ElasticSearch基本使用姿势二
作者:互联网
ElasticSearch基本使用姿势二
本文作为elasticsearch 基本使用姿势第二篇,包含以下内容
- 查询指定字段
- 限制返回条数
- 分页查询
- 分组查询
- 高亮
- 自动补全提示
- 排序
- 返回结果聚合,如统计文档数,某个field value的求和、平均值等
更多相关知识点请查看: * ElasticSearch 基本使用姿势 - 一灰灰Blog
0. 数据准备
初始化一个索引,写入一些测试数据
post second-index/_doc
{
"@timestamp": "2021-06-10 08:08:08",
"url": "/test",
"execute": {
"args": "id=10&age=20",
"cost": 10,
"res": "test result"
},
"response_code": 200,
"app": "yhh_demo"
}
post second-index/_doc
{
"@timestamp": "2021-06-10 08:08:09",
"url": "/test",
"execute": {
"args": "id=20&age=20",
"cost": 11,
"res": "test result2"
},
"response_code": 200,
"app": "yhh_demo"
}
post second-index/_doc
{
"@timestamp": "2021-06-10 08:08:10",
"url": "/test",
"execute": {
"args": "id=10&age=20",
"cost": 12,
"res": "test result2"
},
"response_code": 200,
"app": "yhh_demo"
}
post second-index/_doc
{
"@timestamp": "2021-06-10 08:08:09",
"url": "/hello",
"execute": {
"args": "tip=welcome",
"cost": 2,
"res": "welcome"
},
"response_code": 200,
"app": "yhh_demo"
}
post second-index/_doc
{
"@timestamp": "2021-06-10 08:08:09",
"url": "/404",
"execute": {
"args": "tip=welcome",
"cost": 2,
"res": "xxxxxxxx"
},
"response_code": 404,
"app": "yhh_demo"
}
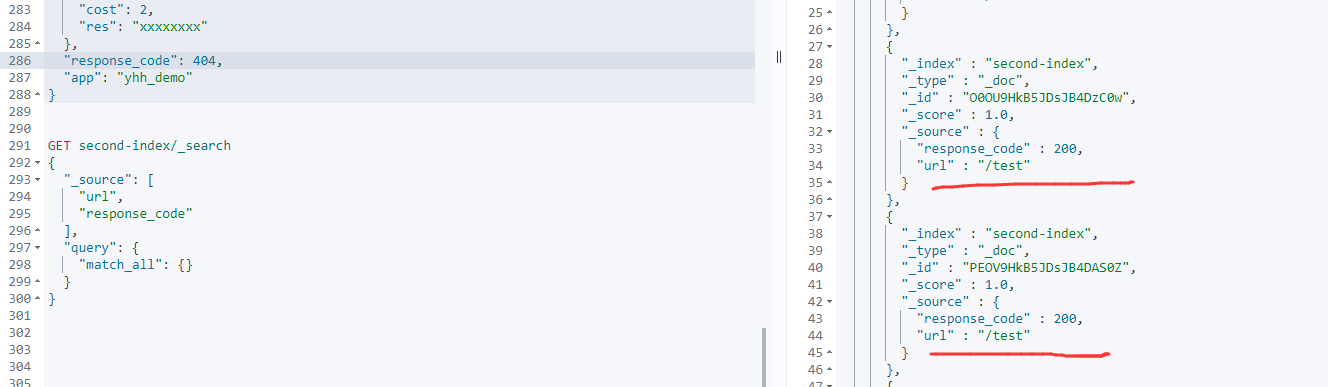
1. 查询指定字段
比如我现在只关心url返回的状态码, 主要借助_source来指定需要查询的字段,查询的语法和之前介绍的一致
GET second-index/_search
{
"_source": [
"url",
"response_code"
],
"query": {
"match_all": {}
}
}
2. 返回条数限制
针对返回结果条数进行限制,属于比较常见的case了,在es中,直接通过size来指定
GET second-index/_search
{
"query": {
"match_all": {}
},
"size": 2
}
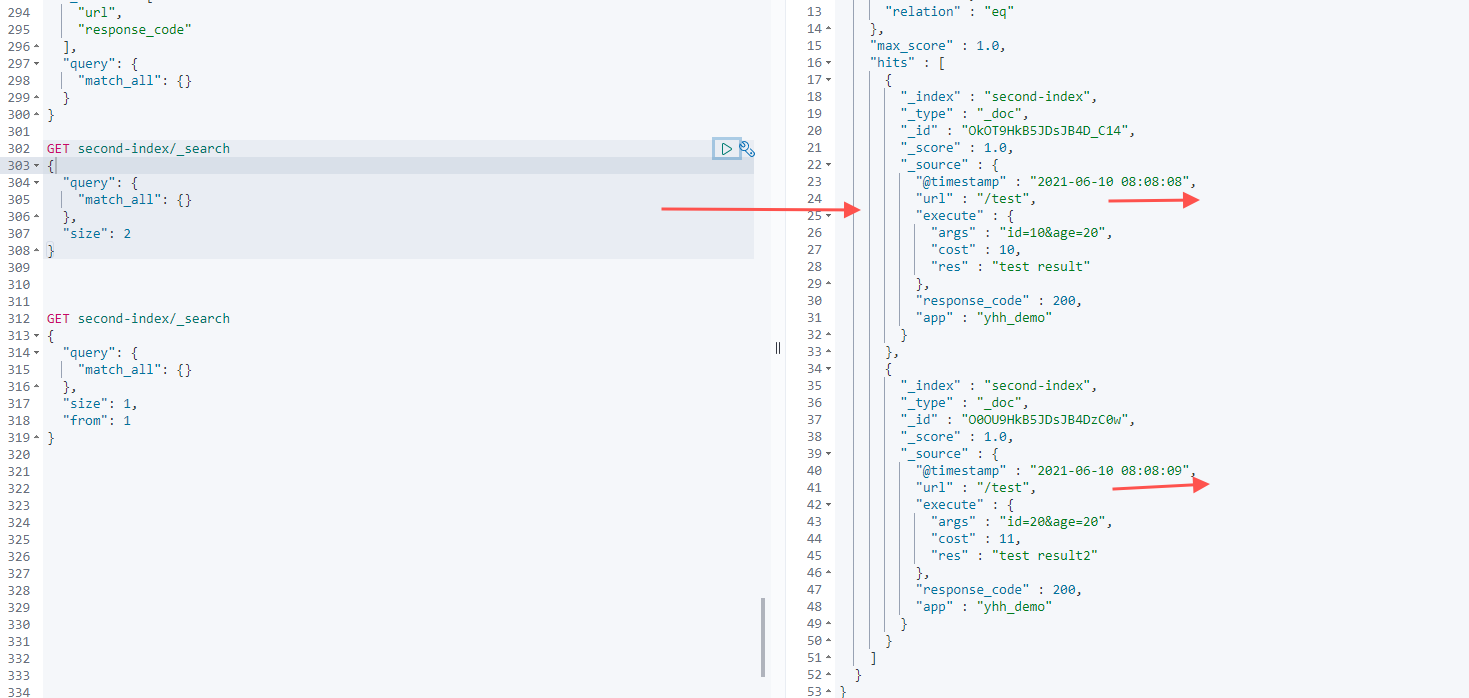
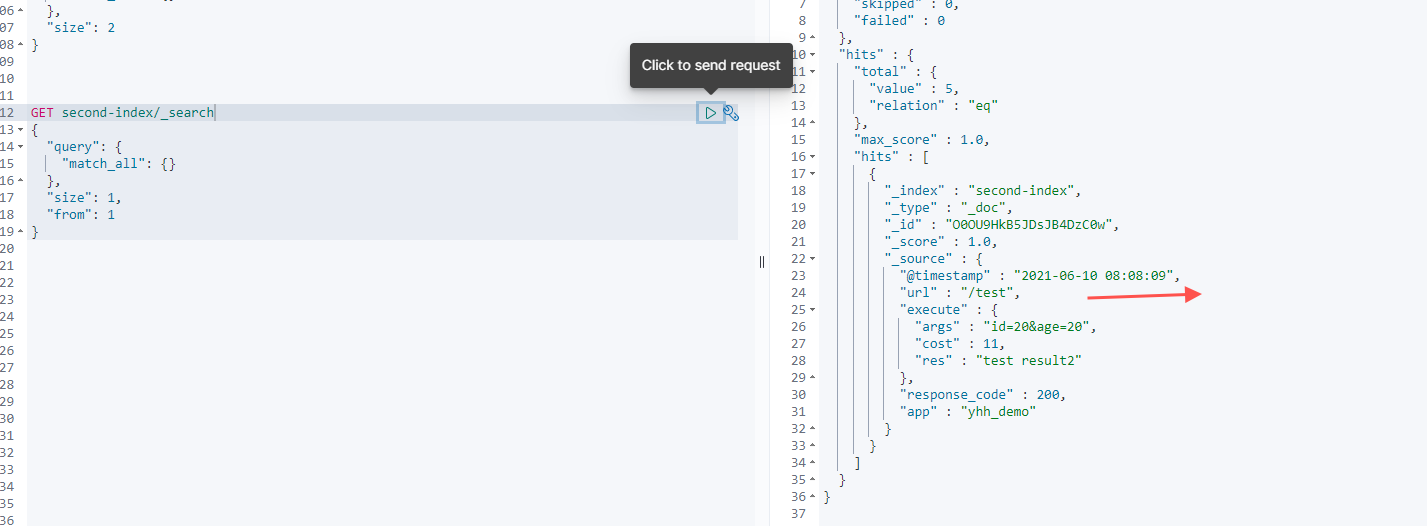
3. 分页查询
通过size限制返回的文档数,通过from来实现分页
GET second-index/_search
{
"query": {
"match_all": {}
},
"size": 1,
"from": 1
}
(注意下面输出截图,与上面的对比,这里返回的是第二条数据)
4. 分组查询
相当于sql中的group by,常用于聚合操作中的统计计数的场景
在es中,使用aggs来实现,语法如下
"aggs": {
"agg-name": { // 这个agg-name 是自定义的聚合名称
"terms": { // 这个terms表示聚合的策略,根据 field进行分组
"field": "",
"size": 10
}
}
}
比如我们希望根据url统计访问计数,对应的查询可以是
GET second-index/_search
{
"query": {
"match_all": {}
},
"size": 1,
"aggs": {
"my-agg": {
"terms": {
"field": "url",
"size": 2
}
}
}
}
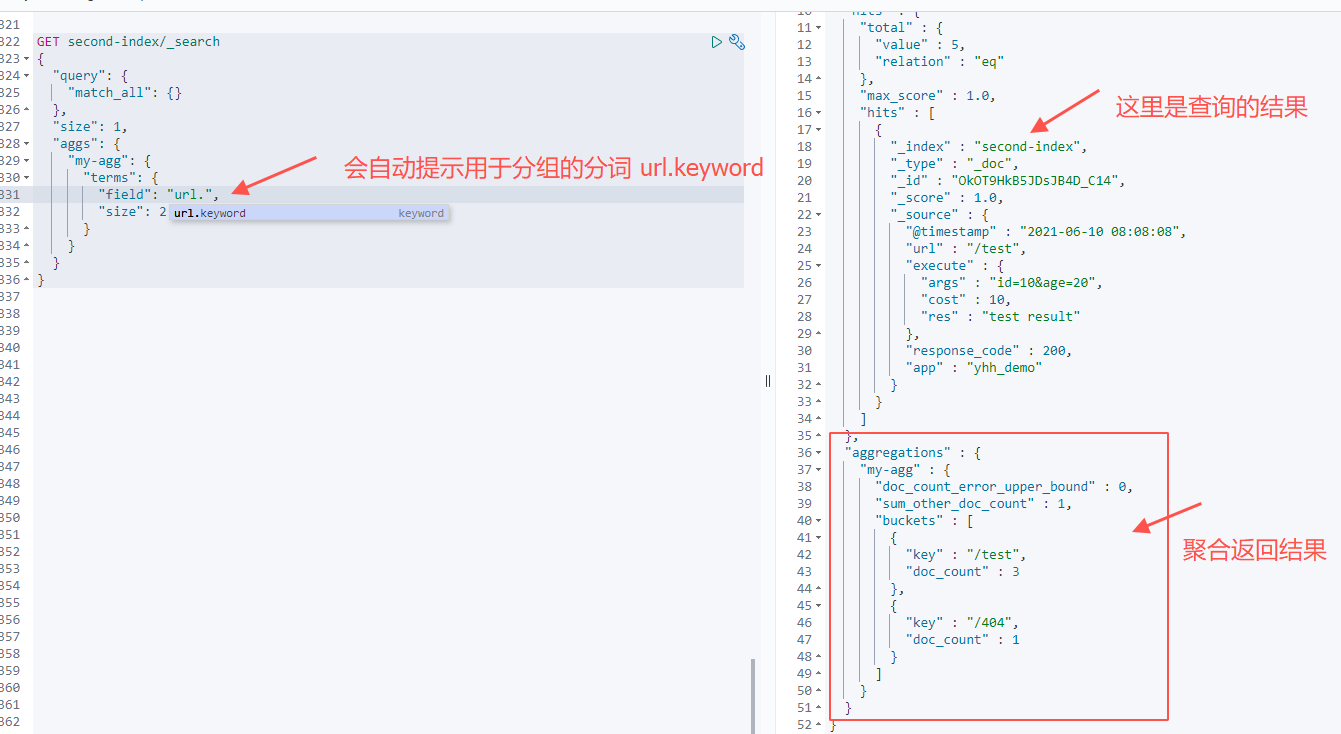
但是在执行时,会发现并不能正常响应
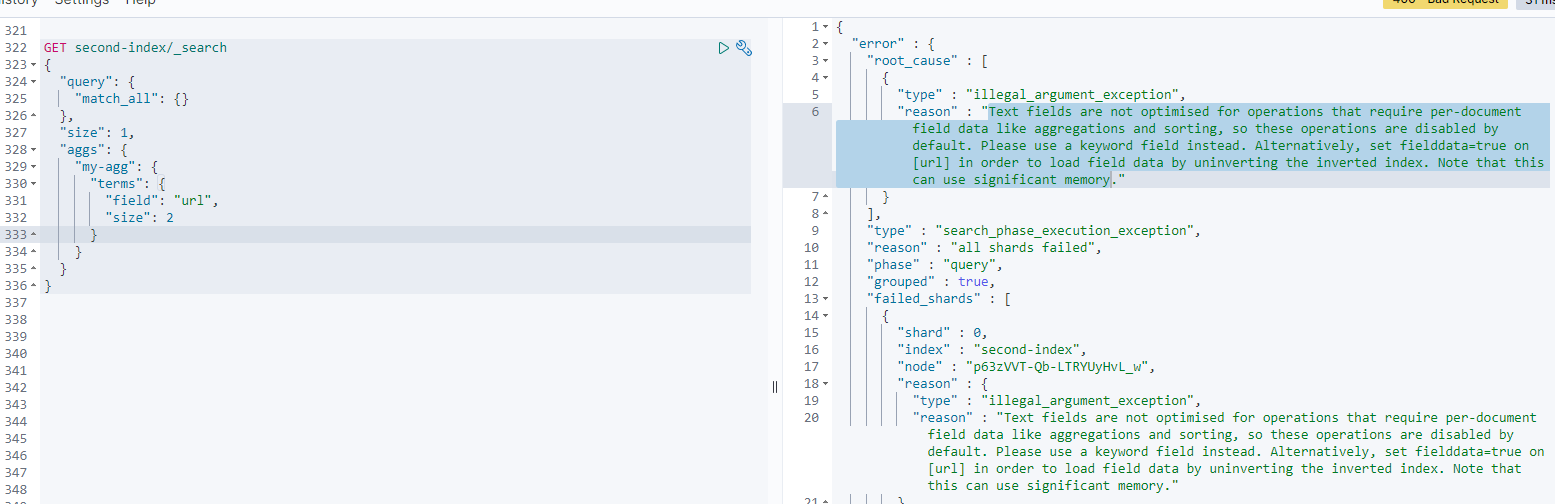
右边返回的提示信息为Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [url] in order to load field data by uninverting the inverted index. Note that this can use significant memory这个异常
简单来说,就是url这个字段为text类型,默认情况下这种类型的不走索引,不支持聚合排序,如果需要则需要设置fielddata=true,或者使用url的分词url.keyword
GET second-index/_search
{
"query": {
"match_all": {}
},
"size": 1,
"aggs": {
"my-agg": {
"terms": {
"field": "url.keyword",
"size": 2
}
}
}
}
注意
-
虽然我们更注重的是分组后的结果,但是
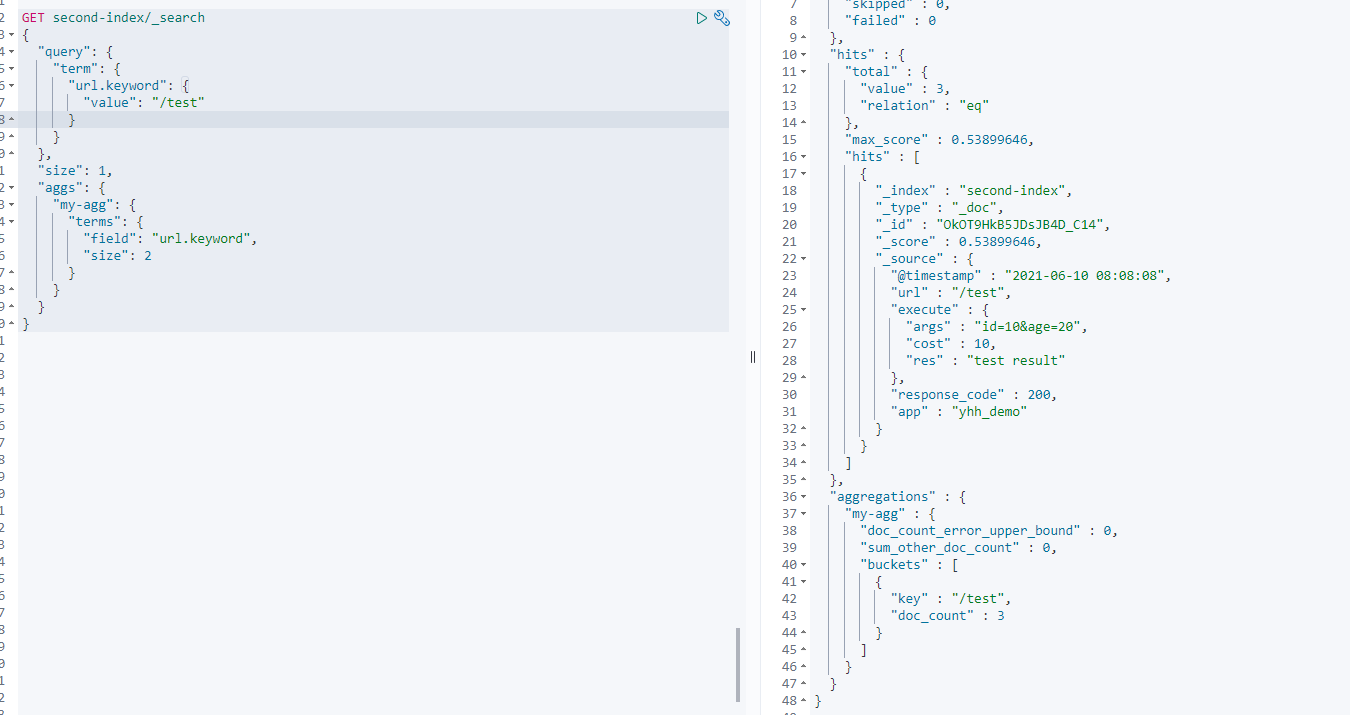
hits中依然会返回命中的文档,若是只想要分组后的统计结果,可以在查询条件中添加size:0 -
聚合操作和查询条件是可以组合的,如只查询某个url对应的计数
GET second-index/_search
{
"query": {
"term": {
"url.keyword": {
"value": "/test"
}
}
},
"size": 1,
"aggs": {
"my-agg": {
"terms": {
"field": "url.keyword",
"size": 2
}
}
}
}
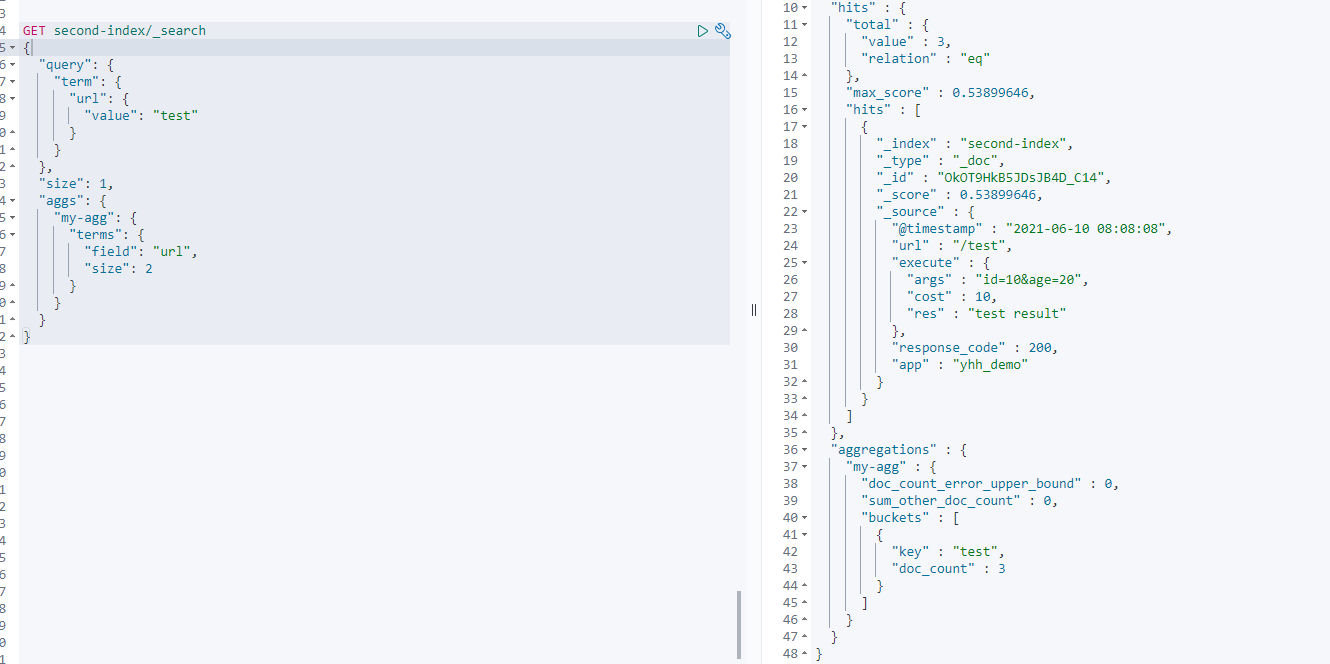
上面介绍了TEXT类型的field,根据分词进行聚合操作;还有一种方式就是设置fielddata=true,操作姿势如下
PUT second-index/_mapping
{
"properties": {
"url": {
"type": "text",
"fielddata": true
}
}
}
修改完毕之后,再根据url进行分组查询,就不会抛异常了
5. 全文搜索
通过配置一个动态索引模板,将所有的field构建一个用于全文检索的field,从而实现全文搜索
6. 聚合操作
上面的分组也算是聚合操作中的一种,接下来仔细看一下es的聚合,可以支持哪些东西
聚合语法:
"aggs": {
"agg_name": { // 自定义聚合名
"agg_type": { // agg_type聚合类型, 如 min, max
"agg_body" // 要操作的计算值
},
"meta": {},
"aggregations": {} // 子聚合查询
}
}
从聚合分类来看,可以划分为下面几种
- Metric Aggregation: 指标分析聚合
- Bucket Aggregation: 分桶聚合
- Pipeline: 管道分析类型
- Matrix: 矩阵分析类型
5.1 Metric Aggregation: 指标分析聚合
常见的有 min, max, avg, sum, cardinality, value count
通常是值查询一些需要通过计算获取到的值
下面分别给出一些演示说明
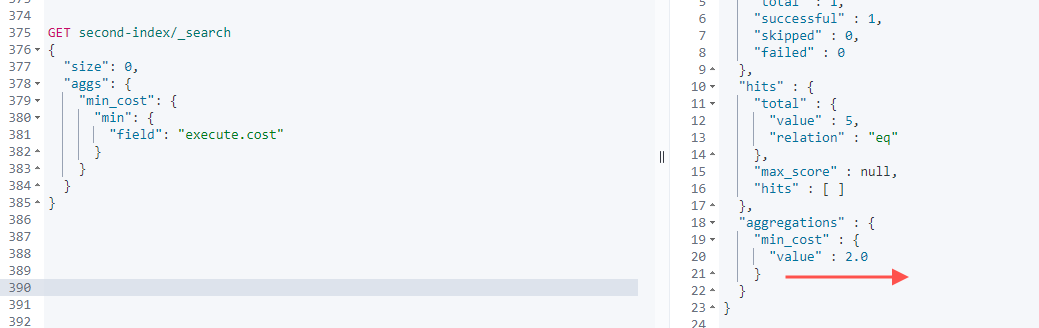
5.1.1 min最小值
获取请求耗时最小的case
GET second-index/_search
{
"size": 0,
"aggs": {
"min_cost": {
"min": {
"field": "execute.cost"
}
}
}
}
- size: 0 表示不需要返回原数据
- min_cost: 自定义的聚合名
- min: 表示聚合类型,为取最小值
"field": "execute.cost": 表示取的是Field: execute.cost的最小值
5.1.2 max 最大值
基本同上,下面中贴出请求代码,截图就省略掉了
GET second-index/_search
{
"size": 0,
"aggs": {
"max_cost": {
"max": {
"field": "execute.cost"
}
}
}
}
5.1.3 sum 求和
GET second-index/_search
{
"size": 0,
"aggs": {
"sum_cost": {
"sum": {
"field": "execute.cost"
}
}
}
}
5.1.4 avg平均值
在监控平均耗时的统计中,这个还是比较能体现服务的整体性能的
GET second-index/_search
{
"size": 0,
"aggs": {
"avg_cost": {
"avg": {
"field": "execute.cost"
}
}
}
}
5.1.5 cardinality 去重统计计数
这个等同于我们常见的 distinct count 注意与后面的 value count 统计所有有值的文档数量之间的区别
GET second-index/_search
{
"_source": "url",
"aggs": {
"cardinality_cost": {
"cardinality": {
"field": "url"
}
}
}
}
去重统计url的计数,如下图,可以看到返回统计结果为3,但是实际的文档数有5个
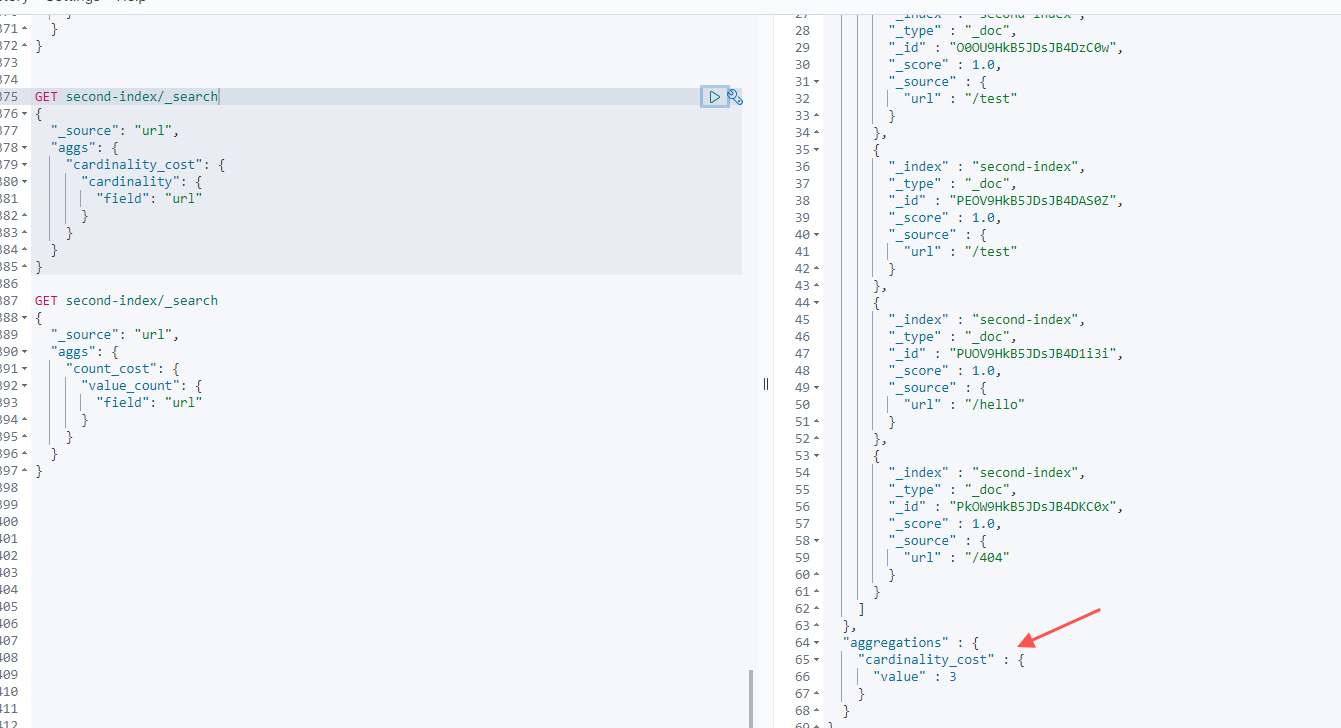
5.1.6 value count 计数统计
文档数量统计,区别于上面的去重统计,这里返回的是全量
GET second-index/_search
{
"size": 0,
"aggs": {
"count_cost": {
"value_count": {
"field": "url"
}
}
}
}
输出结果配合cardinality的返回,做一个对比可以加强理解
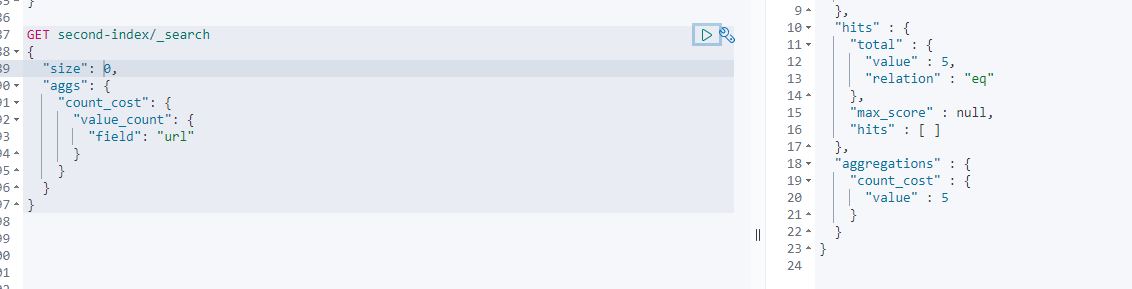
5.1.7 stats 多值计算
一个stats 可以返回上面min,max,sum...等的计算值
GET second-index/_search
{
"size": 0,
"aggs": {
"mult_cost": {
"stats": {
"field": "execute.cost"
}
}
}
}
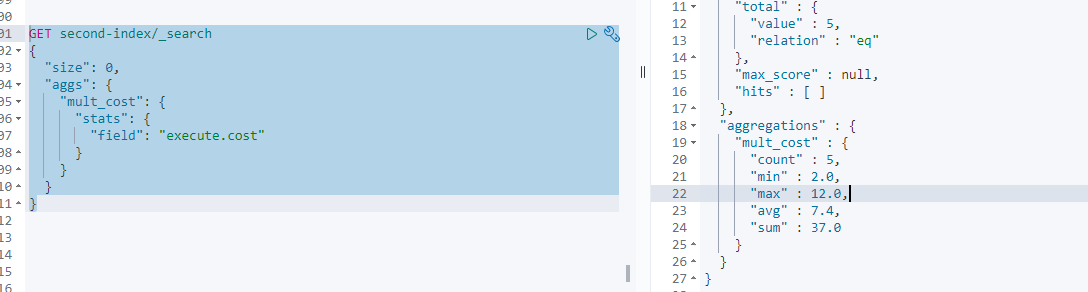
5.1.8 extended_stats 多值扩展
在上面stats的基础上进行扩展,支持方差,标准差等返回
GET second-index/_search
{
"size": 0,
"aggs": {
"mult_cost": {
"extended_stats": {
"field": "execute.cost"
}
}
}
}

5.1.9 percentile 百分位数统计
用于统计 xx% 的记录值,小于等于右边
如下面截图,可知 99%的记录,耗时小于12
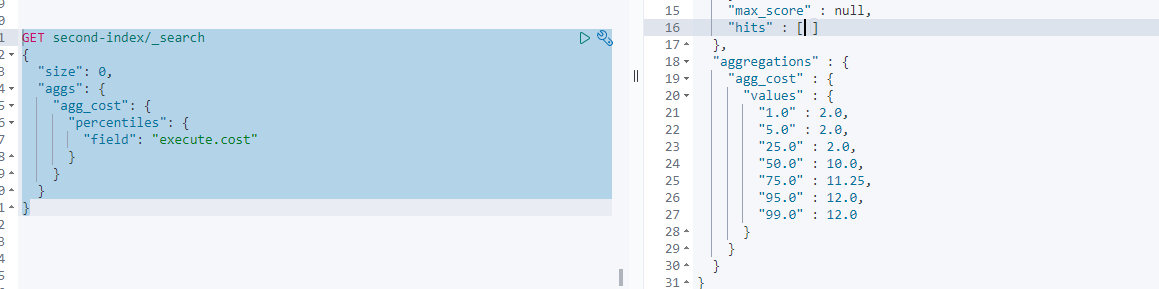
默认的百分比区间是: [1, 45, 25, 50, 75, 95, 99], 可以手动修改
GET second-index/_search
{
"size": 0,
"aggs": {
"agg_cost": {
"percentiles": {
"field": "execute.cost",
"percents": [
10,
50,
90,
99
]
}
}
}
}
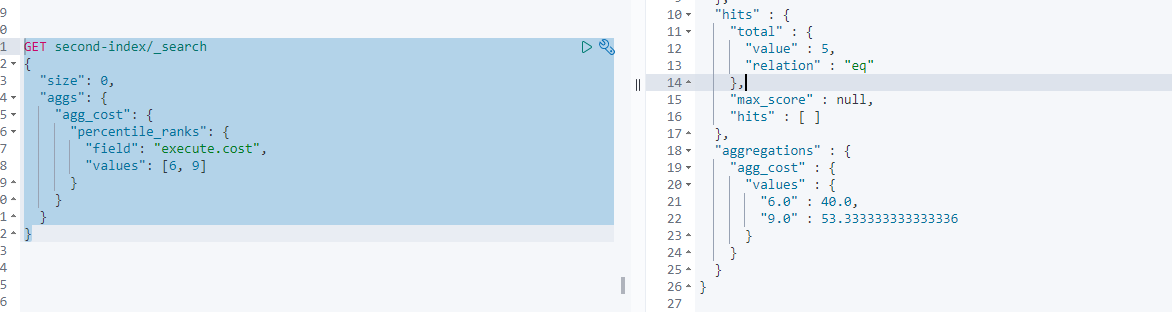
5.1.10 percentile rank统计值所在的区间
上面用于统计不同区间的占比,比如公司的人员年龄分布;而这一个则是我想知道18岁的我,在哪个占比里
GET second-index/_search
{
"size": 0,
"aggs": {
"agg_cost": {
"percentile_ranks": {
"field": "execute.cost",
"values": [6, 9]
}
}
}
}
相关博文
ElasticSearch:aggregations 聚合详解
一灰灰的联系方式
尽信书则不如无书,以上内容,纯属一家之言,因个人能力有限,难免有疏漏和错误之处,如发现bug或者有更好的建议,欢迎批评指正,不吝感激
- 个人站点:https://blog.hhui.top
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
- 微信公众号:一灰灰blog

标签:姿势,基本,index,url,field,second,cost,ElasticSearch,size 来源: https://www.cnblogs.com/yihuihui/p/16376012.html