标签:章节 cookies 登录 session post data requests
章节九:cookies
目录第1-8关我们学习的是爬虫最为基础的知识,从第9关开始,我们正式打开爬虫的进阶之门,学习爬虫更多的精进知识。
在前面几关,我们实操的爬虫项目里都没有涉及到登录这一行为。
但实际很多情况下,由于网站的限制,不登录的话我们只能爬取到一小部分信息。
而我们想要登录的话,则需要带上小饼干。
什么是小饼干?小饼干就是cookies的中文翻译,它是模拟登录时会涉及到的重要知识点。在后面,我会为你详细解释原理。
这一关我准备带你完成一个项目实操——借助Python发表博客评论。其中,会应用到这一块知识。
1. 项目:发表博客评论

这个博客你之前见过,是我们搭建好的爬虫教学演练网站——
因为博客的设置,如果我们不登录的话,就无法在文章下面评论留言。
我们先来看看,“正常人”的登录操作是怎样的。
作为“正常人”,我们会先找到博客的登录按钮(在博客首页的右下角),然后点击。
网页会跳转到登录页面,我们会填写账号密码,点击登录,完成登录操作。

为了让你也能动手操作,我提前注册了一个账号——账号:spiderman,密码:crawler334566。请你复制下面的博客登录网址在浏览器打开:
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php
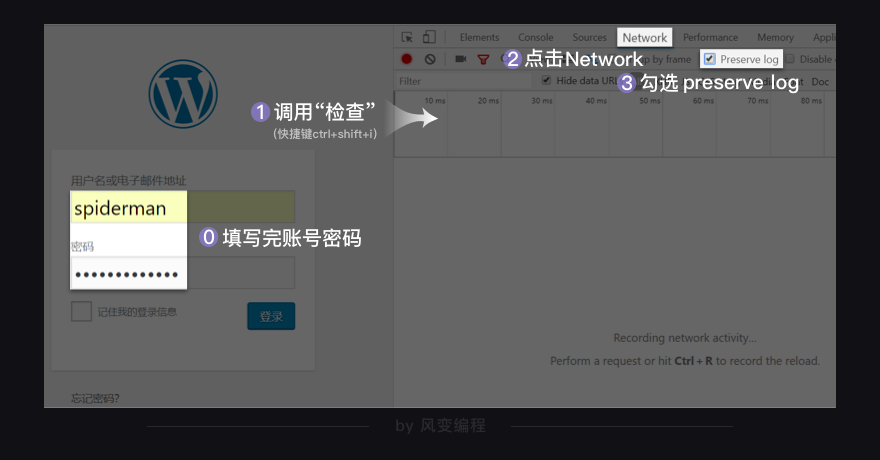
上图左边是“正常人”的操作:填上账号和密码;右边我们可以用工程师的思维,来分析浏览器的登录请求是怎么发送的。你需要做的是:先正常操作——填写完账号密码(别点击登录),再用工程师的做法操作:右击打开“检查”工具,点击【network】,勾选【preserve log】(持续显示请求记录,防止请求记录被刷新)。
确认一遍:“检查”工具打开了?【preserve log】勾选好了?ok了,就点击登录。
我们展开第0个请求【wp-login.php】,浏览一下【headers】。在【General】键里,我们可以先只看前两个参数【Request URL】(请求网址)和【Request Method】(请求方式)。
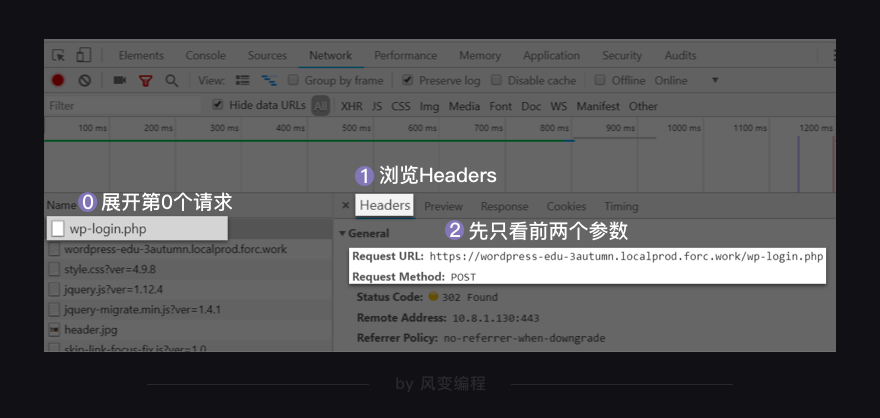
是不是有点困惑?这里的请求方式是post,而不是我们之前学过的get。
post请求
其实,post和get都可以带着参数请求,不过get请求的参数会在url上显示出来。
比如在第5关,我们最终请求的URL会变得超级长。它们,都是参数。
但post请求的参数就不会直接显示,而是隐藏起来。像账号密码这种私密的信息,就应该用post的请求。如果用get请求的话,账号密码全部会显示在网址上,这显然不科学!你可以这么理解,get是明文显示,post是非明文显示。
通常,get请求会应用于获取网页数据,比如我们之前学的requests.get()。post请求则应用于向网页提交数据,比如提交表单类型数据(像账号密码就是网页表单的数据)。
get和post是两种最常用的请求方式,除此之外,还有其他类型的请求方式,如head、options等,这里我们就不详讲了,因为一般很少用到。
现在,get和post这两种请求方式的区别弄懂了吧?我们继续往下看——
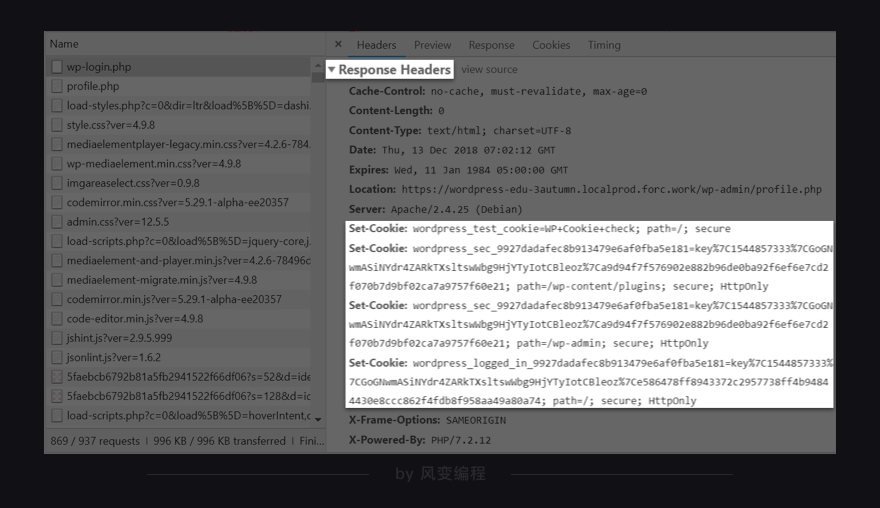
关于【headers】面板里的几个参数,在第3、4关我们已经陆续讲完了,唯独除了【response headers】我们还没有讲。
正如【requests headers】存储的是浏览器的请求信息,【response headers】存储的是服务器的响应信息。我们这一关要找的cookies就在其中。
你会看到在【response headers】里有set cookies的参数。set cookies是什么意思?就是服务器往浏览器写入了cookies。
现在我们就可以谈一谈:cookies究竟是什么?它有什么用?
2. cookies及其用法
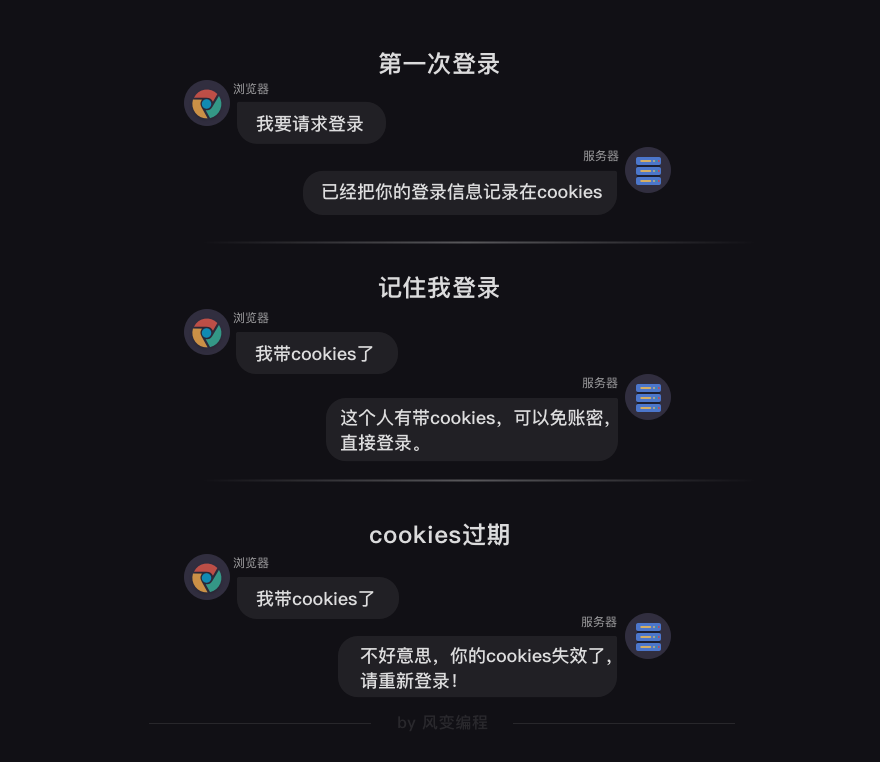
其实,你对cookies并不陌生,我敢肯定你见过它。比如一般当你登录一个网站,你都会在登录页面看到一个可勾选的选项“记住我”,如果你勾选了,以后你再打开这个网站就会自动登录,这就是cookie在起作用。
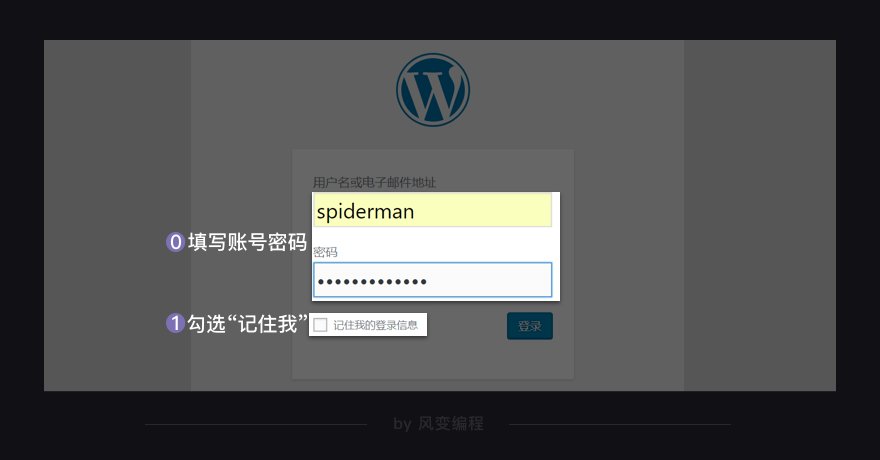
当你登录博客账号spiderman,并勾选“记住我”,服务器就会生成一个cookies和spiderman这个账号绑定。接着,它把这个cookies告诉你的浏览器,让浏览器把cookies存储到你的本地电脑。当下一次,浏览器带着cookies访问博客,服务器会知道你是spiderman,你不需要再重复输入账号密码,即可直接访问。
当然,cookies也是有时效性的,过期后就会失效。你应该有过这样的体验:哪怕勾选了“记住我”,但一段时间过去了,网站还是会提示你要重新登录,就是之前的cookies已经失效。
我们继续看【headers】,看看还有没有哪些有关登录的参数。
咦,拉到【form data】,可以看到5个参数:
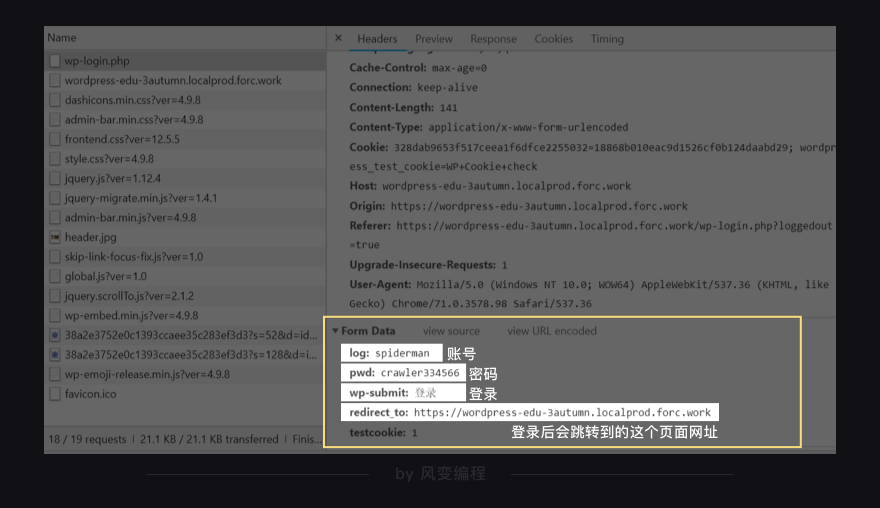
log和pwd显然是我们的账号和密码,wp-submit猜一下就知道是登录的按钮,redirect_to后面带的链接是我们登录后会跳转到的这个页面网址,testcookie我们不知道是什么。
关于登录的参数我们找到了。现在可以尝试开始写代码,向服务器发起登录请求。
import requests
#引入requests。
url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
#把登录的网址赋值给url。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
#加请求头,前面有说过加请求头是为了模拟浏览器正常的访问,避免被反爬虫。
data = {
'log': 'spiderman', #写入账户
'pwd': 'crawler334566', #写入密码
'wp-submit': '登录',
'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie': '1'
}
#把有关登录的参数封装成字典,赋值给data。
login_in = requests.post(url,headers=headers,data=data)
#用requests.post发起请求,放入参数:请求登录的网址、请求头和登录参数,然后赋值给login_in。
print(login_in)
#打印login_in你可以运行一下这个代码。
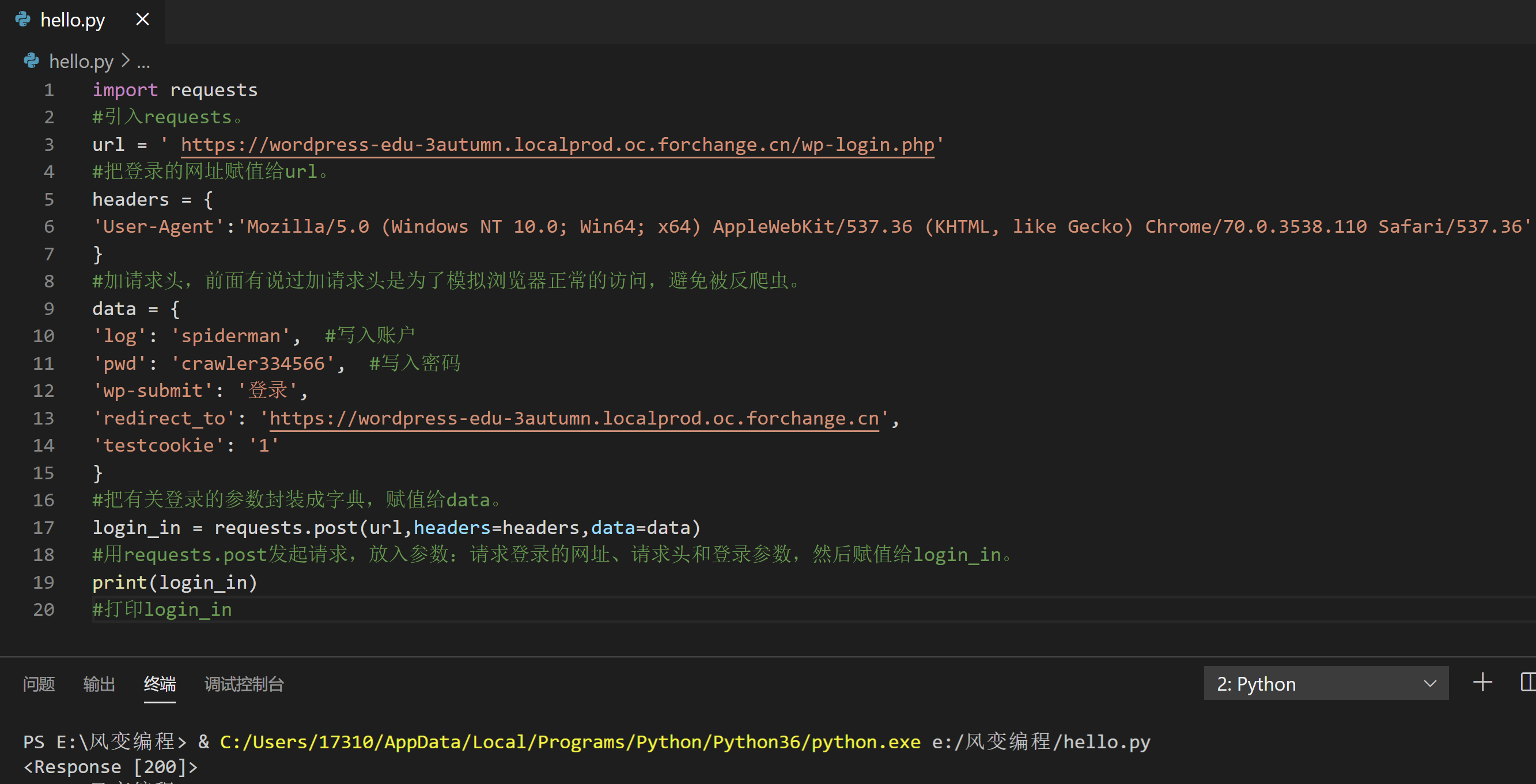
Response [200],是返回了200的状态码,意味着服务器接收到并响应了登录请求。
不过,我们的目标是要往博客的文章里发表评论,所以成功登录只是第一步。
怎么发表评论我们现在还不知道。那就先分析看看“正常人”发表评论,浏览器会发送什么请求。
行,我们在《未来已来(一)——技术变革》这篇文章下面自己写一条评论发表(记得不要关闭检查工具,这样才能看到请求的记录)。
我按“正常人”的操作写了一条“纯属测试”的评论,点击发表。
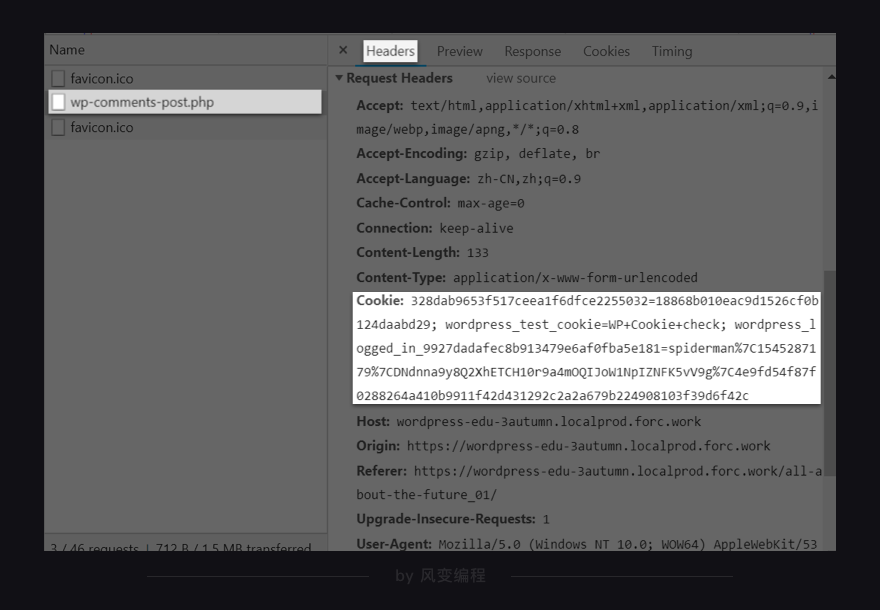
Network里迅速加载出很多请求,点开【wp-comments-post.php】,看headers,发现我刚刚发表的评论就藏在这里。
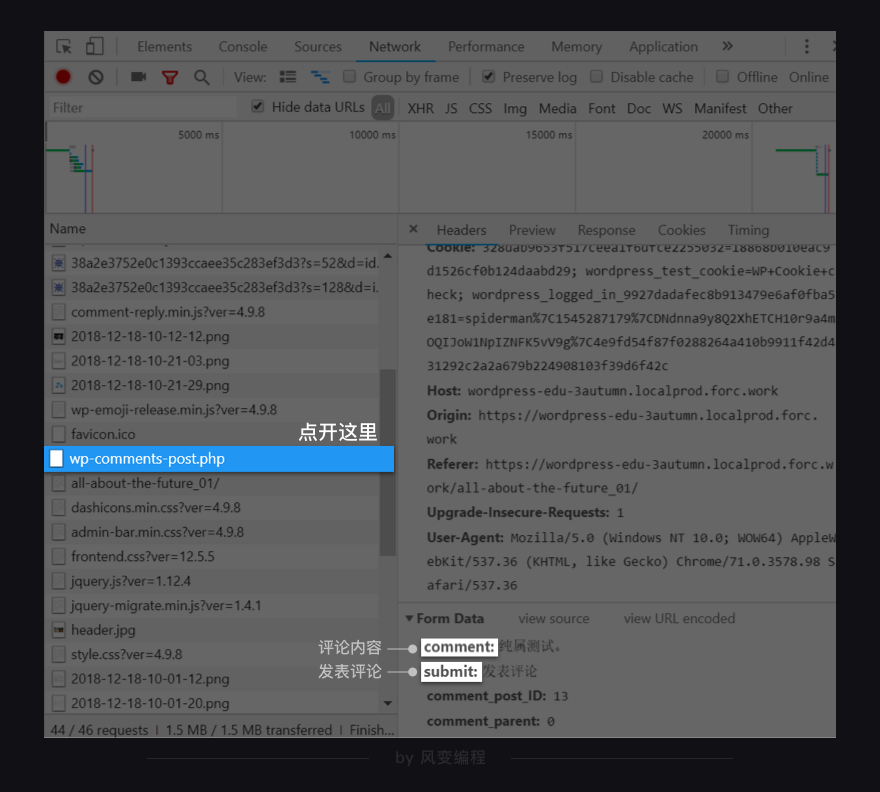
comment是评论内容,submit是发表评论的按钮,另外两个参数我们看不懂,不过没关系,我们知道它们都是和评论有关的参数就行。
你还会发现【wp-comments-post.php】的数据并没有藏在XHR中,而是放在了Other里。原因是我们搭建网站时就写在了Other里,但常规情况下,大部分网站都会把这样的数据存储在XHR里,比如知乎的回答。
我们想要发表博客评论,首先得登录,其次得提取和调用登录的cookies,然后还需要评论的参数,才能发起评论的请求。
现在,登录的代码我们前面写好了,评论的参数我们刚也找到了,就差提取和调用登录的cookies。
我会先带你写一遍发表评论的代码(要认真看注释):
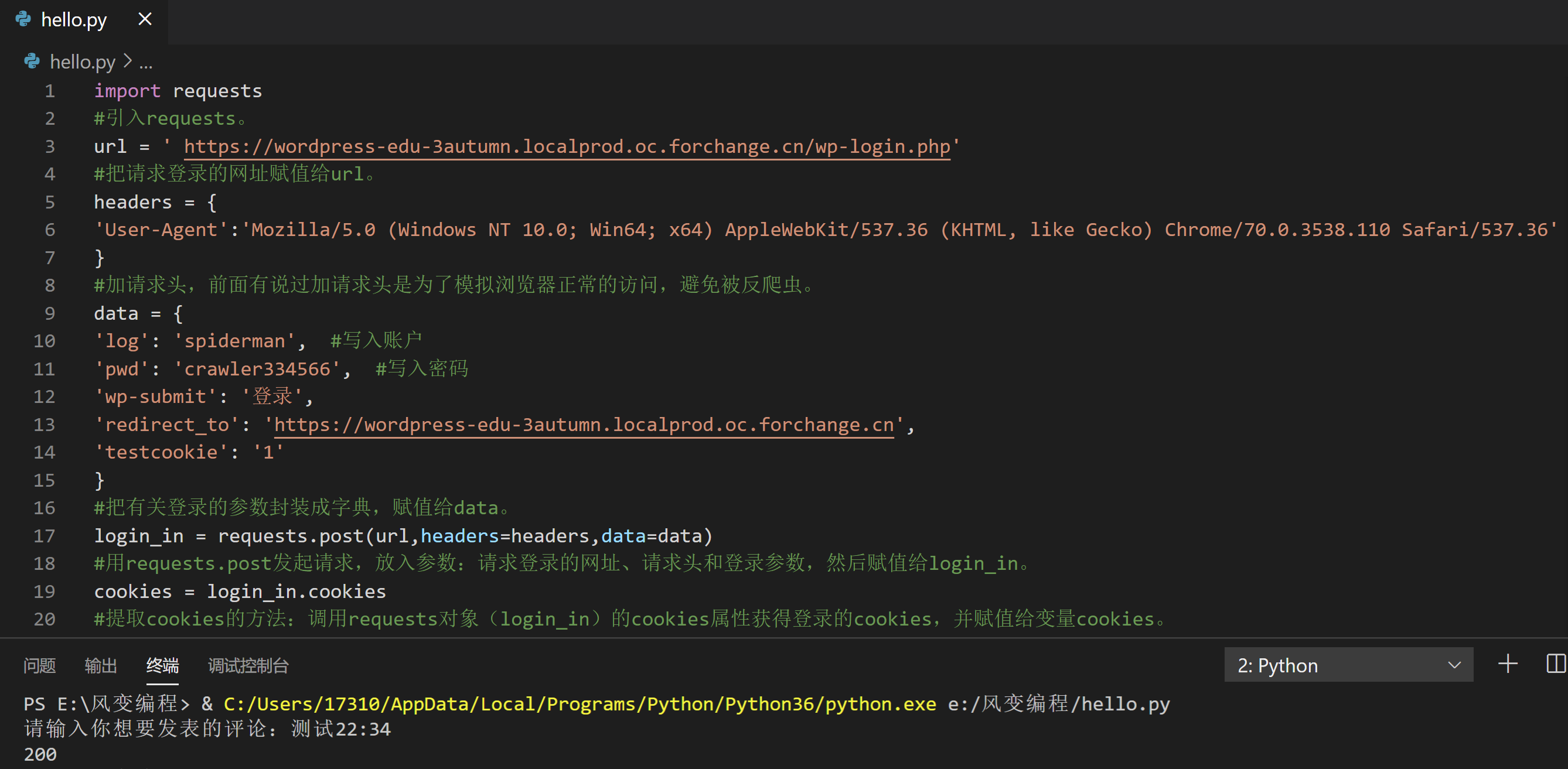
import requests
#引入requests。
url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
#把请求登录的网址赋值给url。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
#加请求头,前面有说过加请求头是为了模拟浏览器正常的访问,避免被反爬虫。
data = {
'log': 'spiderman', #写入账户
'pwd': 'crawler334566', #写入密码
'wp-submit': '登录',
'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie': '1'
}
#把有关登录的参数封装成字典,赋值给data。
login_in = requests.post(url,headers=headers,data=data)
#用requests.post发起请求,放入参数:请求登录的网址、请求头和登录参数,然后赋值给login_in。
cookies = login_in.cookies
#提取cookies的方法:调用requests对象(login_in)的cookies属性获得登录的cookies,并赋值给变量cookies。
url_1 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php'
#我们想要评论的文章网址。
data_1 = {
'comment': input('请输入你想要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '13',
'comment_parent': '0'
}
#把有关评论的参数封装成字典。
comment = requests.post(url_1,headers=headers,data=data_1,cookies=cookies)
#用requests.post发起发表评论的请求,放入参数:文章网址、headers、评论参数、cookies参数,赋值给comment。
#调用cookies的方法就是在post请求中传入cookies=cookies的参数。
print(comment.status_code)
#打印出comment的状态码,若状态码等于200,则证明我们评论成功。提取cookies的方法请看第19的代码:调用requests对象的cookies属性获得登录的cookies。
调用cookies的方法请看第31行的代码:在post请求中传入cookies=cookies的参数。
最后之所以加一行打印状态码的代码,是想运行整个代码后,能立马判断出评论到底有没有成功发表。只要状态码等于200,就说明服务器成功接收并响应了我们的评论请求。
多解释一句:登录的cookies其实包含了很多名称和值,真正能帮助我们发表评论的cookies,只是取了登录cookies中某一小段值而已。所以登录的cookies和评论成功后,你在【wp-comments-post.php】里的headers面板中看到的cookies是不一致的。
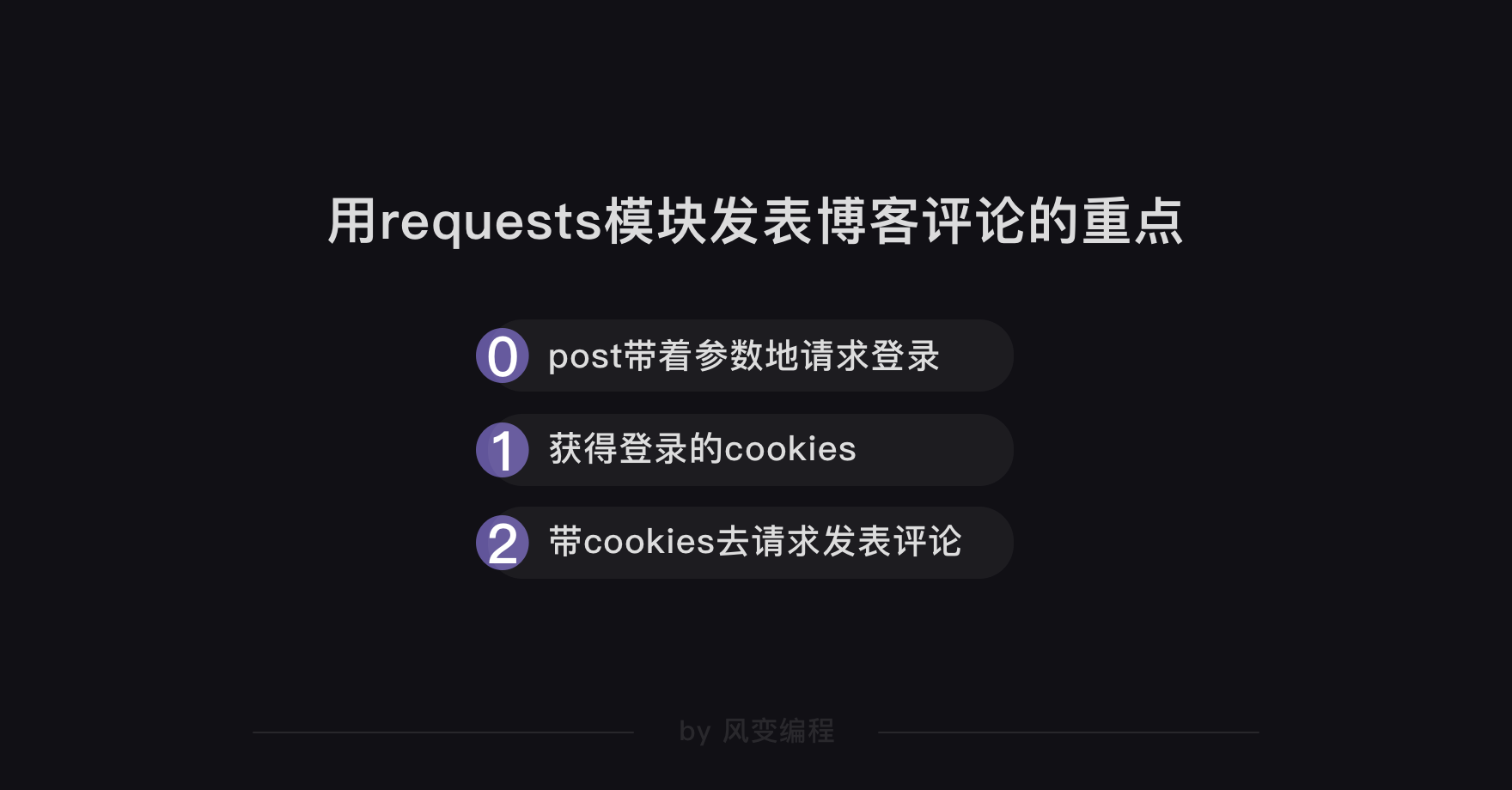
总结一下:发表博客评论就三个重点——

刷新文章的页面,你应该能找到自己的评论。
虽然我们已经成功发表了评论,但我们的项目到这里还没有结束。因为这个代码还有优化的空间(仅仅是完成还不够,更优雅才是我们该有的追求)。
如果要继续优化这个代码的话,我们需要理解一个新的概念——session(会话)。
3. session及其用法
所谓的会话,你可以理解成我们用浏览器上网,到关闭浏览器的这一过程。session是会话过程中,服务器用来记录特定用户会话的信息。
比如你打开浏览器逛购物网页的整个过程中,浏览了哪些商品,在购物车里放了多少件物品,这些记录都会被服务器保存在session中。

如果没有session,可能会出现这样搞笑的情况:你加购了很多商品在购物车,打算结算时,发现购物车空无一物Σ(っ°Д°;)っ,因为服务器根本没有帮你记录你想买的商品。
对了,session和cookies的关系还非常密切——cookies中存储着session的编码信息,session中又存储了cookies的信息。
当浏览器第一次访问购物网页时,服务器会返回set cookies的字段给浏览器,而浏览器会把cookies保存到本地。
等浏览器第二次访问这个购物网页时,就会带着cookies去请求,而因为cookies里带有会话的编码信息,服务器立马就能辨认出这个用户,同时返回和这个用户相关的特定编码的session。
这也是为什么你每次重新登录购物网站后,你之前在购物车放入的商品并不会消失的原因。因为你在登录时,服务器可以通过浏览器携带的cookies,找到保存了你购物车信息的session。
呼,session的概念,以及和cookies的关系我们搞清楚了,终于可以开始优化发表博客评论的代码。
既然cookies和session的关系如此密切,那我们可不可以通过创建一个session来处理cookies?
不知道。那就翻阅requests的官方文档找找看有没有这样的方法,能让我们创建session来处理cookies。
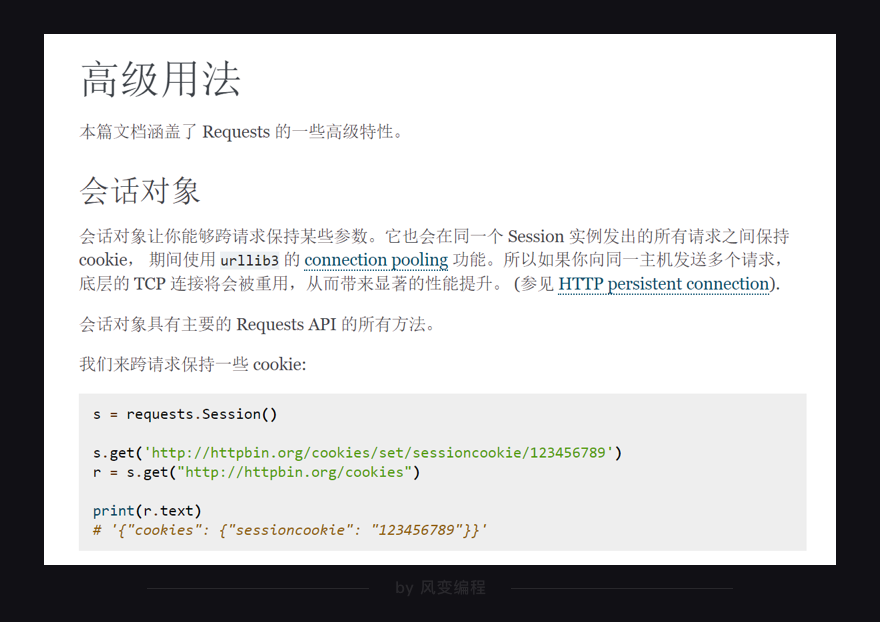
在requests的高级用法里,还真有这样的方法,太棒了!
优化后的发表评论的代码如下(重点看有注释的代码):
import requests
#引用requests。
session = requests.session()
#用requests.session()创建session对象,相当于创建了一个特定的会话,帮我们自动保持了cookies。
url = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
data = {
'log':input('请输入账号:'), #用input函数填写账号和密码,这样代码更优雅,而不是直接把账号密码填上去。
'pwd':input('请输入密码:'),
'wp-submit':'登录',
'redirect_to':'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie':'1'
}
session.post(url,headers=headers,data=data)
#在创建的session下用post发起登录请求,放入参数:请求登录的网址、请求头和登录参数。
url_1 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php'
#把我们想要评论的文章网址赋值给url_1。
data_1 = {
'comment': input('请输入你想要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '13',
'comment_parent': '0'
}
#把有关评论的参数封装成字典。
comment = session.post(url_1,headers=headers,data=data_1)
#在创建的session下用post发起评论请求,放入参数:文章网址,请求头和评论参数,并赋值给comment。
print(comment)
#打印comment我们再运行代码看看(账号:spiderman;密码:crawler334566)。

这么一细看,其实这个代码并没有特别大的优化,我们每次还是需要输入账号密码登录,才能发表评论。
可不可以有更优化的方案?
答案:可以有!cookies能帮我们保存登录的状态,那我们就在第一次登录时把cookies存储下来,等下次登录再把存储的cookies读取出来,这样就不用重复输入账号密码了。
4. 存储cookies
我们先把登录的cookies打印出来看看,请点击运行下面的代码(账号:spiderman;密码:crawler334566)。
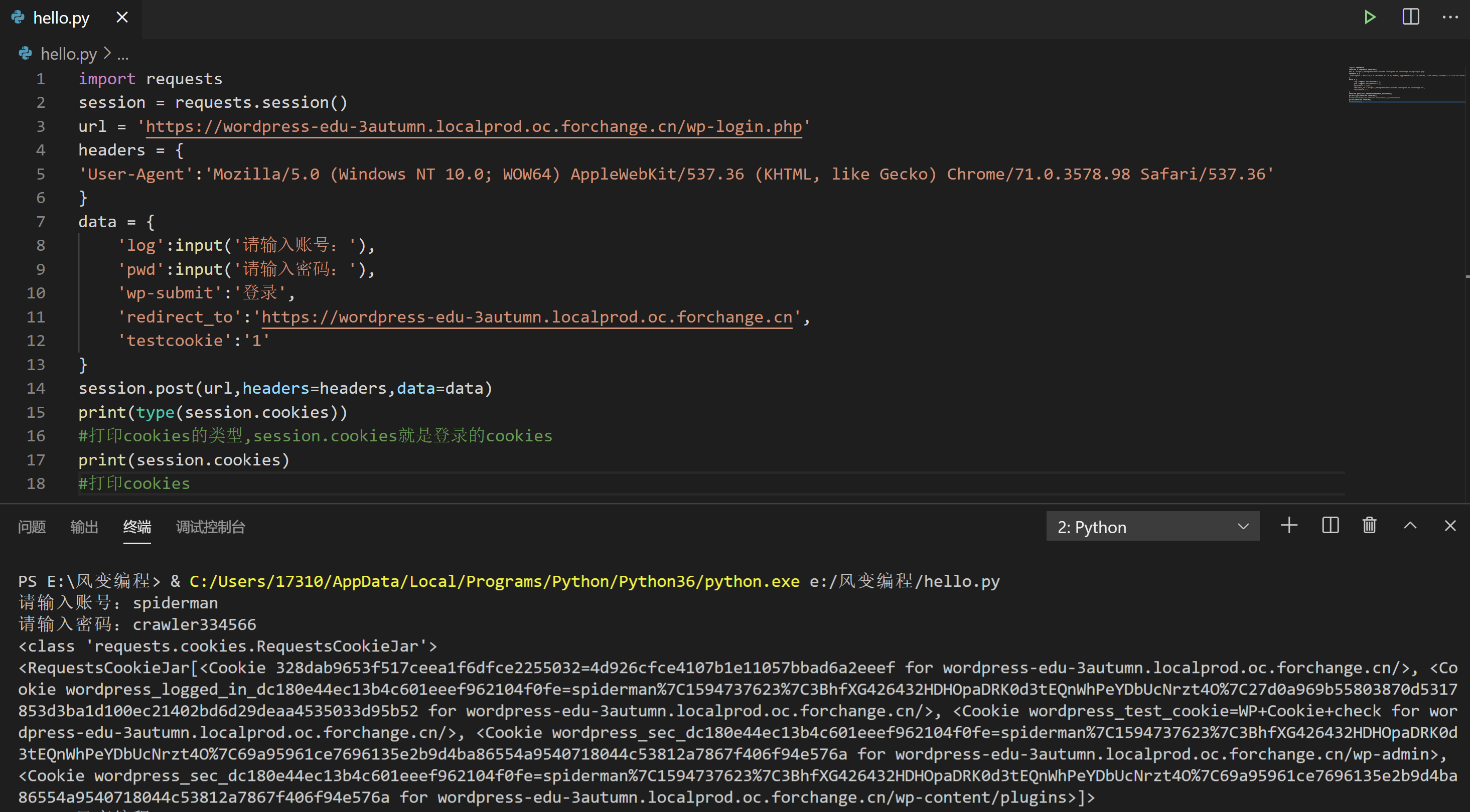
import requests
session = requests.session()
url = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
data = {
'log':input('请输入账号:'),
'pwd':input('请输入密码:'),
'wp-submit':'登录',
'redirect_to':'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie':'1'
}
session.post(url,headers=headers,data=data)
print(type(session.cookies))
#打印cookies的类型,session.cookies就是登录的cookies
print(session.cookies)
#打印cookiesRequestsCookieJar是cookies对象的类,cookies本身的内容有点像一个列表,里面又有点像字典的键与值,具体的值我们看不懂,也不需要弄懂。
那怎么把cookies存储下来?能不能用文件读写的方式,把cookies存储成txt文件?
可是txt文件存储的是字符串,刚刚打印出来的cookies并不是字符串。那有没有能把cookies转成字符串的方法?
对了,在第4关我们知道,json模块能把字典转成字符串。我们或许可以先把cookies转成字典,然后再通过json模块转成字符串。这样,就能用open函数把cookies存储成txt文件。
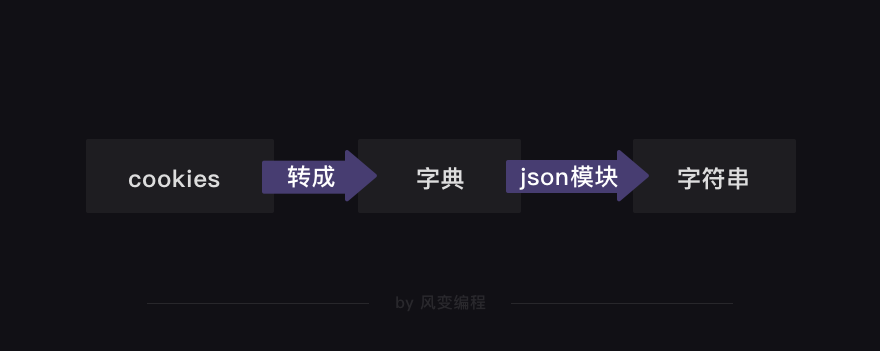
感觉这样的思路应该可以实现。通过使用搜索引擎+翻阅官方文档的方式,就能找到了把cookies转化成字典的方法和json模块的使用方法。

把cookies存储成txt文件的代码如下(有注释的代码要认真看):
import requests,json
#引入requests和json模块。
session = requests.session()
url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
data = {
'log': input('请输入你的账号:'),
'pwd': input('请输入你的密码:'),
'wp-submit': '登录',
'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie': '1'
}
session.post(url, headers=headers, data=data)
cookies_dict = requests.utils.dict_from_cookiejar(session.cookies)
#把cookies转化成字典。
print(cookies_dict)
#打印cookies_dict
cookies_str = json.dumps(cookies_dict)
#调用json模块的dumps函数,把cookies从字典再转成字符串。
print(cookies_str)
#打印cookies_str
f = open('C://Users//17310//Desktop//ceshi//cookies.txt', 'w')
#创建名为cookies.txt的文件,以写入模式写入内容。
f.write(cookies_str)
#把已经转成字符串的cookies写入文件。
f.close()
#关闭文件。提示:以上存储cookies的方法并非最简单的方法,选取这个方法是因为它容易理解。如果你看完了,请运行代码(账号:spiderman;密码:crawler334566)。

运行代码后,确实证明了cookies可以被转成字典,也可以通过json模块把字典格式的cookies转成字符串。
这样一来,cookies的存储我们搞定了,但还得搞定cookies的读取,才能解决每次发表评论都得先输入账号密码的问题。
5. 读取cookies
我们存储cookies时,是把它先转成字典,再转成字符串。读取cookies则刚好相反,要先把字符串转成字典,再把字典转成cookies本来的格式。
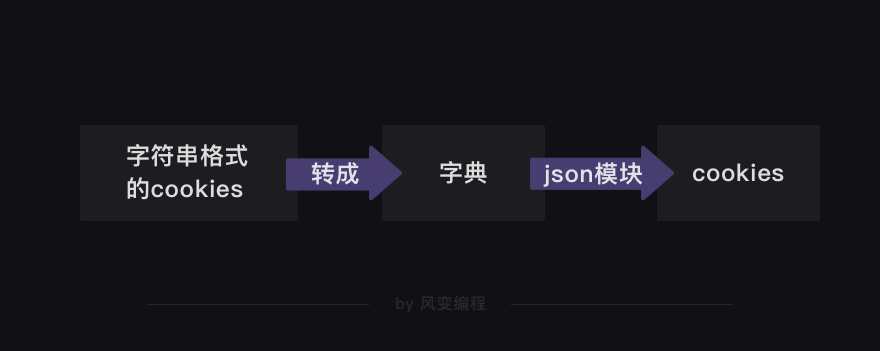
读取cookies的代码如下:
cookies_txt = open('cookies.txt', 'r')
#以reader读取模式,打开名为cookies.txt的文件。
cookies_dict = json.loads(cookies_txt.read())
#调用json模块的loads函数,把字符串转成字典。
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
#把转成字典的cookies再转成cookies本来的格式。
session.cookies = cookies
#获取cookies:就是调用requests对象(session)的cookies属性。终于,cookies的存储与读取我们都弄好了。
最后我们可以把代码优化成:如果程序能读取到cookies,就自动登录,发表评论;如果读取不到,就重新输入账号密码登录,再评论。
再一次优化的代码如下:
import requests,json
session = requests.session()
#创建会话。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
#添加请求头,避免被反爬虫。
try:
#如果能读取到cookies文件,执行以下代码,跳过except的代码,不用登录就能发表评论。
cookies_txt = open('C://Users//17310//Desktop//ceshi//cookies.txt', 'r')
#以reader读取模式,打开名为cookies.txt的文件。
cookies_dict = json.loads(cookies_txt.read())
#调用json模块的loads函数,把字符串转成字典。
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
#把转成字典的cookies再转成cookies本来的格式。
session.cookies = cookies
#获取cookies:就是调用requests对象(session)的cookies属性。
except FileNotFoundError:
#如果读取不到cookies文件,程序报“FileNotFoundError”(找不到文件)的错,则执行以下代码,重新登录获取cookies,再评论。
url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
#登录的网址。
data = {'log': input('请输入你的账号:'),
'pwd': input('请输入你的密码:'),
'wp-submit': '登录',
'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie': '1'}
#登录的参数。
session.post(url, headers=headers, data=data)
#在会话下,用post发起登录请求。
cookies_dict = requests.utils.dict_from_cookiejar(session.cookies)
#把cookies转化成字典。
cookies_str = json.dumps(cookies_dict)
#调用json模块的dump函数,把cookies从字典再转成字符串。
f = open('C://Users//17310//Desktop//ceshi//cookies.txt', 'w')
#创建名为cookies.txt的文件,以写入模式写入内容
f.write(cookies_str)
#把已经转成字符串的cookies写入文件
f.close()
#关闭文件
url_1 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php'
#文章的网址。
data_1 = {
'comment': input('请输入你想评论的内容:'),
'submit': '发表评论',
'comment_post_ID': '13',
'comment_parent': '0'
}
#评论的参数。
comment = session.post(url_1,headers=headers,data=data_1)
#在创建的session下用post发起评论请求,放入参数:文章网址,请求头和评论参数,并赋值给comment。
print(comment.status_code)
#打印comment的状态码你可以体验一下这个代码,感受优化后的效果(账号:spiderman;密码:crawler334566)。
这样是解决了每一次都要重复输入账号密码的问题,但这个代码还存在一个缺陷——并没有解决cookies会过期的问题。
cookies是否过期,我们可以通过最后的状态码是否等于200来判断。但更好的解决方法应该在代码里加一个条件判断,如果cookies过期,就重新获取新的cookies。
所以,更完整以及面向对象的代码应该是下面这样的:
import requests, json
session = requests.session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}
def cookies_read():
cookies_txt = open('C://Users//17310//Desktop//ceshi//cookies.txt', 'r')
cookies_dict = json.loads(cookies_txt.read())
cookies = requests.utils.cookiejar_from_dict(cookies_dict)
return (cookies)
# 以上4行代码,是cookies读取。
def sign_in():
url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php'
data = {'log': input('请输入你的账号'),
'pwd': input('请输入你的密码'),
'wp-submit': '登录',
'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn',
'testcookie': '1'}
session.post(url, headers=headers, data=data)
cookies_dict = requests.utils.dict_from_cookiejar(session.cookies)
cookies_str = json.dumps(cookies_dict)
f = open('C://Users//17310//Desktop//ceshi//cookies.txt', 'w')
f.write(cookies_str)
f.close()
# 以上5行代码,是cookies存储。
def write_message():
url_2 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php'
data_2 = {
'comment': input('请输入你要发表的评论:'),
'submit': '发表评论',
'comment_post_ID': '13',
'comment_parent': '0'
}
return (session.post(url_2, headers=headers, data=data_2))
#以上9行代码,是发表评论。
try:
session.cookies = cookies_read()
except FileNotFoundError:
sign_in()
num = write_message()
if num.status_code == 200:
print('成功啦!')
else:
sign_in()
num = write_message()6. 复习
下面,是这一关的复习:
cookies是服务器为了标记用户,存储在用户本地的数据,它里面也保存了用户的登录信息,同时它有一定的时效性,过期就会失效。
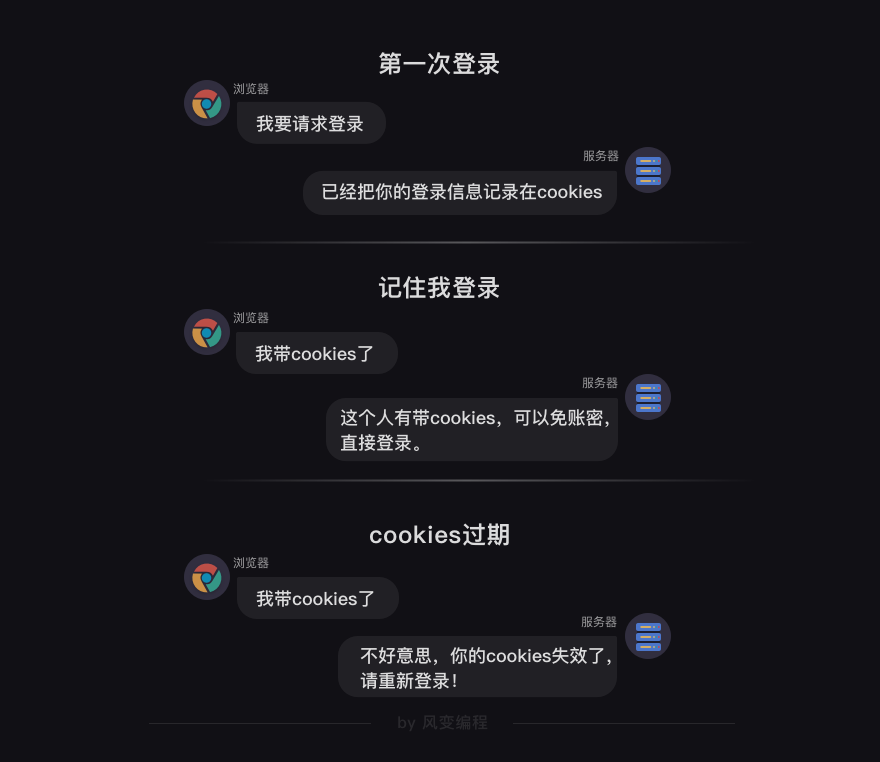
session是会话过程中,服务器用来记录特定用户会话的信息。

session和cookies的关系:cookies里带有session的编码信息,服务器可以通过cookies辨别用户,同时返回和这个用户相关的特定编码的session。


最后,还想和你多说几句——
其实,计算机之所以需要cookies和session,是因为HTTP协议是无状态的协议。
何为无状态?就是一旦浏览器和服务器之间的请求和响应完毕后,两者会立马断开连接,也就是恢复成无状态。
这样会导致:服务器永远无法辨认,也记不住用户的信息,像一条只有7秒记忆的金鱼。是cookies和session的出现,才破除了web发展史上的这个难题。
cookies不仅仅能实现自动登录,因为它本身携带了session的编码信息,网站还能根据cookies,记录你的浏览足迹,从而知道你的偏好,只要再加以推荐算法,就可以实现给你推送定制化的内容。
比如,淘宝会根据你搜索和浏览商品的记录,给你推送符合你偏好的商品,增加你的购买率。cookies和session在这其中起到的作用,可谓举足轻重。
7. 习题练习
7.1 习题一
7.1.1 题目要求
1.要求:
在本练习,我们会借助cookies的相关知识,使用Python登录小说网站,用代码的形式对热榜上的小说进行推荐。
2.目的:
练习掌握cookies和session的用法
练习post和get请求
练习json数据的解析提取
反爬虫应对策略
7.1.2 分步讲解
在这一步,我会带领你完成“分析过程”,请务必完整阅读文档。
在下一步,我们会开始按步骤书写代码。
1.体验流程
想要对热榜的小说进行推荐,我们首先需要用浏览器体验这个过程。
前往小说楼,手动找到热榜所在位置
随机对一部小说进行推荐
最后,再用Python代码去模拟这个过程
2.进入热榜
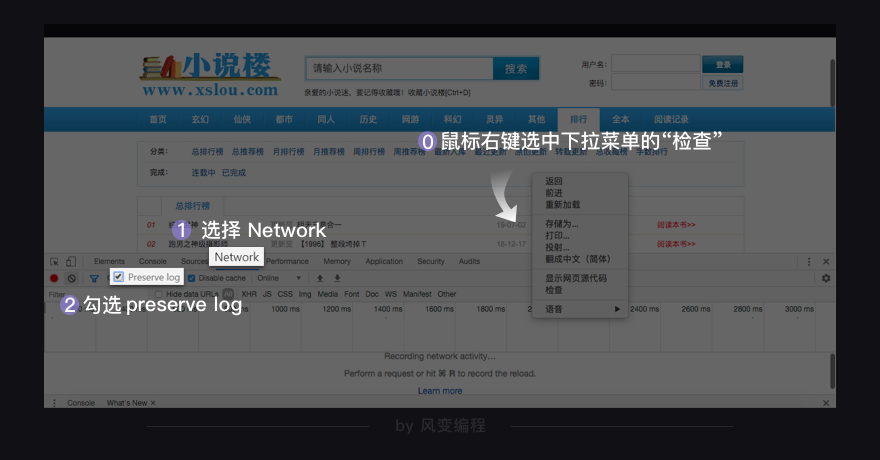
首先,打开小说楼的排行榜页:https://www.xslou.com/top/allvisit_1/
打开【检查】工具,选择【Network】,勾选【Preserve log】(因为等会可能会有页面跳转,勾选上防止在跳转过程中请求被清空)。
3.体验登录
1)然后我们可以随机点击其中一本小说,对其进行推荐
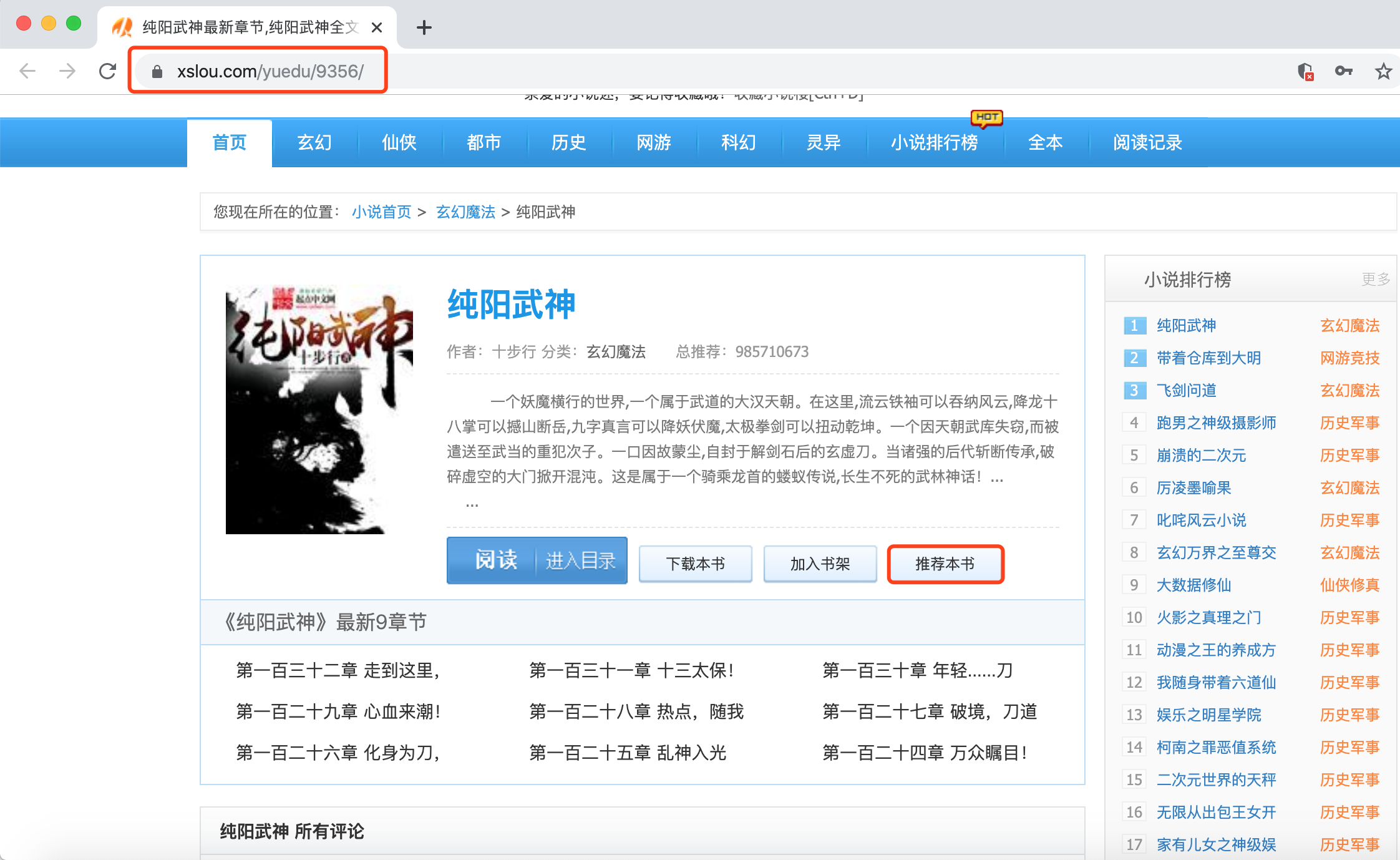
2)此时,如果没有登录小说楼(或注册)的用户,会自动跳到小说楼的登录页面:https://www.xslou.com/login.php
也就是说,想要推荐,我们必须通过登录呀~
3)阅读该URL,很容易能够看出这个是一个登录页,因为有链接有个login(中文:登录)
4)输入账号和密码,同时查看Network,发现浏览器会携带着账号和密码发起Post请求。
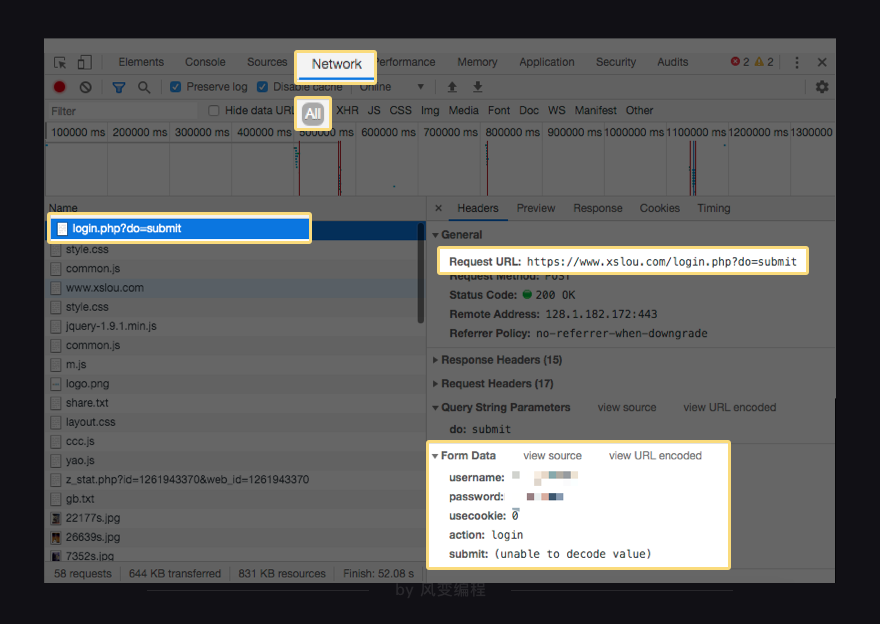
4.获取推荐链接
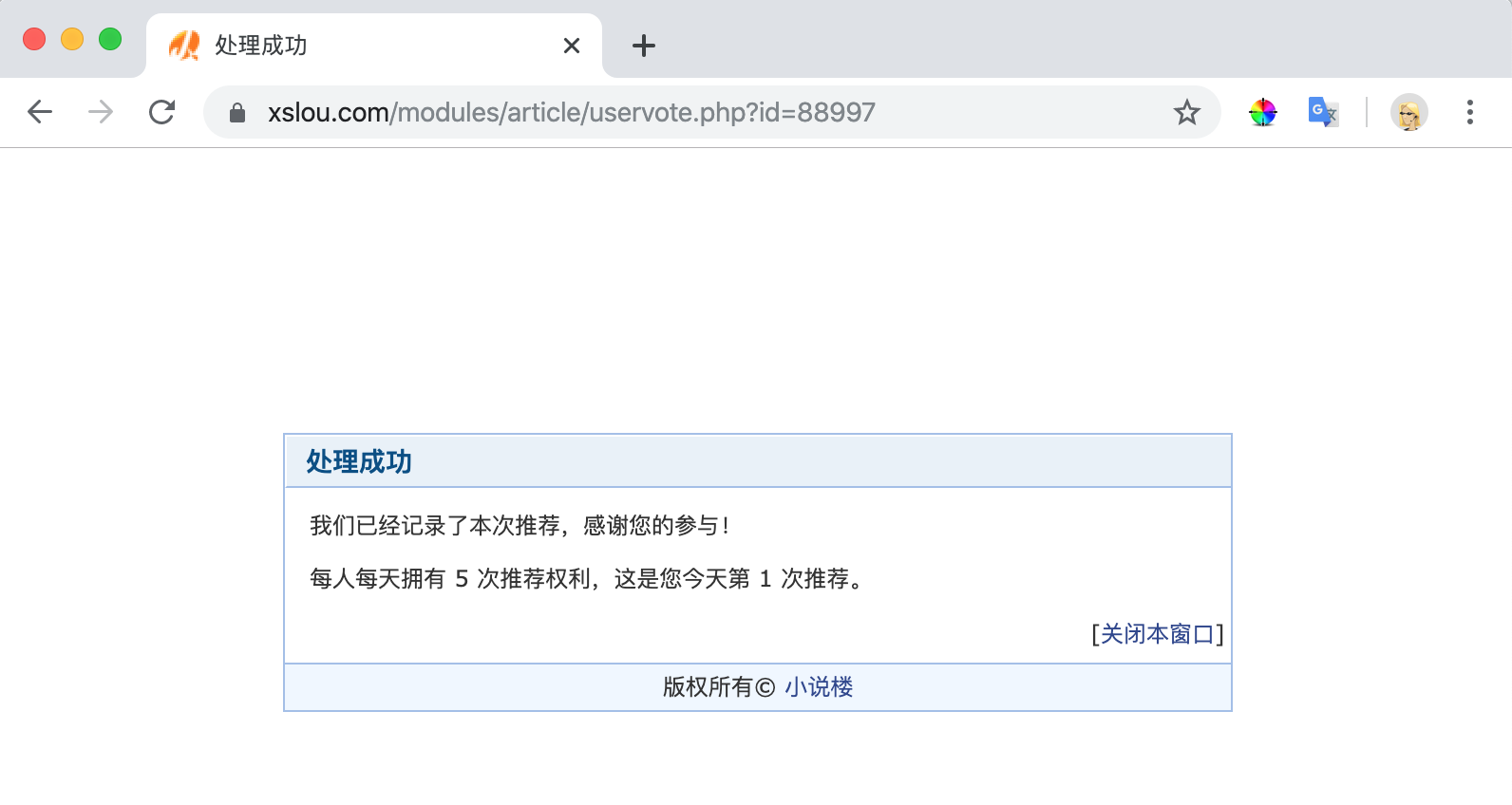
1)完成登录之后,再进行推荐会跳转新页面,提示推荐成功
2)通过翻找Network,我们定位到,推荐的请求是就是当前的url:https://www.xslou.com/modules/article/uservote.php?id=xxx
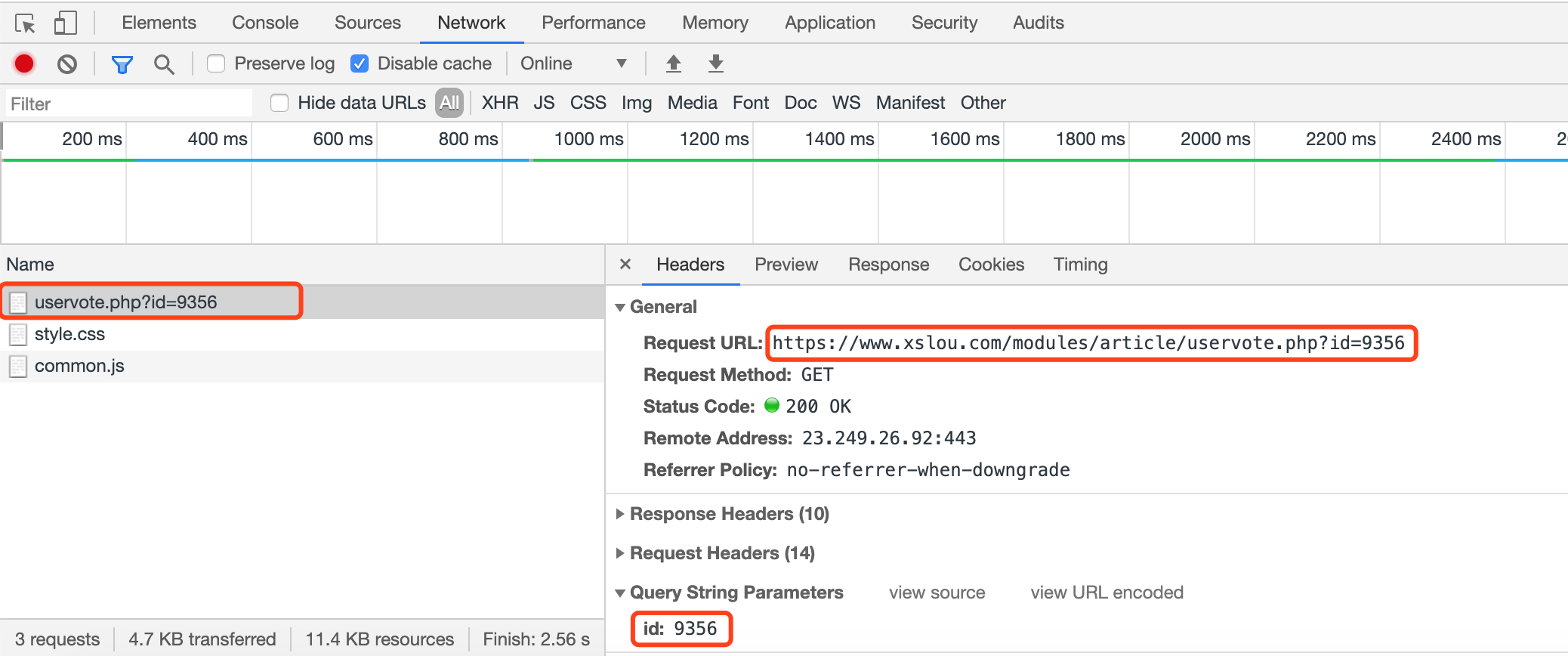
该请求只需要一个参数:id(书籍的id)
注意:该链接限制了每天推荐不能超过5次,也就是说该链接的请求不能超过5次
5.获取书籍id
1)进入小说热门列表页面:https://www.xslou.com/top/allvisit_1/右键检查,
发现该页面的数据就在第0个请求当中。
2)模拟推荐书籍《纯阳武神》时,拿到的id是9356,
不过这个id到底从哪里来的?
要么,它藏在了HTML网页当中;
要么,它就是在请求的时候,后台下发的。
可先在Elements搜索一下该id,看它在不在HTML里。
(【搜索快捷键】win:ctrl+f | mac:command+f)
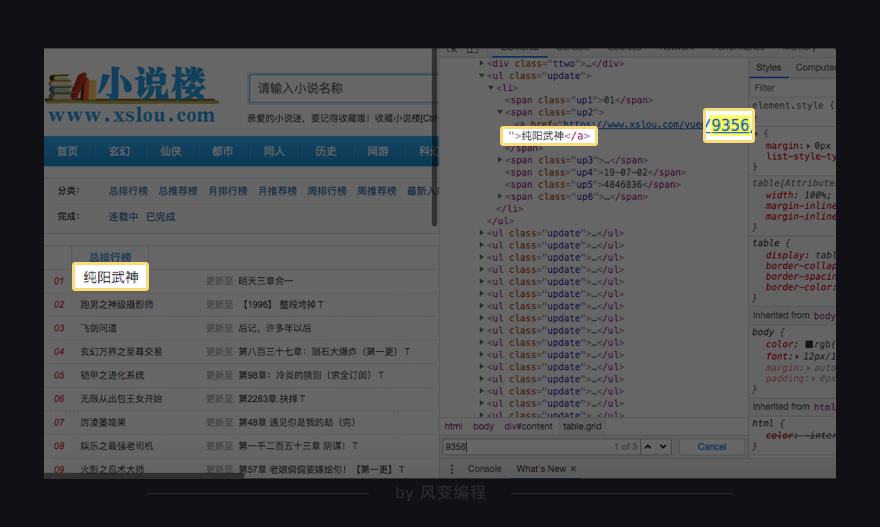
3)经过分析,发现id确实藏在了HTML页面的链接当中:https://www.xslou.com/yuedu/9356/
4)下一步就是将数字9356从链接中分离出来,方法有很多,老师这里只讲解过滤器filter过滤数字。
link = 'https://www.xslou.com/yuedu/9356/'
# 字符串link过滤出数字id(9356)
id_list = list(filter(str.isdigit,link))
book_id = ''.join(id_list)
# 步骤解析:1、filter()过滤数字 2、filter对象转列表 3、列表转字符串
# filter(str.isdigit,字符串)
# 第一个参数用来判断字符串的单个元素是否是数字,数字保留
# filter()返回的是对象,需要用list()函数转换成列表
# ''.join(列表)将列表转换成字符串6.思考实现方案
所以正确的流程应该是:
- 模拟登录获取cookies
- 拿到书籍的id
- 使用id参数和cookies请求推荐
注:其中,前两步可以顺序调换。
7.1.3 代码实现
1.使用session和cookies模拟登录
体验登录:https://www.xslou.com/login.php
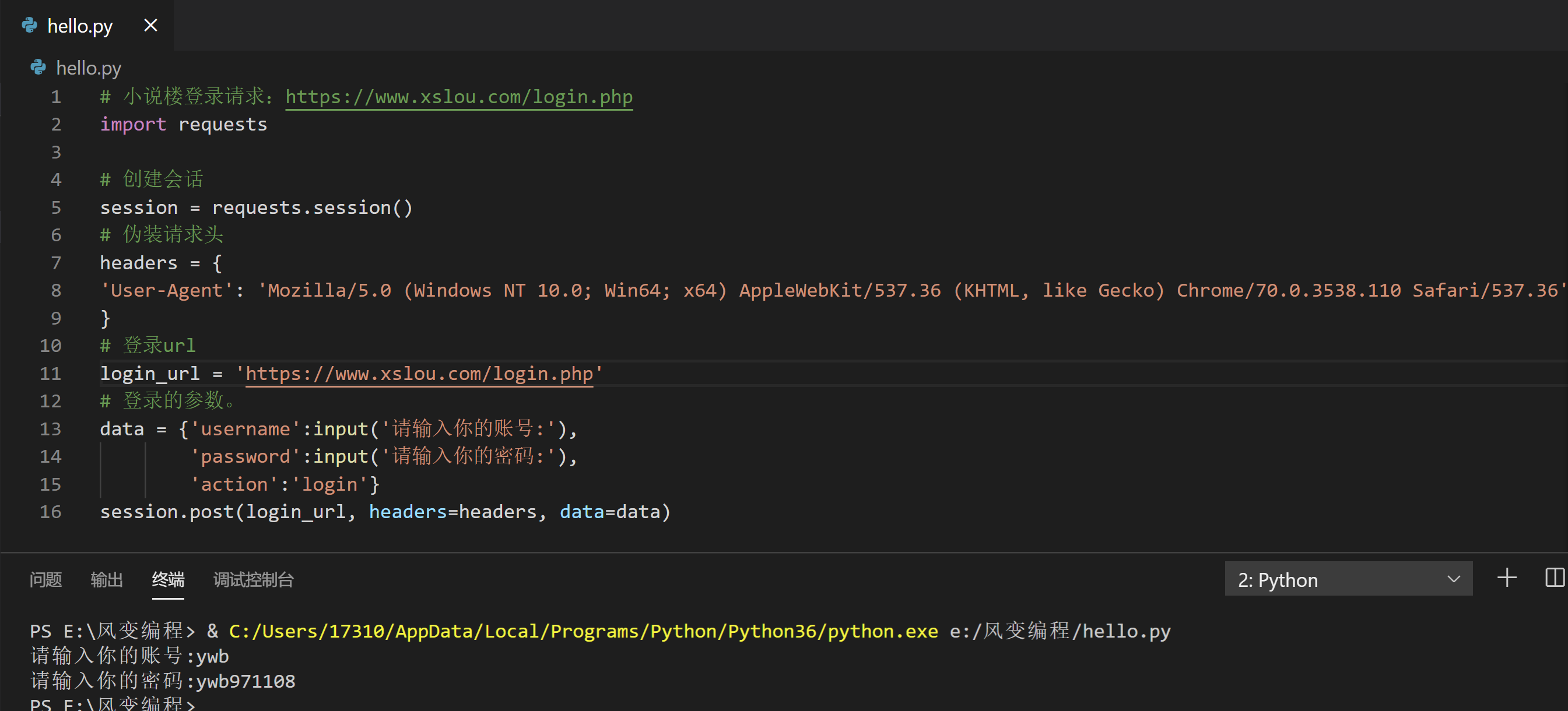
# 小说楼登录请求:https://www.xslou.com/login.php
import requests
# 创建会话
session = requests.session()
# 伪装请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
# 登录url
login_url = 'https://www.xslou.com/login.php'
# 登录的参数。
data = {'username':input('请输入你的账号:'),
'password':input('请输入你的密码:'),
'action':'login'}
session.post(login_url, headers=headers, data=data)2.获取书籍id
想要请求推荐XHR,我们需要拿到参数id,也就是书籍id
小说排行榜:https://www.xslou.com/top/allvisit_1/
提示:
- 本步骤不需要模拟登录
- 网站的编码模式是gbk
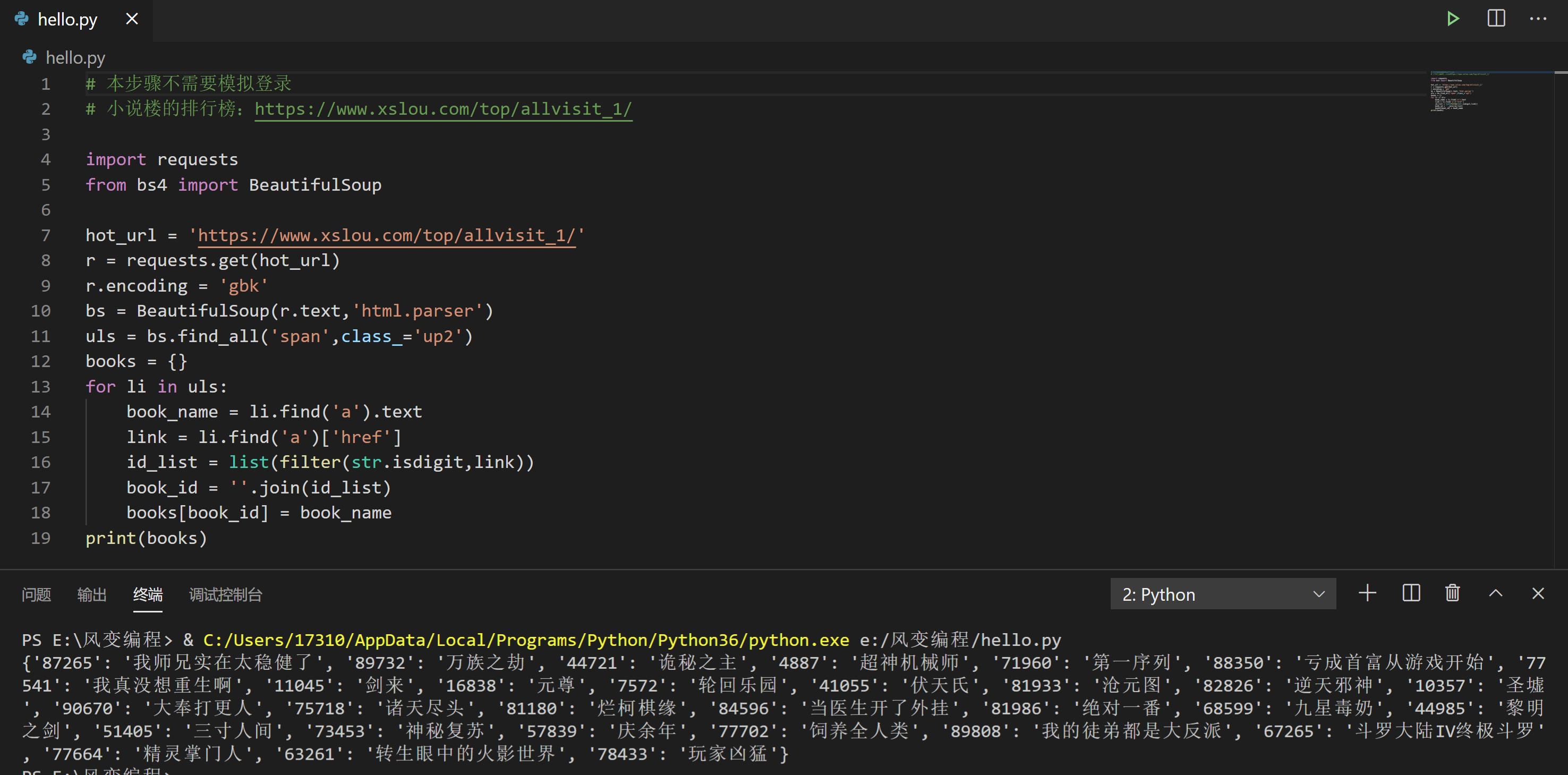
# 本步骤不需要模拟登录
# 小说楼的排行榜:https://www.xslou.com/top/allvisit_1/
import requests
from bs4 import BeautifulSoup
hot_url = 'https://www.xslou.com/top/allvisit_1/'
r = requests.get(hot_url)
r.encoding = 'gbk'
bs = BeautifulSoup(r.text,'html.parser')
uls = bs.find_all('span',class_='up2')
books = {}
for li in uls:
book_name = li.find('a').text
link = li.find('a')['href']
id_list = list(filter(str.isdigit,link))
book_id = ''.join(id_list)
books[book_id] = book_name
print(books)3.带cookies和参数请求推荐链接
将上述两组代码组合。
拿到cookies和参数,完成推荐请求(不要超过5次)
我帮你预置了前两个代码,你可以在此基础上完成本关卡任务。
注意:
- 请求url需要拼接书籍id
- 请求时候别忘了添加请求头和cookies:cookies=
session.cookies
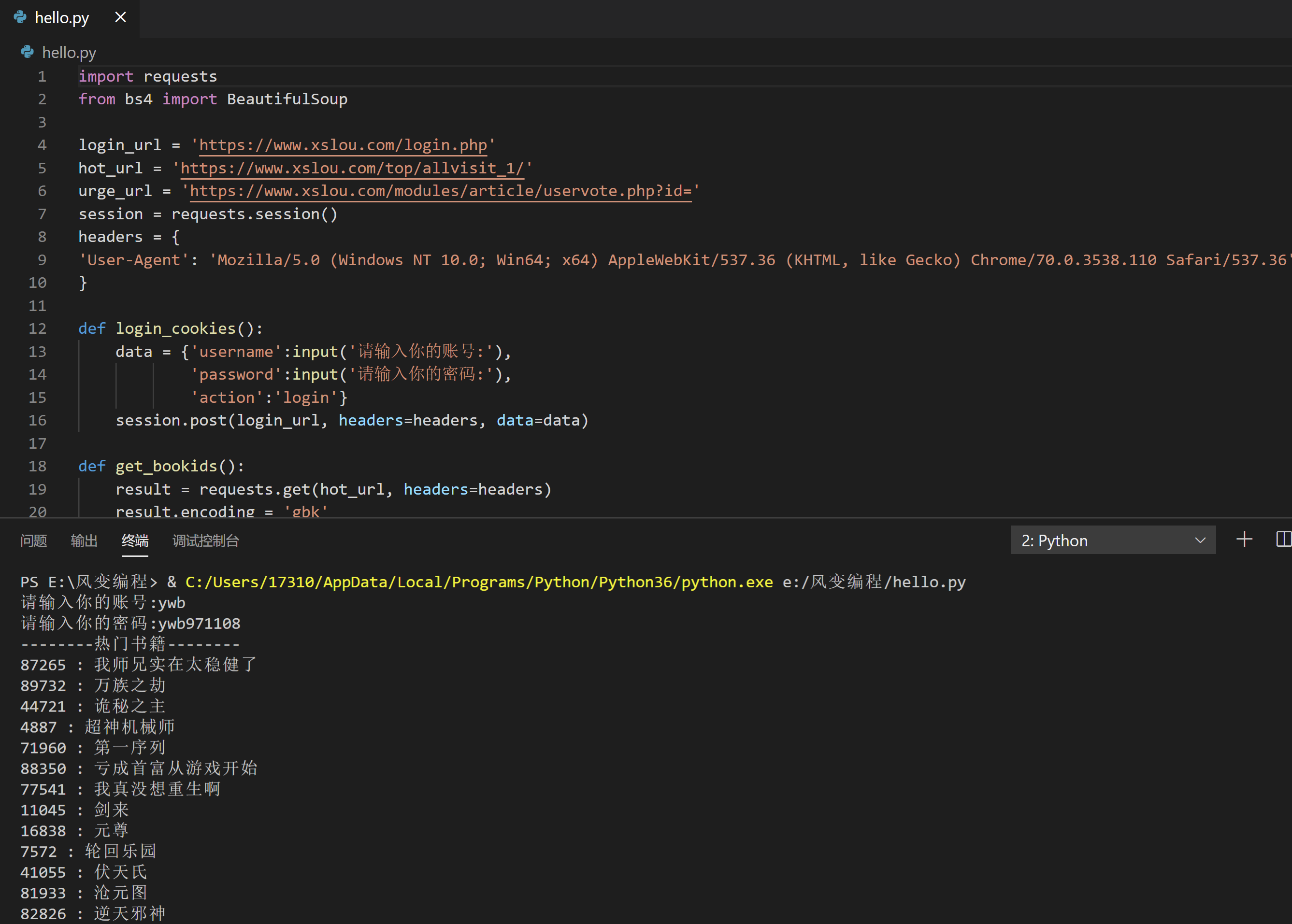
# 将上述两组代码组合。拿到cookies和参数,完成推荐请求。
# 我帮你预置了前两个代码,你可以在此基础上完成本关卡任务。
# 小说楼:https://www.xslou.com/
# 小说楼登录:https://www.xslou.com/login.php
# 小说楼的排行榜:https://www.xslou.com/top/allvisit_1/
# 小说楼推荐:https://www.xslou.com/modules/article/uservote.php?id=
import requests
from bs4 import BeautifulSoup
login_url = 'https://www.xslou.com/login.php'
hot_url = 'https://www.xslou.com/top/allvisit_1/'
urge_url = 'https://www.xslou.com/modules/article/uservote.php?id='
session = requests.session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
def login_cookies():
data = {'username':input('请输入你的账号:'),
'password':input('请输入你的密码:'),
'action':'login'}
session.post(login_url, headers=headers, data=data)
def get_bookids():
result = requests.get(hot_url, headers=headers)
result.encoding = 'gbk'
bs = BeautifulSoup(result.text,'html.parser')
uls = bs.find_all('span',class_='up2')
books = {}
for li in uls:
book_name = li.find('a').text
link = li.find('a')['href']
id_list = list(filter(str.isdigit,link))
book_id = ''.join(id_list)
books[book_id] = book_name
return books
def urge(book_id):
url = urge_url+book_id
result = session.get(url, headers=headers, cookies=session.cookies)
result.encoding = 'gbk'
if result.status_code == 200:
bs = BeautifulSoup(result.text,'html.parser')
urge_info = bs.find('div',class_='blocktitle').get_text()
urge_info2 = bs.find('div',class_='blockcontent').get_text()
print(urge_info)
print(urge_info2)
def main ():
login_cookies()
books = get_bookids()
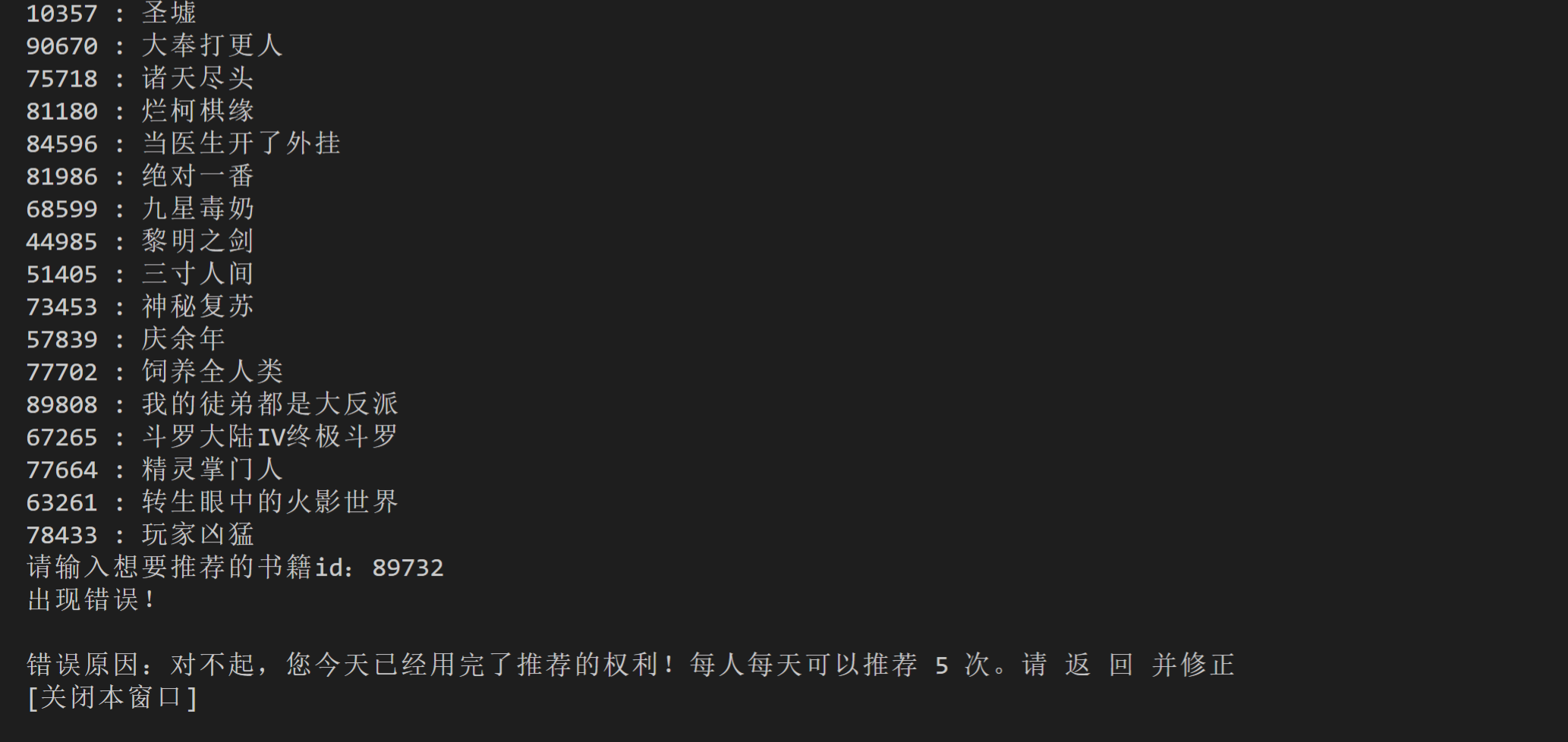
print('--------热门书籍--------')
for k,v in books.items():
print(k,':',v)
book_id = input('请输入想要推荐的书籍id:')
urge(book_id)
main()7.2 习题二
7.2.1 题目要求
1.练习介绍
想不想自己动手做个翻译器呢,一点都不难哦~
就用你学过的post和json,一起试试爬取有道翻译自制翻译器吧ლ(^ω^ლ)
2.要求
实现功能:用户输入英文或中文,程序即可打印出来对应的译文。
7.2.2 第一步:分析问题,明确目标
1.实现功能:用户输入英文或中文,程序即可打印出来对应的译文。
2.步骤讲解
这个页面,我们在左边输入文字,那么浏览器会把输入的信息传输给服务器,再返回对应的内容。
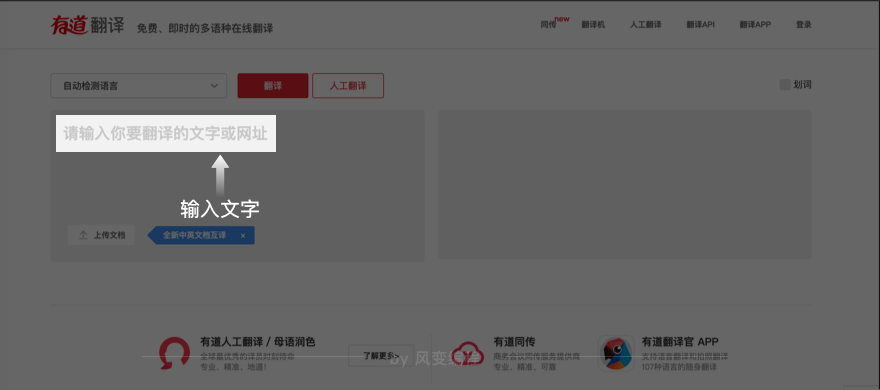
3.我们希望达成的效果如下图,即用户输入英文或中文,程序即可打印出来对应的译文:

7.2.3 第二步:思考要用到的知识
步骤讲解
实现一键翻译的功能,最简单的方案便是爬虫。在此,我们选择的网站是有道翻译。http://fanyi.youdao.com/
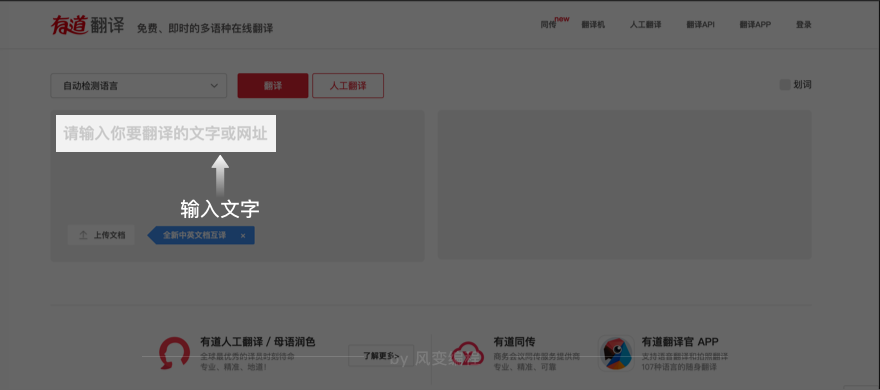
这个页面,你在左边输入文字,那么浏览器会把你输入的信息传输给服务器。再返回对应的内容。
这就是一个典型的Post操作。
我们在Headers也可以看到“Request Method: POST”哦
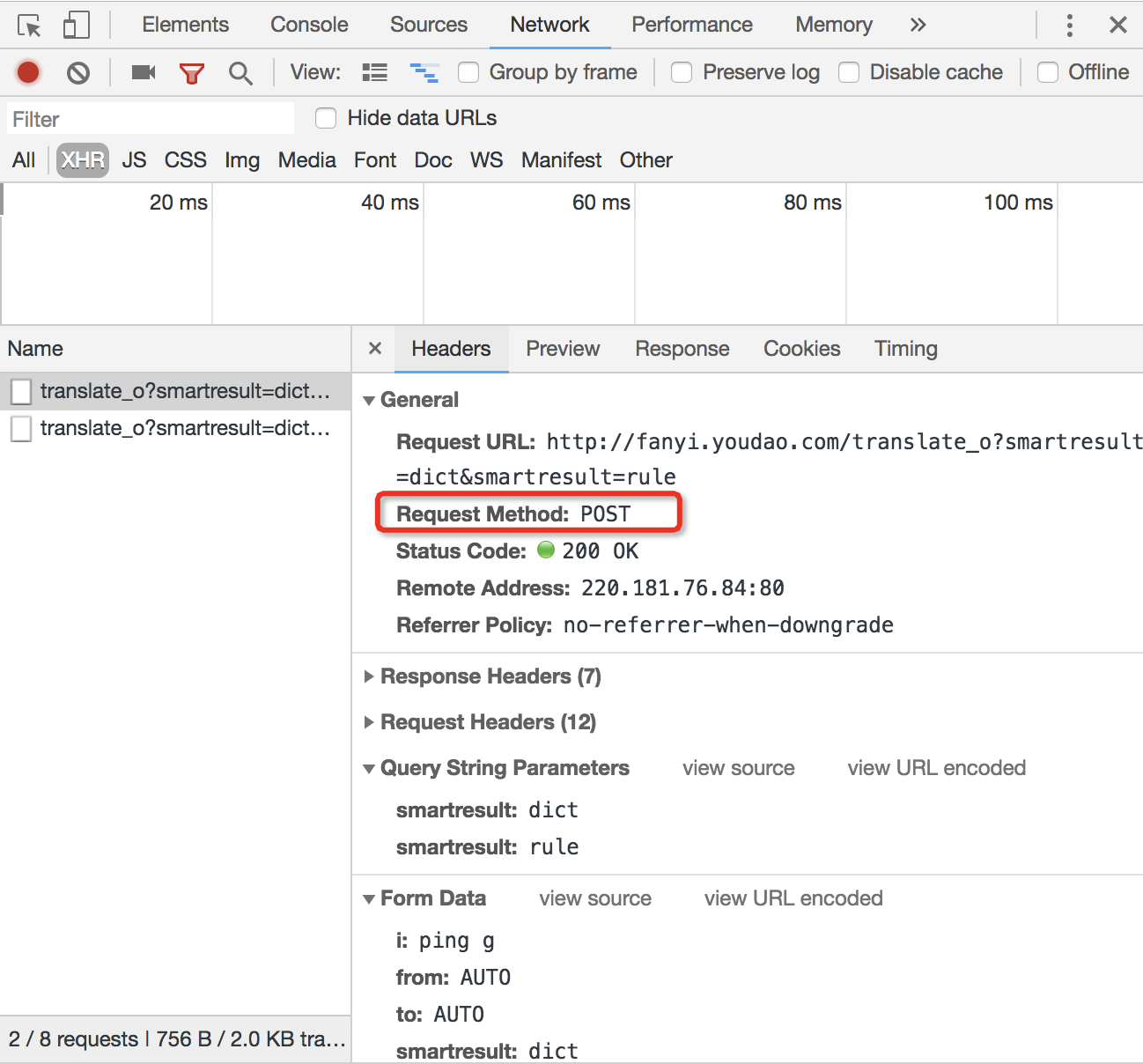
在前几关练习我们用的都是Get方式请求,Post是另一种常见的方式,课上已经学过其用法,在此不多赘述。
Get是向服务器发索取数据的一种请求,而Post是向服务器提交数据的一种请求
虽然第九关我们主要讲的是Cookies,
Cookies用于服务器实现会话,用户登录及相关功能时进行状态管理
但这道题并不需要用到小饼干,因为不需要登录不需要账号密码等。
主要考查的还是Post的用法。
注意哦 ლ(╹◡╹ლ)
有道翻译有反爬虫机制,它使用了加密技术。如果你的程序报错,你可以通过搜索、查阅资料找到解决方案:尝试把访问的网址中“/translate_o”中的“_o”删除。
服务器返回的内容,是json的格式。我们可以用处理列表、处理字典的手段来提取翻译。
7.2.4 第三步:写代码
你可以在浏览器的[network]-[Headers]-[General]里找到需要访问的网址,在[network]-[Headers]-[From data]里找到需要上传的数据。
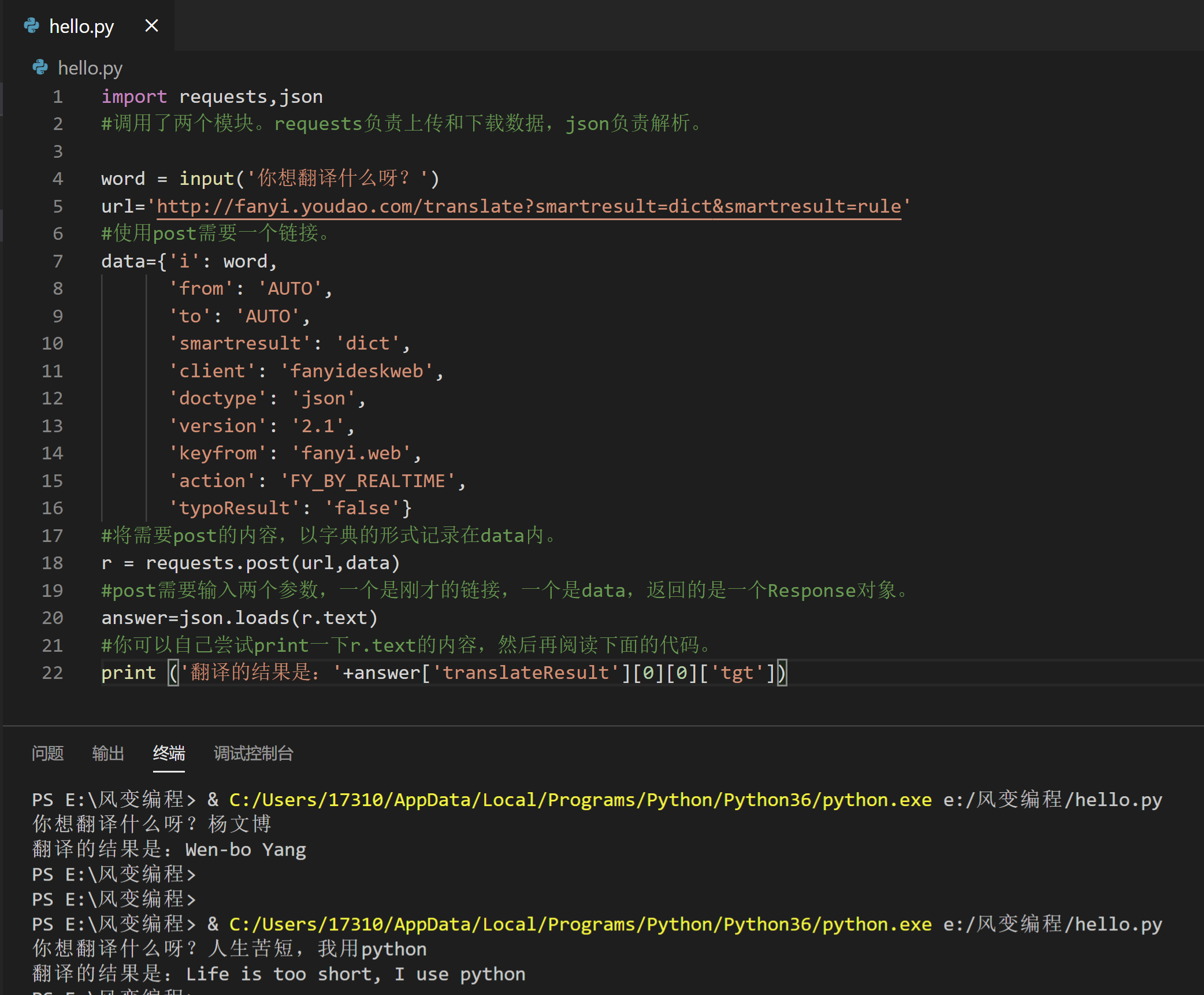
import requests,json
#调用了两个模块。requests负责上传和下载数据,json负责解析。
word = input('你想翻译什么呀?')
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
#使用post需要一个链接。
data={'i': word,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTIME',
'typoResult': 'false'}
#将需要post的内容,以字典的形式记录在data内。
r = requests.post(url,data)
#post需要输入两个参数,一个是刚才的链接,一个是data,返回的是一个Response对象。
answer=json.loads(r.text)
#你可以自己尝试print一下r.text的内容,然后再阅读下面的代码。
print ('翻译的结果是:'+answer['translateResult'][0][0]['tgt'])7.2.5 第四步:套层壳(小彩蛋,了解即可,感兴趣的话可以深入学习)
我们总会听到前端后端全栈,感觉神秘有高大上,你一定很好奇它们都是什么呀?
今天呢,我们就简单接触下前端~
有米有很期待呀(́>◞౪◟<‵)ノシ
前端,是一种GUI软件。而我们现在要用的是Python里的一个模块实现本地窗口的功能。
它就是Tkinter~
Tkinter 模块是 Python 的标准 Tk GUI 工具包的接口。
Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 MacOS系统里。
Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中。
http://www.runoob.com/python/python-gui-tkinter.html
最后的代码大约是这个模样,注意阅读注释,
当然你可以在终端运行(复制)这些代码,观察效果~
认真阅读注释,你也可以复制下来在你的IDE中运行下哦~
import requests
import json
from tkinter import Tk,Button,Entry,Label,Text,END
class YouDaoFanyi(object):
def __init__(self):
pass
def crawl(self,word):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
#使用post需要一个链接
data={'i': word,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTIME',
'typoResult': 'false'}
#将需要post的内容,以字典的形式记录在data内。
r = requests.post(url, data)
#post需要输入两个参数,一个是刚才的链接,一个是data,返回的是一个Response对象
answer=json.loads(r.text)
#你可以自己尝试print一下r.text的内容,然后再阅读下面的代码。
result = answer['translateResult'][0][0]['tgt']
return result
class Application(object):
def __init__(self):
self.window = Tk()
self.fanyi = YouDaoFanyi()
self.window.title(u'我的翻译')
#设置窗口大小和位置
self.window.geometry('310x370+500+300')
self.window.minsize(310,370)
self.window.maxsize(310,370)
#创建一个文本框
#self.entry = Entry(self.window)
#self.entry.place(x=10,y=10,width=200,height=25)
#self.entry.bind("<Key-Return>",self.submit1)
self.result_text1 = Text(self.window,background = 'azure')
# 喜欢什么背景色就在这里面找哦,但是有色差,得多试试:http://www.science.smith.edu/dftwiki/index.php/Color_Charts_for_TKinter
self.result_text1.place(x = 10,y = 5,width = 285,height = 155)
self.result_text1.bind("<Key-Return>",self.submit1)
#创建一个按钮
#为按钮添加事件
self.submit_btn = Button(self.window,text=u'翻译',command=self.submit)
self.submit_btn.place(x=205,y=165,width=35,height=25)
self.submit_btn2 = Button(self.window,text=u'清空',command = self.clean)
self.submit_btn2.place(x=250,y=165,width=35,height=25)
#翻译结果标题
self.title_label = Label(self.window,text=u'翻译结果:')
self.title_label.place(x=10,y=165)
#翻译结果
self.result_text = Text(self.window,background = 'light cyan')
self.result_text.place(x = 10,y = 190,width = 285,height = 165)
#回车翻译
def submit1(self,event):
#从输入框获取用户输入的值
content = self.result_text1.get(0.0,END).strip().replace("\n"," ")
#把这个值传送给服务器进行翻译
result = self.fanyi.crawl(content)
#将结果显示在窗口中的文本框中
self.result_text.delete(0.0,END)
self.result_text.insert(END,result)
#print(content)
def submit(self):
#从输入框获取用户输入的值
content = self.result_text1.get(0.0,END).strip().replace("\n"," ")
#把这个值传送给服务器进行翻译
result = self.fanyi.crawl(content)
#将结果显示在窗口中的文本框中
self.result_text.delete(0.0,END)
self.result_text.insert(END,result)
print(content)
#清空文本域中的内容
def clean(self):
self.result_text1.delete(0.0,END)
self.result_text.delete(0.0,END)
def run(self):
self.window.mainloop()
if __name__=="__main__":
app = Application()
app.run()做出来的效果就是下图:
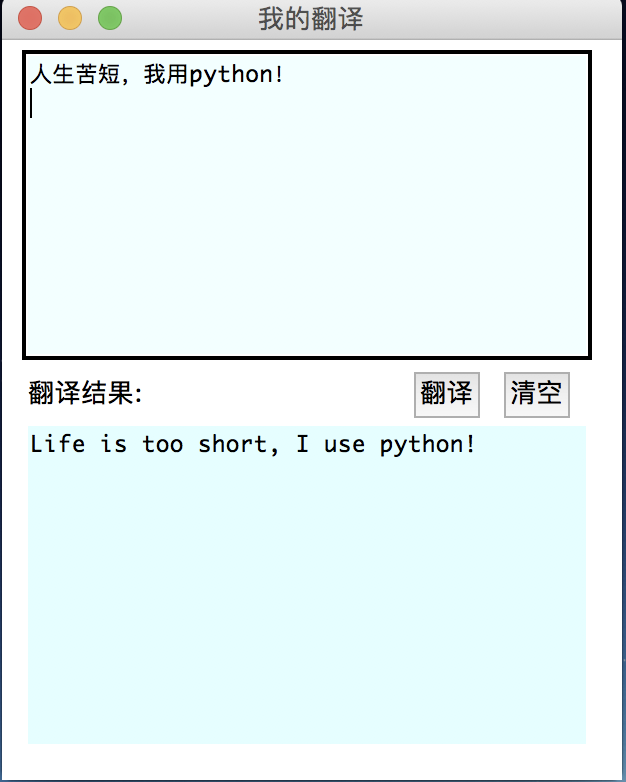
7.3 习题三
7.3.1 题目要求
1.练习介绍
学了爬虫这么久,想不想接触下AI,创建一个可以聊天的机器人呀٩̋(๑˃́ꇴ˂̀๑)
2.要求:
实现功能:利用图灵机器人官网http://www.tuling123.com/的接口,创建一个可以聊天的机器人
7.3.2 第一步:登录注册图灵机器人
1.注册登录,才能创建自己的图灵机器人。
根据帮助中心的“说明书”,我们可以了解如何运用这个新工具~
2.步骤讲解
进入图灵机器人官网http://www.tuling123.com/,戳进帮助中心。
就像打开玩具先看说明书一样,我们来看看官方文档怎么说怎么用~
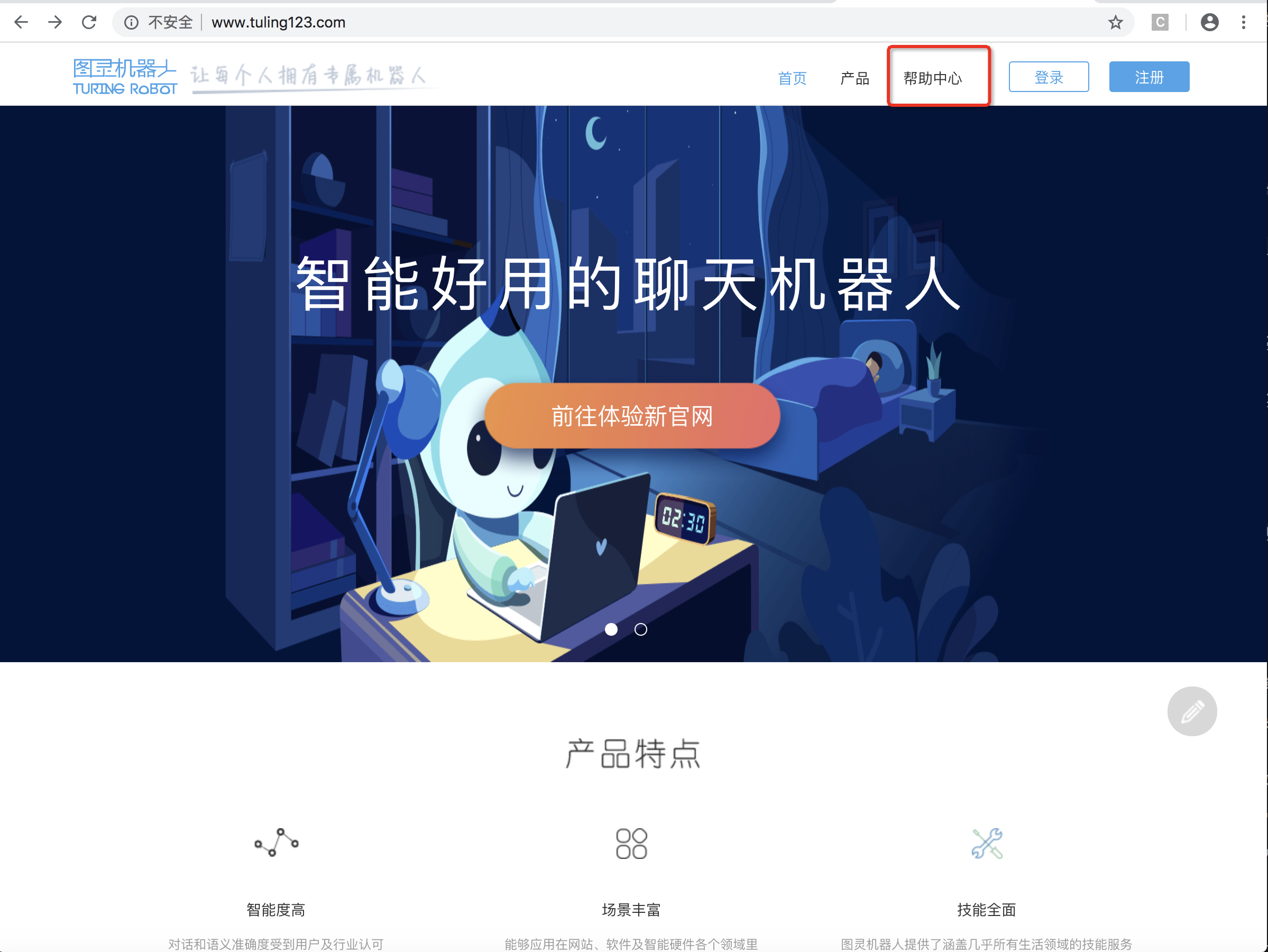
在功能说明中,我们知道,首先得登录注册,用免费版本就可以了(当然~土豪请随意),创建机器人
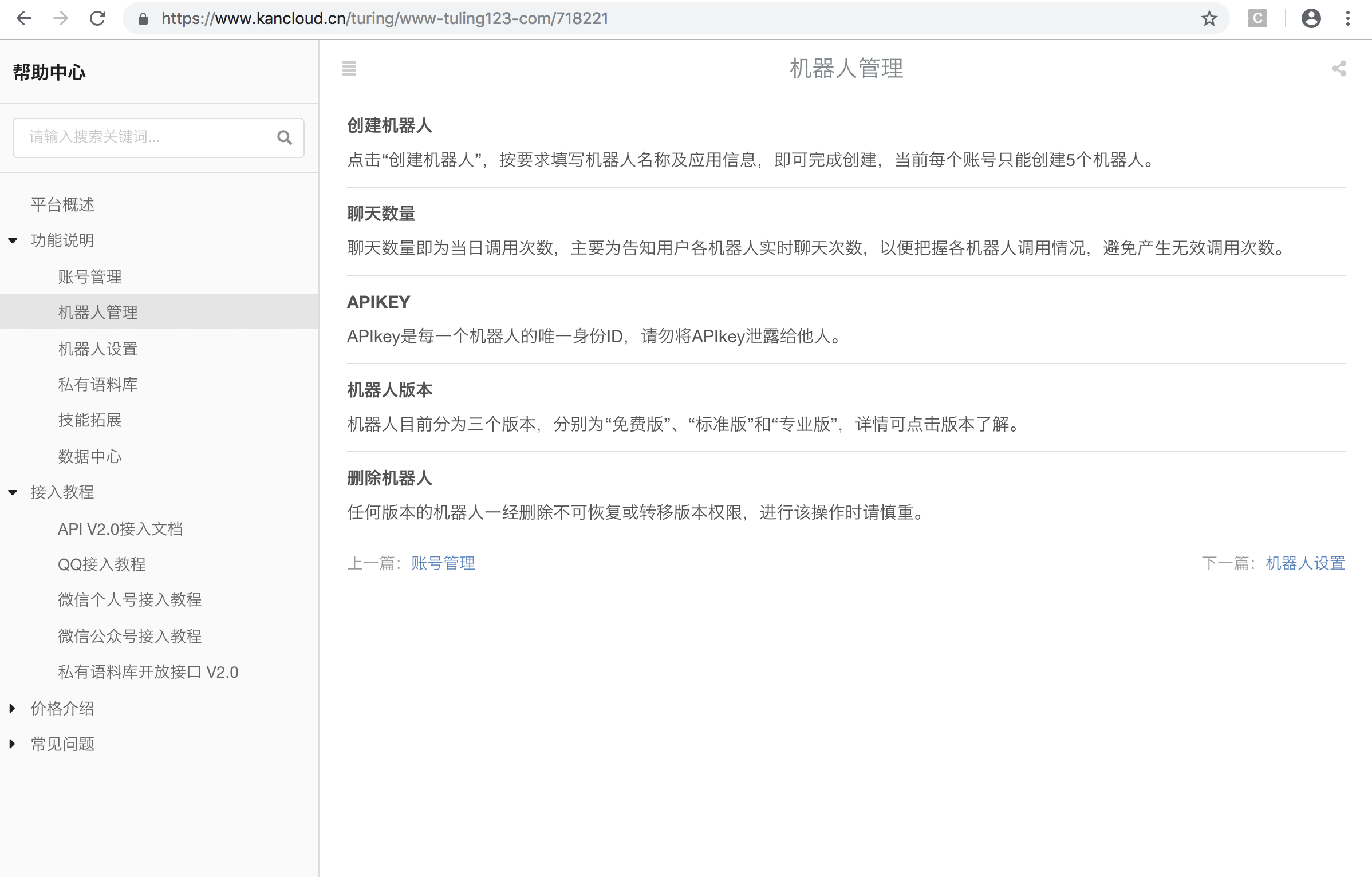
在“机器人设置”中,我们用的是第一个API接入
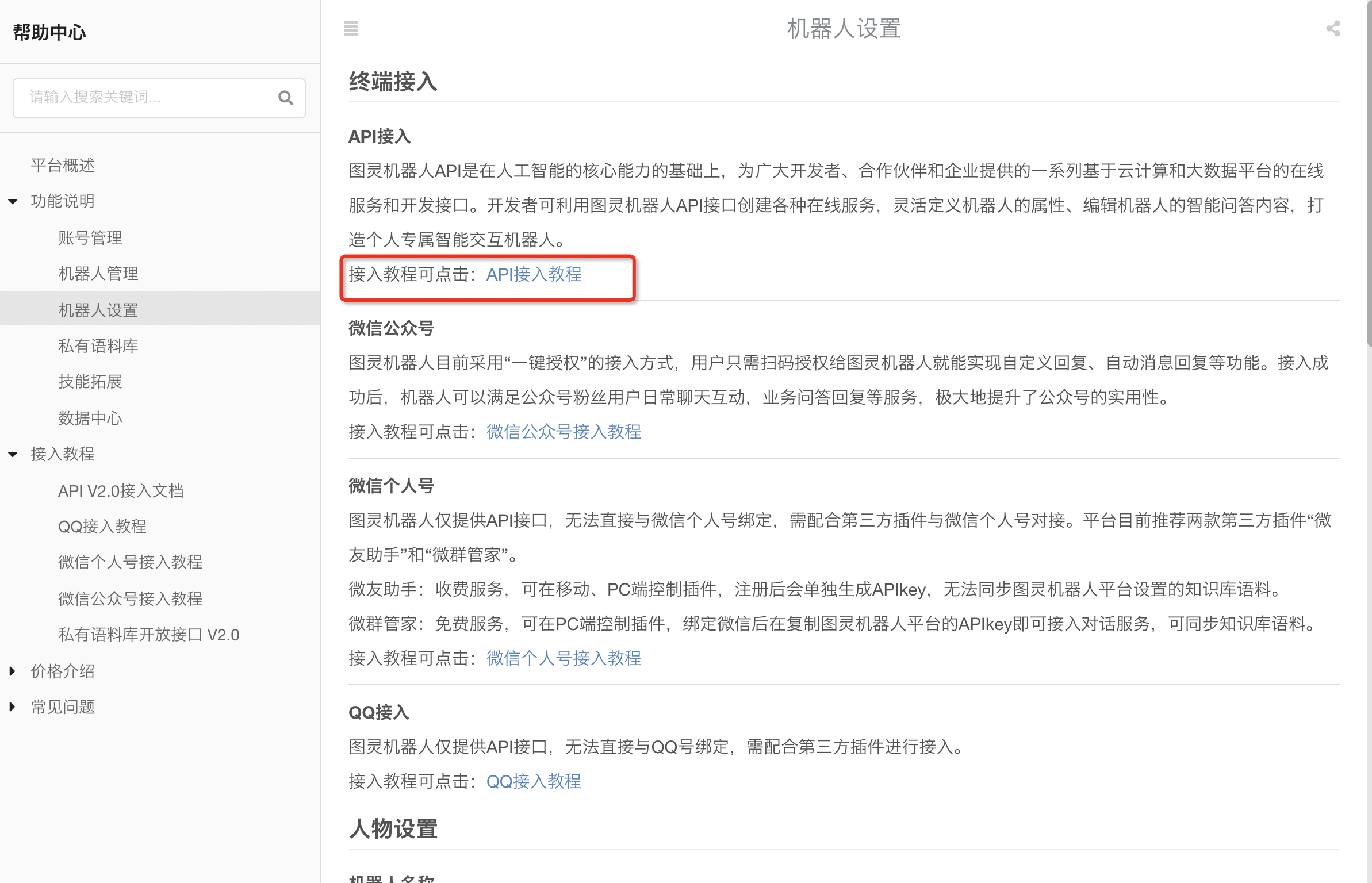
那什么是API呢?通俗地讲:
API就是接口,就是通道,负责一个程序和其他软件的沟通,本质是预先定义的函数,而我们不需要了解这个函数只是调用这个接口就可达到函数的效果。
好,接下来我们看下“API V2.0接入文档”.
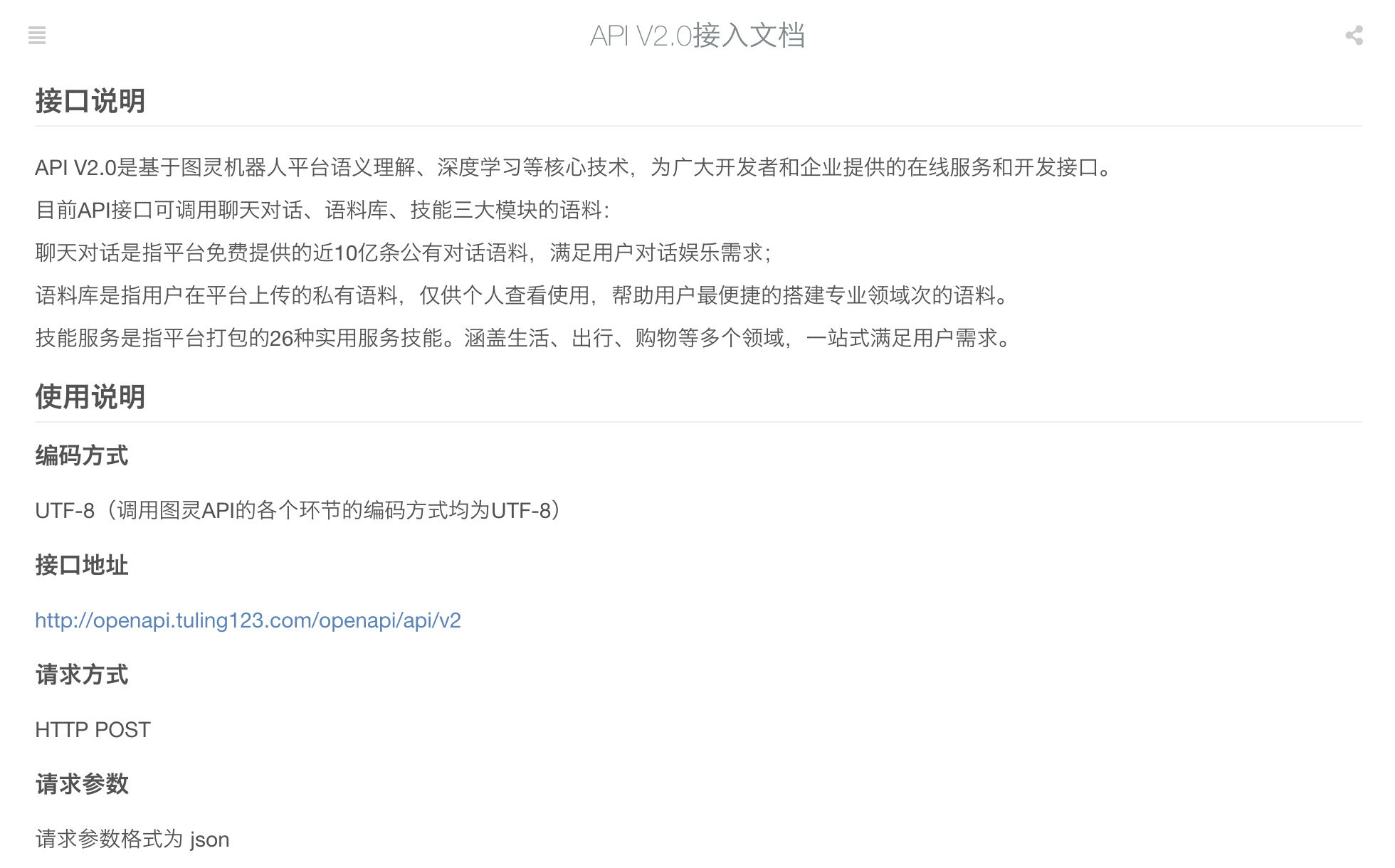
接口说明:API接口可调用聊天对话、语料库、技能三大模块的语料。
很好,我们今天想做的聊天机器人用这个接口就刚巧合适~
同时,在使用说明中我们可以知晓:
首先创建post请求所需的json数据,然后向指定的接口发起post请求即可,
而且从参数说明中可以看到,只有参数 perception 和 userinfo 才是必须的.
对于userid这个参数官方文档说的是:长度小于32,是用户的唯一标识,这里我们只要创建userid 是长度小于32的字符串即可
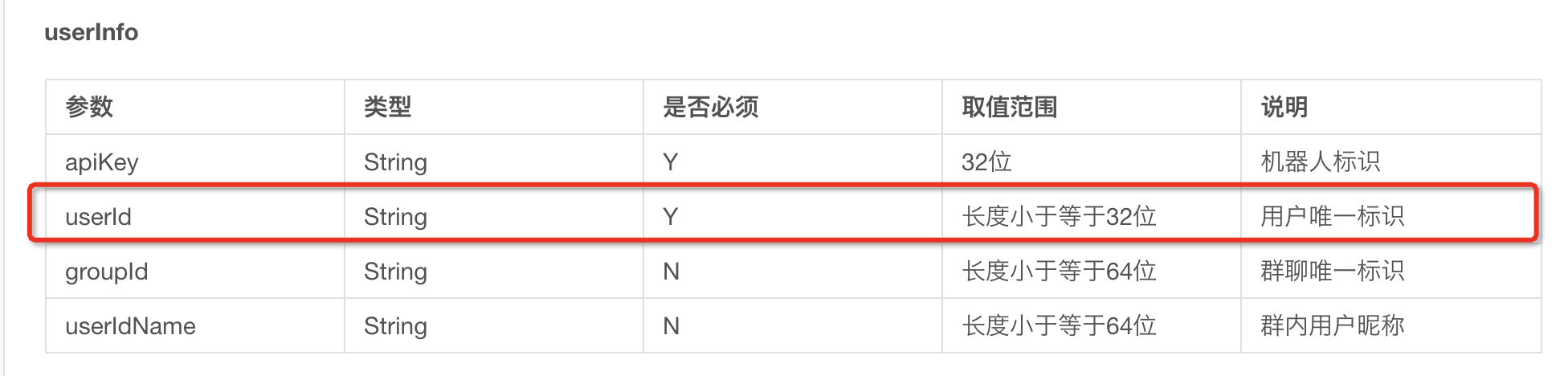
说明书已经看完啦,来,开始着手做准备工作!
那我们回到主页,注册登录
然后在机器人管理界面,创建图灵机器人,最多可以创建5个,由此得出对应的5个apikey。(实际上一个就够啦)
apikey是针对接口访问的授权方式。
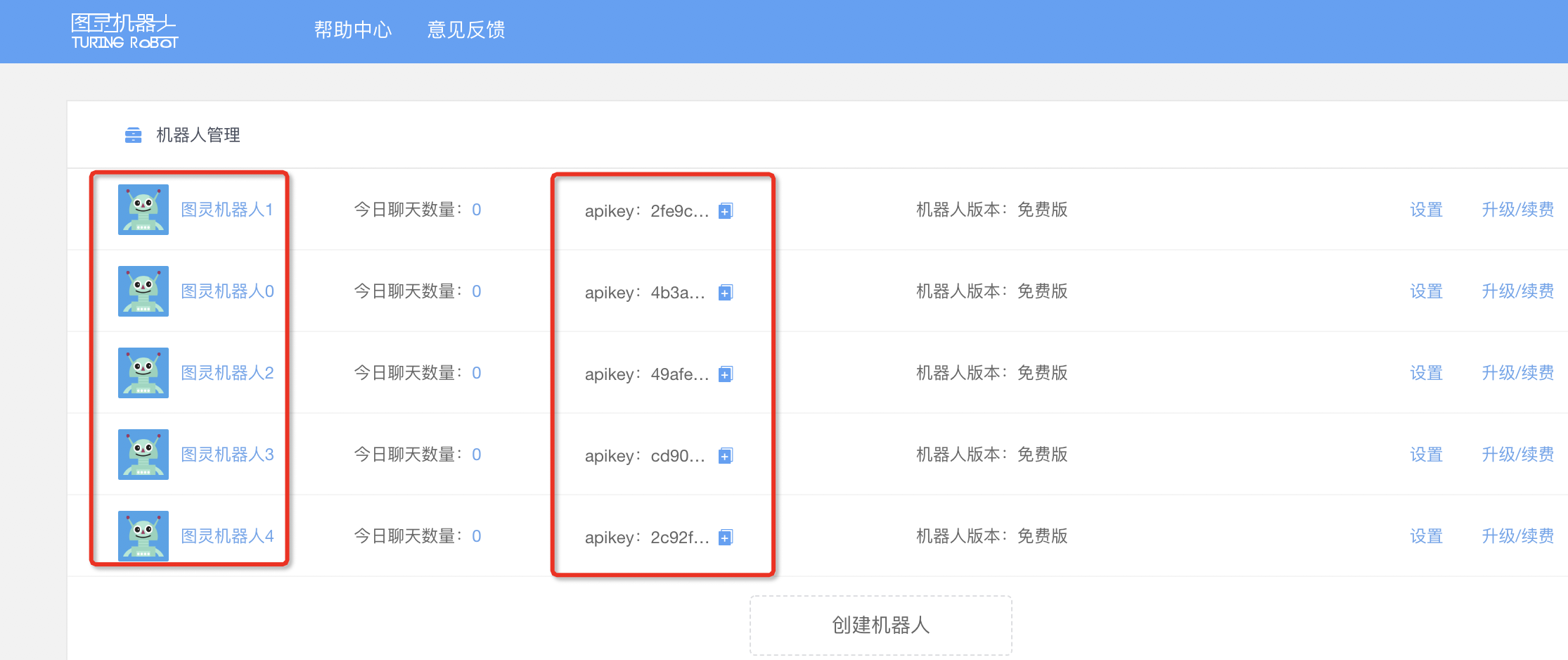
准备工作做完啦,接下来想想该如何写代码
7.3.3 第二步:创建自己的聊天机器人
请求过程:首先创建post请求所需的json数据,然后向指定的接口发起post请求即可,
而且从参数说明中可以看到,只有参数 perception 和 userinfo 才是必须的
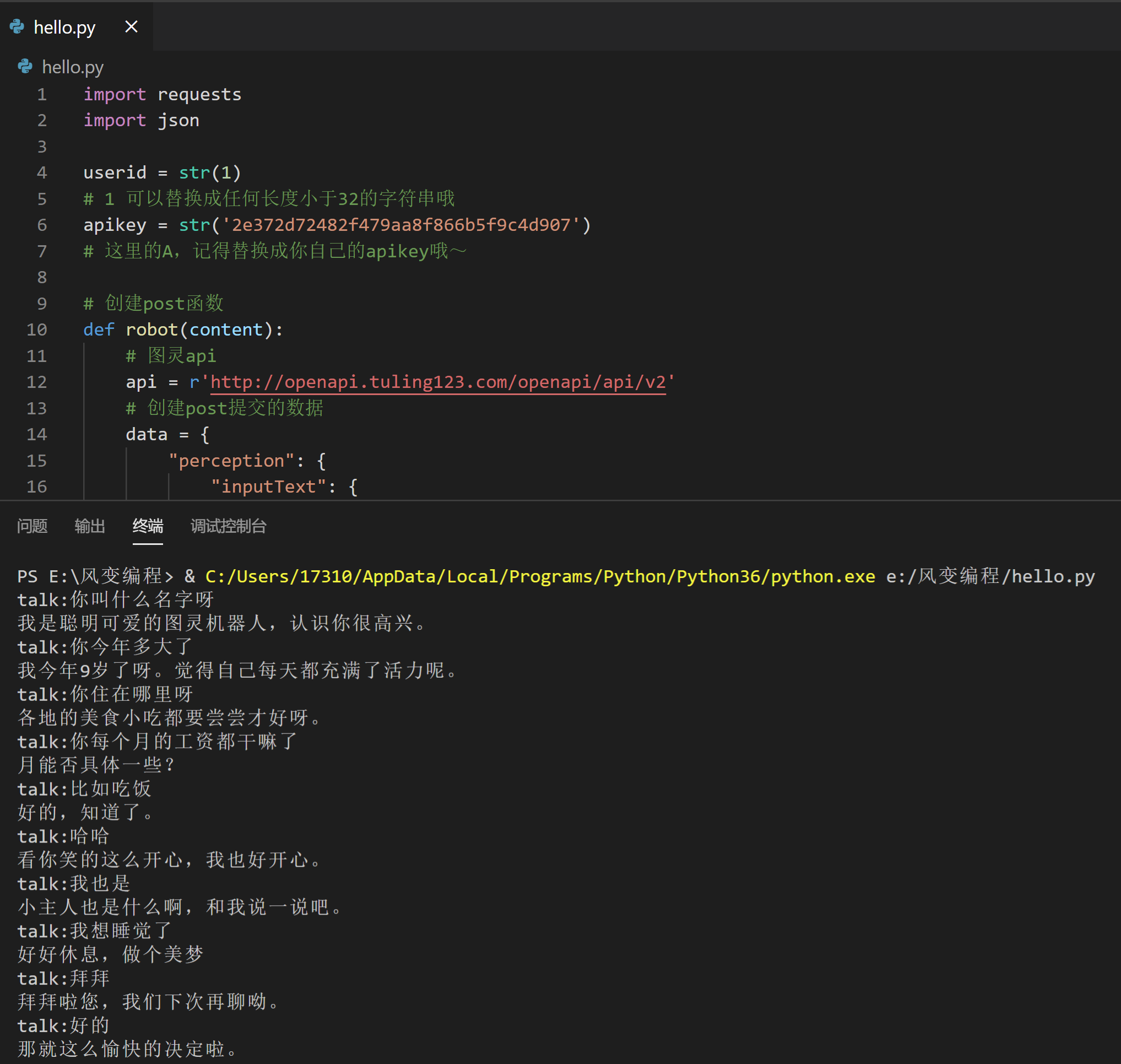
import requests
import json
userid = str(1)
# 1 可以替换成任何长度小于32的字符串哦
apikey = str('2e372d72482f479aa8f866b5f9c4d907')
# 这里的A,记得替换成你自己的apikey哦~
# 创建post函数
def robot(content):
# 图灵api
api = r'http://openapi.tuling123.com/openapi/api/v2'
# 创建post提交的数据
data = {
"perception": {
"inputText": {
"text": content
}
},
"userInfo": {
"apiKey": apikey,
"userId": userid,
}
}
# 转化为json格式
jsondata = json.dumps(data)
# 发起post请求
response = requests.post(api, data = jsondata)
# 将返回的json数据解码
robot_res = json.loads(response.content)
# 提取对话数据
print(robot_res["results"][0]['values']['text'])
for x in range(10):
content = input("talk:")
# 输入对话内容
robot(content)
if x == 10:
break
# 十次之后就结束对话,数字可以改哦,你想几次就几次标签:章节,cookies,登录,session,post,data,requests
来源: https://www.cnblogs.com/ywb123/p/16413298.html
本站声明:
1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享;
2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关;
3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关;
4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除;
5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。