数据预处理利器 Amazon Glue DataBrew
作者:互联网

前言
在日常业务中,我们通常使用关系型数据库来存储数据,供应用程序使用。
数据库按表、行来存储数据的方式常常造成不同敏感程度的数据被混合在一起,但在做数据统计时,我们需要更细粒度地去区分不同数据的权限,避免造成敏感数据泄露。
以证券交易所为例,不同部门可能会有不同的数据访问需求。
-
财务部门,需要对本日的交易额和手续费进行汇总
-
合规部门,需要对特定地区的交易进行审计
-
数据部门,需要使用脱敏数据进行应用研发
这些需求很难通过在数据表上设定权限来实现。它们有的需要做字段级的访问控制,有的需要对特定内容进行限制,也有的需要对字段做一些遮罩处理。
面对这个需求,我们可以使用传统的 ETL 手段和工具来处理,也可以使用无服务器的 Amazon Glue DataBrew 来实现。今天,我们来介绍一下 Amazon Glue DataBrew 的基本用法和常见使用场景。
Amazon Glue DataBrew 简介
Amazon Glue DataBrew(下简称「DataBrew」) 是一个无服务器的、可视化的数据预处理和 ETL 工具。它提供了一个可视化编辑界面,让用户可以分析数据形态数据,并对数据进行处理操作,预览效果。它提供了 200 多项操作和函数,可以满足大部分基本数据处理需求。
核心概念
这次我们主要讲解数据处理,其中涉及的核心概念有下面几个。
-
数据集(Dataset),即原始数据加上与之对应的元数据
-
项目(Project),就是基于 Web 的可视化数据编辑器
-
处置方案(Recipe),即对数据进行一系列处理,比如去除空字段、转换数据类型等等
接下来,我们就来进行第一步:数据集的创建。
创建数据集
这次我们使用纽约市出租车行程开放数据(NYC-TLC)作为示范。
1、创建本地 S3 桶
因为有区域限制,所以 NYC-TLC 的数据无法在 DataBrew 中直接使用。要使用这个数据,我们必须先自己创建一个 S3 桶,再把其中一部分数据复制过来。
2、复制到本地 S3 桶
安装亚马逊云科技命令行工具后,我们可以使用如下命令将桶复制到我们自己的桶。因为 S3 桶名为全局唯一,所以请注意把下面的 my-nyc-tlc 换成你实际创建的桶名。
aws s3 cp s3://nyc-tlc/trip+data/fhvhv_tripdata_2020-12.csv s3://my-nyc-tlc
3、连接数据集
接下来,我们可以到 DataBrew 的「数据集」(Datasets)界面,选择「连接到新数据集」。
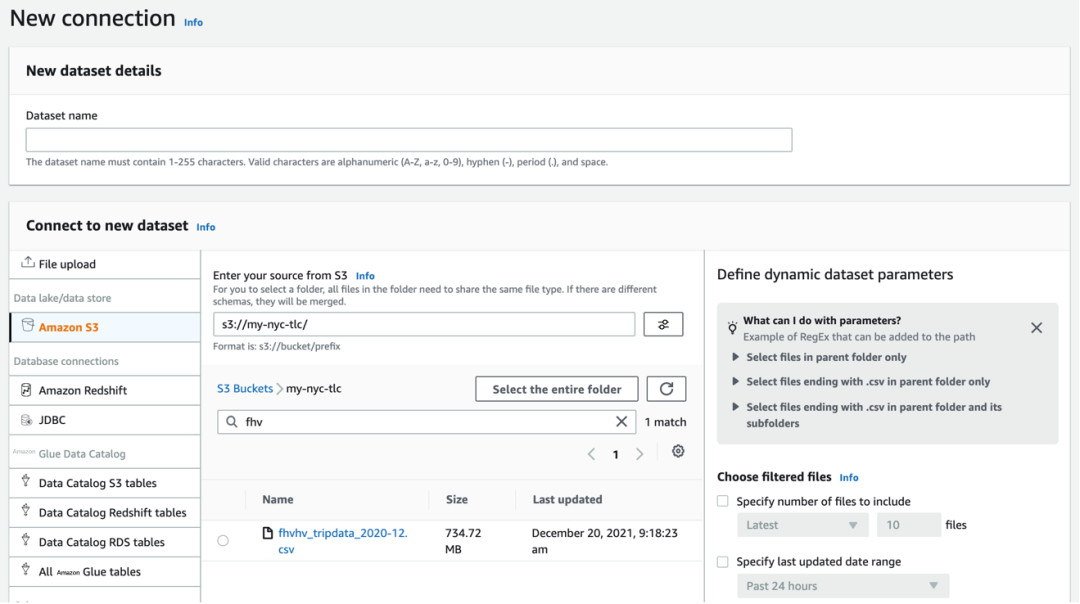
可以看到,DataBrew 支持的数据源还是很多的,除了常见的直连 S3,也可以通过 JDBC 连接数据库。如果数据本身已经在数据湖里,经由爬虫录入到了 Glue Data Catalog,我们也可以直接选择。
为了简便,在这次演示里,我们选择前面创建的 S3 桶和复制过来的 .csv 文件。数据格式选择 CSV。
数据形态分析
创建数据集后,我们可以快速地预览数据集中的数据。
如果想详细了解数据形态,比如值的分布、值的区间、极值、平均值、有效值等,我们可以点击右上角的「分析数据形态」(Run data profie)按钮,创建一个「数据形态分析任务」。
创建时我们可以选择是进行采样分析还是全量分析,并且配置一些参数,比如:是否分析重复的行,是否分析不同字段的相关性等。
点击「创建并运行」,数据形态分析任务就开始运行,稍后我们就能在「数据形态概览」标签下看到类似如下的结果。
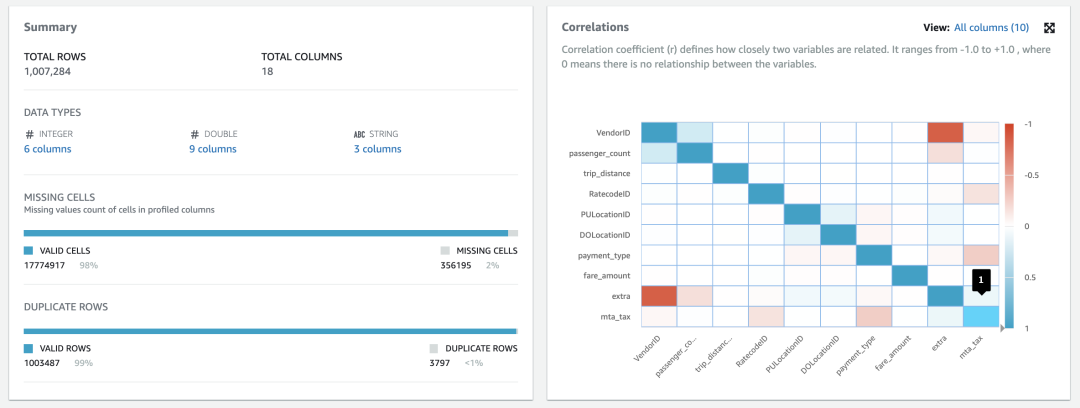
图左边可以看到整体的数据量,有效值以及重复的行等等。右边是字段关联表,代表字段之间的联动性。比如 A 字段变化时,B 字段如果也变化,那么颜色就会越深。
拿第一行来说,我们可以看到横向的 VendorID 字段和纵向的 extra 字段是有强烈关联的,并且 VendorID 值越大,extra 值就越小。
假设 extra 代表的是小费,那么我们可以说 VendorID 越小的公司,乘客给的小费就越多。这可能是因为 VendorID 小的公司使用的是比较高级的出租车。此外,我们也可以看到乘客数量、上下车地点,甚至支付方式,都和 extra 有一些关联关系。
通过这个关联关系图,我们可以快速判断哪些字段是我们感兴趣想要深入分析的。鼠标指向任意一个格子,可以看到格子的原始值,方便细化判断。
当然,我们也很容易就会注意到蓝色格子组成的斜线,不言而喻,这是因为任何字段都和自身是完全联动的。
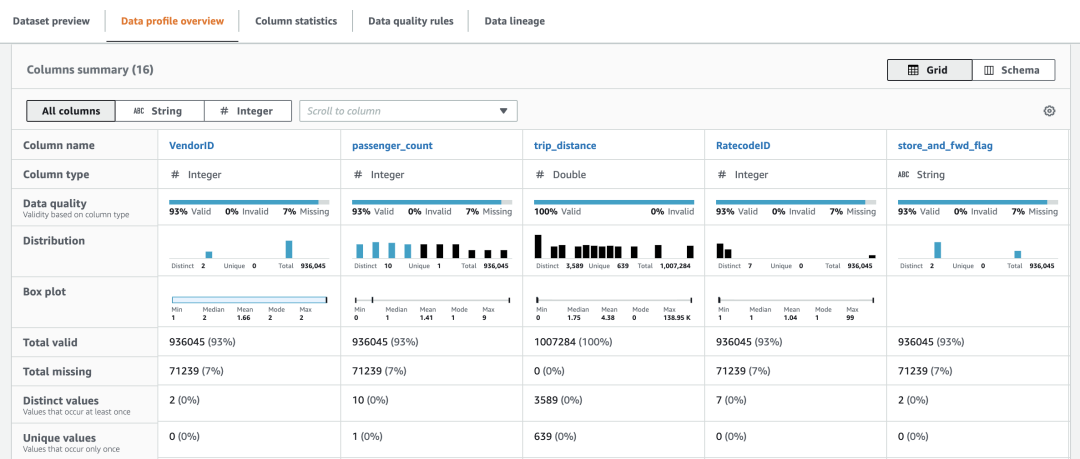
这个报告很清晰易懂,此处我只简单介绍下部分术语:
-
Valid 代表字段值符合 DataBrew 的推断或者元数据中的定义
-
Distinct 代表这个字段有多少个独特值(和其他值都不同)
-
Unique 代表这个字段有多少个唯一值(只出现过 1 次)
-
Median 是中位数,即按大小排序后,处在正中间的值
-
Mean 是平均值
-
Mode 是模数,即出现次数最多的值
此外,在直方图上,黑色代表是超出数据方差的极值。因为这部分值的数量较少,如果按比例展示可能就看不到或者看不清了,所以通常会把他的比例进行放大,用黑色区分,代表这部分的值和蓝色部分的值不成正常比例。
注:目前 DataBrew 仅支持字符串和数字类型的数据形态分析,如果某个字段的内容是类似 2021-10-10 这样的日期或时间,则这个字段不会纳入分析。要解决这个问题,我们可以对数据进行处理,给这个字段增加一个前缀(比如 DT-)或者修改这个字段的类型。
数据处理
数据形态看得差不多,接下来我们来处理数据。
DataBrew 为我们提供了一个数据处理的可视化编辑界面。这个界面在 DataBrew 中称作一个「项目」,所以我们首先要创建一个项目。直接在数据集界面右上角点击「为此数据集创建项目」(Create a project with this dataset)即可创建项目。
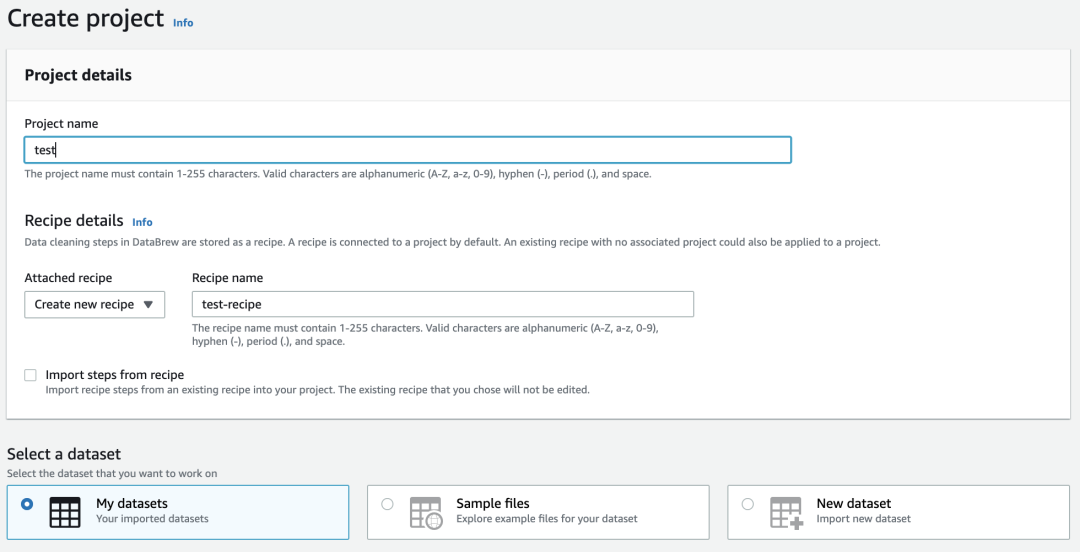
此处,必须输入的参数是项目名、数据集和 IAM 角色。角色可交由 DataBrew 自动创建,用于访问数据源,也就是 S3 桶。
创建完成后,我们会看到这样的一个载入界面。这个界面会持续数分钟,因为它需要分配底层计算实例,安装编辑器应用,配置权限等等。
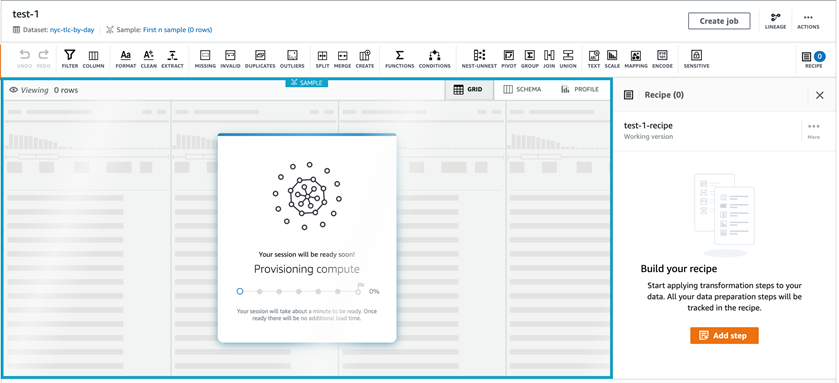
数分钟后,我们就能看到完整的编辑器,上面一排图标就是我们能做的操作。这些操作分类如下:
-
Filter 过滤,即去掉包含非法值、缺失值的行等
-
Column 列级处理,即删除字段,修改字段类型等
-
Format 值格式化,比如字符串大小写转换,数字的小数点精确度等
-
Clean 值清理,比如删除首尾的引号、空格,添加前后缀等
-
Extract 值提取,比如提取日期中的年月日等
-
Missing 缺失值处理,比如值缺失时填入指定值,填入平均值等
-
Invalid、Duplicates、Outliers 对应非法制、重复值和异常值,逻辑和缺失值类似
-
Split、Merge 分别是拆分和合并,即按分隔符把一个字符串字段拆分成多个字段,或者反之
-
Create 是根据一个字段的值生成另一个字段,通常用于生成标签字段
-
Functions 是对某个字段使用函数生成另一个字段
-
Condition 和 Create 类似,也是按条件生成新字段
-
Nest-Unnest 指的是把多个字段合并成单个数组、对象字段,或者反之
-
Pivot 指的是维度替换,比如原来有两个字段「车牌号」和「上车地点」,现在每个车牌号会变成一个字段名字,然后对应的上车地点则会变成一个列表值放在车牌号字段下
-
Group、Join 和 Union,就类似 SQL 的 GROUP BY、JOIN 和 UNION
-
Text 是对文本处理,比如令牌化
-
Scale 是数字值规整化,比如正规化
-
Mapping 也是根据字段值创建新的字段,和前面的 Condition 类似,可以视作是一个快捷方式
-
Encode 是对数据进行常见的编码,比如机器学习常见的「单热编码」(One-hot encoding)
-
Sensitve 是对敏感和隐私数据的处理,比如遮罩、加解密等
接下来,我们来看几个常见的数据处理场景。
注:请注意 DataBrew 的项目(编辑器)与很多 AWS 不同,不是按秒而是最少收取半小时的费用。
1、列级过滤 – 限制访问数据类型
假设现在某个财务或者税务部门的分析师,希望能分析统计下面这些信息。
-
不同出租车信息供应商旗下的汽车的交易额
-
不同日期的出租车交易额
-
主要的支付方式
-
月度出租车交易总额
这时候,我们就可以只显示相关的字段,而把其他的字段给过滤掉。要做字段过滤,我们可以使用 DataBrew 的 Column > Delete 操作。这个操作会删除指定的字段,只保留允许用户查看的字段。
2、行级过滤 – 只保留特定语义的数据
几乎所有数据工具都支持表级别的过滤,部分工具也支持字段过滤,但支持行级过滤的要少一些。行级过滤意味着我们可以对数据的语义做判断,并且只允许用户查看部分类型的数据。
比如下面这个需求。
-
只允许分析机场区域和 CDB 商圈之间的出租车记录
-
只允许分析夜间的出租车记录
-
只允许分析金额小于 100 元的记录
要做到行级过滤,我们可以使用 Filter > By condition 操作,这个操作支持对数字和字符串做简单对比,然后进行过滤。
如果某些字段不能直接满足对比要求,那么我们可以按条件把值先提取到另一个字段,再对新的字段做条件处理。比如「是否夜间」这个比较难直接判断,那么我们就可以先使用 Functions > Date functions > HOUR 函数把小时信息提取到新字段,然后再针对这个字段进行过滤。
3、其他处理
除了行级和列级过滤,DataBrew 也可以做很多别的数据处理,下面简单介绍几个场景。
敏感数据处理
为保护用户隐私,我们可以把敏感数据进行加密。
目前 DataBrew 支持两种加密方式,一种是「确定性加密」(Deterministic Encryption),另一种是「非确定性加密」(Probablistic Encryption)。
前者适合加密一些不需要参与运算,但是需要以确定值参与统计,并且最后还需要还原的字段。比如:出租车的车牌或者乘客上下车的地点。
后者则适合加密一些不需要参与运算,也不需要参与统计,但是在特定时刻,有特定权限的人还是需要将其还原的数据。比如:人名,身份证号等个人相关信息。
如果只需要统计,不需要还原,则可以选择对该字段直接进行哈希处理,或者将该字段的部分值进行遮罩(比如替换成「#」)。
函数调用
DataBrew 内置了非常多的函数,这些函数和我们常见的 Excel 函数类似,可以帮助我们快速地对数据进行处理。常用的函数有:
-
数学函数:取整、取绝对值等
-
文字函数:大小写转换、取部分文字、替换文字等
-
日期函数:取年月日、取日期差等
-
窗口函数:取某个时间窗口的总数、最大最小值等
-
Web 函数:IP 与整数值互转、URL 的请求字符串提取等
条件处理
DataBrew 支持使用 IF 或者 CASE,根据字段值的不同,输出指定的值到一个新的列。
这个处理方式适合在没有现成的函数可用时,手动、精细地对某个字段进行处理或标记。比如:把用户的生日转换成属相或者星座。
此外,条件处理还支持日期格式,并且支持以其他字段的值作为输入,形成类似变成语言的 FOR 循环效果,这可以帮助用户实现复杂的数据处理逻辑。
创建数据处理任务
在项目中,我们可以对数据做处理并且预览效果,但此时的处理仅针对采样的数据,实际数据仍然没有处理。预览效果觉得处理无误后,我们就可以创建数据处理任务,从而对全量数据进行处理。
在项目的右上角,点击「创建任务」。接下来,我们需要输入:
-
目标 S3 桶
-
数据格式,比如:CSV、Parquet 等
-
执行周期,比如:一次性、定时重复执行等
-
执行角色,这个角色需要能访问源桶和目标桶
这些信息输入完成后,我们可以选择「创建并运行」,直接运行这个任务。
数据血缘
DataBrew 为每个项目提供了简易的数据血缘图(Linage)。在数据血缘图中,我们可以看到针对这个项目,我们的原始数据在哪个 S3 桶,这个桶对应了哪个数据集,对应这个数据集的项目是什么,这个项目对数据进行了哪些处理,然后输出到了哪里。
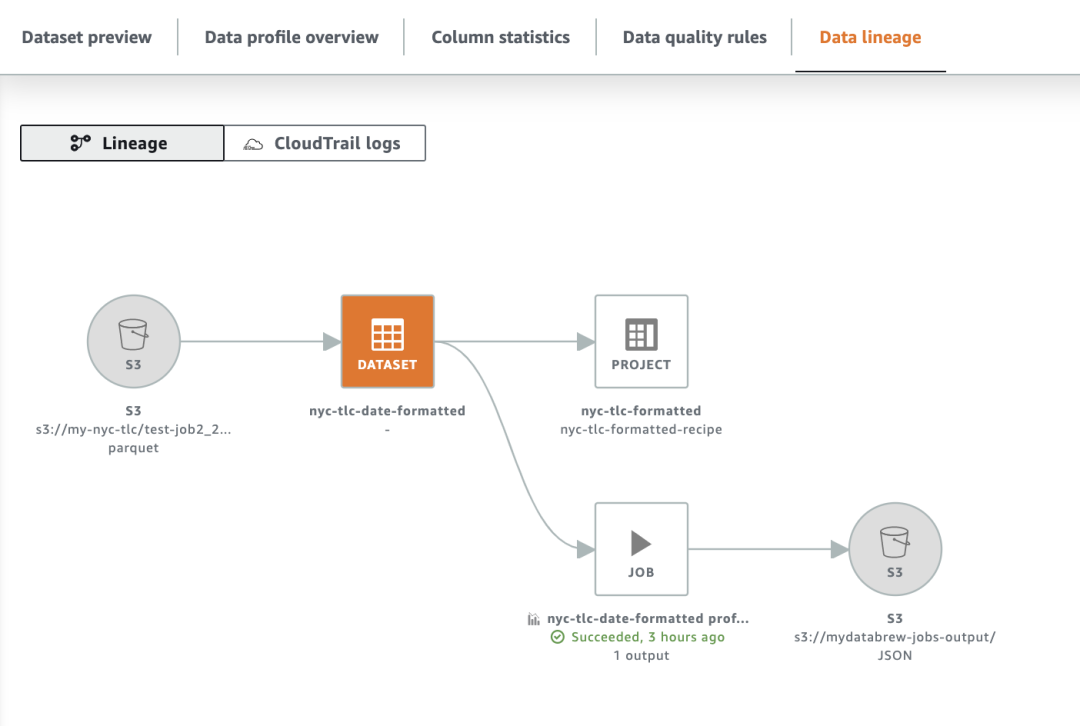
需要注意的是,目前 DataBrew 的血缘仅展示当前的 DataBrew 项目中数据的流向。
总结
随着大数据系统的建设和技术发展,数据湖中的数据越来越多,越来越实时。为了合规、合法,数据持有者必须高度重视访问控制。
数据湖工具通常也会提供权限控制,但粒度通常只能到表级别,如果要到行级别或者列级别,则需要额外在本地安装工具,而且有被绕过的风险。不同部门和访问权限的人使用不同的 S3 桶,并且使用只包含特定业务需要的数据文件,可以很大程度上降低数据泄露的风险。
对于探索期的项目,权限的管理可能比较粗放,但是在业务稳定开始长期运行时,我们应该考虑把这些流程固化下来,让用户和部门只能访问到自己能访问并且需要访问的数据。
作为一个无服务器的数据处理服务,DataBrew 非常适合数据科学家、业务专家等对业务熟悉但对底层技术研究不深的用户,以及数据合规探索期的团队。使用 Amazon Glue DataBrew 我们可以快速搭建起一套弹性的数据处理流水线,把更多的精力放在业务上。
对 Amazon Glue DataBrew 的简单介绍就到这里,希望对读者有所帮助。
本篇作者

张玳
亚马逊云科技解决方案架构师
十余年企业软件研发、设计和咨询经验,专注企业业务与亚马逊云科技服务的有机结合。译有《软件之道》《精益创业实战》《精益设计》《互联网思维的企业》,著有《体验设计白书》等书籍。

标签:DataBrew,可以,字段,Amazon,创建,Glue,数据,我们 来源: https://www.cnblogs.com/AmazonwebService/p/16307979.html