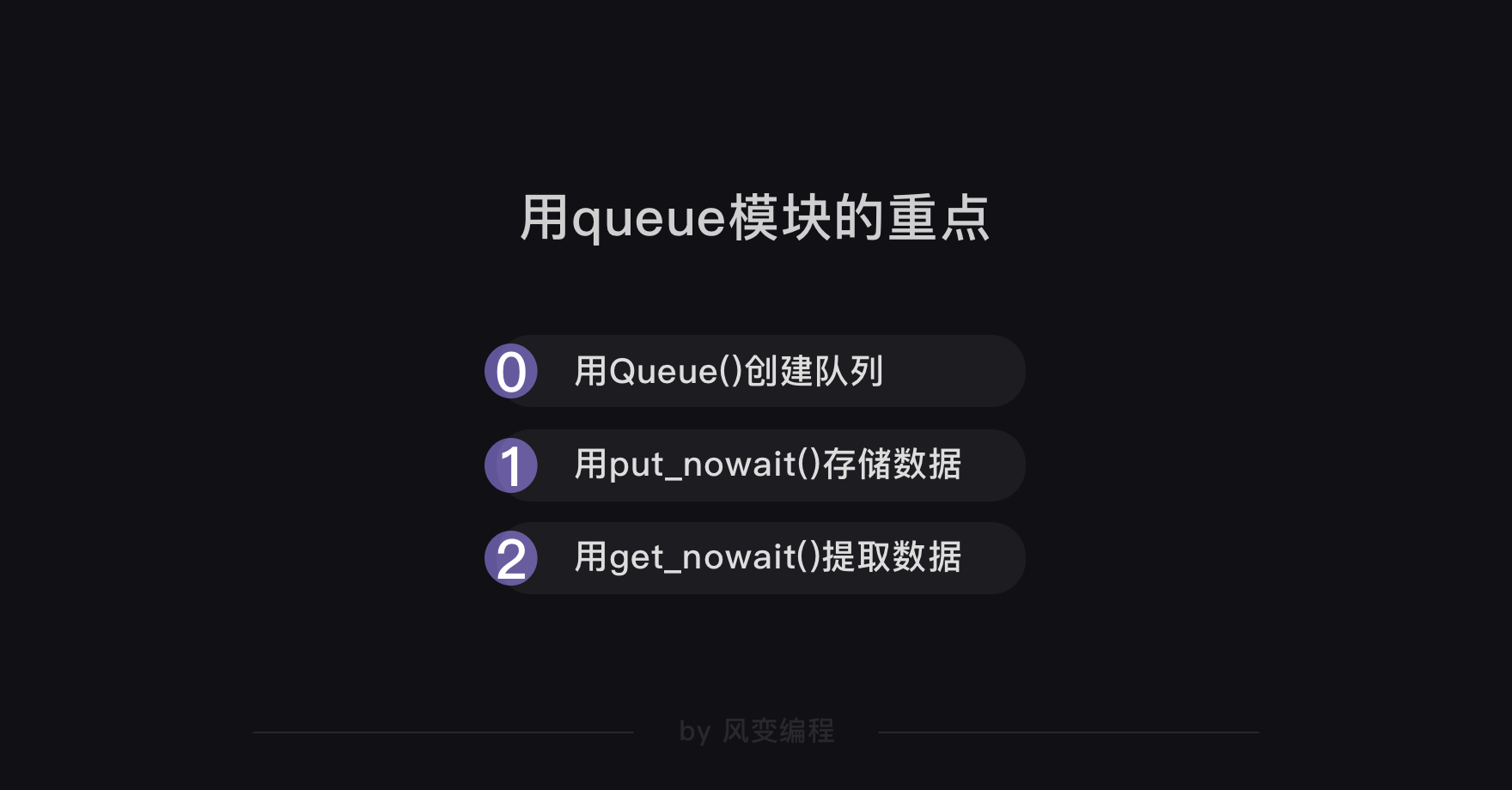
当我们用多协程来爬虫,需要创建大量任务时,我们可以借助queue模块。
queue翻译成中文是队列的意思。我们可以用queue模块来存储任务,让任务都变成一条整齐的队列,就像银行窗口的排号做法。因为queue其实是一种有序的数据结构,可以用来存取数据。
这样,协程就可以从队列里把任务提取出来执行,直到队列空了,任务也就处理完了。就像银行窗口的工作人员会根据排号系统里的排号,处理客人的业务,如果已经没有新的排号,就意味着客户的业务都已办理完毕。
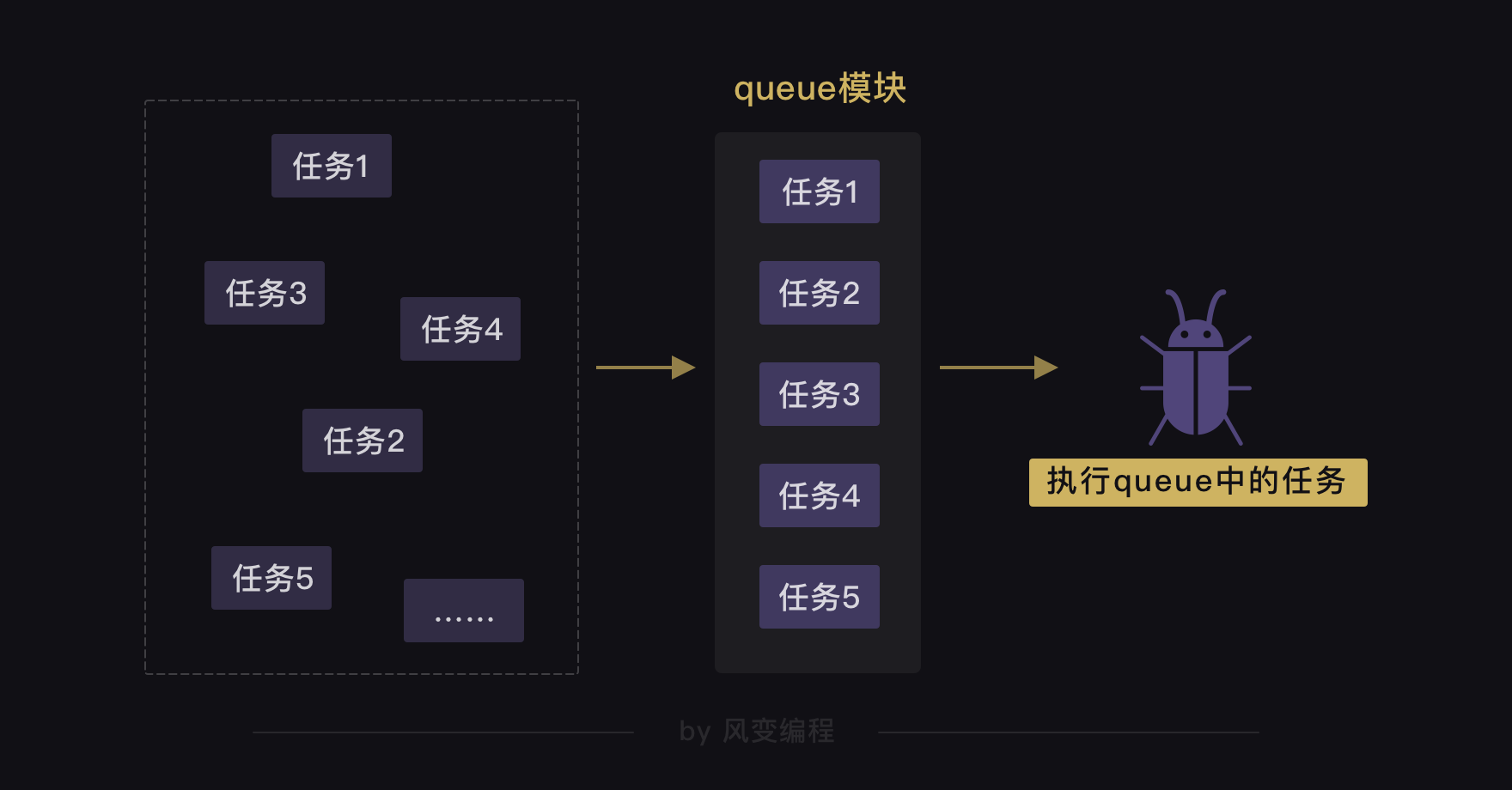
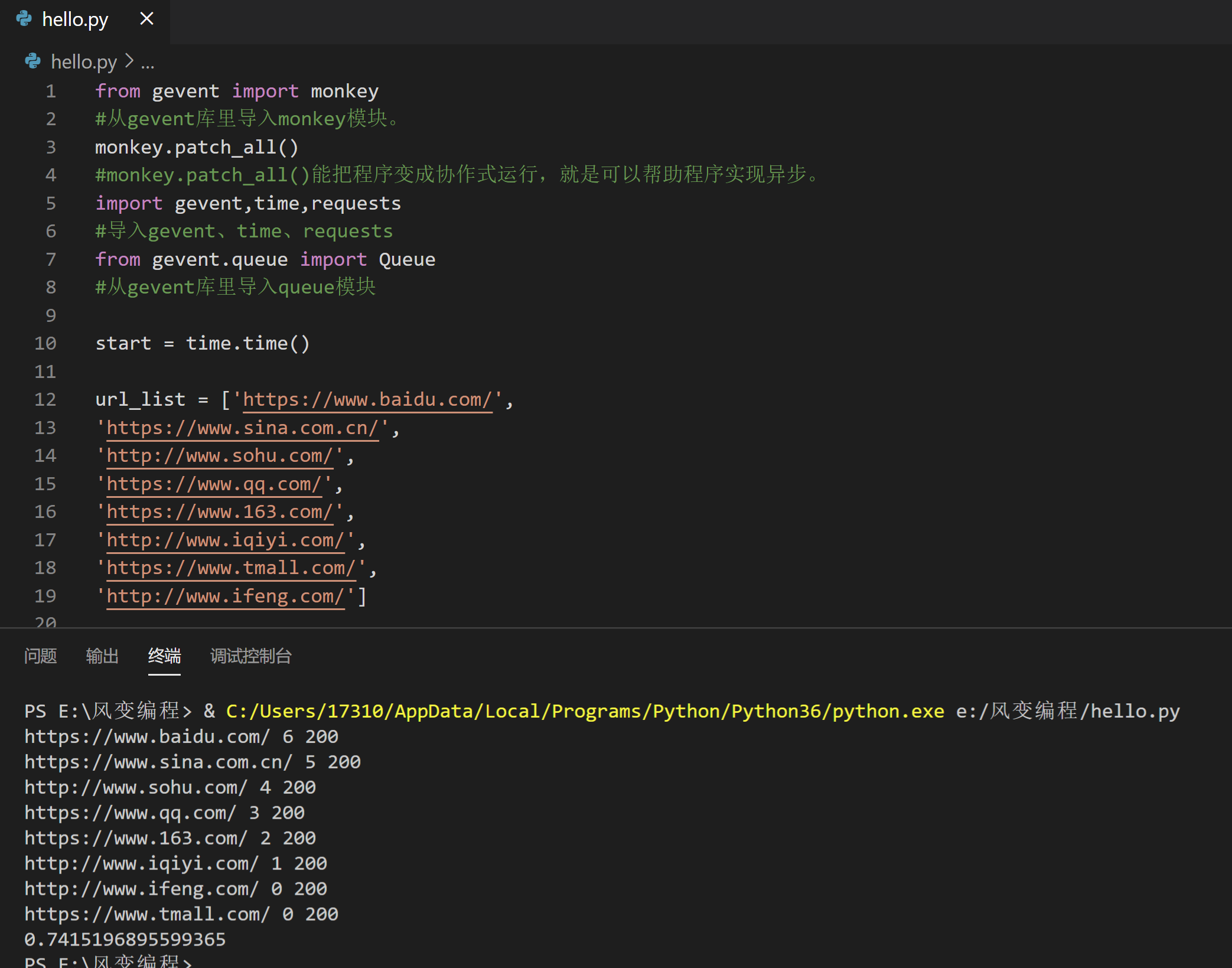
接下来,我们来实操看看,可以怎么用queue模块和协程配合,依旧以抓取8个网站为例。
from gevent import monkey
monkey.patch_all()
import gevent,time,requests
from gevent.queue import Queue
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
for url in url_list:
work.put_nowait(url)
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
for x in range(2):
task = gevent.spawn(crawler)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
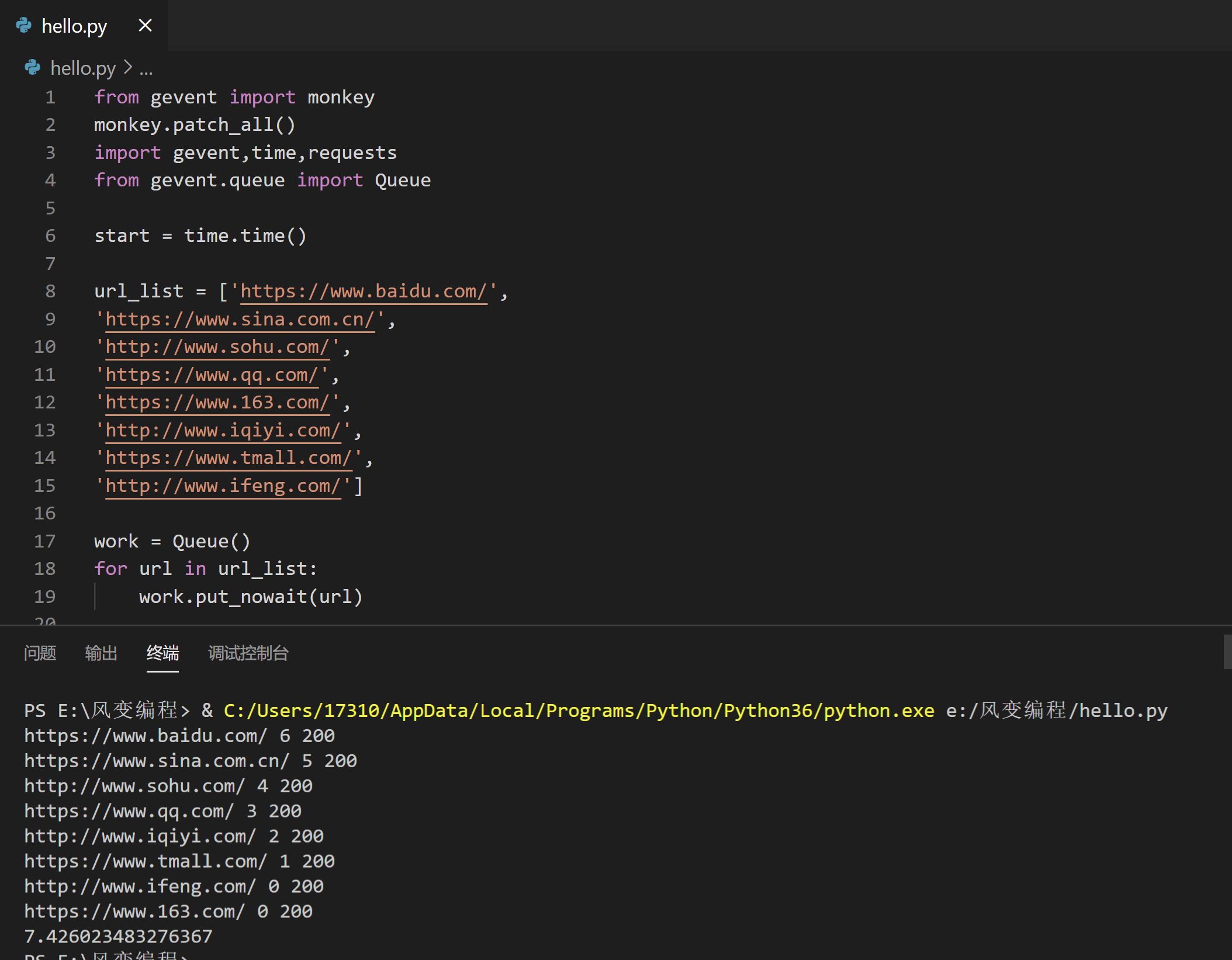
网址后面的数字指的是队列里还剩的任务数,比如第一个网址后面的数字6,就是此时队列里还剩6个抓取其他网址的任务。
现在,我们把刚刚运行的代码拆成4部分来讲解,第1部分是导入模块。
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests
from gevent.queue import Queue
#从gevent库里导入queue模块
因为gevent库里就带有queue,所以我们用【from gevent.queue import Queue】就能把queue模块导入。其他模块和代码我们在讲解gevent时已经讲解过了,相信你能懂。
第2部分,是如何创建队列,以及怎么把任务存储进队列里。
start = time.time()
#记录程序开始时间
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
#创建队列对象,并赋值给work。
for url in url_list:
#遍历url_list
work.put_nowait(url)
#用put_nowait()函数可以把网址都放进队列里。
用Queue()能创建queue对象,相当于创建了一个不限任何存储数量的空队列。如果我们往Queue()中传入参数,比如Queue(10),则表示这个队列只能存储10个任务。
创建了queue对象后,我们就能调用这个对象的put_nowait方法,把我们的每个网址都存储进我们刚刚建立好的空队列里。
work.put_nowait(url)这行代码就是把遍历的8个网站,都存储进队列里。
第3部分,是定义爬取函数,和如何从队列里提取出刚刚存储进去的网址。
def crawler():
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()函数可以把队列里的网址都取出。
r = requests.get(url)
#用requests.get()函数抓取网址。
print(url,work.qsize(),r.status_code)
#打印网址、队列长度、抓取请求的状态码。
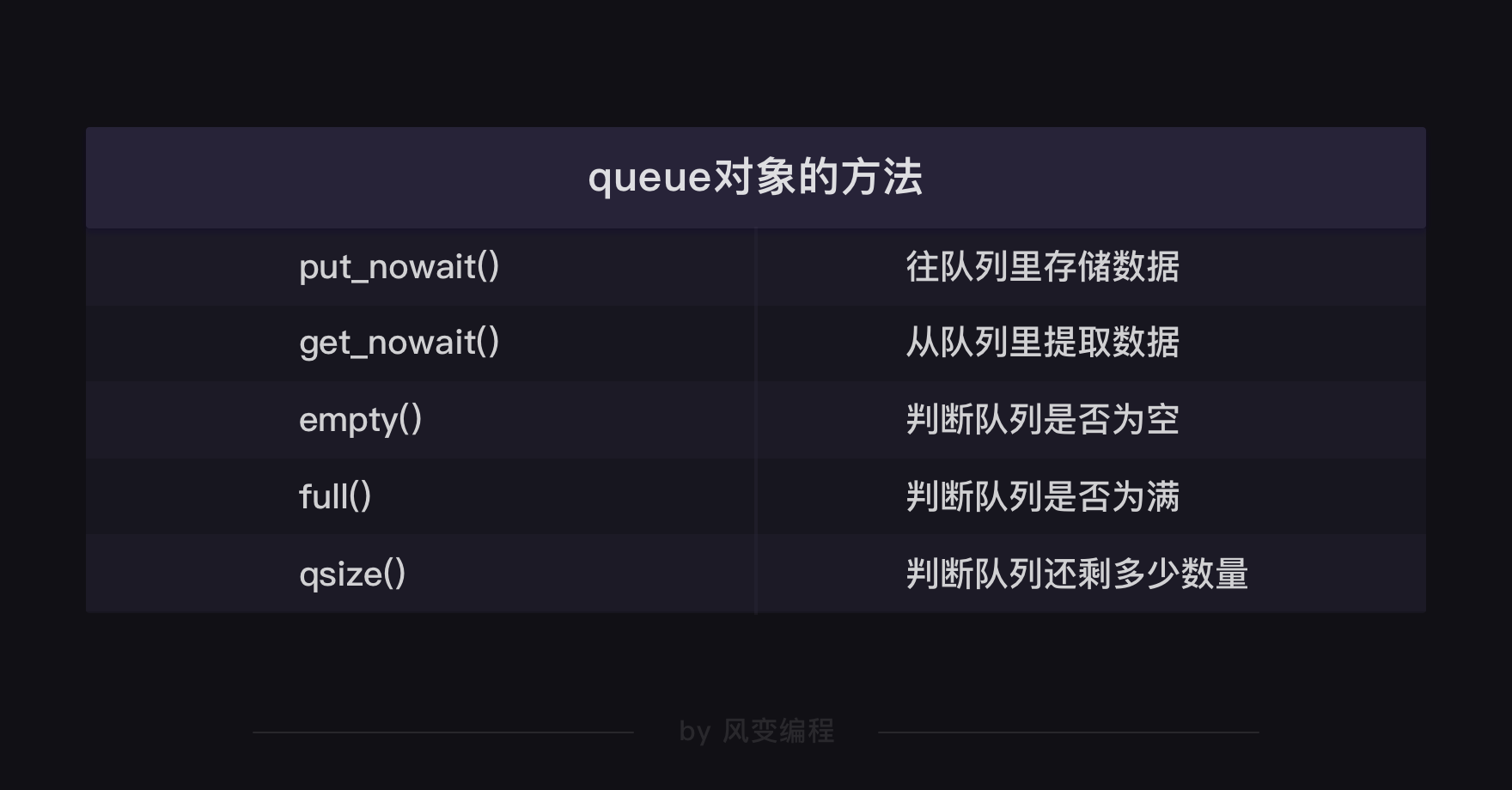
这里定义的crawler函数,多了三个你可能看不懂的代码:1.while not work.empty():;2.url = work.get_nowait();3.work.qsize()。
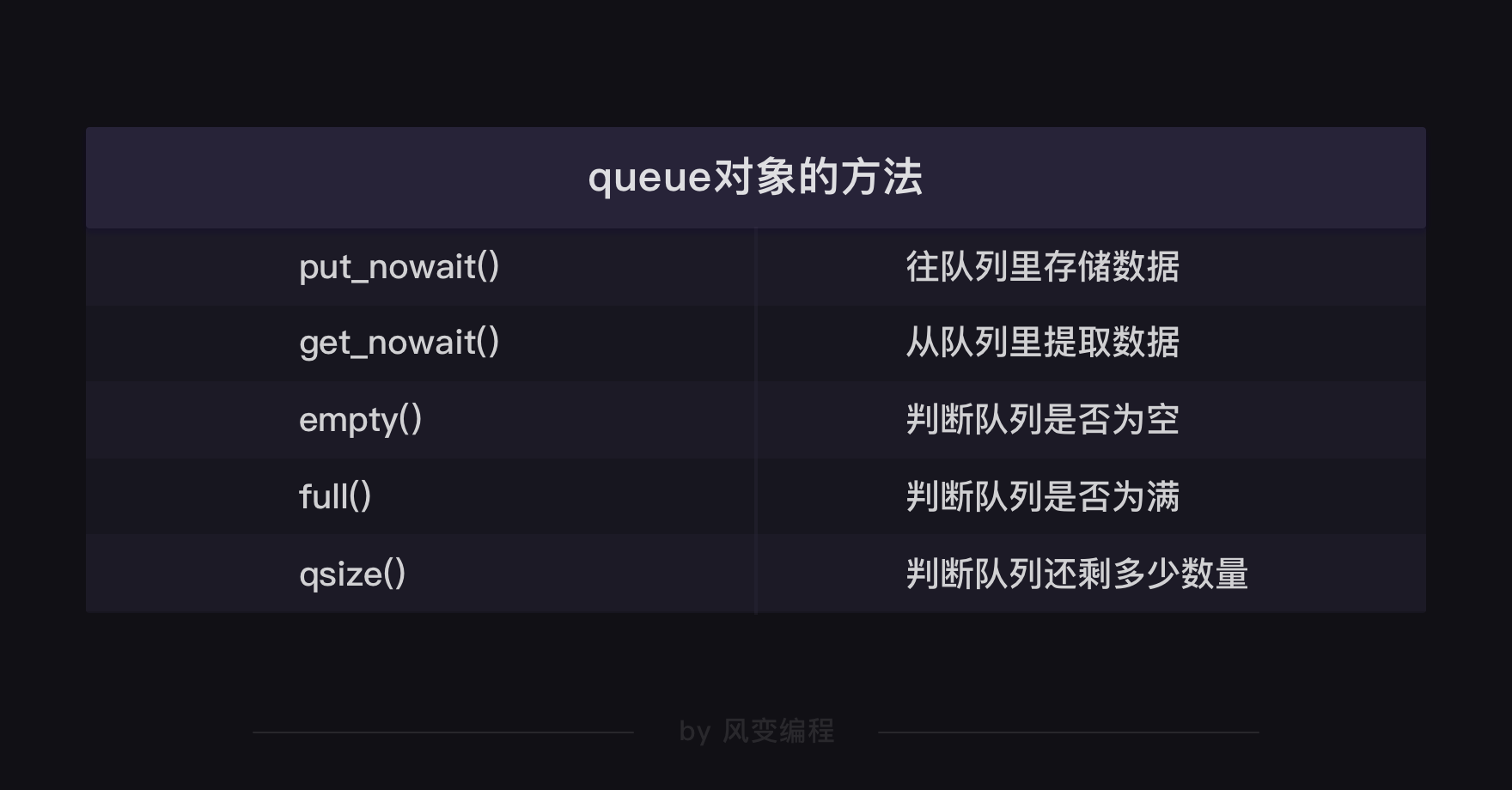
这三个代码涉及到queue对象的三个方法:empty方法,是用来判断队列是不是空了的;get_nowait方法,是用来从队列里提取数据的;qsize方法,是用来判断队列里还剩多少数量的。
当然,queue对象的方法还不止这几种,比如有判断队列是否为空的empty方法,对应也有判断队列是否为满的full方法。
你是不是觉得queue对象这么多方法,一下子记不住?其实,这些不需要你死记硬背的,附上一张queue对象的方法表,你只需要在用到的时候,查查表就好。
代码的前3部分,我们讲解完了。如果你能明白队列怎么创建、数据怎么存储进队列,以及怎么从队列里提取出的数据,就说明queue模块的重点内容你都掌握了。
接在第3部分代码的后面,就是让爬虫用多协程执行任务,爬取队列里的8个网站的代码(重点看有注释的代码)。
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
#创建空的任务列表
for x in range(2):
#相当于创建了2个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
print(end-start)
用一张图可以来解释这个过程:
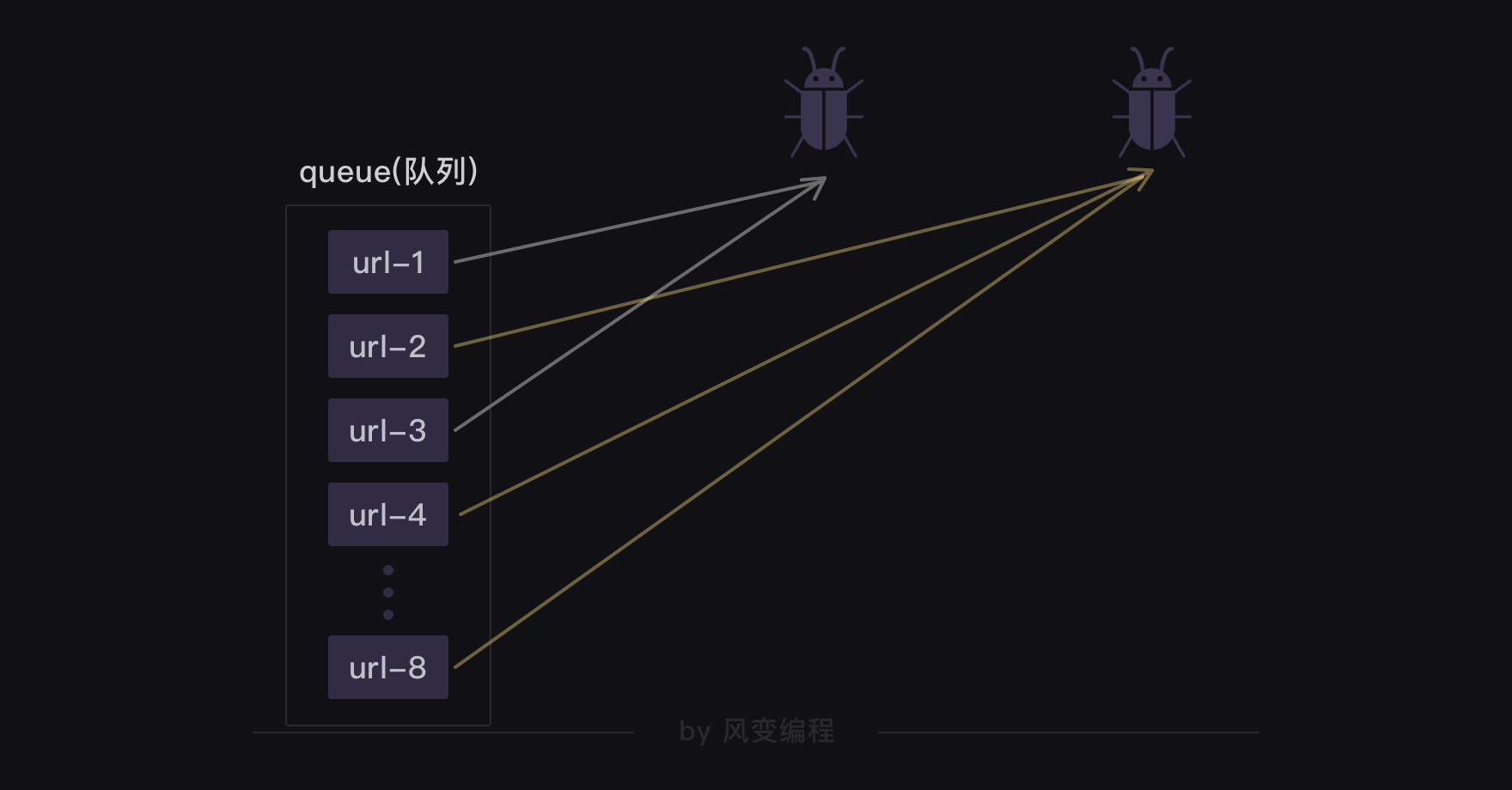
我们创建了两只可以异步爬取的爬虫。它们会从队列里取走网址,执行爬取任务。一旦一个网址被一只爬虫取走,另一只爬虫就取不到了,另一只爬虫就会取走下一个网址。直至所有网址都被取走,队列为空时,爬虫就停止工作。
用协程技术和队列爬取8个网站的完整代码如下:
from gevent import monkey
#从gevent库里导入monkey模块。
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,time,requests
#导入gevent、time、requests
from gevent.queue import Queue
#从gevent库里导入queue模块
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
#创建队列对象,并赋值给work。
for url in url_list:
#遍历url_list
work.put_nowait(url)
#用put_nowait()函数可以把网址都放进队列里。
def crawler():
while not work.empty():
#当队列不是空的时候,就执行下面的程序。
url = work.get_nowait()
#用get_nowait()函数可以把队列里的网址都取出。
r = requests.get(url)
#用requests.get()函数抓取网址。
print(url,work.qsize(),r.status_code)
#打印网址、队列长度、抓取请求的状态码。
tasks_list = [ ]
#创建空的任务列表
for x in range(2):
#相当于创建了2个爬虫
task = gevent.spawn(crawler)
#用gevent.spawn()函数创建执行crawler()函数的任务。
tasks_list.append(task)
#往任务列表添加任务。
gevent.joinall(tasks_list)
#用gevent.joinall方法,执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time.time()
print(end-start)
下面,请你动手把上面的代码敲一遍(不动手实践的爬虫学习都是耍流氓)。
动手总会有收获的。恭喜你,这一关的核心知识,实现多协程的gevent库和Queue模块,你都学完了!
4. 拓展复习
不过,我还想和你拓展一点新的知识。
同样是要做饭菜,我们已经知道比先做饭再做菜更好的方式是,等待做饭的过程中去做菜。但其实还有更快的方案:让一个人负责做饭,一个人负责做菜。
继续说我们的计算机历史小知识:在后来,我们的CPU从单核终于进化到了多核,每个核都能够独立运作。计算机开始能够真正意义上同时执行多个任务(术语叫并行执行),而不是在多个任务之间来回切换(术语叫并发执行)。
比如你现在打开浏览器看着爬虫课程的同时,可以打开音乐播放器听歌,还可以打开Excel。对于多核CPU而言,这些任务就都是同时运行的。
时至今日,我们电脑一般都会是多核CPU。多协程,其实只占用了CPU的一个核运行,没有充分利用到其他核。利用CPU的多个核同时执行任务的技术,我们把它叫做“多进程”。
所以,真正大型的爬虫程序不会单单只靠多协程来提升爬取速度的。比如,百度搜索引擎,可以说是超大型的爬虫程序,它除了靠多协程,一定还会靠多进程,甚至是分布式爬虫。
多进程爬虫和分布式爬虫不属于我们这个课程的知识范畴,我这里不会多讲。或许接下来我们会开设爬虫进阶课程,到时再和大家分享。
最后,是这一关的复习。
同步与异步——
多协程,是一种非抢占式的异步方式。使用多协程的话,就能让多个爬取任务用异步的方式交替执行。


5. 习题练习
1.要求:
请使用多协程和队列,爬取时光网电视剧TOP100的数据(剧名、导演、主演和简介),并用csv模块将数据存储下来。
时光网TOP100链接:http://www.mtime.com/top/tv/top100/
2.目的:
1)练习掌握gevent的用法
2)练习掌握queue的用法
3.书写代码
提示:
1.分析数据存在哪里(打开“检查”工具,刷新页面,查看第0个请求,看【response】)
2.观察网址规律(多翻几页,看看网址会有什么变化)
3.获取、解析和提取数据(需涉及知识点:queue、gevent、request、BeautifulSoup、find和find_all)
4.存储数据(csv本身的编码格式是utf-8,可以往open()里传入参数encoding='utf-8'。这样能避免由编码问题引起的报错。)
5.注:在练习的【文件】中,你能找到自己创建的csv文件。将其下载到本地电脑后,请用记事本打开,因为用Excel打开可能会因编码问题出现乱码。
from gevent import monkey
monkey.patch_all()
import gevent,requests,bs4,csv
from gevent.queue import Queue
work = Queue()
url_1 = 'http://www.mtime.com/top/tv/top100/'
work.put_nowait(url_1)
url_2 = 'http://www.mtime.com/top/tv/top100/index-{page}.html'
for x in range(2,11):
real_url = url_2.format(page=x)
work.put_nowait(real_url)
def crawler():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
while not work.empty():
url = work.get_nowait()
res = requests.get(url,headers=headers)
bs_res = bs4.BeautifulSoup(res.text,'html.parser')
datas = bs_res.find_all('div',class_="mov_con")
for data in datas:
TV_title = data.find('a').text
data = data.find_all('p')
TV_data =''
for i in data:
TV_data =TV_data + ''+ i.text
writer.writerow([TV_title,TV_data])
print([TV_title,TV_data])
csv_file = open('C://Users//17310//Desktop//ceshi//timetop.csv','w',newline='',encoding='utf-8')
writer = csv.writer(csv_file)
task_list = []
for x in range(3):
task = gevent.spawn(crawler)
task_list.append(task)
gevent.joinall(task_list)
标签:章节,www,协程,url,十二,爬虫,gevent,time,com 来源: https://www.cnblogs.com/ywb123/p/16416978.html