#章节五:列表和字典
作者:互联网
章节五:列表和字典
目录截至目前,我们已经掌握了3种数据类型:整数、浮点数、字符串。这一关我们就要学习两种新的数据类型:列表、字典。
不过在这之前,我想先和你聊一聊“计算机”与“数据”之间水乳交融的关系。
计算机名字里就有【计算】两字,如果计算机离开了数据,就如巧妇难为无米之炊。所以说,数据对于计算机很重要。
总的来说,计算机有3种方式利用数据:

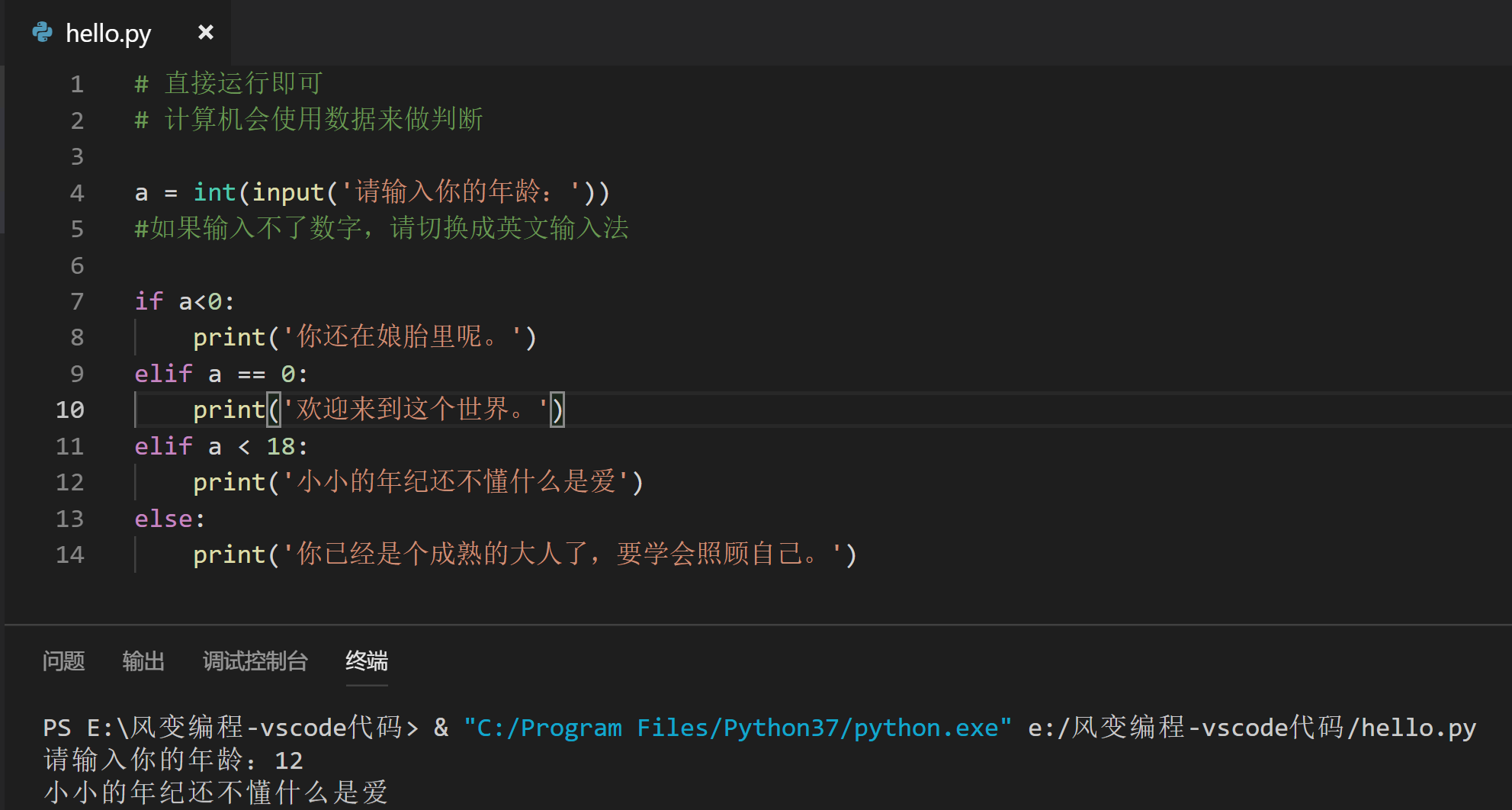
第一种:直接使用数据,比如print()语句,可以直接把我们提供的数据打印出来,通常所见即所得。

第二种:计算和加工数据,让我们看个例子:

这两个print语句,计算机都是先【计算和加工数据】,再把print()括号里的数据打印到屏幕里。
我们再看看第三种:用数据做判断是怎么一回事。
1. 列表
那现在我们对【计算机】和【数据】的关系有了一定的了解吧,也正因为数据的重要性,所以对于编程新手来说,掌握主要的数据类型是重中之重。
我们就会接触两种新的数据类型——列表和字典,你会发现,它们比我们学过的“整数、浮点数、字符串”更加高级,更有“包容性”。
为什么这么说呢?前面学的几种类型,每次赋值只能保存一条数据。如果我们需要使用很多数据的时候,就会很不方便。
而列表和字典的作用,就是可以帮我们存储大量数据,让计算机去读取和操作。
首先我们来看看列表。为了感受列表的作用,我们来玩玩角色扮演的游戏:从现在起,你就是一个新班级的班主任了!
第一天,班上来了50个新鲜的面孔。你让学生把名字写在花名册上,方便上课时一个个点名。
如果只能用已学的知识来解决这个问题,我们需要将每个学生的名字都赋值到一个变量名,然后再分别打印。代码是这样的:
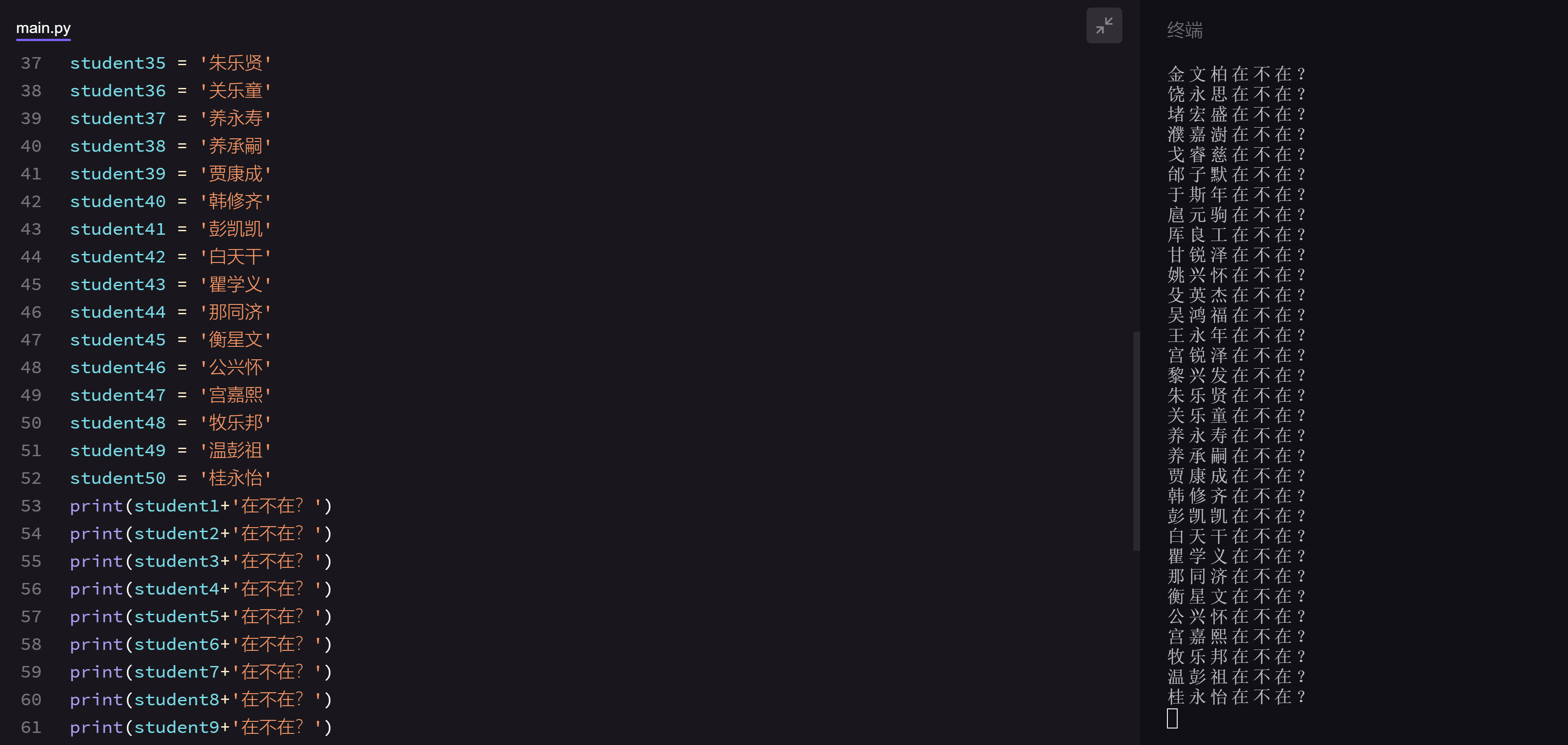
但我们知道,在编程世界里,最忌讳的就是“重复性劳动”。这一百行代码打下来,即使是复制黏贴修改的,分分钟也要抓狂。
实际上呢,只要学会了列表和循环,3行代码就能搞定。
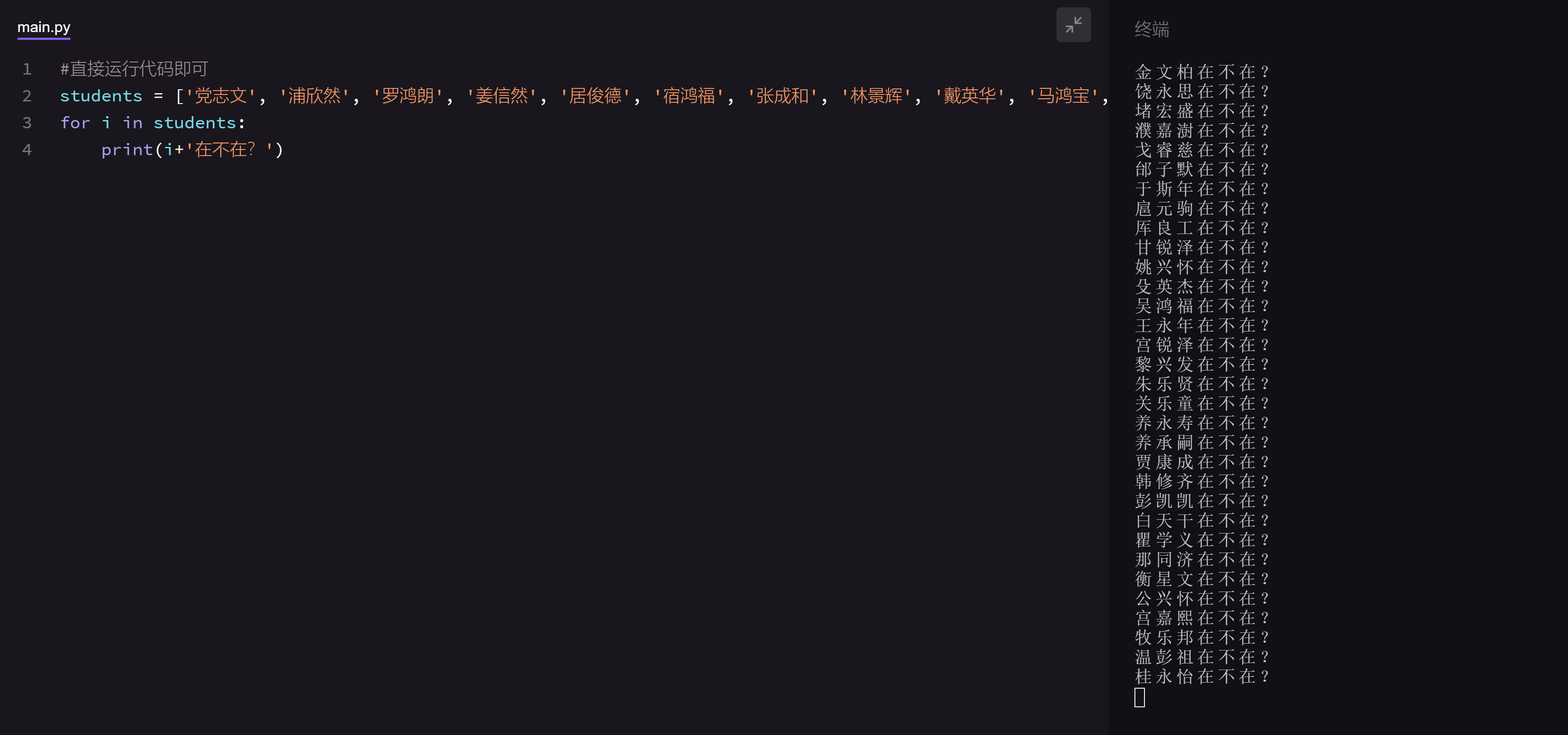
发现了吗?在第一行代码里,赋值号右边不再像字符串那样只能放一个名字,而是放了50个。
这就是我们要新认识的第一个数据类型——列表,下面我会从4个方面来介绍列表的用法。
1.1 什么是列表
首先,我们来看看列表(list)的代码格式:

图中的['小明','小红','小刚']就是一个列表。
一个列表需要用中括号[ ]把里面的各种数据框起来,里面的每一个数据叫作“元素”。每个元素之间都要用英文逗号隔开。
这就是列表的标准格式
举例:请你创建一个列表名为list1的列表,列表里有三个元素:'小明',18,1.70,并将其打印出来
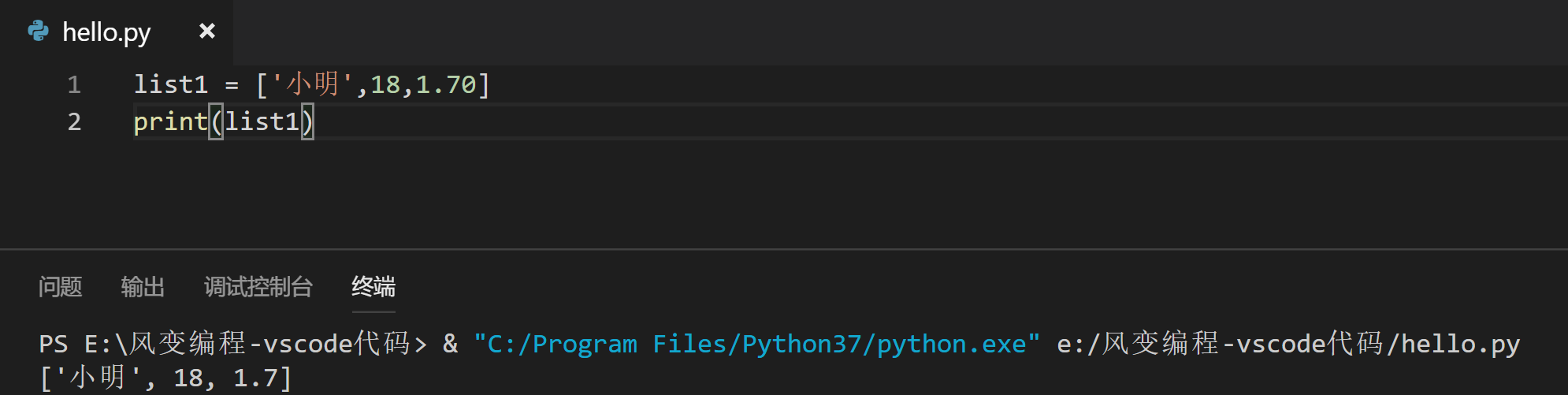
恭喜你,成功掌握了列表的规范写法以及打印列表的方法。而且也用代码验证了一个知识点:列表很包容,各种类型的数据(整数/浮点数/字符串)无所不能包。
不过,很多时候,我们只需要用到列表中的某一个元素,好比老师上课点名时,不会说“所有的同学都站起来回答一下这个问题”。
所以,问题来了:列表中具体的某个元素,要如何取出来?
1.2 从列表提取单个元素
这就涉及到一个新的知识点:偏移量。列表中的各个元素,好比教室里的某排学生那样,是有序地排列的,也就是说,每个元素都有自己的位置编号(即偏移量)。

从上图可得:1.偏移量是从0开始的,而非我们习惯的从1开始;2.列表名后加带偏移量的中括号,就能取到相应位置的元素。
所以,我们可以通过偏移量来对列表进行索引(可理解为搜索定位),读取我们所需的元素。
举例:假如你现在要喊小明来回答问题,用代码怎么写呢利用列表的偏移量来打印出'小明'这个元素。
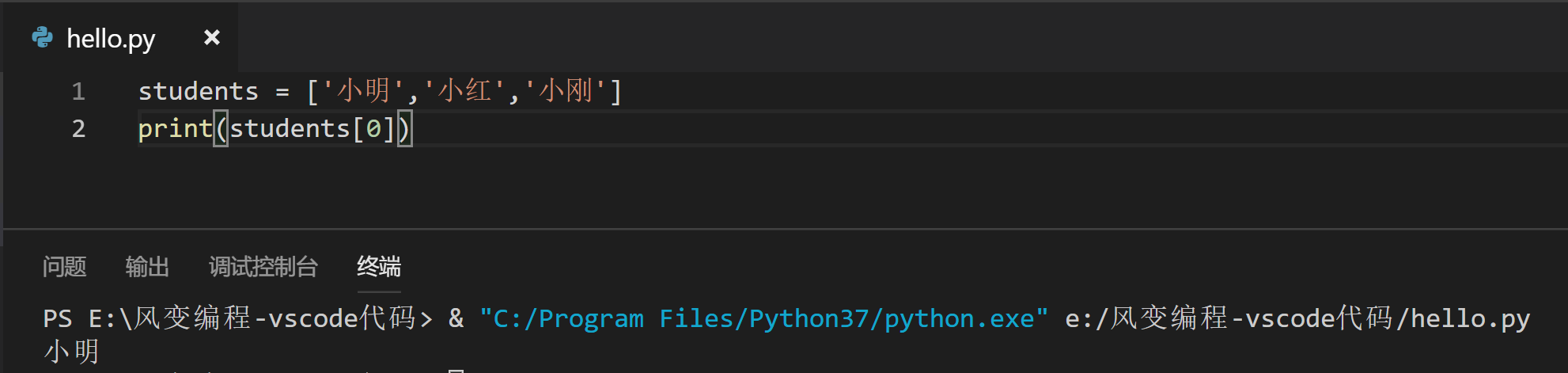
现在我们已经知道了如何从列表中取出一个元素,那如果要同时取好几个呢?所以我们接着学习如何从列表中取出多个元素。
1.3 从列表提取多个元素
秘法小口诀:冒号左边空,就要从偏移量为0的元素开始取;右边空,就要取到列表的最后一个元素。冒号左边数字对应的元素要拿,右边的不动
举例:
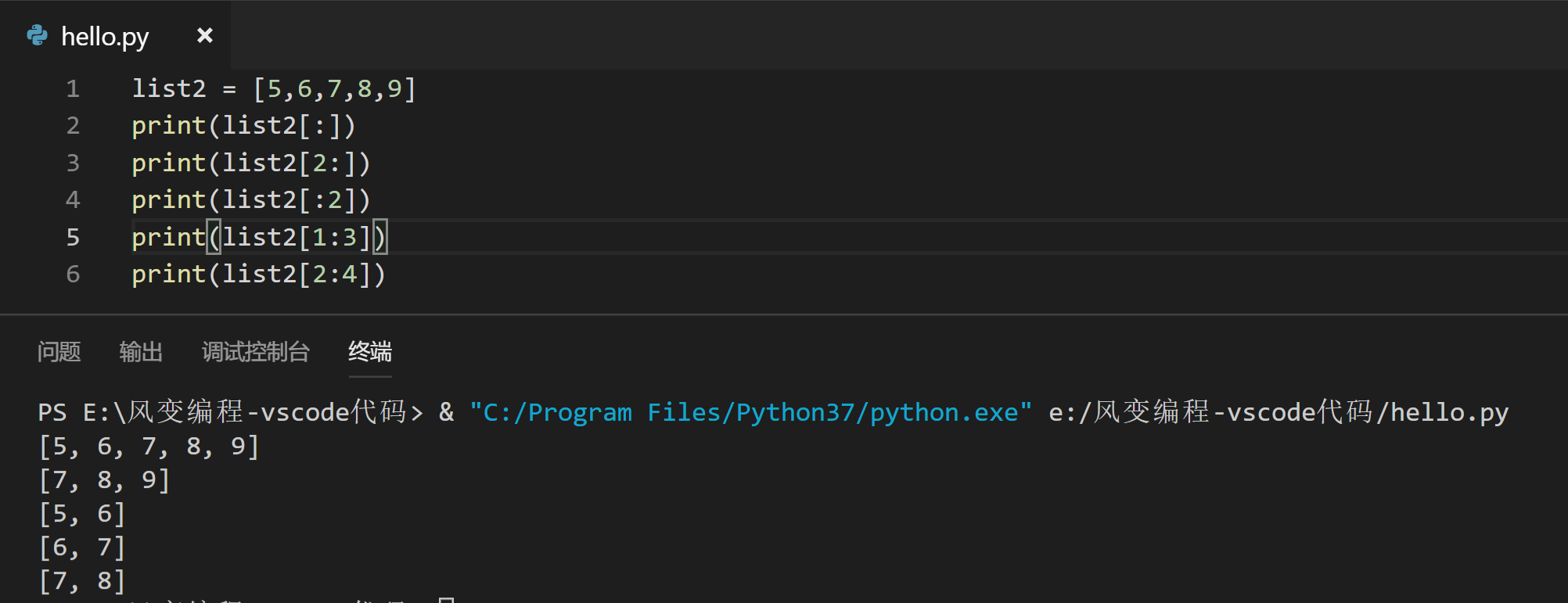

1.4 给列表增加/删除元素
过了一周,你正上着课呢,教导主任突然领了一个新学生“小美”,说是转校生,要插到你们班。这时,我们就需要用到append()函数给列表增加元素,append的意思是附加,增补。
举例:
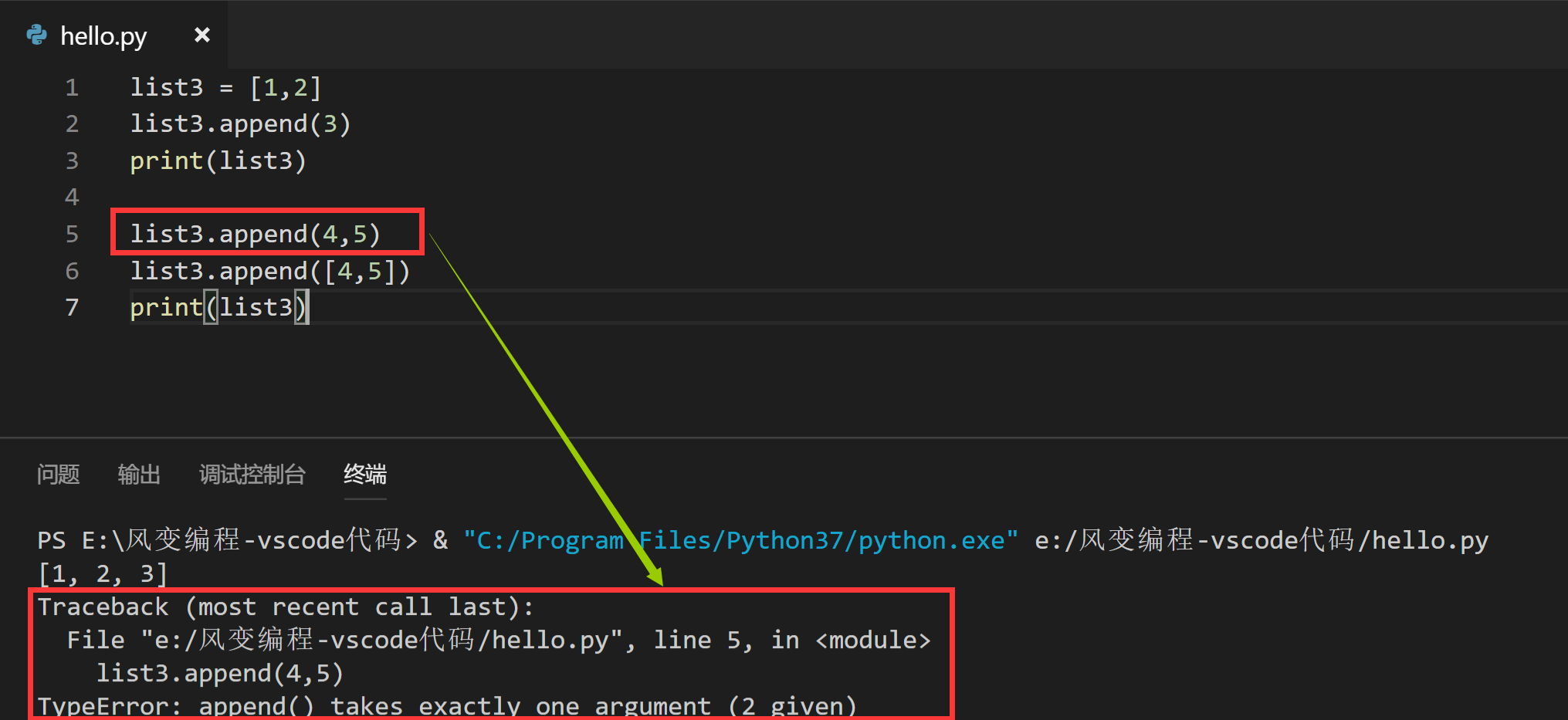
你发现规律了吗?我们来解读一下报错信息和代码的结果:
这句话的意思是:append后的括号里只能接受一个参数,但却给了两个,也就是4和5。所以,用append()给列表增加元素,每次只能增加一个元素
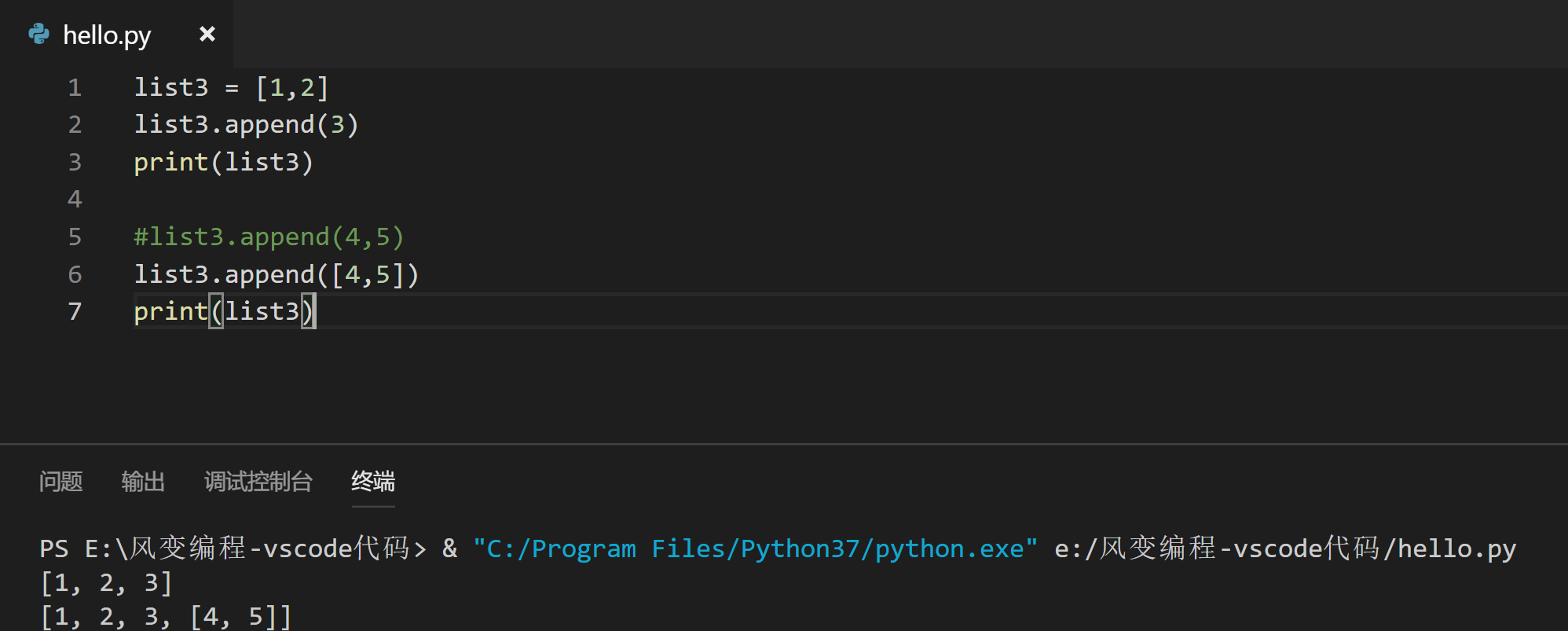
同时,从第6行代码 list3.append([4,5]) 能成功运行可以看出:
append函数并不生成一个新列表,而是让列表末尾新增一个元素。而且,列表长度可变,理论容量无限,所以支持任意的嵌套。
通过代码来试验一番:现在,请你把小美加入students列表中,并打印出列表,注意格式是列表名.append( ):
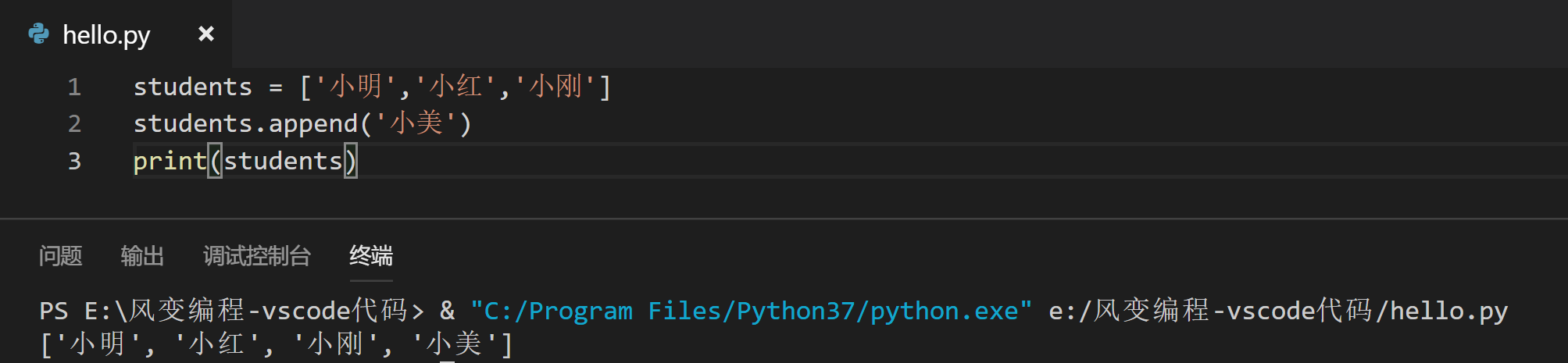
又是新的一天,你接到一个电话,小红生病请假了,今天不来上课。所以,你要将小红从列表中删除。
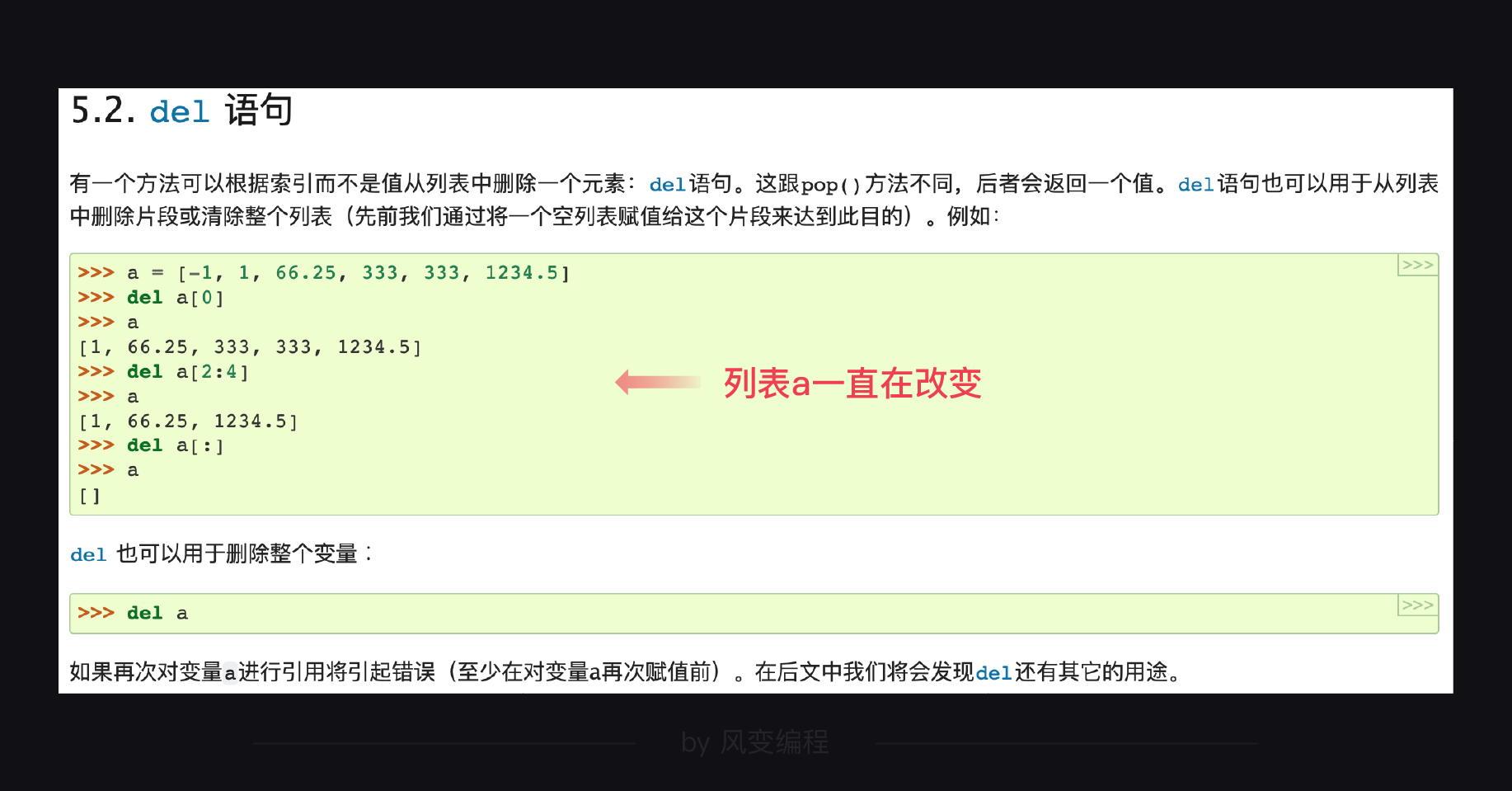
提示:需要用到del语句。请你先读一下Python官方文档对“del语句”的解释:(懂得阅读官方文档也是编程学习中一个重要能力)
根据上图中的知识,将'小红'从列表中删除,并打印出来:(语法是:del 列表名[元素的索引])
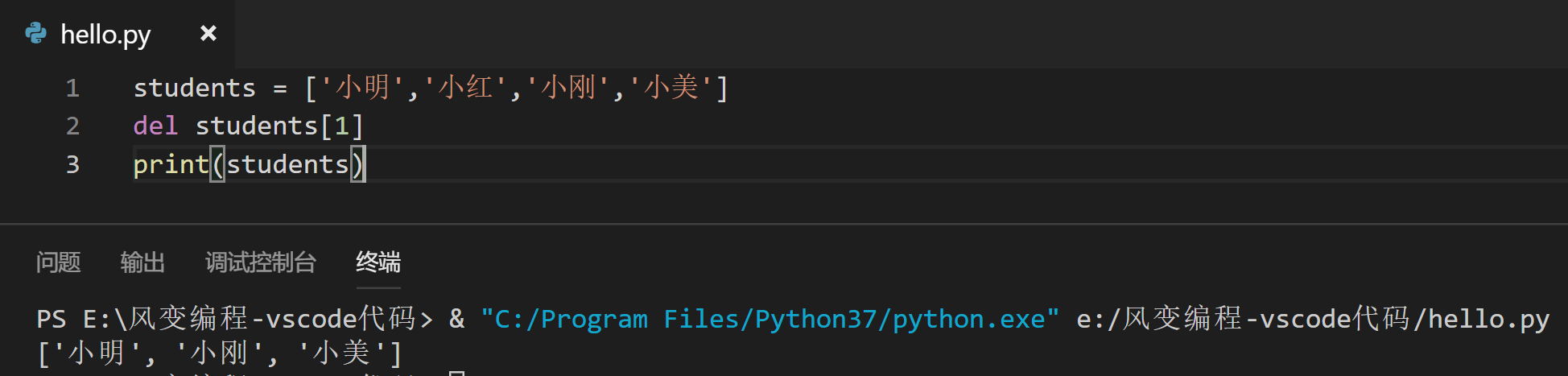
事实上del语句非常方便,既能删除一个元素,也能一次删除多个元素(原理和切片类似,左取右不取)。
至此,我们对列表的基本概况已经摸了个遍,是时候总结一下了:

2. 数据类型:字典
众所周知,一个老师的日常就是出卷、改卷。这次期中考呢,小明、小红、小刚分别考了95、90和90分。
假如我们还用列表来装数据的话,我们需要新创建一个列表来专门放分数,而且要保证和姓名的顺序是一致的,很麻烦。
所以类似这种名字和数值(如分数、身高、体重等)两种数据存在一一对应的情况,用第二种数据类型——“字典”(dictionary)来存储会更方便。
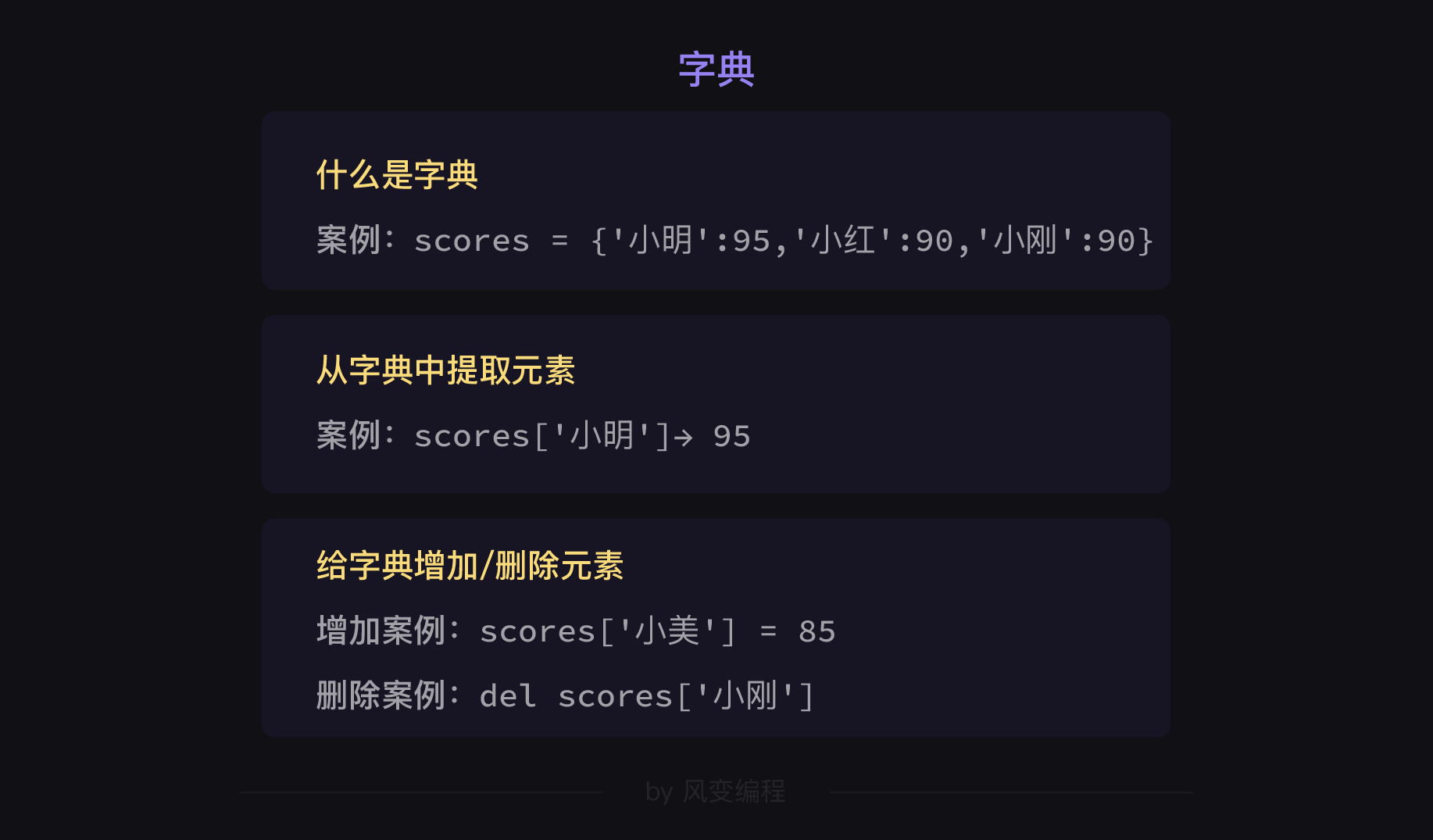
2.1 什么是字典
同样的,我们先来看一下字典是长怎么样的:

仔细看下,字典和列表有3个地方是一样的:1.有名称;2.要用=赋值;3.用逗号作为元素间的分隔符。
而不一样的有两处:1.列表外层用的是中括号[ ],字典的外层是大括号{ };
students = ['小明','小红','小刚']
scores = {'小明':95,'小红':90,'小刚':90}
2.列表中的元素是自成一体的,而字典的元素是由一个个键值对构成的,用英文冒号连接。如'小明':95,其中我们把'小明'叫键(key),95叫值(value)。
这样唯一的键和对应的值形成的组合,我们就叫做【键值对】,上述字典就有3个【键值对】:'小明':95、'小红':90、'小刚':90
如果不想口算,我们可以用len()函数来得出一个列表或者字典的长度(元素个数),括号里放列表或字典名称。
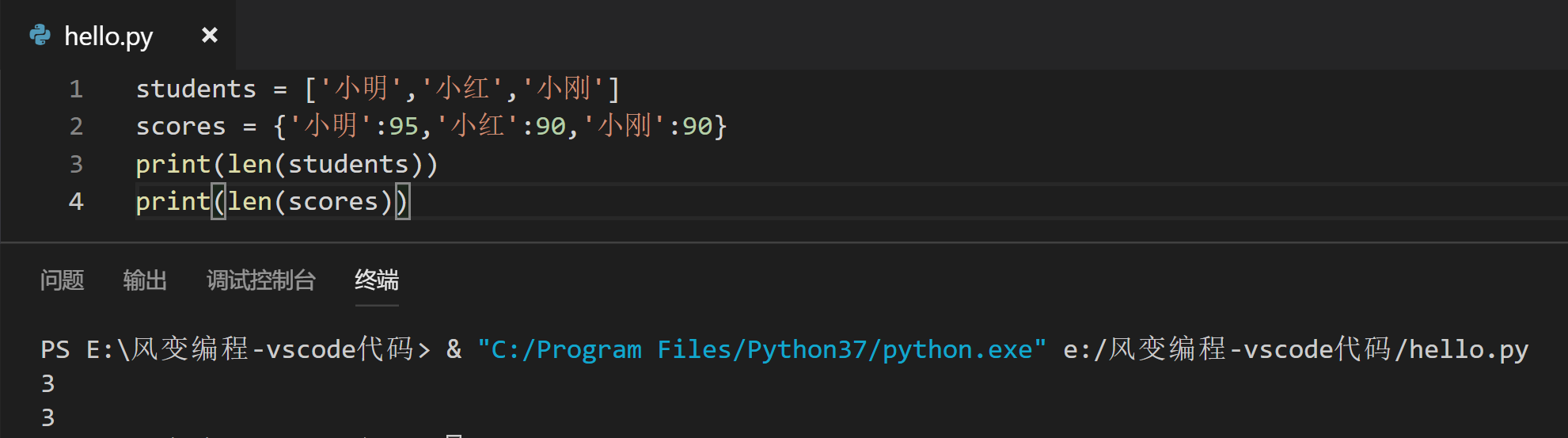
这里需要强调的是,字典中的键具备唯一性,而值可重复。
举例:
现在,我们尝试将小明的成绩从字典里打印出来。这就涉及到字典的索引,和列表通过偏移量来索引不同,字典靠的是键。
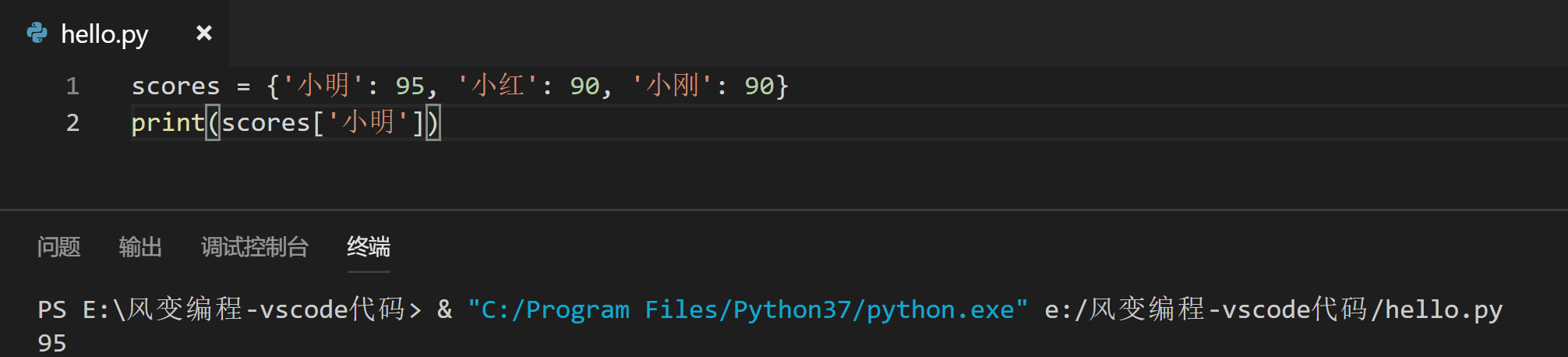
这便是从字典中提取对应的值的用法。和列表相似的是要用[ ],不过因为字典没有偏移量,所以在中括号中应该写键的名称,即字典名[字典的键]。
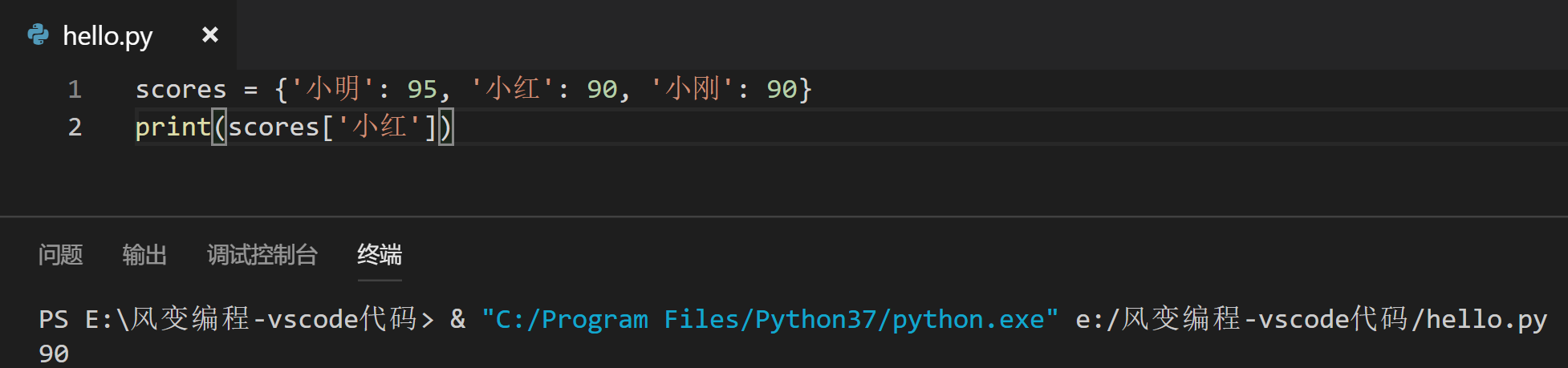
现在请你将小红的成绩也打印出来吧
2.2 给字典增加/删除元素
小刚拿到试卷后,下课后来找你,说把他总分算错了,应该是92分。你看了一下,发现还真的是。于是,你在成绩册上将90划掉,改成了92。
这个操作在代码里对应的是字典的删除和增加。
首先先来看一个例子:
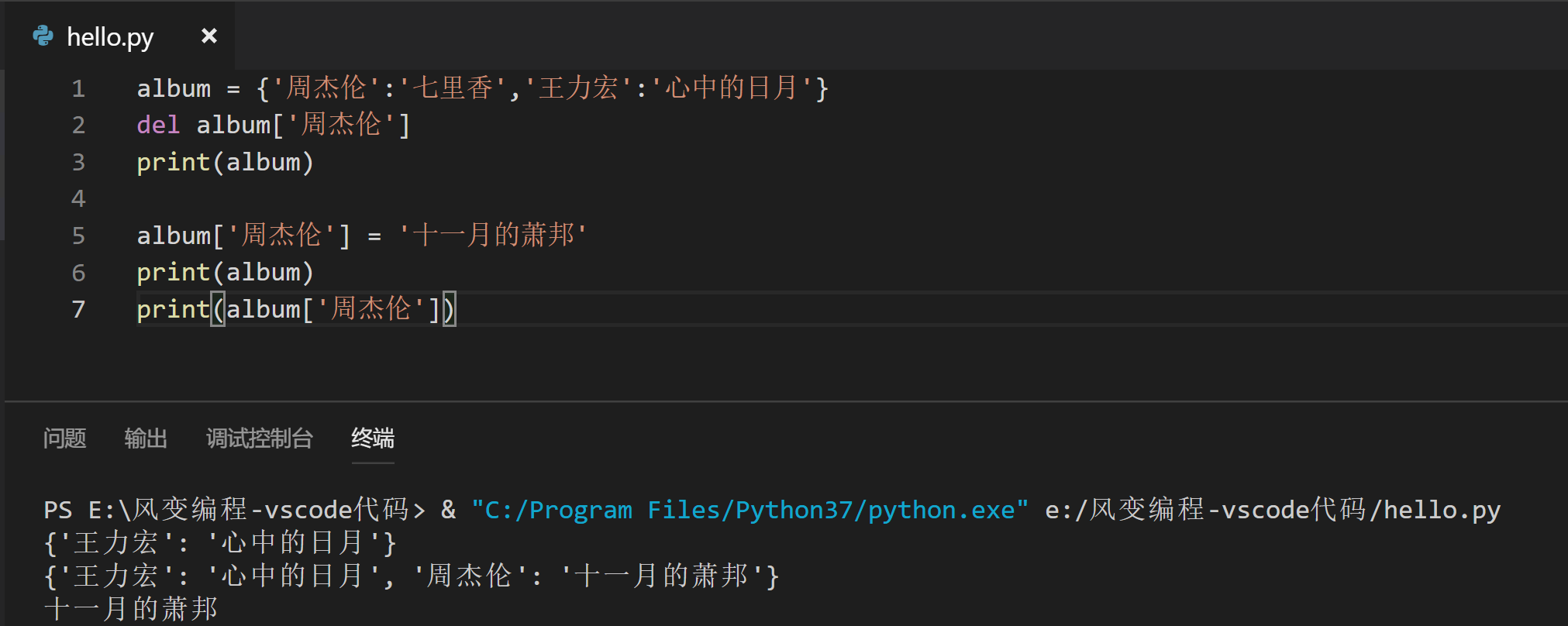
我们可以发现:删除字典里键值对的代码是del语句del 字典名[键],而新增键值对要用到赋值语句字典名[键] = 值。
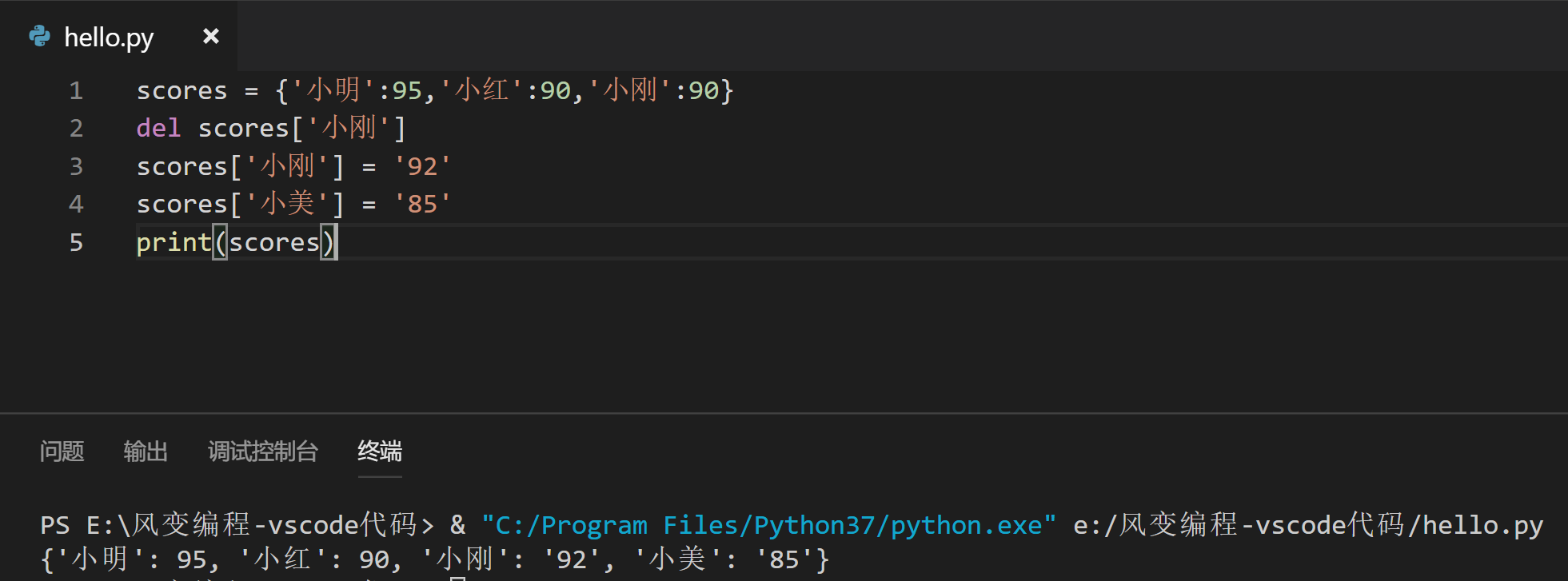
那么,请你把小刚的成绩改成92分吧。对了,新来的小美也考了,得了85。请你对字典里进行修改和新增,然后将整个字典都打印出来。
好了。至此,我们可以总结一下字典的基础知识:
3. 列表和字典的异同
列表和字典同作为Python里能存储多条数据的数据类型,有许多共同点,也有值得我们注意的不同点,那么接下来我们先来看看不同点。
3.1 列表和字典的不同点
一个很重要的不同点是列表中的元素是有自己明确的“位置”的,所以即使看似相同的元素,只要在列表所处的位置不同,它们就是两个不同的元素。
来看看这个:
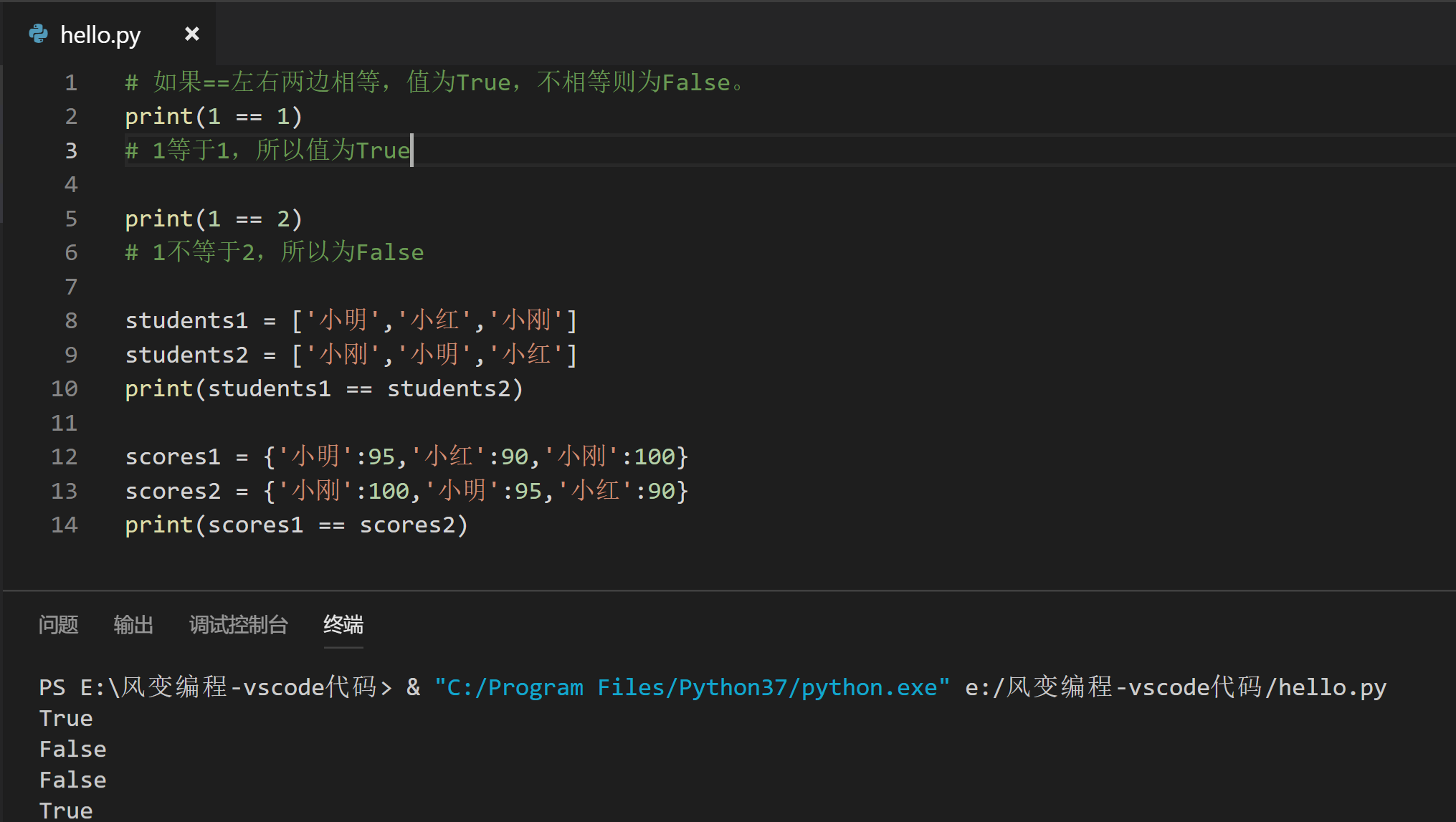
而字典相比起来就显得随和很多,调动顺序也不影响。因为列表中的数据是有序排列的,而字典中的数据是随机排列的。
这也是为什么两者数据读取方法会不同的原因:列表有序,要用偏移量定位;字典无序,便通过唯一的键来取值。
3.2 列表和字典的相同点
1.我们先来看第一个共同点:在列表和字典中,如果要修改元素,都可用赋值语句来完成。
举例:
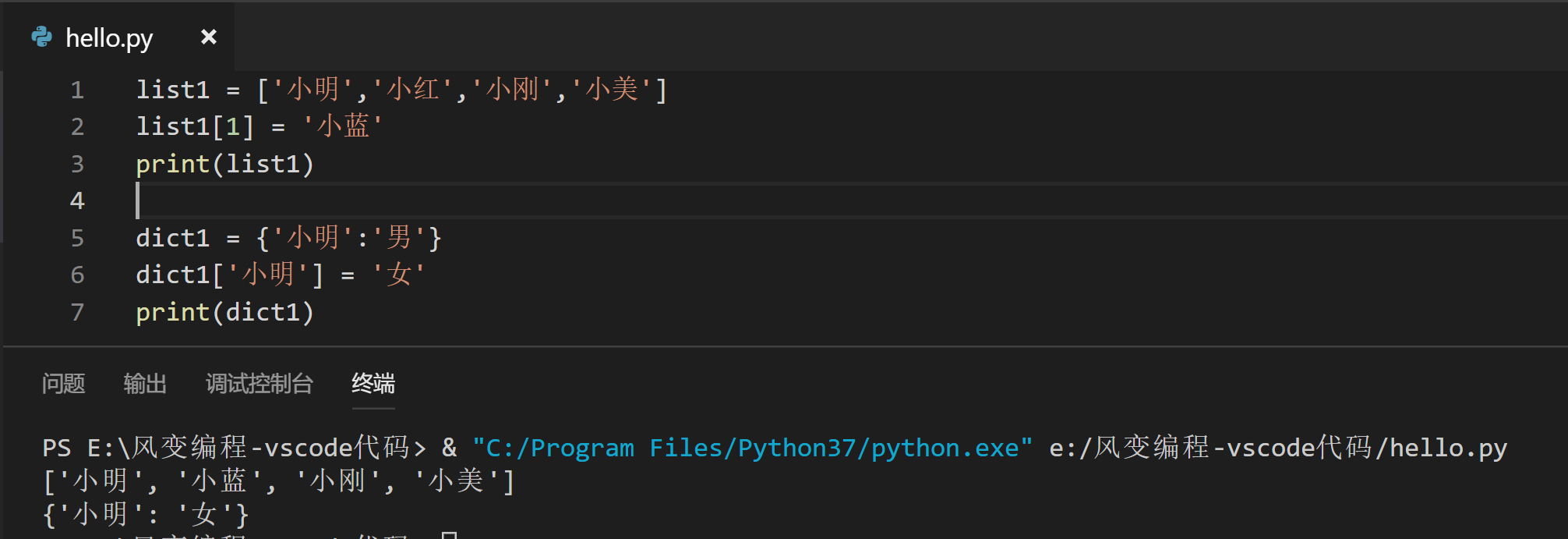
所以,上面修改小刚成绩的时候,其实直接用赋值语句即可,del语句通常是用来删除确定不需要的键值对。
scores = {'小明':95,'小红':90,'小刚':90}
#del scores['小刚']
#如果只需要修改键里面的值,可不需要del语句
scores['小刚'] = 92
2.第二个共同点其实之前已经略有提及,即支持任意嵌套。除之前学过的数据类型外,列表可嵌套其他列表和字典,字典也可嵌套其他字典和列表。
icon先来看看第一种情况:列表嵌套列表。你在班级里成立了以四人为单位的学习小组。这时,列表的形式可以写成:
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]
students这个列表是由两个子列表组成的,现在有个问题是:我们要怎么把小芳取出来呢?
可能你数着小芳是列表的第7个元素(从0开始),所以想students7不就能取到小芳吗?
事情当然没有那么简单,当我们在提取这种多级嵌套的列表/字典时,要一层一层地取出来,就像剥洋葱一样:
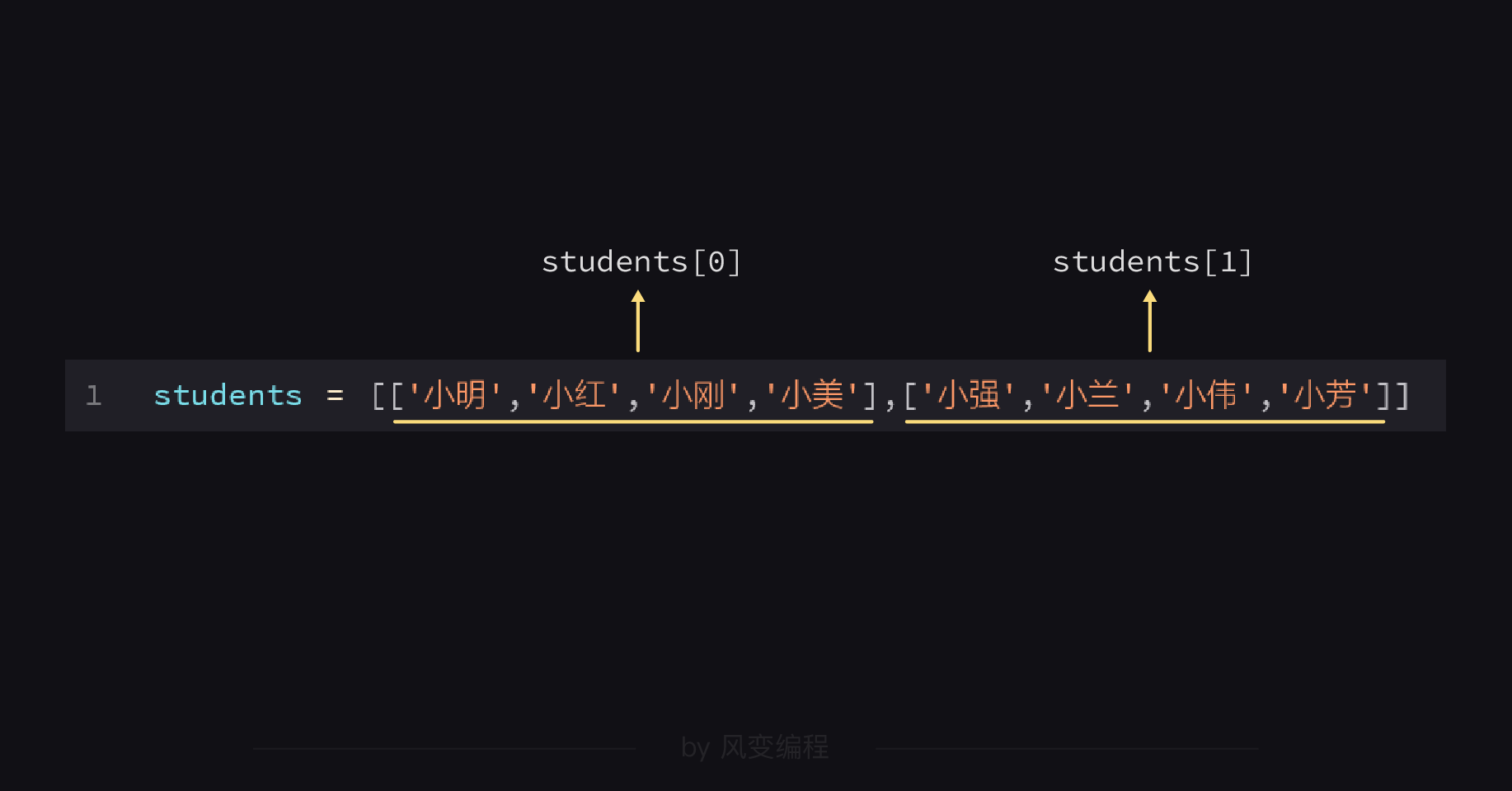
现在,我们确定了小芳是在students1的列表里,继续往下看。

小芳是students1列表里偏移量为3的元素,所以要取出小芳,代码可以这么写:
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]
print(students[1][3])
接下来,我们再来看看第二种情况:字典嵌套字典。
和列表嵌套列表也是类似的,需要一层一层取出来,比如说要取出小芳的成绩,代码是这样写:
scores = {
'第一组':{'小明':95,'小红':90,'小刚':100,'小美':85},
'第二组':{'小强':99,'小兰':89,'小伟':93,'小芳':88}
}
print(scores['第二组']['小芳'])
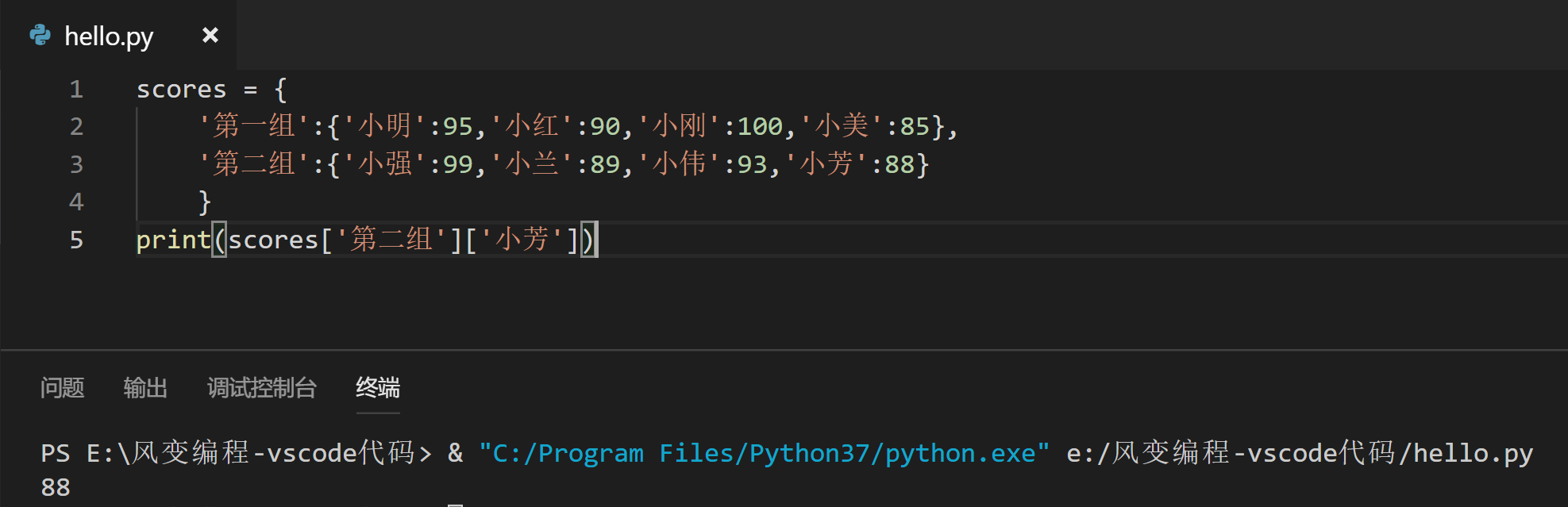
我们再来提高下难度,看看列表和字典相互嵌套的情况,可以将代码和注释结合起来看。
# 最外层是大括号,所以是字典嵌套列表,先找到字典的键对应的列表,再判断列表中要取出元素的偏移量
students = {
'第一组':['小明','小红','小刚','小美'],
'第二组':['小强','小兰','小伟','小芳']
}
print(students['第一组'][3])
#取出'第一组'对应列表偏移量为3的元素,即'小美'
# 最外层是中括号,所以是列表嵌套字典,先判断字典是列表的第几个元素,再找出要取出的值相对应的键
scores = [
{'小明':95,'小红':90,'小刚':100,'小美':85},
{'小强':99,'小兰':89,'小伟':93,'小芳':88}
]
print(scores[1]['小强'])
#先定位到列表偏移量为1的元素,即第二个字典,再取出字典里键为'小强'对应的值,即99。
4. 习题练习
4.1 习题一
1.练习目标:
我们会通过今天的作业,更熟练地取出层层嵌套中的数据,并了解一种新的数据类型:元组。
2.练习要求:
我们知道了列表和字典的不同:列表的基本单位是元素,而字典里是键值对。所以,两者提取数据的方式也不同。
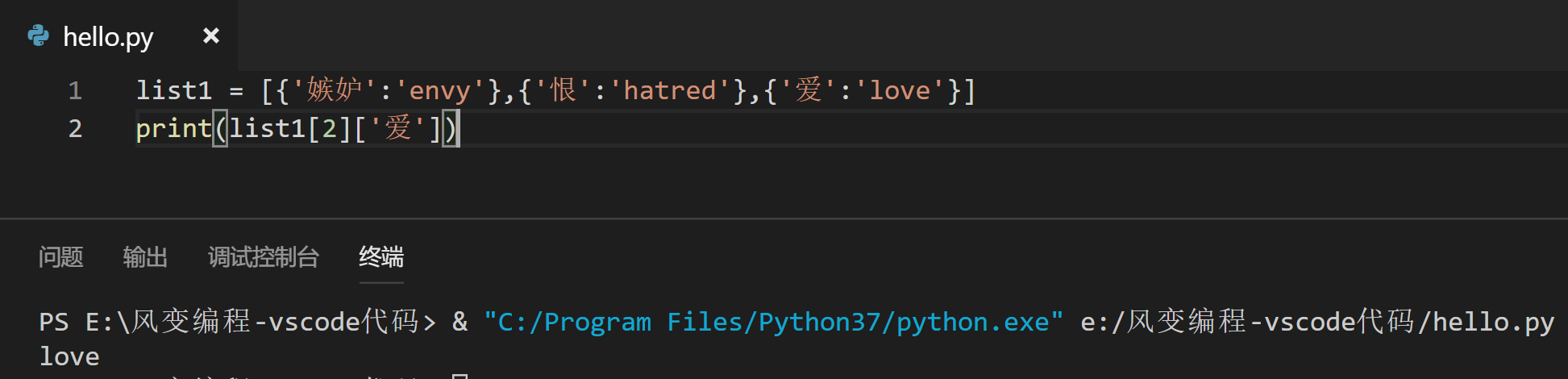
(1)请你通过所学知识,把列表list1中的'love'取出来,并打印出来。
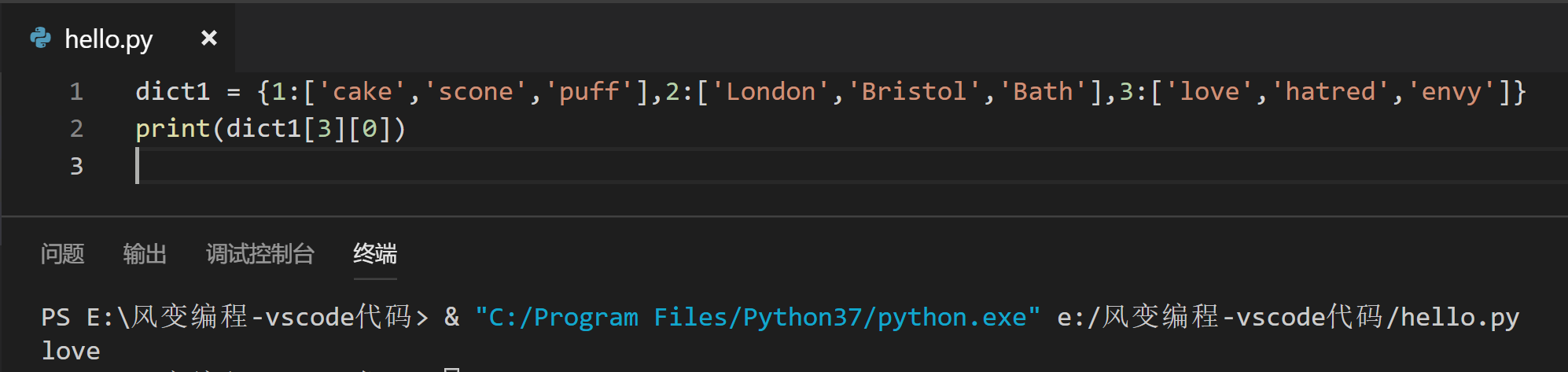
(2)请你通过所学知识,把字典dict1中的'love'取出来,并打印出来。
(3)下面,介绍一种新的数据类型:元组(tuple)。 可以看到:元组和列表很相似,不过,它是用小括号来包的。
元组和列表都是序列,提取的方式也是偏移量,如 tuple11、tuple1[1:]。另外,元组也支持任意的嵌套。
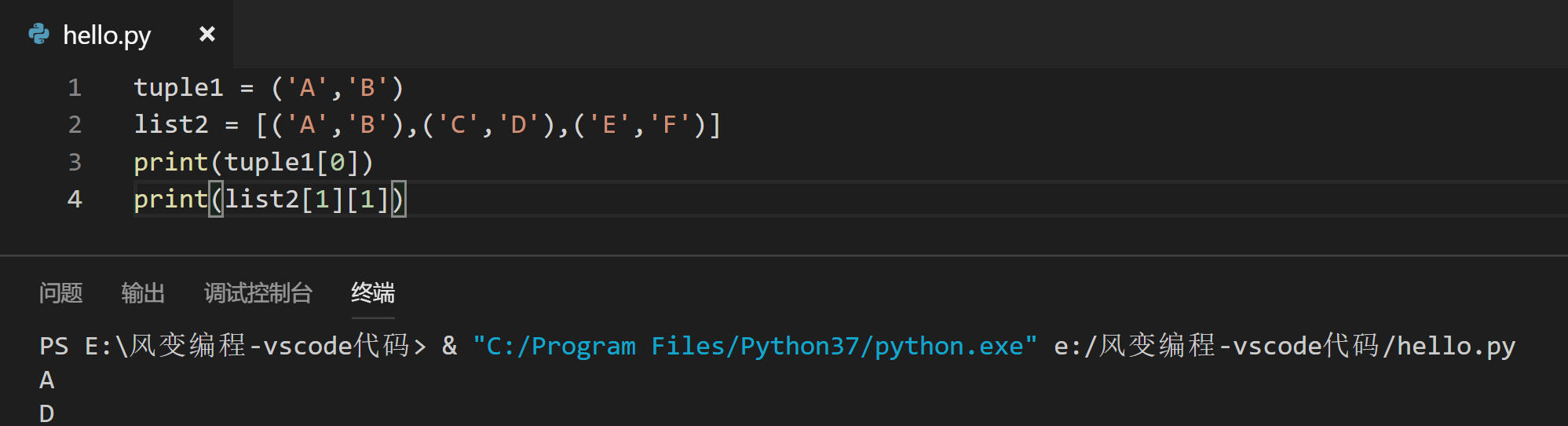
请你根据以上提供的信息,将tuple1中的A和list2中的D打印出来。
(4)代码参考
list1 = [{'嫉妒':'envy'},{'恨':'hatred'},{'爱':'love'}]
print(list1[2]['爱'])
# 第一步:取出列表中的第三个元素(list1[2]),字典{'爱':'love'};
# 第二步:取出list1[2]中键'爱'所对应的值,即'love’(list1[2]['爱'])。
dict1 = {1:['cake','scone','puff'],2:['London','Bristol','Bath'],3:['love','hatred','envy']}
print(dict1[3][0])
# 第一步:取出字典中键为3对应的值(dict1[3]),即['love','hatred','envy']。
# 第二步:再取出列表['love','hatred','envy']中的第一个元素(dict1[3][0])。
tuple1 = ('A','B')
list2 = [('A','B'),('C','D'),('E','F')]
print(tuple1[0])
print(list2[1][37])
# 从代码里,也可看出:1.元组内数据的提取也是用偏移量;2.元组也支持互相嵌套。
4.2 习题二
1.练习目标
在层层嵌套的各种数据类型中,准确地提取出你需要的数据。
2.练习要求
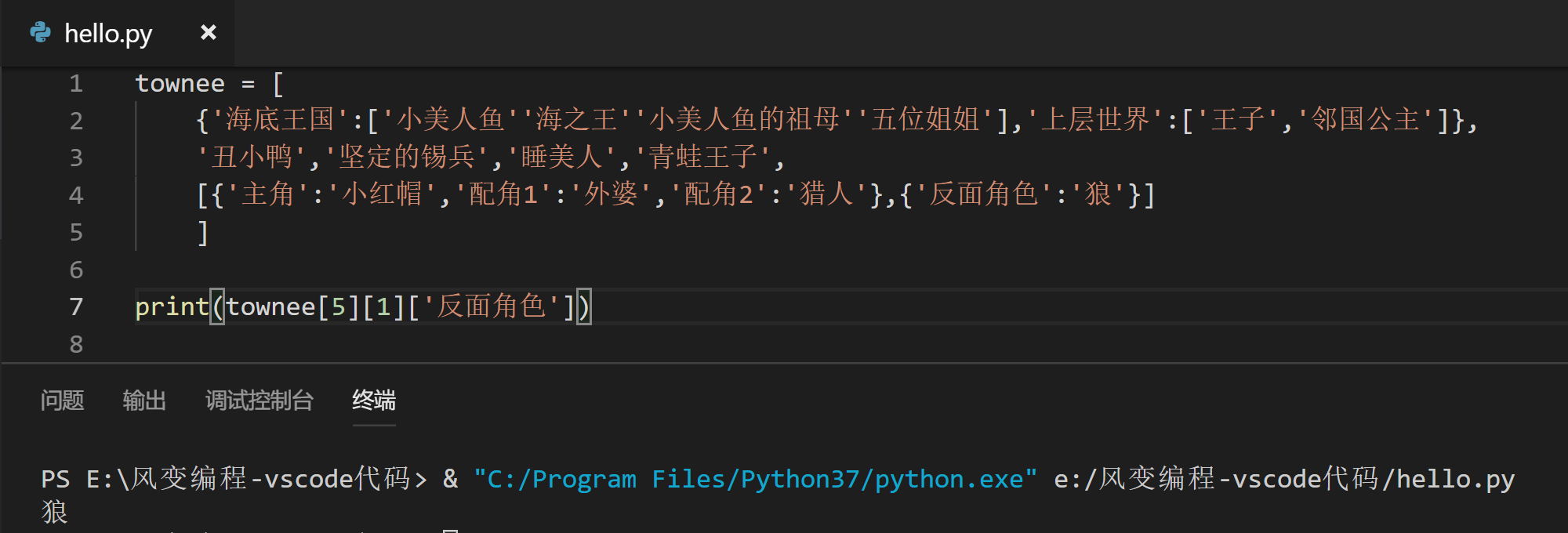
在未来世界,一个新建的童话镇吸引了不少人入住。
不过,在人群里隐藏着一只狼,会威胁大家的安全。
童话镇的镇长希望你能找到它,并揭发其身份。
用程序语言就是说:列表中有个字符串是“狼”,将其打印出来吧。
节选自风变编程学习笔记:https://www.pypypy.cn/
标签:章节,小明,元素,偏移量,列表,小刚,字典 来源: https://www.cnblogs.com/ywb123/p/16338646.html