知识蒸馏
作者:互联网

第一个方向是把一个已经训练好的臃肿的网络进行瘦身
权值量化:把模型的权重从原来的32个比特数变成用int8,8个比特数来表示,节省内存,加速运算
剪枝:去掉多余枝干,保留有用枝干。分为权重剪枝和通道剪枝,也叫结构化剪枝和非结构化剪枝,一根树杈一根树杈的剪叫非结构化剪枝,也可以整层整层的剪叫结构化剪枝。
第二个方向是在设计时就考虑哪些算子哪些设计是轻量化的
第三个方向是在数值运算的角度来加速各种算子的运算
比如im2col+GEMM,就是把卷积操作转成矩阵操作,矩阵操作是很多算法库里内置的功能,比如py,tf和matlab都有底层的加速到极致的矩阵运算的算子
第四个方向就是硬件部署
用英伟达的TensorRT库,把模型压缩成中间格式,部署在Jetson开发板上;Tensorflow-slim和Tensorflow-lite是tensorflow轻量化的生态;因特尔的openvino;FPGA集成电路也可以部署人工智能算法
轻量化网络有很多需要考虑的内容:参数量、计算量···
知识的表示与迁移

把左边的马图像喂给分类模型,会有很多类别,每个类别识别出一个概率,训练网络时,我们只会告诉网络,这张图片是马,其余是驴是汽车的概率都是0,这个就是hard targets,用hard targets训练网络,但这就相当于告诉网络,这就是一匹马,不是驴不是车,而且不是驴不是车的概率是相等的,这是不科学的。若是把马的图片喂给已经训练好的网络里面,网络给出soft targets这个结果,是马的概率为0.7,为驴的概率为0.25,为车的概率是0.05,所以soft targets就传递了更多的信息。

所以训练教师网络的时候就可以用hard targets训练,训练出了教师网络之后,教师网络对这张图片的预测结果soft targets能够传递更多的信息,就可以用soft targets去训练学生网络
总结
Soft Label包含了更多“知识”和“信息,像谁,不像谁,有多像,有多不像,特别是非正确类别概率的相对大小(驴和车)
引入蒸馏温度T,把原来比较硬的soft targets变的更软,更软的soft targets去训练学生网络,那些非正确类别概率的信息就暴露的越彻底,相对大小的知识就暴露出来,让学生网络去学
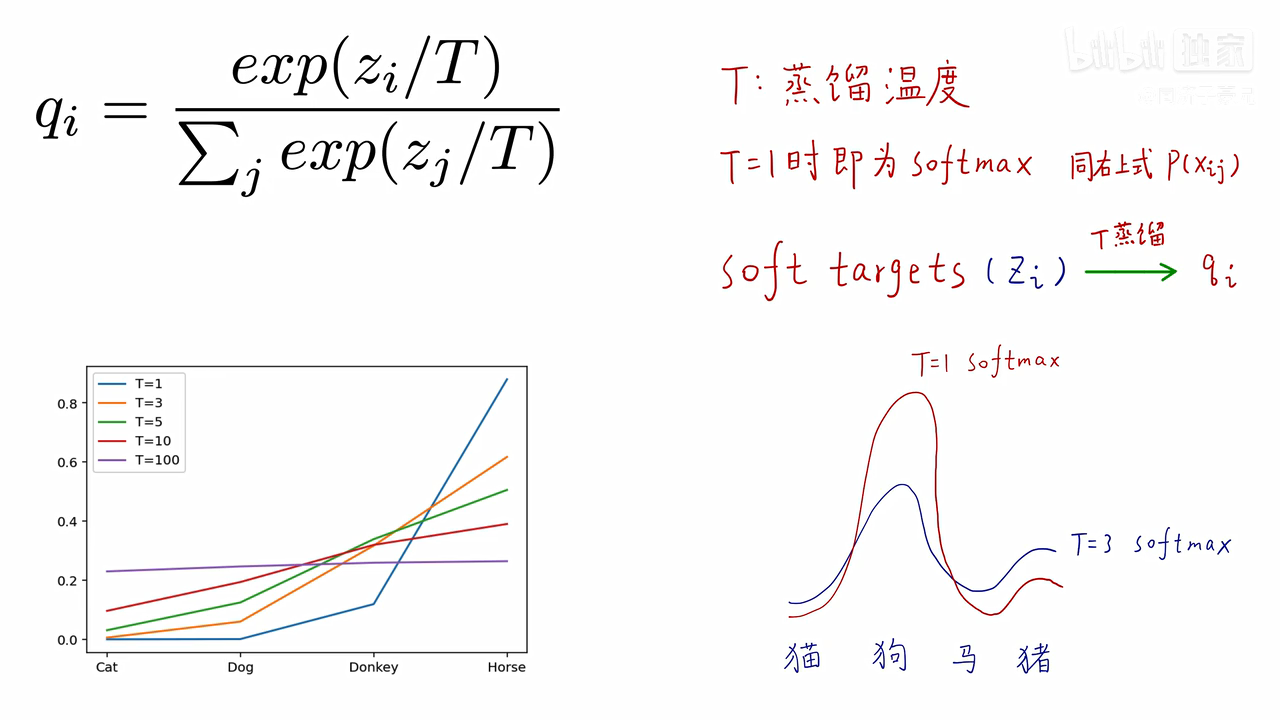
T为1,就是原softmax函数,softmax本来就是把每个类别的logic强行变成0-1之间的概率,并且求和为1,是有放大差异的功能,如果logic高一点点,经过softmax,都会变的很高。
T越小,非正确类别的概率相对大小的信息就会暴露的更明显;T越大,曲线就会变得更soft,高的概率给降低,低的概率会变高,贫富差距就没有了。
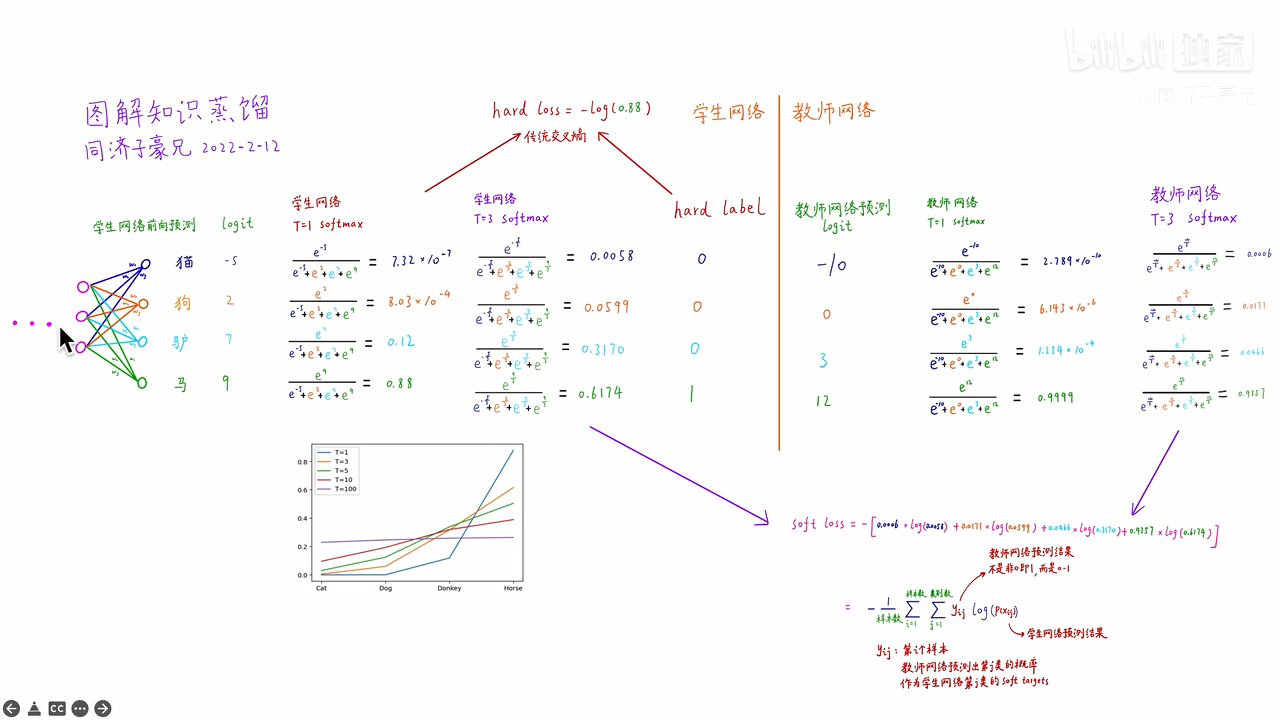
举个例子:
左侧学生网络是个神经网络,四个类别有一个线性分类层,猫的类别给出的分数logit为-5,狗的类别给出的分数logit为2,驴的类别给出的分数logit为7,马的类别给出的分数logit为9
原来的softmax在图中是当T=1时的计算,从计算结果可以看出,有不同数量级,贫富差异较大;
当T=3时,得到的分布就更软了,基本是同一个数量级。但是还是几个数值均分布在0-1之间且和为1
右侧教师网络也是
知识蒸馏的过程
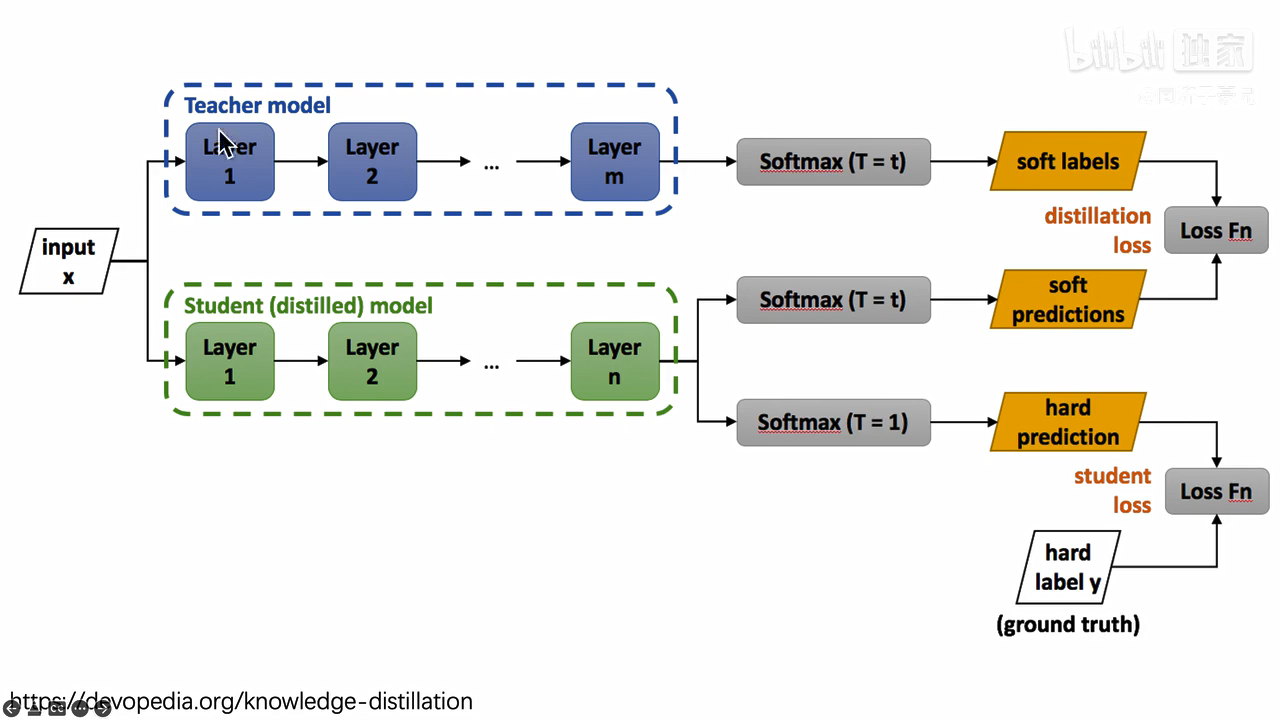
首先有一个已经训练好的教师网络(Teacher model),把很多数据(input)喂给教师网络,教师网络会给每个数据都给一个温度为T的时候的softmax(文中soft labels);同时把数据(input)喂给学生网络(student model),也给学生网络一个温度T获得softmax(文中soft predictions),对soft labels和soft predictions做一个损失函数L(distillation loss也叫soft loss),让他们两个越接近越好,解释就是学生在模拟老师的预测结果;学生网络经过一个T=1的普通的softmax(文中的hard prediction)和hard label再做一个损失函数(student loss也叫hard loss),让他们两个越接近越好。所以这个学生网络既要在温度为T的预测结果和教师网络的预测结果尽可能接近,又要在温度为1的预测结果和标准答案更可能接近。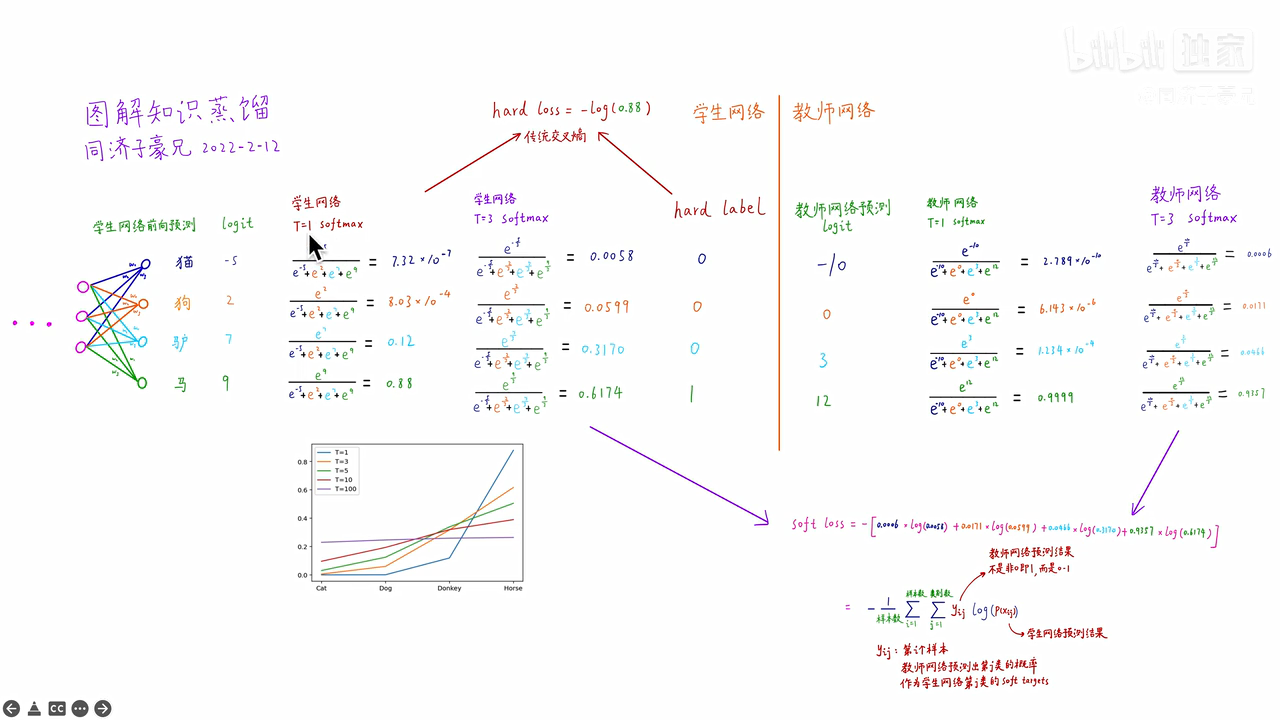
计算hard loss:学生网络和hard label之间的传统交叉熵为-log(0.88)
计算soft loss:如图
将两个损失函数求和,作为最终学生网络的损失函数,去训练学生网络
知识蒸馏有一个附带的效果:假如用没有3的minist手写数据集去训练学生网络,但是训练教师网络的时候是用的所有类别去训练的,教师网络也会将3的知识迁移给学生网络,虽然学生网络从来没见过3这个类别样本,但是最终学生网络也能预测3。
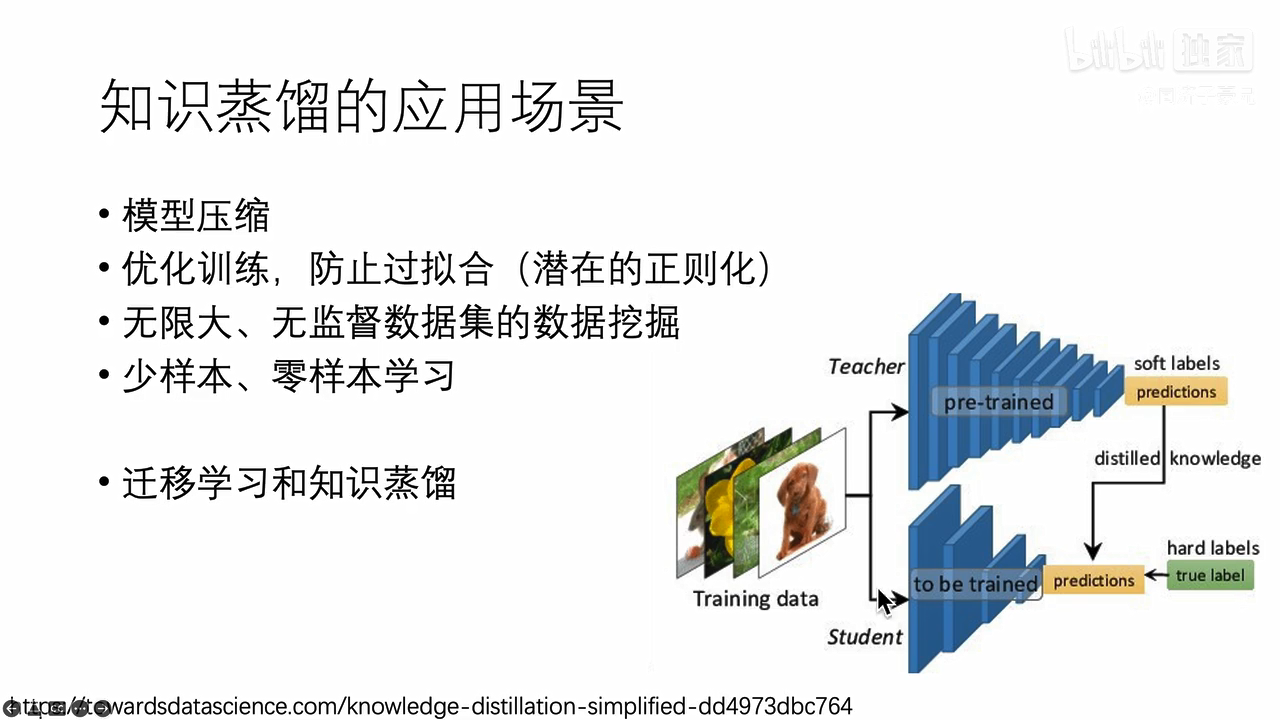
为什么知识蒸馏有用: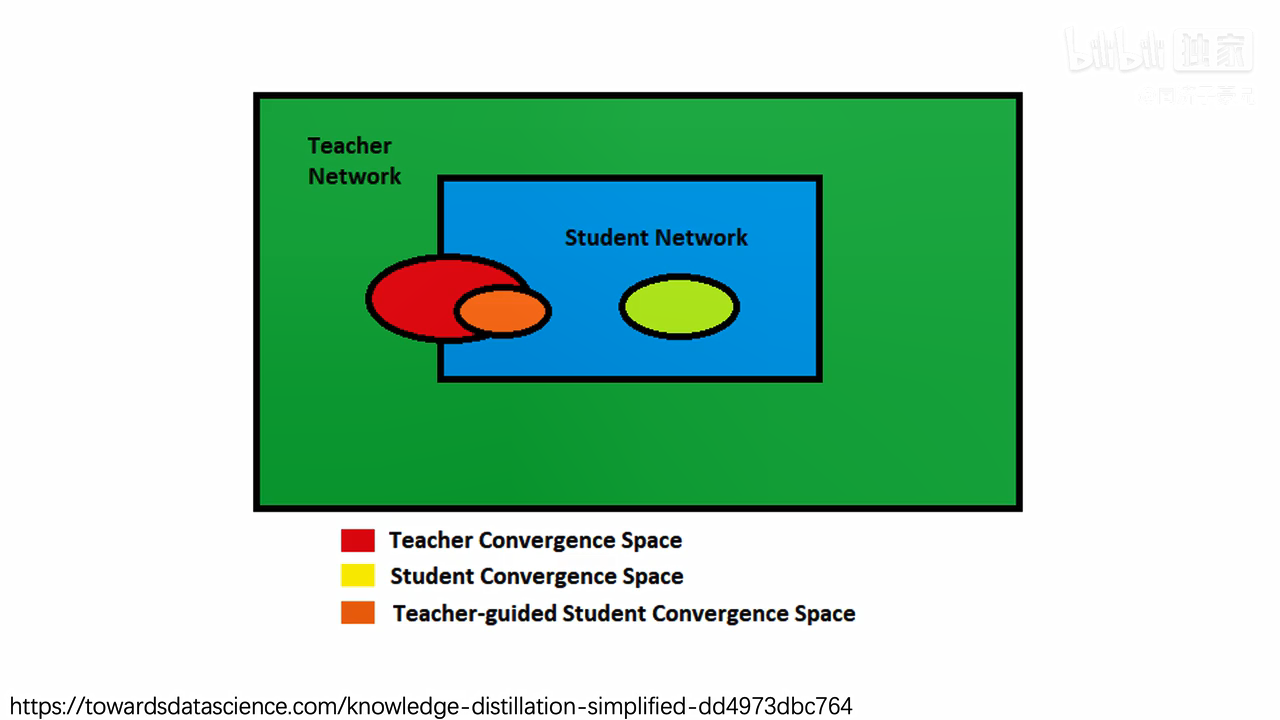
绿色是教师网络的求解空间,表达能力拟合能力比较强,蓝色是学生网络,表达能力拟合能力比较差,训练教师网络之后,教师网络收敛到红圈里面,单独训练学生网络,不蒸馏,学生网络会收敛到金黄色的圈子,金黄色的圈子和红圈有一定距离。加上蒸馏(橙黄色的圈)以后,教师网络就会引导黄权,告诉他怎么收敛,最终收敛到橙圈里,与红圈越近,性能越好
知识蒸馏发展趋势 
1、教学相长:都是老师帮学生,那学生能不能帮助老师成长
2、引入助教,多个老师、多个同学
3、刚才的知识只通过soft targets来表示,只是网络最后一层的预测结果,网络的中间层是不是也可以解刨出来进行知识蒸馏,例如,如下图所示,让学生网络的第一层模拟教师网络的第五层,让学生网络的第二层模拟教师网络的第十层,这样,老师不仅把最后结果告诉你,也把对这个问题的思考告诉学生网络;还可以对数据集进行蒸馏,对比学习进行蒸馏
4、多模态:既有视觉又有文本又有语音怎么蒸馏,对知识图谱进行蒸馏,对预训练大模型进行知识蒸馏 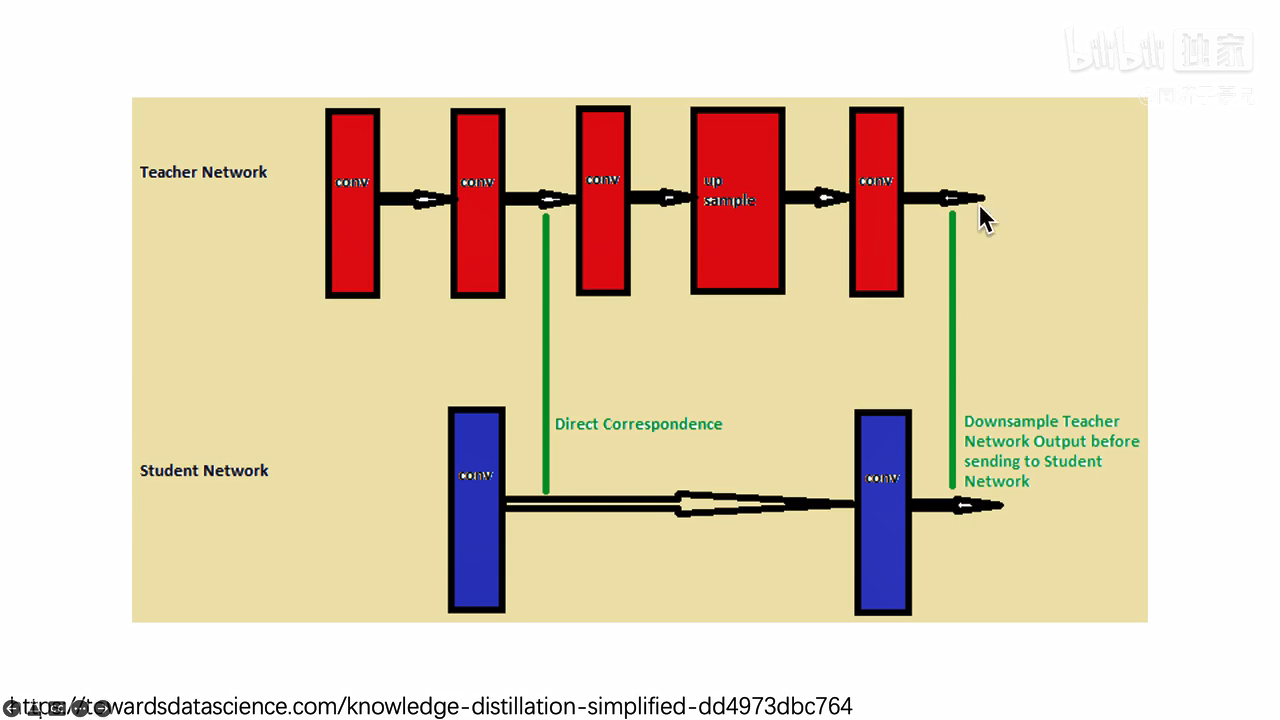
知识蒸馏代码库
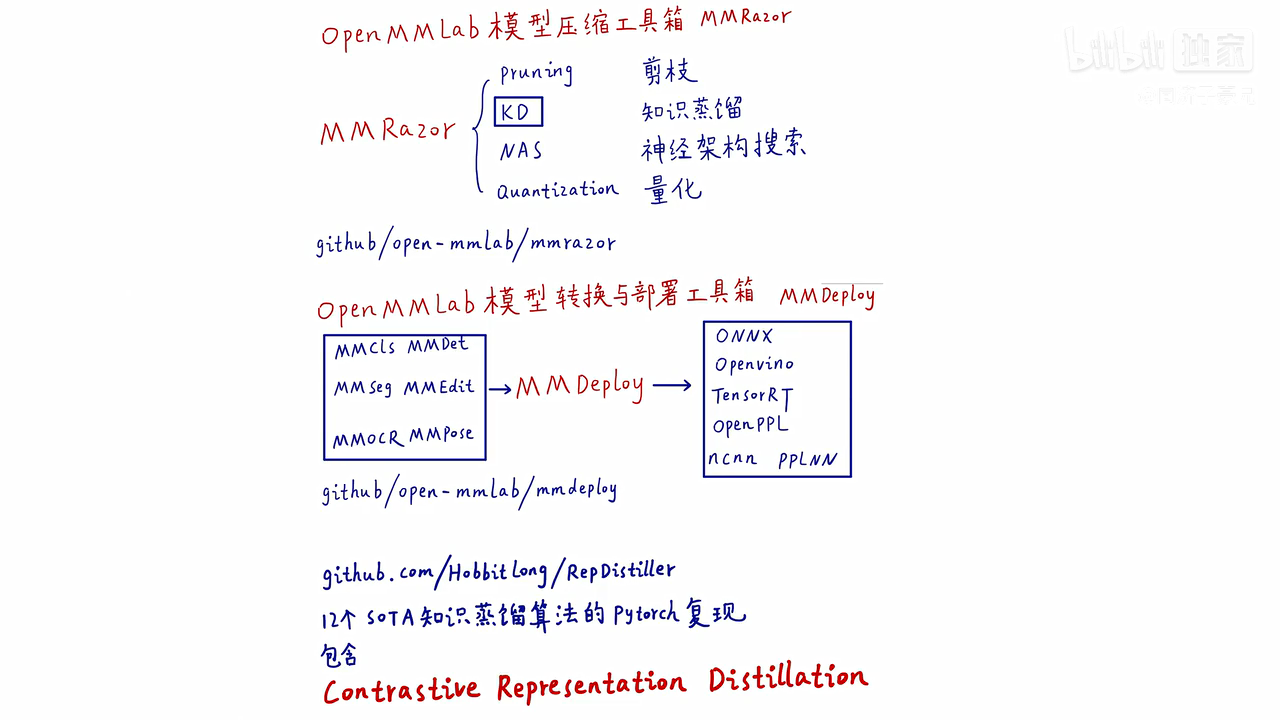
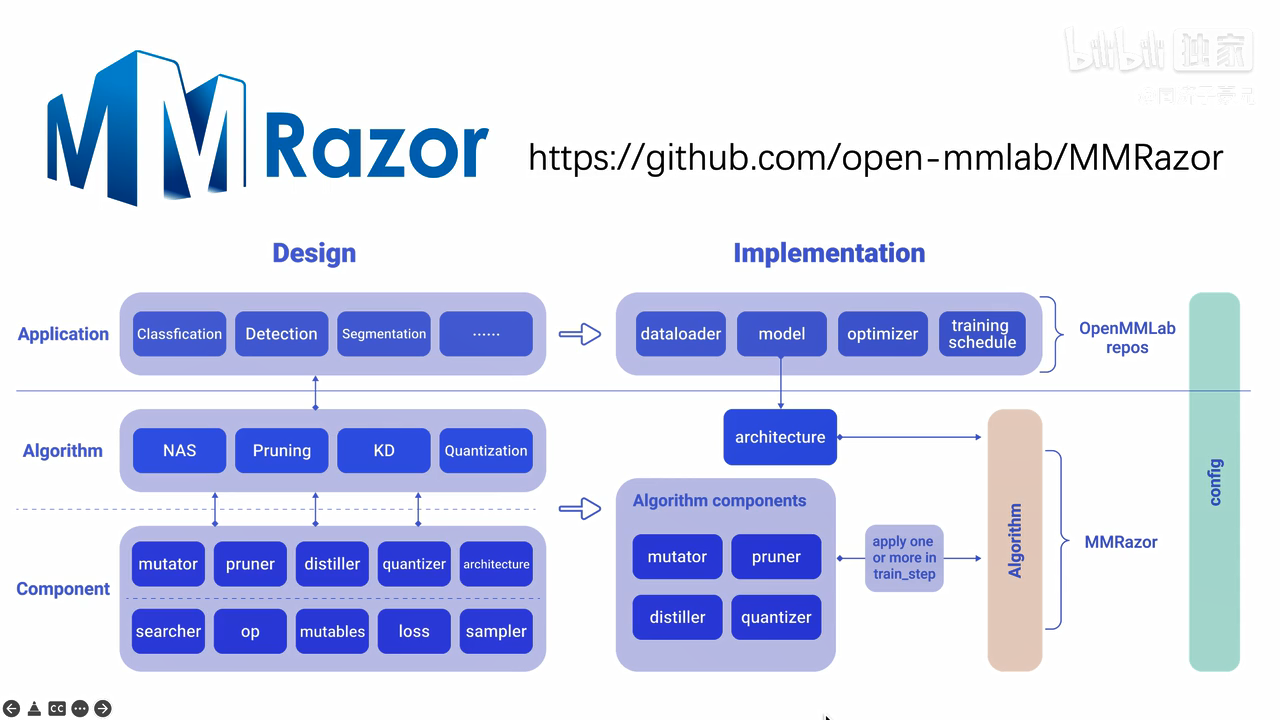
模型压缩工具箱MMRazor开源库:
https://github.com/open-mmlab/mmrazor,包括剪枝,蒸馏,神经架构搜索和量化。
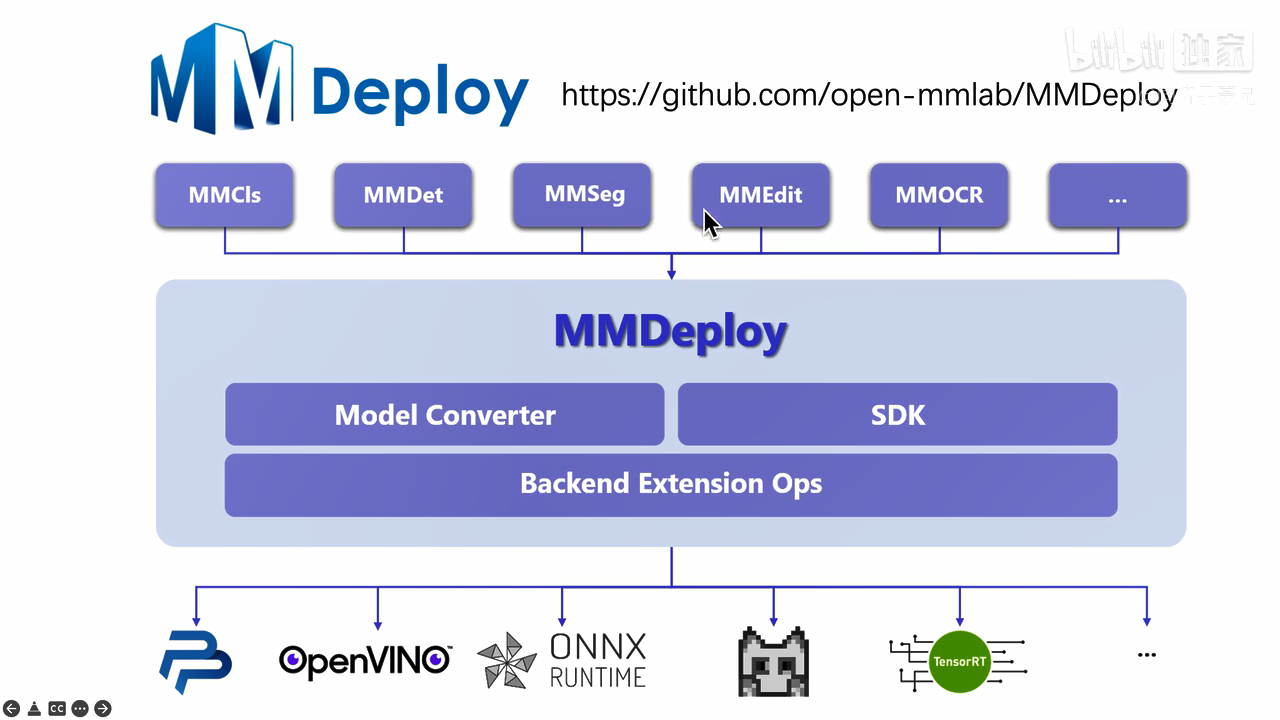
模型转换与部署工具箱MMDeploy开源库:
https://github.com/open-mmlab/mmdeploy
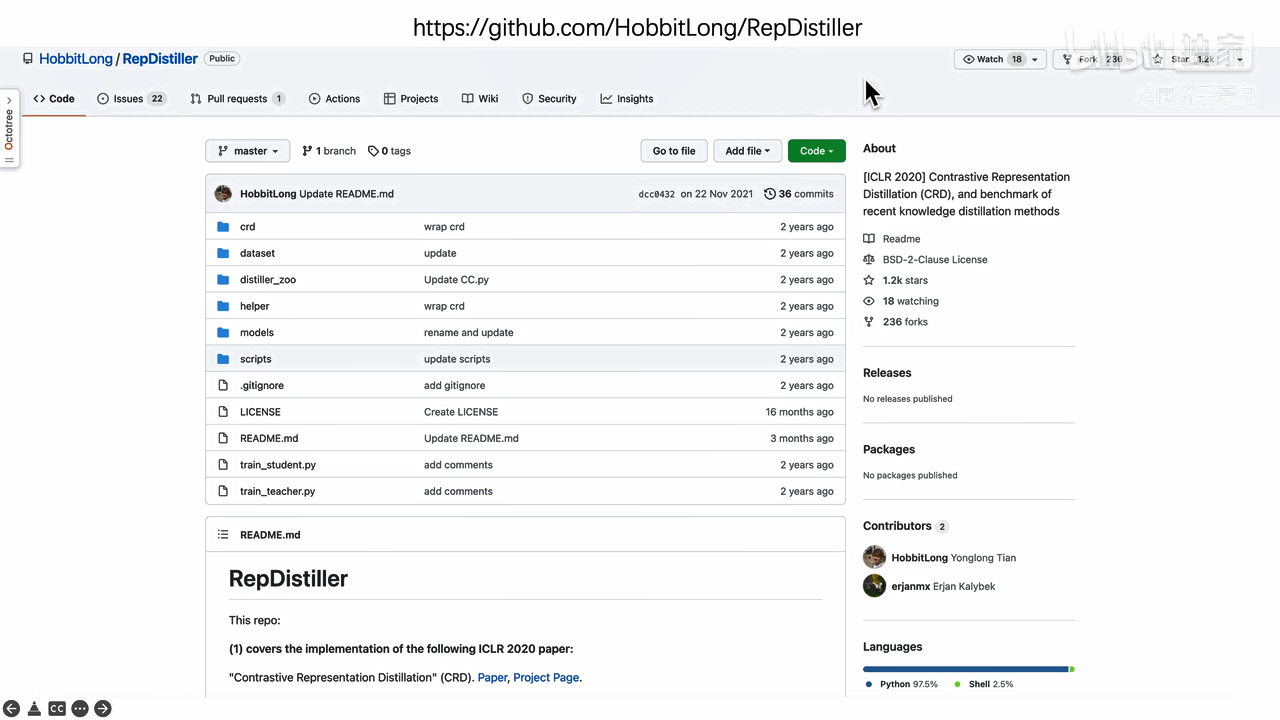
12个SOTA知识蒸馏算法的pytorch复现:https://github.com/Hobbitlong/RepDistiller



标签:教师,蒸馏,知识,网络,学生,soft,targets 来源: https://www.cnblogs.com/suehoo/p/16322525.html