最佳实践|从Producer 到 Consumer,如何有效监控 Kafka
作者:互联网
简介: 对于运维人而言,如何安装维护一套监控系统,或如何进行技术选型,从来不是工作重点。如何借助工具对所需的应用、组件进行监控,发现并解决问题才是重中之重。随着 Prometheus 逐渐成为云原生时代可观测标准,为了帮助更多运维人用好 Prometheus,阿里云云原生团队将定期更新 Prometheus 最佳实践系列。第一期我们讲解了《最佳实践|Spring Boot 应用如何接入 Prometheus 监控》,今天将为大家带来,消息队列产品 Kafka 的监控最佳实践。
对于运维人而言,如何安装维护一套监控系统,或如何进行技术选型,从来不是工作重点。如何借助工具对所需的应用、组件进行监控,发现并解决问题才是重中之重。 随着 Prometheus 逐渐成为云原生时代可观测标准,为了帮助更多运维人用好 Prometheus,阿里云云原生团队将定期更新 Prometheus 最佳实践系列。第一期我们讲解了《最佳实践|Spring Boot 应用如何接入 Prometheus 监控》,今天将为大家带来,消息队列产品 Kafka 的监控最佳实践。 本篇内容主要包括三部分:Kafka 概览介绍、常见关键指标解读、如何建立相应监控体系。 什么是 Kafka Kafka 起源 Kafka 是由 Linkedin 公司开发,并捐赠给 Apache 软件基金会的分布式发布订阅消息系统,Kafka 的目的是通过 Hadoop 的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Kafka 的诞生是为了解决 Linkedin 的数据管道问题,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。起初 Linkedin 采用 ActiveMQ 进行数据交换,但当时的 ActiveMQ 无法满足 Linkedin 对数据传递系统的要求,经常出现消息阻塞或者服务无法正常访问等问题。Linkedin 决定研发自己的消息队列,Linkedin 时任首席架构师 Jay Kreps 便开始组建团队进行消息队列的研发。 Kafka 特性 相较于其他消息队列产品,Kafka 存在以下特性:
添加图片注释,不超过 140 字(可选)
Kafka 的诞生是为了解决 Linkedin 的数据管道问题,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。起初 Linkedin 采用 ActiveMQ 进行数据交换,但当时的 ActiveMQ 无法满足 Linkedin 对数据传递系统的要求,经常出现消息阻塞或者服务无法正常访问等问题。Linkedin 决定研发自己的消息队列,Linkedin 时任首席架构师 Jay Kreps 便开始组建团队进行消息队列的研发。 Kafka 特性 相较于其他消息队列产品,Kafka 存在以下特性:

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
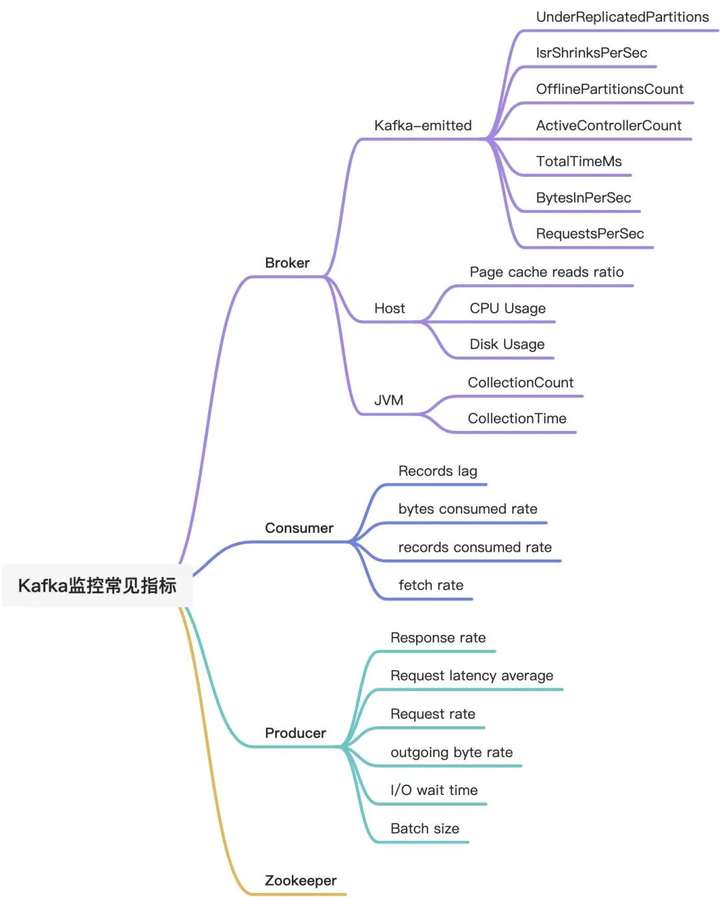
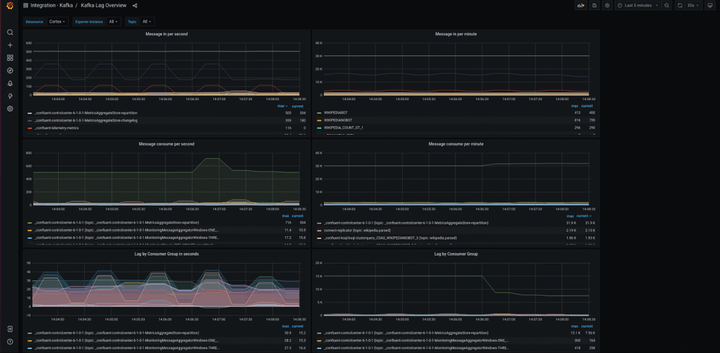
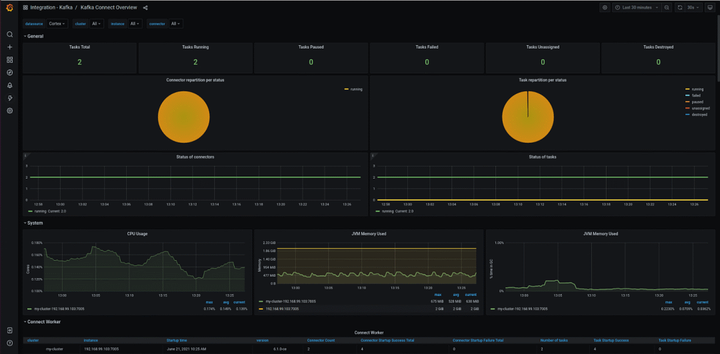
Broker 指标 由于所有消息都必须通过 Broker 才能被使用,因此,对 Broker 进行监控并预警非常重要。Broker 指标关注:Kafka-emitted 指标、Host-level 指标、JVM 垃圾收集指标。
添加图片注释,不超过 140 字(可选)
Broker 指标 由于所有消息都必须通过 Broker 才能被使用,因此,对 Broker 进行监控并预警非常重要。Broker 指标关注:Kafka-emitted 指标、Host-level 指标、JVM 垃圾收集指标。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
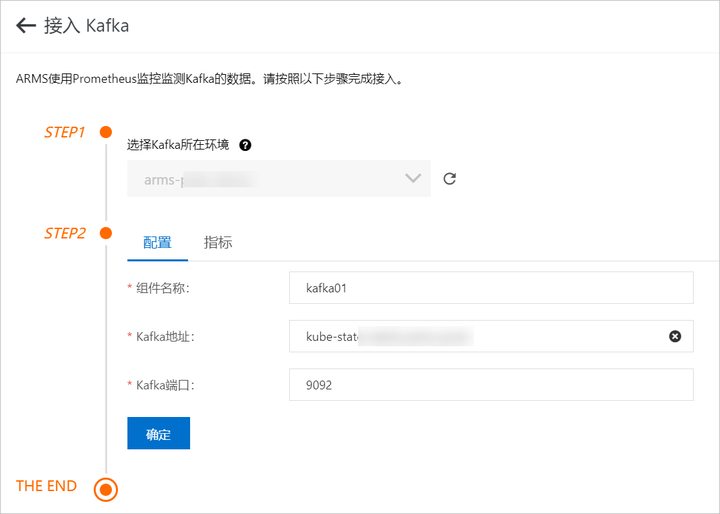
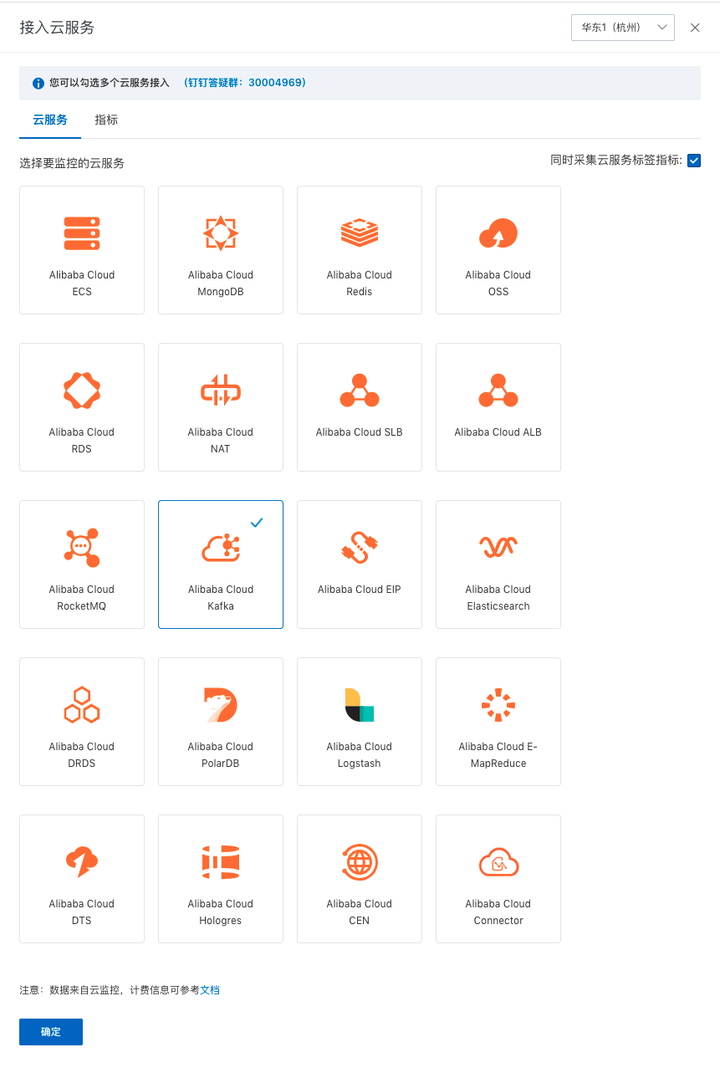
如果是购买 Kafka 云产品,可以通过”Prometheus for 云服务“进行监控 登录 Prometheus 控制台。在页面左上角选择目标地域,然后选择新建 Prometheus 实例。在弹出页面单击 Prometheus 实例 for 云服务。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
如果是购买 Kafka 云产品,可以通过”Prometheus for 云服务“进行监控 登录 Prometheus 控制台。在页面左上角选择目标地域,然后选择新建 Prometheus 实例。在弹出页面单击 Prometheus 实例 for 云服务。
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
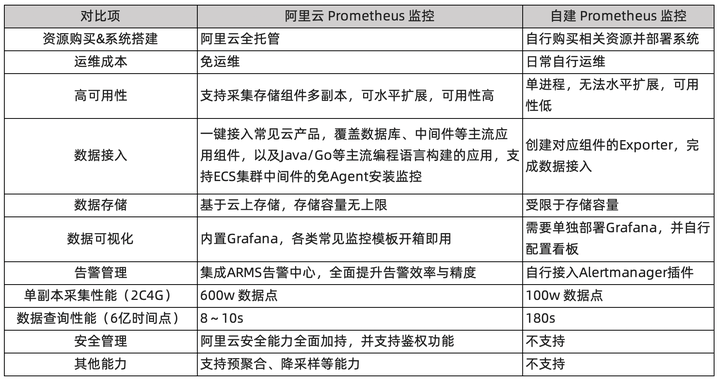
相较于开源 Prometheus,阿里云 Prometheus 监控具备以下特性
添加图片注释,不超过 140 字(可选)
相较于开源 Prometheus,阿里云 Prometheus 监控具备以下特性
添加图片注释,不超过 140 字(可选)
参考及引用: Kafka 官方文档: https://kafka.apache.org/documentation/#monitoring Kafka Exporter Github 地址: https://github.com/danielqsj/kafka_exporter https://zhuanlan.zhihu.com/p/473163768https://github.com/apache/kafkahttps://kafka.apache.org/code.html
原文链接:http://click.aliyun.com/m/1000345007/
本文为阿里云原创内容,未经允许不得转载”。
添加图片注释,不超过 140 字(可选)
参考及引用: Kafka 官方文档: https://kafka.apache.org/documentation/#monitoring Kafka Exporter Github 地址: https://github.com/danielqsj/kafka_exporter https://zhuanlan.zhihu.com/p/473163768https://github.com/apache/kafkahttps://kafka.apache.org/code.html
原文链接:http://click.aliyun.com/m/1000345007/
本文为阿里云原创内容,未经允许不得转载”。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
Kafka 的诞生是为了解决 Linkedin 的数据管道问题,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。起初 Linkedin 采用 ActiveMQ 进行数据交换,但当时的 ActiveMQ 无法满足 Linkedin 对数据传递系统的要求,经常出现消息阻塞或者服务无法正常访问等问题。Linkedin 决定研发自己的消息队列,Linkedin 时任首席架构师 Jay Kreps 便开始组建团队进行消息队列的研发。 Kafka 特性 相较于其他消息队列产品,Kafka 存在以下特性:
- 持久性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 高吞吐:Kafka 每秒可以处理百万条消息;
- 可扩展:Kafka 集群支持热扩展;
- 容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败);
- 高并发:支持数千个客户端同时读写。
- 大数据领域:如网站行为分析、日志聚合、应用监控、流式数据处理、在线和离线数据分析等领域。
- 数据集成:将消息导入 ODPS、OSS、RDS、Hadoop、HBase 等离线数据仓库。
- 流计算集成:与 StreamComput e、E-MapReduce、Spark、Storm 等流计算引擎集成。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
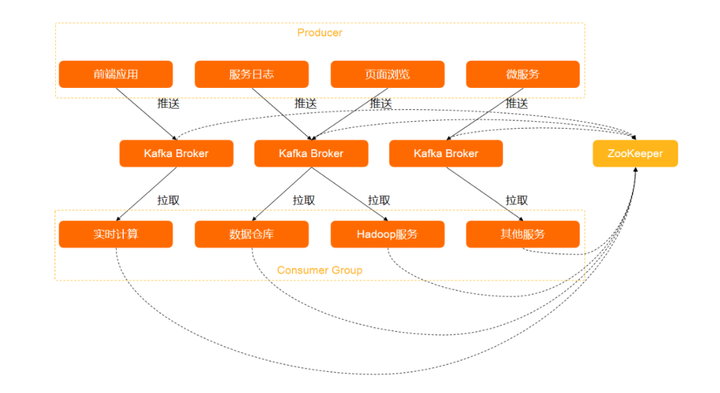
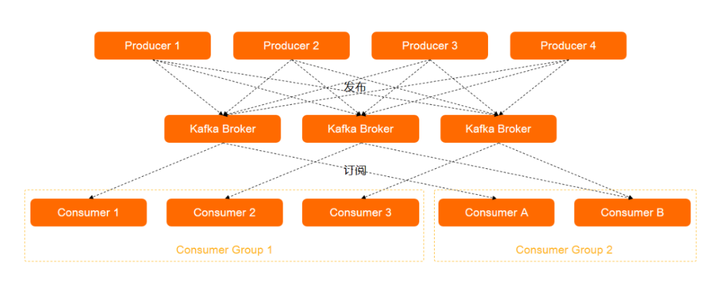
- Producer:消息发布者,也称为消息生产者, 通过 Push 模式向 Broker 发送消息。发送的消息可以是网站的页面访问、服务器日志,也可以是 CPU 和内存相关的系统资源信息。
- Broker:用于存储消息的服务器。Broker 支持水平扩展。Broker 节点的数量越多,集群吞吐率越高。
- Consumer Group:Consumer 被称为消息订阅者或消息消费者,负责向服务器读取消息并进行消费。Consumer Group 指一类 Consumer,这类 Consumer 通常接收并消费同一类消息,且消息消费逻辑一致。通过 Pull 模式从 Broker 订阅并消费消息。
- Zookeeper:管理集群配置、选举 Leader 分区,并在 Consumer Group 发生变化时进行负载均衡。其中值得一提的是,如果没有 ZooKeeper 就无法完成 Kafka 部署。ZooKeeper 是将所有东西粘合在一起的粘合剂
- 发布/订阅模型 :Kafka 采用发布/订阅模型,Consumer Group 和 Topic 的对应关系是 N : N,即一个 Consumer Group 可以同时订阅多个 Topic,一个 Topic 也可以被多个 Consumer Group 同时订阅。虽然一个Topic可以被多个 Consumer Group 同时订阅,但该 Topic 只能被同一个 Consumer Group 内的任意一个 Consumer 消费。
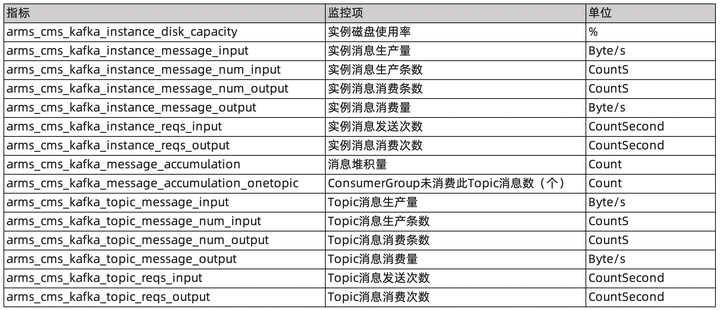
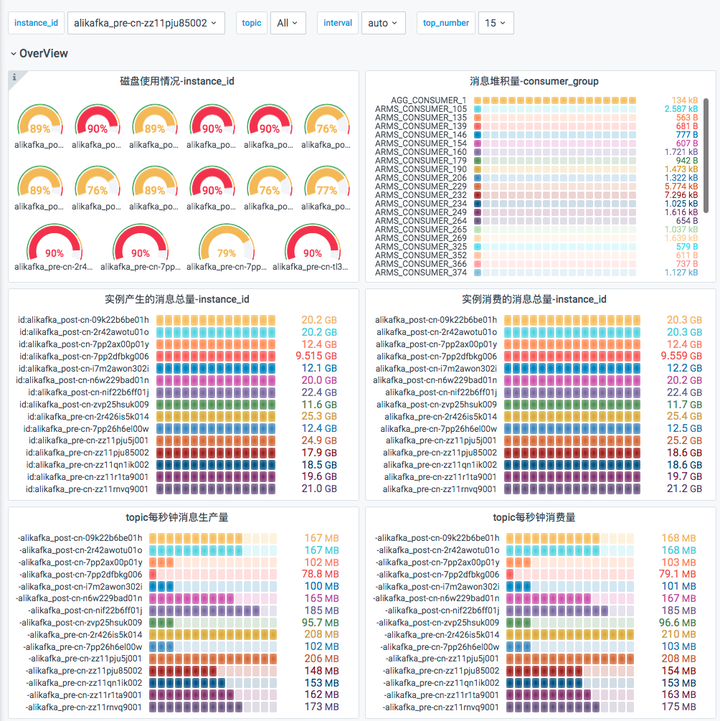
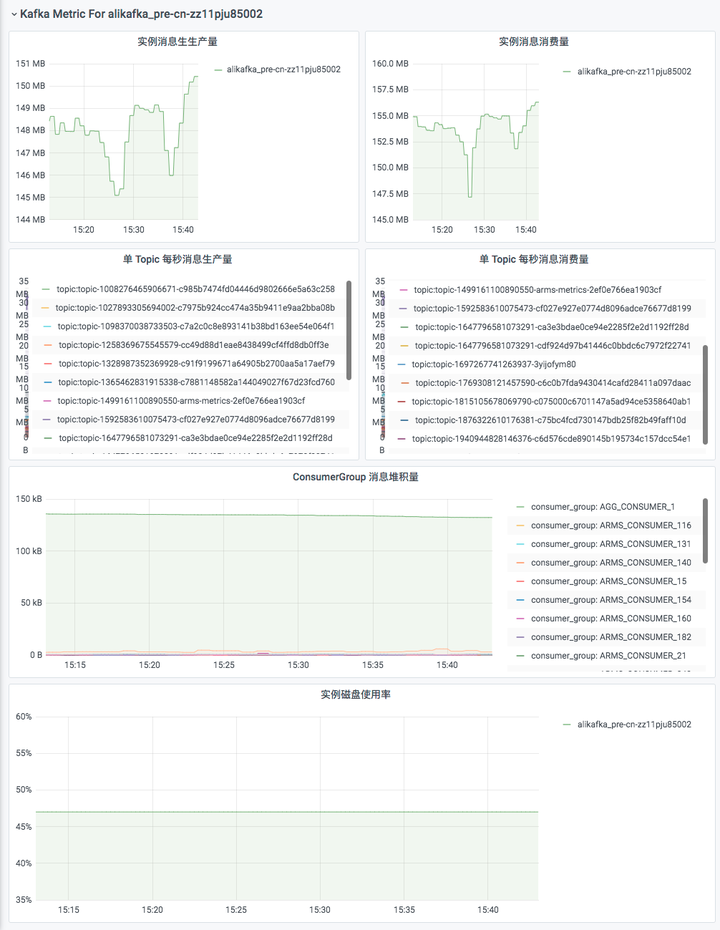
- 实例消息生产流量(bytes/s)
- 实例消息消费流量(bytes/s)
- 实例磁盘使用率(%)-实例各节点中磁盘使用率的最大值
- Topic 消息生产流量(bytes/s)
- Topic 消息消费流量(bytes/s)
- Group 未消费消息总数(个)
添加图片注释,不超过 140 字(可选)
Broker 指标 由于所有消息都必须通过 Broker 才能被使用,因此,对 Broker 进行监控并预警非常重要。Broker 指标关注:Kafka-emitted 指标、Host-level 指标、JVM 垃圾收集指标。
- Broker - Kafka-emitted 指标
- Broker - Host 基础指标 & JVM 垃圾收集指标
- 初级水平,自己搞不定开源 Prometheus 部署;
- 比较懒,又不想日常维护 Prometheus 系统,包括相关组件更新、系统整体扩容;
- 业务上线非常着急,需要马上有相应的监控系统;
- 企业级用户 希望 Prometheus 服务低成本、数据库规模无上限、高性能高可用
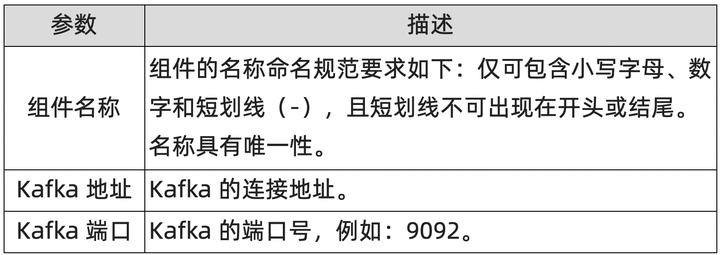
- 添加 Kafka 类型的组件
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
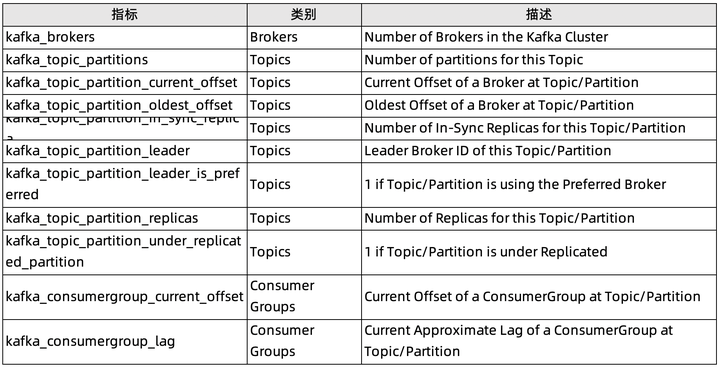
- 默认采集相关指标
添加图片注释,不超过 140 字(可选)
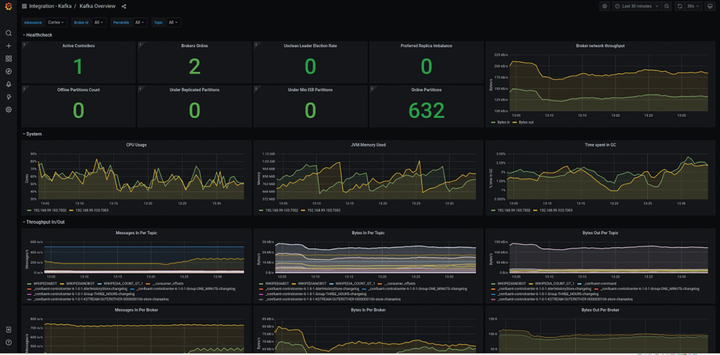
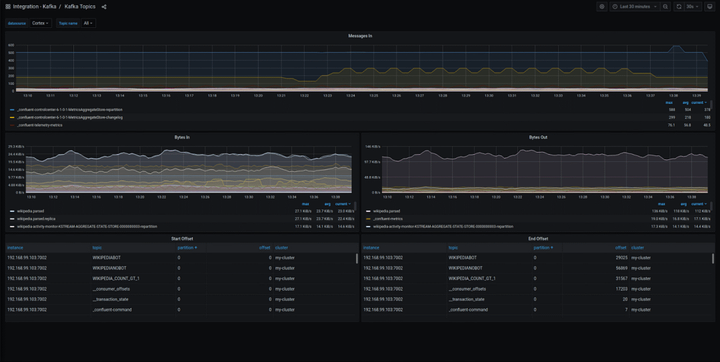
- 查看相关数据指标
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
如果是购买 Kafka 云产品,可以通过”Prometheus for 云服务“进行监控 登录 Prometheus 控制台。在页面左上角选择目标地域,然后选择新建 Prometheus 实例。在弹出页面单击 Prometheus 实例 for 云服务。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
- 添加 Alibaba Cloud Kafka 监控
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
- 默认采集相关指标
添加图片注释,不超过 140 字(可选)
- 查看相关数据指标
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
相较于开源 Prometheus,阿里云 Prometheus 监控具备以下特性
添加图片注释,不超过 140 字(可选)
参考及引用: Kafka 官方文档: https://kafka.apache.org/documentation/#monitoring Kafka Exporter Github 地址: https://github.com/danielqsj/kafka_exporter https://zhuanlan.zhihu.com/p/473163768https://github.com/apache/kafkahttps://kafka.apache.org/code.html
原文链接:http://click.aliyun.com/m/1000345007/
本文为阿里云原创内容,未经允许不得转载”。
标签:Producer,140,kafka,Prometheus,监控,Kafka,Consumer 来源: https://www.cnblogs.com/yunqishequ/p/16355824.html