ALBERT
作者:互联网
介绍
谷歌的研究者设计了一个精简的BERT(A Lite BERT,ALBERT),参数量远远少于传统的 BERT 架构。BERT (Devlin et al., 2019) 的参数很多,模型很大,内存消耗很大,在分布式计算中的通信开销很大。但是 BERT 的高内存消耗边际收益并不高,如果继续增大 BERT-large 这种大模型的隐含层大小,模型效果不升反降。
启发于 mobilenet,ALBERT 通过两个参数削减技术克服了扩展预训练模型面临的主要障碍:
- 第一个技术是对嵌入参数化进行因式分解。大的词汇嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与嵌入层的分离开。这种分离使得隐藏层的增加更加容易,同时不显著增加词汇嵌入的参数量。(不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,先映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。)
- 第二种技术是跨层参数共享。这一技术可以避免参数量随着网络深度的增加而增加。
两种技术都显著降低了 BERT 的参数量,同时不对其性能造成明显影响,从而提升了参数效率。ALBERT 的配置类似于 BERT-large,但参数量仅为后者的 1/18,训练速度却是后者的 1.7 倍。
- 训练任务方面:提出了Sentence-order prediction (SOP)来取代NSP。具体来说,其正例与NSP相同,但负例是通过选择一篇文档中的两个连续的句子并将它们的顺序交换构造的。这样两个句子就会有相同的话题,模型学习到的就更多是句子间的连贯性。用于句子级别的预测(SOP)。SOP 主要聚焦于句间连贯,用于解决原版 BERT 中下一句预测(NSP)损失低效的问题。
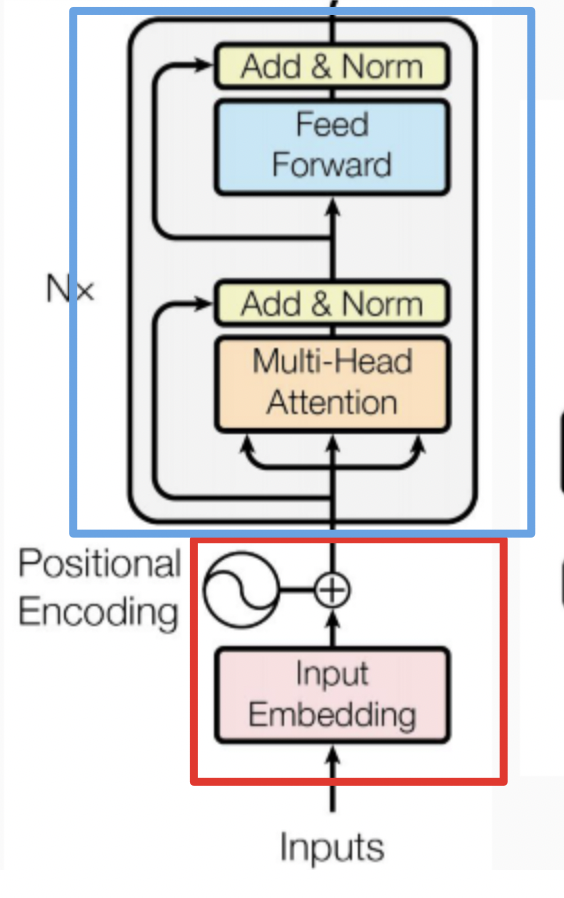
模型结构
ALBERT 架构的主干和 BERT 类似,都使用了基于 GELU 的非线性激活函数的 Transformer。但是其分别在两个地方减少了参数量。
以下图为例可以看到模型的参数主要集中在两块,一块是 Token embedding projection block,另一块是 Attention feed-forward block,前者占有 20% 的参数量,后者占有 80% 的参数量。
Factorized embedding parameterization
在 BERT 中,Token Embedding 的参数矩阵大小为\(V \times H\),其中V表示词汇的长度,H为隐藏层的大小。即:
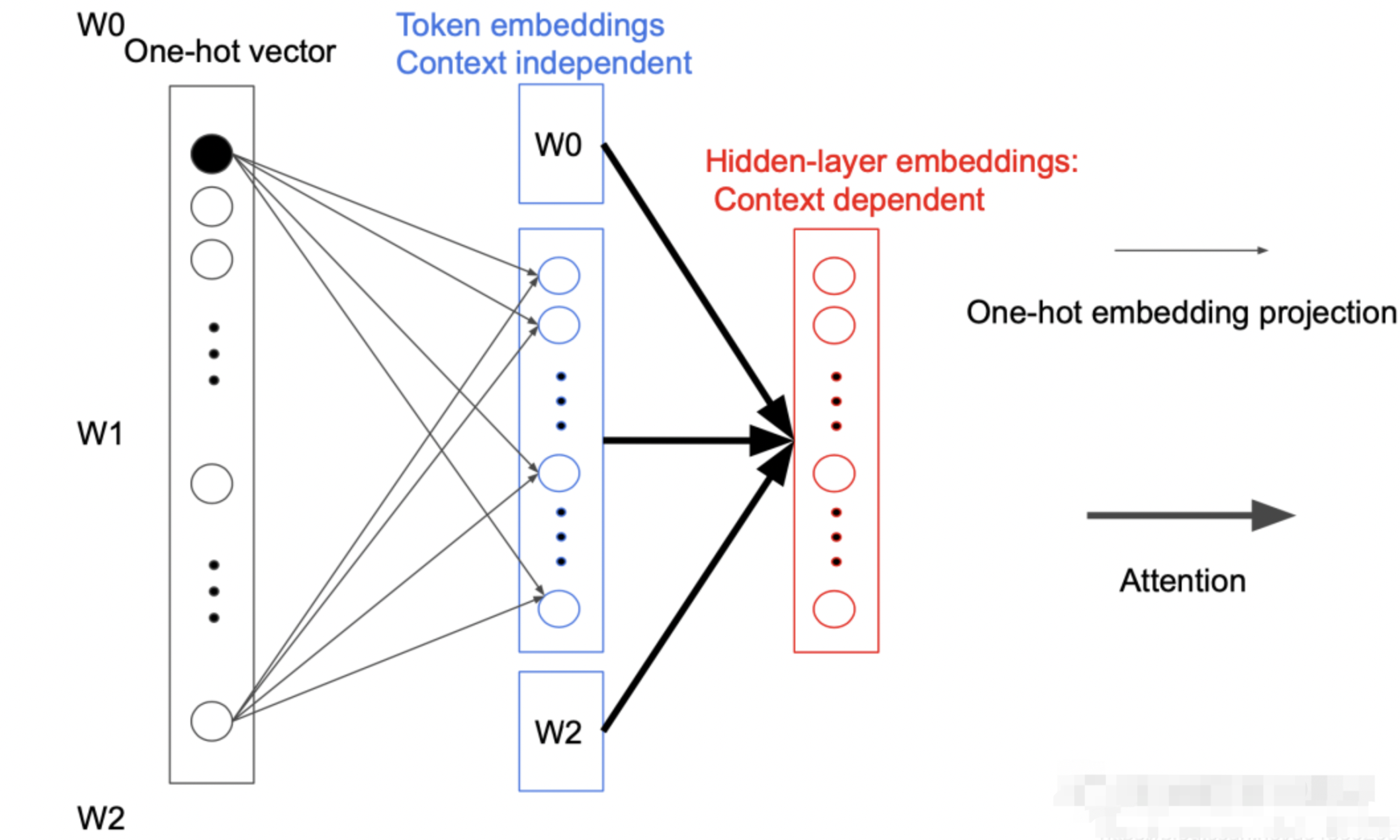
而 ALBERT 为了减少参数数量,在映射中间加入一个大小为E的隐藏层,这样矩阵的参数大小就从\(O(V \times H)\)降低为\(O(V \times E + E \times H)\),而\(E \ll H\)
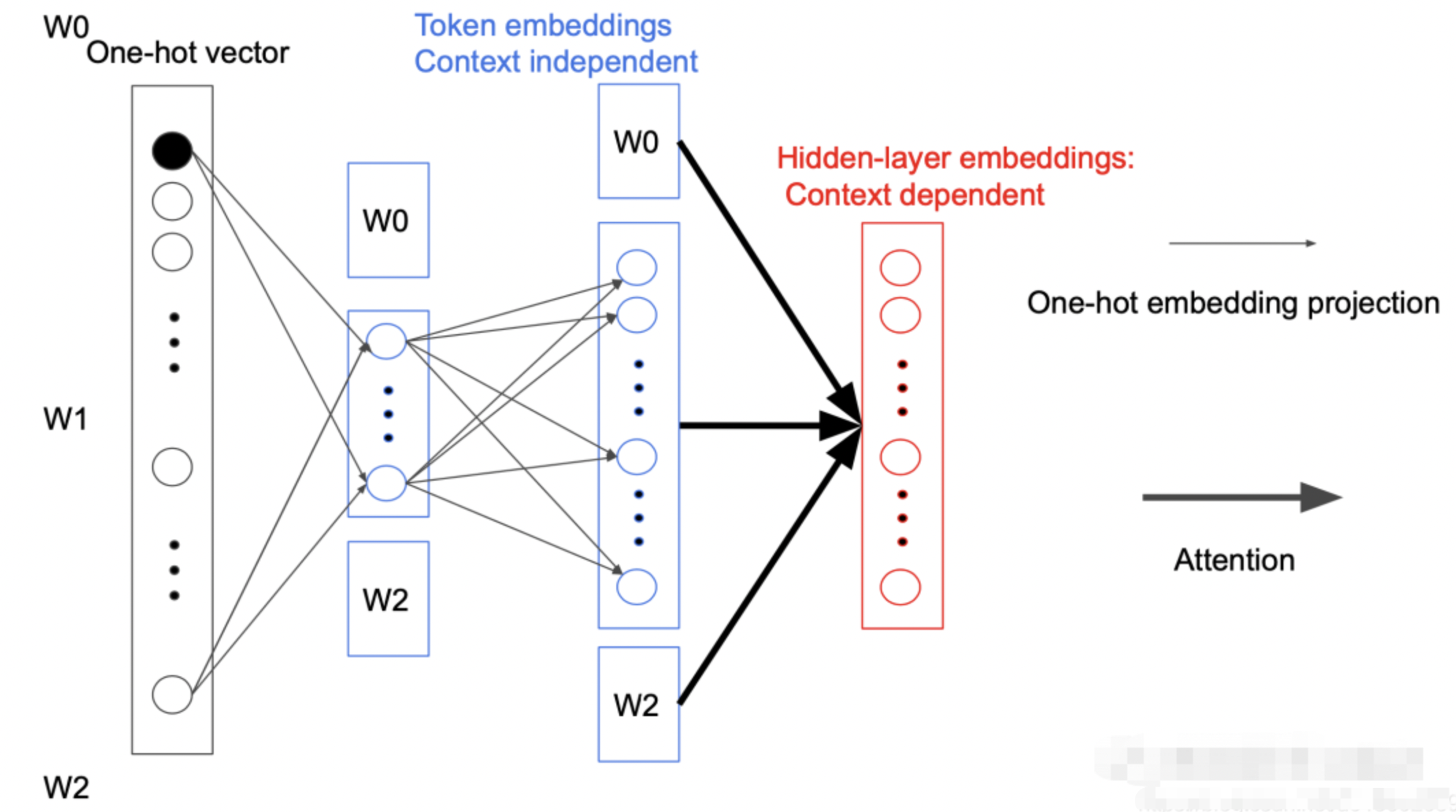
之所以可以这样做是因为每次反向传播时都只会更新一个 Token 相关参数,其他参数都不会变。而且在第一次投影的过程中,词与词之间是不会进行交互的,只有在后面的 Attention 过程中才会做交互,我们称为 Sparsely updated。如果词不做交互的话,完全没有必要用一个很高维度的向量去表示,所以就引入一个小的隐藏层。
Cross-layer parameter sharing
ALBERT 的参数共享主要是针对所有子模块内部进行的,这样便可以把 Attention feed-forward 模块参数量从$ O(12 \times L \times H \times H)$ 降低到\(12 \times H \times H\),其中L为层数,H为隐藏层的大小。
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
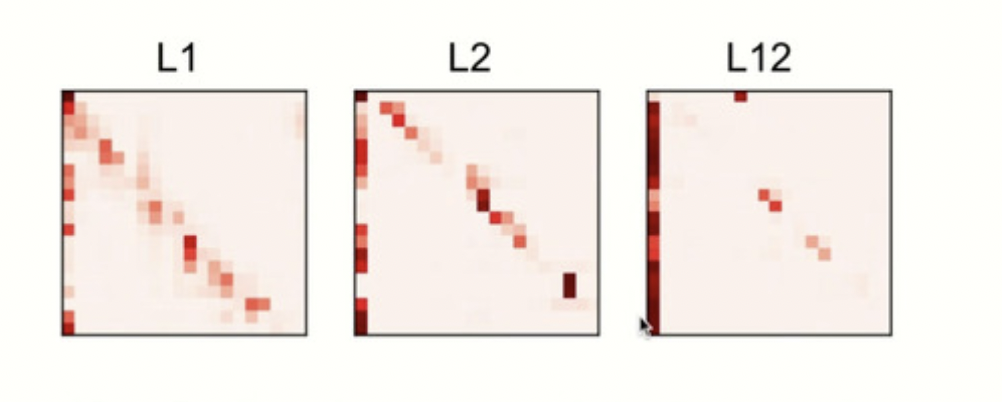
ALBERT 之所以这样做是因为,考虑到每层其实学习到内容非常相似,所以尝试了将其进行参数共享。下图为不同层 Attention 学到的东西:
Sentence order prediction
谷歌自己把它换成了 SOP。这个在百度 ERNIE 2.0 里也有,叫 Sentence Reordering Task,而且 SRT 比 SOP 更强,因为需要预测更多种句子片段顺序排列。ERNIE 2.0 中还有一些别的东西可挖,比如大小写预测 Captialization Prediction Task、句子距离 Sentence Distance Task。
- NSP:下一句预测, 正样本=上下相邻的2个句子,负样本=随机2个句子
- SOP:句子顺序预测,正样本=正常顺序的2个相邻句子,负样本=调换顺序的2个相邻句子
- NOP任务过于简单,只要模型发现两个句子的主题不一样就行了,所以SOP预测任务能够让模型学习到更多的信息
SOP任务也很简单,它的正例和NSP任务一致(判断两句话是否有顺序关系),反例则是判断两句话是否为反序关系。
我们举个SOP例子:
正例:1.朱元璋建立的明朝。2.朱元璋处决了蓝玉。
反例:1.朱元璋处决了蓝玉。2.朱元璋建立的明朝。
BERT使用的NSP损失,是预测两个片段在原文本中是否连续出现的二分类损失。目标是为了提高如NLI等下游任务的性能,但是最近的研究都表示 NSP 的作用不可靠,都选择了不使用NSP。
作者推测,NSP效果不佳的原因是其难度较小。将主题预测和连贯性预测结合在了一起,但主题预测比连贯性预测简单得多,并且它与LM损失学到的内容是有重合的。
SOP的正例选取方式与BERT一致(来自同一文档的两个连续段),而负例不同于BERT中的sample,同样是来自同一文档的两个连续段,但交换两段的顺序,从而避免了主题预测,只关注建模句子之间的连贯性。
- 使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
- 避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
No Dropout
RoBERTA 指出 BERT 一系列模型都是” 欠拟合” 的,所以干脆直接关掉 dropout, 那么在 ALBERT 中也是去掉 Dropout 层可以显著减少临时变量对内存的占用。同时论文发现,Dropout 会损害大型 Transformer-based 模型的性能。
标签:BERT,ALBERT,times,SOP,参数,NSP,句子 来源: https://www.cnblogs.com/zjuhaohaoxuexi/p/16401895.html