Prometheus 四种metric类型
作者:互联网
Prometheus的4种metrics(指标)类型:
- Counter
- Gauge
- Histogram
- Summary
四种指标类型的数据对象都是数字,如果要监控文本类的信息只能通过指标名称或者 label 来呈现,在 zabbix 一类的监控中指标类型本身支持 Log 和文本,当然在这里我们不是要讨论 Prometheus 的局限性,而是要看一看 Prometheus 是如何把数字玩出花活的。 Counter 与 Gauge 比较好理解,我们简单的过一下 然后主要关注 Histogram 和 Summary
Counter 与 Gauge
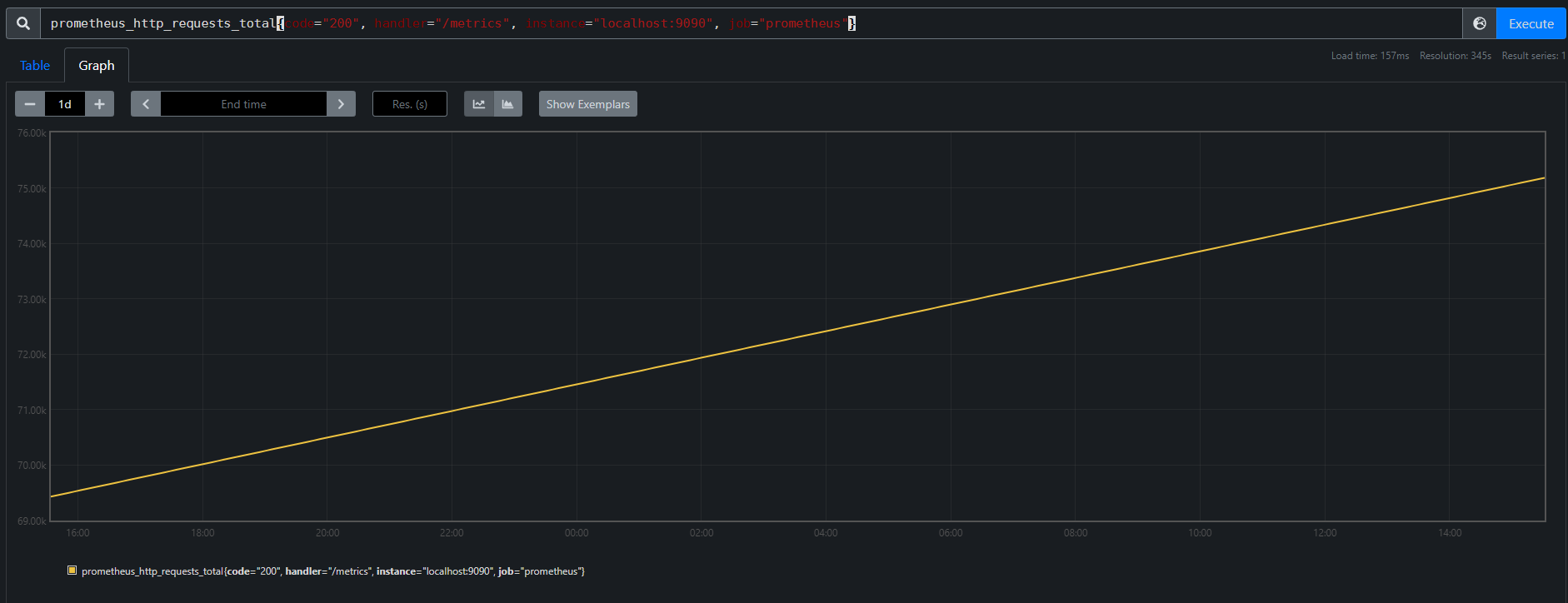
Counter
单调递增的计数器。
例如 Prometheus自身 中 metrics 的 http 请求总数
Gauge
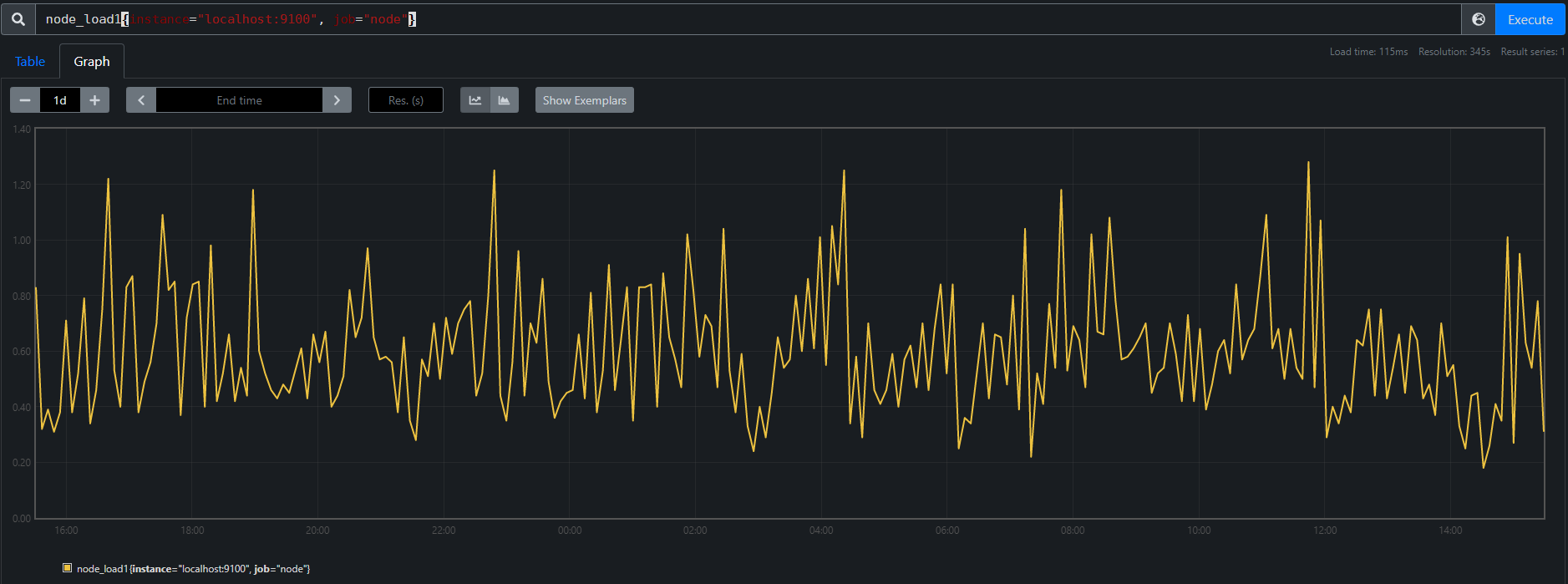
仪表,也可以认为是一种计数器,不过支持加和减。
例如 node 中的负载数据
Histogram 与 Summary
Histogram
直方图常用于请求持续时间或者响应大小采样,然后将结果记录到存储桶(bucket),每个桶为累加数据。
通过三个metrics名称来完整暴露一组Histogram
- 桶累积计数器,
<basename>_bucket{le="<upper inclusive bound>"} - 所有观察值的总和,
<basename>_sum - 已观察到的事件计数,
<basename>_count与上述相同<basename>_bucket{le="+Inf"})
例如K8s中pod启动耗时:
kubelet_pod_start_duration_seconds_bucket
kubelet_pod_start_duration_seconds_count #进行过pod start的数量
kubelet_pod_start_duration_seconds_sum # 总耗时
具体到某个节点中
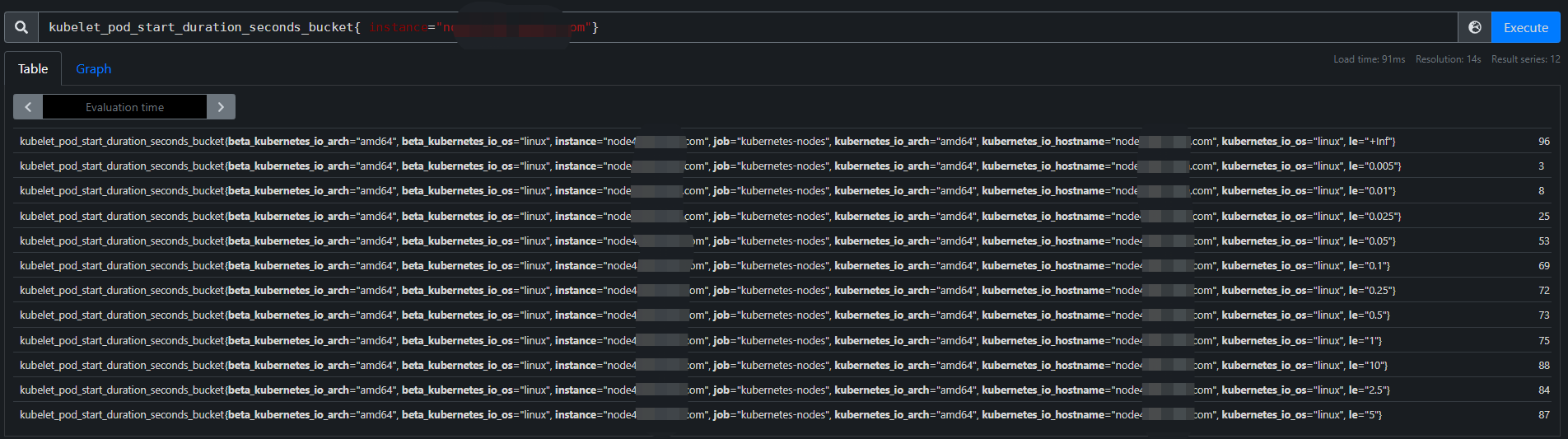
le:小于等于。例如le=”5“,即pod启动耗时<=5s的有87次
+inf:无穷。当启动耗时为无穷时,也就是节点下pod启动过的数量,与kubelet_pod_start_duration_seconds_count相等
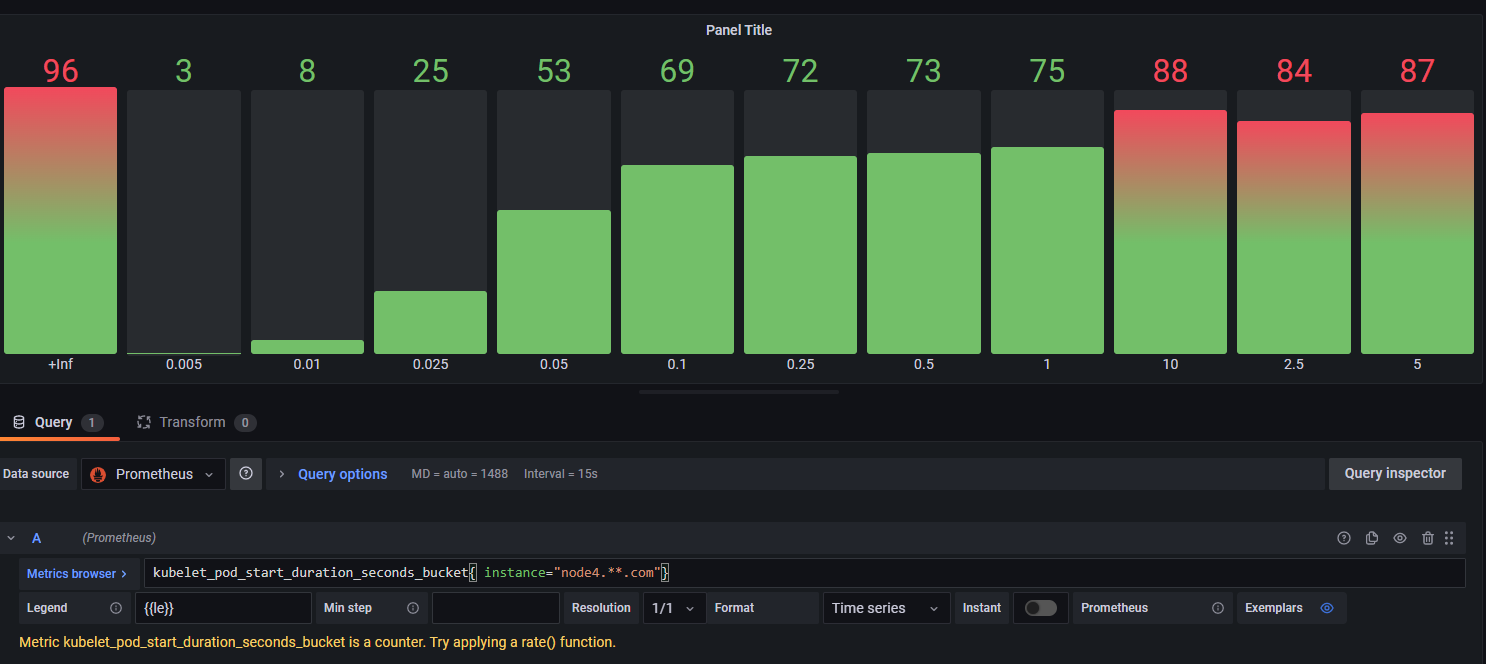
通过grafana 中 Bar gauge呈现桶的分布如下:
有了直方图数据后我们可以做相应的比例计算:
计算pod启动耗时大于1s,小于2.5s的次数
#kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="2.5"} - ignoring(le) kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="1"}
9
计算pod启动耗时大于2.5s的比例
#kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="2.5"} / ignoring(le) kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="+Inf"}
0.875
使用 PromQL 函数histogram_quantile计算百分位
#histogram_quantile(0.80,kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com"} )
1.3000000000000018
即80%的pod启动次数中,耗时<=1.3s,histogram_quantile函数计算百分位得到是一个近似值。
通过histogram_quantile函数聚合
计算Prometheus http所有请求中80百分位的值
histogram_quantile(0.8, sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le))

即80%的请求响应时间<=0.08s
通过histogram计算网站性能指标 - Apdex指数
Apdex 指数 =( 满意数量 + 0.5 * 可容忍数量 ) / 总样本数,假设请求满意时间为0.3s,则可容忍时间为1.2s(4倍)
(
sum(rate(http_request_duration_seconds_bucket{le="0.3"}[5m])) by (job)
+
sum(rate(http_request_duration_seconds_bucket{le="1.2"}[5m])) by (job)
) / 2 / sum(rate(http_request_duration_seconds_count[5m])) by (job)
Summary
Summary与Histogram相似,也是通过三个metrics名称来完整暴露一组Summary,不过Summary是直接在客户端帮我们计算出了百分位数(Histogram 则使用上面提到的histogram_quantile函数计算)
- φ 分位数(0 ≤ φ ≤ 1),
<basename>{quantile="<φ>"} - 所有观察值的总和,
<basename>_sum - 已观察到的事件计数,
<basename>_count
例如cgroup操作延迟:
kubelet_cgroup_manager_latency_microseconds
kubelet_cgroup_manager_latency_microseconds_sum
kubelet_cgroup_manager_latency_microseconds_count

Summary和Histogram都可以使用rate函数计算平均数
计算cgroup update操作的平均延迟:
rate(kubelet_cgroup_manager_latency_microseconds_sum{ instance="node4.**.com",operation_type="update"}[10m]) / rate(kubelet_cgroup_manager_latency_microseconds_count{ instance="node4.**.com",operation_type="update"}[10m])
最后我们对比一下Summary与Histogram
| Histogram | Summary | |
|---|---|---|
| 配置要求 | 选择符合预期观测值范围(le)的存储桶 | 选择所需的分位数φ和窗口范围,其他φ无法再被计算 |
| 客户端性能影响 | 低,仅需增加计数器 | 高,在客户端计算分位数 |
| 服务端性能影响 | 高,服务端需计算分位数 | 服务端成本低 |
时间序列的数量(除了_sum和_count序列) |
每添加一个存储桶增加一个时间序列 | 每添加一个分位数φ 值增加一个时间序列 |
| 分位数误差 | 受限于相关桶的宽度 | 误差在 φ 值的限制 |
| φ分位数和窗口范围 | 取决于histogram_quantile函数中φ | 由客户端预先添加 |
| 聚合 | histogram_quantile函数聚合 | 不聚合 |
通过博客阅读:iqsing.github.io
参考:
标签:le,seconds,metric,bucket,kubelet,Prometheus,duration,pod,四种 来源: https://www.cnblogs.com/qsing/p/16352910.html